
Comments
Ok, I’m a bit underwhelmed. I’ve asked it a fairly technical question, about a very niche topic (Final Fantasy VII reverse engineering): https://chatgpt.com/share/68001766-92c8-8004-908f-fb185b7549...
With right knowledge and web searches one can answer this question in a matter of minutes at most. The model fumbled around modding forums and other sites and did manage to find some good information but then started to hallucinate some details and used them in the further research. The end result it gave me was incorrect, and the steps it described to get the value were totally fabricated.
What’s even worse in the thinking trace it looks like it is aware it does not have an answer and that the 399 is just an estimate. But in the answer itself it confidently states it found the correct value.
Essentially, it lied to me that it doesn’t really know and provided me with an estimate without telling me.
Now, I’m perfectly aware that this is a very niche topic, but at this point I expect the AI to either find me a good answer or tell me it couldn’t do it. Not to lie me in the face.
Edit: Turns out it’s not just me: https://x.com/transluceai/status/1912552046269771985?s=46
Compare to Gemini Pro 2.5:
https://g.co/gemini/share/c8fb1c9795e4
Of note, the final step in the CoT is:
> Formulate Conclusion: Since a definitive list or count isn't readily available through standard web searches, the best approach is to: state that an exact count is difficult to ascertain from readily available online sources without direct analysis of game files ... avoid giving a specific number, as none was reliably found across multiple sources.
and then the response is in line with that.
By M4v3R 2025-04-175:23 I like this answer. It does mention the correct, definitive way of getting the information I want (extracting the char.lgp data file) and so even though it gave up it pushes you in the right direction, whereas o3/o4 just make up stuff.
I've used AI with "niche" programming questions and it's always a total let down. I truly don't understand this "vibe coding" movement unless everyone is building todo apps.
By SkyPuncher 2025-04-172:322 reply There's a bit of a skill to it.
Good architecture plans help. Telling it where in an existing code base it can find things to pattern match against is also fantastic.
I'll often end up with a task that looks something like this:
* Implement Foo with a relation to FooBar.
* Foo should have X, Y, Z features
* We have an existing pattern for Fidget in BigFidget. Look at that for implementation
* Make sure you account for A, B, C. Check Widget for something similar.
It works surprisingly well.
> Good architecture plans help.
This is they key answer right here.
LLMs are great at interpolating and extrapolating based on context. Interpolating is far less error-prone. The problem with interpolating is that you need to start with accurate points so that interpolating between them leads to expected and relatively accurate estimates.
What we are seeing is the result of developers being oblivious to higher-level aspects of coding, such as software architecture, proper naming conventions, disciplined choice of dependencies and dependency management, and even best practices. Even basic requirements-gathering.
Their own personal experience is limited to diving into existing code bases and patching them here and there. They often screw up the existing software architecture because their lack of insight and awareness leads them to post PRs that get the job done at the expense of polluting the whole codebase into an unmanageable mess.
So these developers crack open an LLM and prompt it to generate code. They use their insights and personal experience to guide their prompts. Their experience reflects what they do on a daily basis. The LLMs of course generate code from their prompts, and the result is underwhelming. Garbage-in, garbage-out.
It's the LLMs fault, right? All the vibe coders out there showcasing good results must be frauds.
The telltale sign of how poor these developers are is how they dump the responsibility of they failing to get LLMs to generate acceptable results on the models not being good enough. The same models that are proven effective at creating whole projects from scratch at their hands are incapable of the smallest changes. It's weird how that sounds, right? If only the models were better... Better at what? At navigating through your input to achieve things that others already achieve? That's certainly the model's fault, isn't it?
A bad workman always blames his tools.
Yes, with a bit of work around prompting and focusing on closed context, or as you put it, interpolating, you can get further. But the problems is that, this is not how the LLMs were sold. If you blame someone for trying to use it by specifying fairly high level prompts - well isn´t that exactly how this technology was being advertised the whole time? The problem is not the bad workman, the problem is that the tool is not doing what it is advertised as doing.
