
Often when designing systems, we aim for perfection in things like consistency of data, availability, latency, and more.
The hardest part of system design is that it’s difficult (if not impossible) to design systems that have perfect consistency, perfect availability, incredibly low latency, and incredibly high throughput, all at the same time.
Instead, when we approach system design, it’s best to treat each of these properties as points on different axes that we balance to find the “right fit” for the application we’re supporting.
I recently made some major tradeoffs in the design of Bluesky’s Following Feed/Timeline to improve the performance of writes at the cost of consistency in a way that doesn’t negatively affect users but reduced P99s by over 96%.
Timeline Fanout
When you make a post on Bluesky, your post is indexed by our systems and persisted to a database where we can fetch it to hydrate and serve in API responses.
Additionally, a reference to your post is “fanned out” to your followers so they can see it in their Timelines.
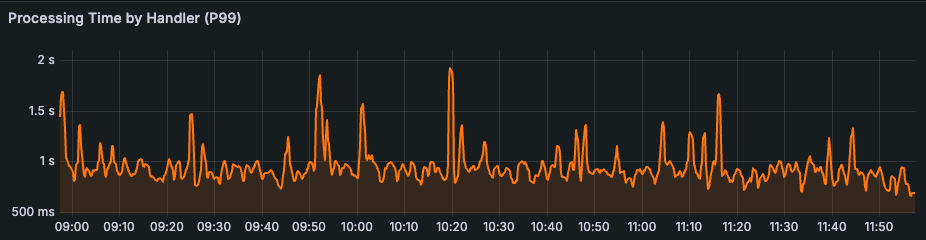
Knowing where it’s okay to be imperfect lets you trade consistency for other desirable aspects of your systems and scale ever higher.
There are plenty of other places for improvement in our Timelines architecture, but this step was a big one towards improving throughput and scalability of Bluesky’s Timelines.
If you’re interested in these sorts of problems and would like to help us build the core data services that power Bluesky, check out this job listing.
If you’re interested in other open positions at Bluesky, you can find them here.

{kind=link}