> But the problems is that, this is not how the LLMs were sold.
No one cares about promises. The only thing that matters are the tangibles we have right now.
Right now we have a class of tools that help us write multidisciplinary apps with a few well-crafted prompts and zero code involved.
By hansmayer 2025-04-218:44 Well, some of us do. Would you take a 3-door car after paying for a minivan? And no, you cannot write an app with zero code involved, this is literally how computers work.
By extr 2025-04-175:39 Yeah this is a great summary of what I do as well and I find it very effective. I think of hands-off AI coding like you're directing a movie. You have a rough image of what "good" looks like in your head, and you're trying to articulate it with enough detail to all the stagehands and actors such that they can realize the vision. The models can always get there with enough coaching, traditionally the question is if that's worth the trouble versus just doing it yourself.
Increasingly I find that AI at this point is good enough I am rarely stepping in to "do it myself".
By hatefulmoron 2025-04-170:471 reply It's incredible when I ask Claude 3.7 a question about Typescript/Python and it can generate hundreds of lines of code that are pretty on point (it's usually not exactly correct on first prompt, but it's coherent).
I've recently been asking questions about Dafny and Lean -- it's frustrating that it will completely make up syntax and features that don't exist, but still speak to me with the same confidence as when it's talking about Typescript. It's possible that shoving lots of documentation or a book about the language into the context would help (I haven't tried), but I'm not sure if it would make up for the model's lack of "intuition" about the subject.
Don't need to ho that esoteric. Seen them make stuff up pretty often for more common functional programming languages like Haskell and OCaml.
By greenavocado 2025-04-172:511 reply Recommend using RAG for this. Make the Haskell or OCaml documentation your knowledge base and index it for RAG. Then it makes a heck of a lot more sense!
How does one do that? As far as I can tell neither Claude or chatgpt web clients support this. Is there a third party tool that people are using?
By hellsten 2025-04-1817:39 You could try using the built-in "projects" feature of Claude and ChatGPT: https://support.anthropic.com/en/articles/9517075-what-are-p...
You can get pretty good results by copying the output from Firefox's Reader View into your project, for example: about:reader?url=https://learnxinyminutes.com/ocaml/
By greenavocado 2025-04-1711:38 They can't
You can use openwebui with deepseek v3 0324 via API with for example deepinfra as provider for your embeddings and text generation models
By Foobar8568 2025-04-176:06 Well all LLM are fairly bad for react native as soon as you look at more than hello world type of things.
I got stuck with different LLM until I checked the official documentation, yeah spouting nonsense from 2y+ removed features I suppose or just making up stuff.
By mikepurvis 2025-04-173:35 I'm trialing co-pilot in VSCode and it's a mixed bag. Certain things it pops out great, but a lot of times I'll be like woohoo! <tab> <tab> <tab> and then end up immediately realising wait a sec, none of this is actually needed, or it's just explicitly calling for things that are already default values, or whatever.
(This is particularly in the context of metadata-type stuff, things like pyproject files, ansible playbooks, Dockerfiles, etc)
I recently exclaimed that “vibe coding is BS” to one of my coworkers before explaining that I’ve actually been using GPT, Claude, llama (for airplanes), Cline, Cursor, Windsurf, and more for coding for as long as they’ve been available (more recently playing with Gemini). Cline + Sonnet 3.7 has been giving me great results on smaller projects with popular languages, and I feel truly fortunate to have AWS Bedrock on tap to drive this stuff (no effective throttling/availability limits for an individual dev). Even llama + Continue has proven workable (though it will absolutely hallucinate language features and APIs).
That said, 100% pure vibe coding is, as far as I can tell, still very much BS. The subtle ugliness that can come out of purely prompt-coded projects is truly a rat hole of hate, and results can get truly explosive when context windows saturate. Thoughtful, well-crafted architectural boundaries and protocols call for forethought and presence of mind that isn’t yet emerging from generative systems. So spend your time on that stuff and let the robots fill in the boilerplate. The edges of capability are going to keep moving/growing, but it’s already a force multiplier if you can figure out ways to operate.
For reference, I’ve used various degrees of assistance for color transforms, computer vision, CNN network training for novel data, and several hundred smaller problems. Even if I know how to solve a problem, I generally run it through 2-3 models to see how they’ll perform. Sometimes they teach me something. Sometimes they violently implode, which teaches me something else.
> That said, 100% pure vibe coding is, as far as I can tell, still very much BS.
I don't really agree. There's certainly a showboating factor, not to mention there is currently a goldrush to tap this movement to capitalize from it. However, I personally managed to create a fully functioning web app from scratch with Copilot+vs code using a mix of GPT4 and o1-mini. I'm talking about both backend and frontend, with basic auth in place. I am by no means a expert, but I did it in an afternoon. Call it BS, the the truth of the matter is that the app exists.
By saberience 2025-04-1710:061 reply People were making a front and backend web app in half a day using Ruby on Rails way before LLMs were ever a thing, and their code quality was still much better than yours!
So vibe coding, sure you can create some shitty thing which WORKS, but once it becomes bigger than a small shitty thing, it becomes harder and harder to work with because the code is so terrible when you're pure vibe coding.
By motorest 2025-04-1712:44 > People were making a front and backend web app in half a day using Ruby on Rails way before LLMs were ever a thing, and their code quality was still much better than yours!
A few people were doing that.
With LLMs, anyone can do that. And more.
It's important to frame the scenario correctly. I repeat: I created everything in an afternoon just for giggles, and I challenged myself to write zero lines of code.
> So vibe coding, sure you can create some shitty thing which WORKS (...)
You're somehow blindly labelling a hypothetical output as "shitty", which only serves to show your bias. In the meantime, anyone who is able to churn out a half-functioning MVP in an afternoon is praised as a 10x developer. There's a contrast in there, where the same output is described as shitty or outstanding depending on who does it.
By ecocentrik 2025-04-1715:23 People who embracing vibe coding are probably the same people who were already sudo-vibe coding to begin with using found fragments of code they could piece together to make things sort of work for simple tasks.
By killerdhmo 2025-04-172:27 I mean, I don't think you need to do cutting edge programming to make something personal to you. See here from Canva's product. Check this out: https://youtu.be/LupwvXsOQqs?t=2366
By motorest 2025-04-176:03 > I've used AI with "niche" programming questions and it's always a total let down.
That's perfectly fine. It just means you tried without putting in any effort and failed to get results that were aligned with your expectations.
I'm also disappointed when I can't dunk or hit >50% of my 3pt shots, but then again I never played basketball competitively
> I truly don't understand this "vibe coding" movement unless everyone is building todo apps.
Yeah, I also don't understand the NBA. Every single one of those players show themselves dunking and jumping over cars and having almost perfect percentages in 3pt shots during practice, whereas I can barely get off my chair. The problem is certainly basketball.
By lend000 2025-04-174:39 I imagine after GPT-4 / o1, improvements on benchmarks have been increasingly a result of overfitting, because those breakthrough models already used most of the high quality training data that is available on the internet, there haven't been any dramatic architectural changes, we are already melting the world's GPUs, and there simply isn't enough new, high quality data being generated (orders of magnitudes more than what they already used on older models) to enable breakthrough improvements.
What I'd really like to see is the model development companies improving their guardrails so that they are less concerned about doing something offensive or controversial and more concerned about conveying their level of confidence in an answer, i.e. saying I don't know every once in a while. Once we get a couple years of relative stagnation in AI models, I suspect this will become a huge selling point and you will start getting "defense grade", B2B type models where accuracy is king.
By casinoplayer0 2025-04-177:56 I wanted to believe. But not now.
By hirvi74 2025-04-171:23 Have you asked this same question to various other models out there in the wild? I am just curious if you have found some that performed better. I would ask some models myself, but I do not know the proper answer, so I would probably be gullible enough to believe whatever the various answers have in common.
AIs in general are definitely hallucinating a lot more when it comes to niche topics. It is funny how they are unable to say "I don't know" and just make up things to answer your questions
By felipeerias 2025-04-178:18 LLMs made me a lot more aware of leading questions.
Tiny changes in how you frame the same query can generate predictably different answers as the LLM tries to guess at your underlying expectations.
By M4v3R 2025-04-176:06 Btw Ive also asked this question using Deep Research mode in ChatGPT and got the correct answer: https://chatgpt.com/share/68009a09-2778-8004-af40-4a8e7e812b...
So maybe this is just too hard for a “non-research” mode. I’m still disappointed it lied to me instead of saying it couldn’t find an answer.
How would it ever know the answer it found is true and correct though? It could as well just repeat some existing false answer that you didn't yet find on your own. That's not much better than hallucinating it, since you can't verify its truth without finding it independently anyway.
By M4v3R 2025-04-175:20 I would be ok with having an answer and an explanation of how it got the answer with a list of sources. And it does just that - the only problem is that both the answer and the explanation are fabrications after you double check the sources.
By Davidzheng 2025-04-172:13 Underwhelmed compared with Gemini 2.5 Pro--however it would've been impressive a month ago I think.
By tern 2025-04-176:27 What's the correct answer? Curious if it got it right the second time: https://chatgpt.com/share/68009f36-a068-800e-987e-e6aaf190ec...
By heavyset_go 2025-04-1720:45 Same thing happened when asking it a fairly simple question about dracut on Linux.
If I went through with the changes it suggested, I wouldn't have a bootable machine.
> Not to lie me in the face.
Are you saying that, it deliberately lied to you?
> With right knowledge and web searches one can answer this question in a matter of minutes at most.
Reminded me of Dunning Kruger curve, the ai model at the first peak and you at the latter.
By M4v3R 2025-04-179:12 > Are you saying that, it deliberately lied to you?
Pretty much yeah. Now “deliberately” does imply some kind of agency or even consciousness which I don’t believe these models have, its probably the result of overfitting, reward hacking or some other issues from training it, but the end result is that the model straight up misleads you knowingly (as in - the thinking trace is aware of the fact it doesn’t know the answer but it provides it anyways).
By mountainriver 2025-04-1813:281 reply Oh boy, here comes the “it didn’t work for this one specific thing I tried” posts
By dragonmost 2025-04-197:10 But then how can you rely on it for things you don't know the answer to? The exercise just goes to show it still can't admit it doesn't know and lies instead.
Interesting... I asked o3 for help writing a flake so I could install the latest Webstorm on NixOS (since the one in the package repo is several months old), and it looks like it actually spun up a NixOS VM, downloaded the Webstorm package, wrote the Flake, calculated the SHA hash that NixOS needs, and wrote a test suite. The test suite indicates that it even did GUI testing- not sure whether that is a hallucination or not though. Nevertheless, it one-shotted the installation instructions for me, and I don't see how it could have calculated the package hash without downloading, so I think this indicates some very interesting new capabilities. Highly impressive.
By danpalmer 2025-04-177:05 Are you sure about all of this? You acknowledged it might be a hallucination, but you seem to mostly believe it? o3 doesn't have the ability to spin up a VM.
https://xcancel.com/TransluceAI/status/1912552046269771985 / https://news.ycombinator.com/item?id=43713502 is a discussion of these hallucinations.
As for the hash, could it have simply found a listing for the package with hashes provided and used that hash?
By tymscar 2025-04-1620:49 Thats so different from my experience. I tried to have it switch a flake for a yarn package that works to npm and after 3 tries with all the hints I could give it it couldn’t do it
By bool3max 2025-04-177:37 I find that so incredibly unlikely. Granted I haven't been keeping up to date with the latest LLM developments - but has there even been any actual confirmation from OpenAI that these models have the ability to do such things in the background?
By peterldowns 2025-04-1619:373 reply If it can write a nixos flake it's significantly smarter than the average programmer. Certainly smarter than me, one-shotting a flake is not something I'll ever be able to do — usually takes me about thirty shots and a few minutes to cool off from how mad I am at whoever designed this fucking idiotic language. That's awesome.
By ZeroTalent 2025-04-1620:142 reply I was a major contributor of Flake. What in particular is so idiotic in your opinion?
By peterldowns 2025-04-1620:261 reply I use flakes a lot and I think both flakes and the Nix language are beyond comprehension. Try searching duckduckgo or google for “what is nix flakes” or “nix flake schema” and take an honest read at the results. Insanely complicated and confusing answers, multiple different seemingly-canonical sources of information. Then go look at some flakes for common projects; the almost necessary usage of things like flake-compat and flake-util, the many-valid-approaches to devshell and package definitions, the concepts of “apps” in addition to packages. All very complicated and crazy!
Thank you for your service, I use your work with great anger (check my github I really do!)
By ZeroTalent 2025-04-1620:521 reply I apologize. It was my Haskell life period.
By peterldowns 2025-04-1620:592 reply I forgive you as I hope you forgive me. Flakes are certainly much better than Nix without them, and they’ve saved me much more time than they’ve cost me.
By ZeroTalent 2025-04-2110:28 No worries I also have to say I haven't had me morning coffee when I was writing my comment and maybe reacted overly emotionally. To me prioritizing Flakes being succinct was a priority.
By wg0 2025-04-176:58 Man ... Classic HN.
But yes unfortunately even if you across the whole functional paradigm, nix is surely complicated. And one single file whole system up is rarely true.
By yjftsjthsd-h 2025-04-1620:18 FWIW, they said the language was bad, not specifically flakes. IMHO, nix is super easy if you already know Haskell (possibly others in that family). If you don't, it's extremely unintuitive.
By brailsafe 2025-04-170:06 I mean, a smart programmer still has to learn what NixOs and Flakes are, and based on your description and some cursory searching, a smart programmer would just go do literally anything else. Perfect thing to delegate to a machine that doesn't have to worry about motivation.
Just jokes, idk anything about either.
\s
By ai-christianson 2025-04-1619:42 > Interesting... I asked o3 for help writing...
What tool were you using for this?
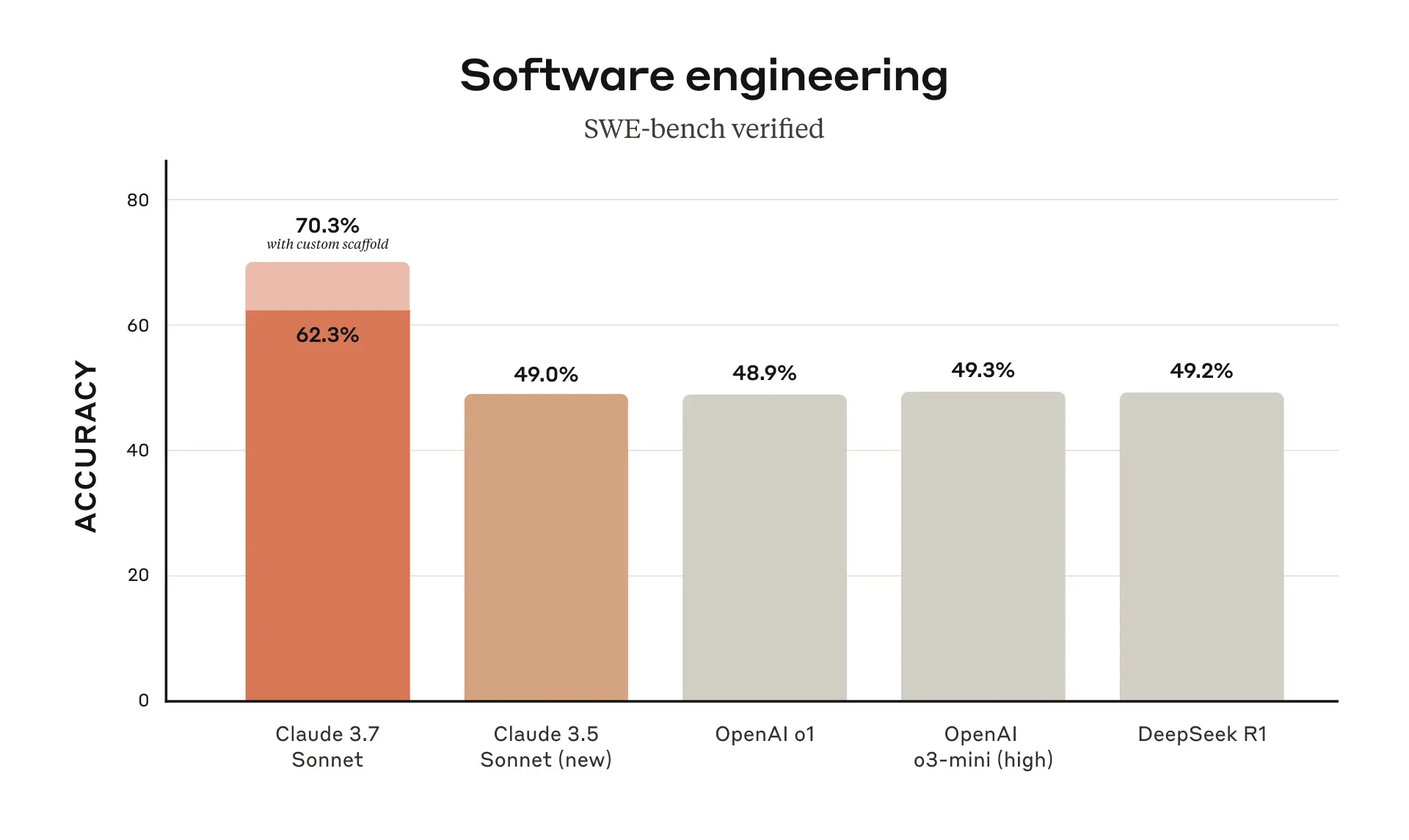
By georgewsinger 2025-04-1617:207 reply Very impressive! But under arguably the most important benchmark -- SWE-bench verified for real-world coding tasks -- Claude 3.7 still remains the champion.[1]
Incredible how resilient Claude models have been for best-in-coding class.
[1] But by only about 1%, and inclusive of Claude's "custom scaffold" augmentation (which in practice I assume almost no one uses?). The new OpenAI models might still be effectively best in class now (or likely beating Claude with similar augmentation?).
Gemini 2.5 Pro is widely considered superior to 3.7 Sonnet now by heavy users, but they don't have an SWE-bench score. Shows that looking at one such benchmark isn't very telling. Main advantage over Sonnet being that it's better at using a large amount of context, which is enormously helpful during coding tasks.
Sonnet is still an incredibly impressive model as it held the crown for 6 months, which may as well be a decade with the current pace of LLM improvement.
By unsupp0rted 2025-04-1617:376 reply Main advantage over Sonnet is Gemini 2.5 doesn't try to make a bunch of unrelated changes like it's rewriting my project from scratch.
By itsmevictor 2025-04-1617:451 reply I find Gemini 2.5 truly remarkable and overall better than Claude, which I was a big fan of
By enraged_camel 2025-04-1618:143 reply Still doesn't work well in Cursor unfortunately.
By ai-christianson 2025-04-1619:45 Works well in RA.Aid --in fact I'd recommend it as the default model in terms of overall cost and capability.
By michaelbarton 2025-04-1623:38 Not the OP but believe they could be referring to the fact it’s not supported in edit mode yet, only agent mode.
So far for me that’s not been too much of a roadblock. Though I still find overall Gemini struggles with more obscure issues such as SQL errors in dbt
By pdntspa 2025-04-173:35 Cline/Roo Code work fine with it
By bitbuilder 2025-04-1618:341 reply This was incredibly irritating at first, though over time I've learned to appreciate this "extra credit" work. It can be fun to see what Claude thinks I can do better, or should add in addition to whatever feature I just asked for. Especially when it comes to UI work, Claude actually has some pretty cool ideas.
If I'm using Claude through Copilot where it's "free" I'll let it do its thing and just roll back to the last commit if it gets too ambitious. If I really want it to stay on track I'll explicitly tell it in the prompt to focus only on what I've asked, and that seems to work.
And just today, I found myself leaving a comment like this: //Note to Claude: Do not refactor the below. It's ugly, but it's supposed to be that way.
Never thought I'd see the day I was leaving comments for my AI agent coworker.
> If I'm using Claude through Copilot where it's "free"
Too bad Microsoft is widely limiting this -- have you seen their pricing changes?
I also feel like they nerfed their models, or reduced context window again.
Claude is almost comically good outside of copilot. When using through copilot it’s like working with a lobotomized idiot (that complains it generated public code about half the time).
By TuxSH 2025-04-1910:20 It used to be good, or at least quite decent in GH Copilot, but it all turned into poop (the completions, the models, everything) ever since they announced the pricing changes.
Considering that M$ obviously trains over GitHub data, I'm a bit pissed, honestly, even if I get GH Copilot Pro for free.
What language / framework are you using? I ask because in a Node / Typescript / React project I experience the opposite- Claude 3.7 usually solves my query on the first try, and seems to understand the project's context, ie the file structure, packages, coding guidelines, tests, etc, while Gemini 2.5 seems to install packages willy-nilly, duplicate existing tests, create duplicate components, etc.
By unsupp0rted 2025-04-1711:04 Node / Vue
By jdgoesmarching 2025-04-1617:481 reply Also that Gemini 2.5 still doesn’t support prompt caching, which is huge for tools like Cline.
2.5 Pro supports prompt caching now: https://cloud.google.com/vertex-ai/generative-ai/docs/models...
By jdgoesmarching 2025-04-1618:07 Oh, that must’ve been in the last few days. Weird that it’s only in 2.5 Pro preview but at least they’re headed in the right direction.
Now they just need a decent usage dashboard that doesn’t take a day to populate or require additional GCP monitoring services to break out the model usage.
By Workaccount2 2025-04-1617:52 It's viable context, context length where is doesn't fall apart, is also much longer.
By zaptrem 2025-04-1618:10 I do find it likes to subtly reformat every single line thereby nuking my diff and making its changes unusable since I can’t verify them that way, which Sonnet doesn’t do.
By armen52 2025-04-1621:12 I don't understand this assertion, but maybe I'm missing something?
Google included a SWE-bench score of 63.8% in their announcement for Gemini 2.5 Pro: https://blog.google/technology/google-deepmind/gemini-model-...
By amedviediev 2025-04-1719:14 I keep seeing this sentiment so often here and on X that I have to wonder if I'm somehow using a different Gemini 2.5 Pro. I've been trying to use it for a couple of weeks already and without exaggeration it has yet to solve a single programming task successfully. It is constantly wrong, constantly misunderstands my requests, ignores constraints, ignores existing coding conventions, breaks my code and then tells me to fix it myself.
By spaceman_2020 2025-04-1619:24 I feel that Claude 3.7 is smarter, but does way too much and has poor prompt adherence
By redox99 2025-04-172:26 2.5 Pro is very buggy with cursor. It often stops before generating any code. It's likely a cursor problem, but I use 3.7 because of that.
By saberience 2025-04-1710:08 Eh, I wouldn't say that's accurate, I think it's situational. I code all day using AI tools and Sonnet 3.7 is still the king. Maybe it's language dependent or something, but all the engineers I know are full on Claude-Code at this point.
By pizzathyme 2025-04-1619:103 reply The image generation improvement with o4-mini is incredible. Testing it out today, this is a step change in editing specificity even from the ChatGPT 4o LLM image integration just a few weeks ago (which was already a step change). I'm able to ask for surgical edits, and they are done correctly.
There isn't a numerical benchmark for this that people seem to be tracking but this opens up production-ready image use cases. This was worth a new release.
Thanks for sharing that. that was more interesting then their demo. I tried it and it was pretty good! I have felt that the ability to iterate from images blocked this from any real production use I had. This may be good enough now.
Example of edits (not quite surgical but good): https://chatgpt.com/share/68001b02-9b4c-8012-a339-73525b8246...
By ec109685 2025-04-171:24 I don’t know if they let you share the actual images when sharing a chat. For me, they are blank.
wait, o4-mini outputs images? What I thought I saw was the ability to do a tool call to zoom in on an image.
Are you sure that's not 4o?
By Agentus 2025-04-1623:08 also another addition: i previously tried to upload an image for chatgpt to edit and it was incapable under the previous model i tried. Now its able to change uploaded images using o4mini.
By oofbaroomf 2025-04-1617:233 reply Claude got 63.2% according to the swebench.com leaderboard (listed as "Tools + Claude 3.7 Sonnet (2025-02-24)).[0] OpenAI said they got 69.1% in their blog post.
[0] swebench.com/#verified
By georgewsinger 2025-04-1617:421 reply Yes, however Claude advertised 70.3%[1] on SWE bench verified when using the following scaffolding:
> For Claude 3.7 Sonnet and Claude 3.5 Sonnet (new), we use a much simpler approach with minimal scaffolding, where the model decides which commands to run and files to edit in a single session. Our main “no extended thinking” pass@1 result simply equips the model with the two tools described here—a bash tool, and a file editing tool that operates via string replacements—as well as the “planning tool” mentioned above in our TAU-bench results.
Arguably this shouldn't be counted though?
[1] https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
By tedsanders 2025-04-1618:081 reply I think you may have misread the footnote. That simpler setup results in the 62.3%/63.7% score. The 70.3% score results from a high-compute parallel setup with rejection sampling and ranking:
> For our “high compute” number we adopt additional complexity and parallel test-time compute as follows:
> We sample multiple parallel attempts with the scaffold above
> We discard patches that break the visible regression tests in the repository, similar to the rejection sampling approach adopted by Agentless; note no hidden test information is used.
> We then rank the remaining attempts with a scoring model similar to our results on GPQA and AIME described in our research post and choose the best one for the submission.
> This results in a score of 70.3% on the subset of n=489 verified tasks which work on our infrastructure. Without this scaffold, Claude 3.7 Sonnet achieves 63.7% on SWE-bench Verified using this same subset.
By georgewsinger 2025-04-1619:461 reply Somehow completely missed that, thanks!
I think reading this makes it even clearer that the 70.3% score should just be discarded from the benchmarks. "I got a 7%-8% higher SWE benchmark score by doing a bunch of extra work and sampling a ton of answers" is not something a typical user is going to have already set up when logging onto Claude and asking it a SWE style question.
Personally, it seems like an illegitimate way to juice the numbers to me (though Claude was transparent with what they did so it's all good, and it's not uninteresting to know you can boost your score by 8% with the right tooling).
By ianbutler 2025-04-171:39 It isn't on the benchmark https://www.swebench.com/#verified
The one on the official leaderboard is the 63% score. Presumably because of all the extra work they had to do for the 70% score.
By awestroke 2025-04-1617:41 OpenAI have not shown themselves to be trustworthy, I'd take their claims with a few solar masses of salt
By swyx 2025-04-1617:50 they also gave more detail on their SWEBench scaffolding here https://www.latent.space/p/claude-sonnet
By lattalayta 2025-04-1617:412 reply I haven't been following them that closely, but are people finding these benchmarks relevant? It seems like these companies could just tune their models to do well on particular benchmarks
By mickael-kerjean 2025-04-171:52 The benchmark is something you can optimize for, doesn't mean it generalize well. Yesterday I tried for 2 hours to get claude to create a program that would extract data from a weird adobe file. 10$ later, the best I had is a program that was doing something like:
switch(testFile) { case "test1.ase": // run this because it's a particular case case "test2.ase": // run this because it's a particular case default: // run something that's not working but that's ok because the previous case should // give the right output for all the test files ... }By emp17344 2025-04-1617:56 That’s exactly what’s happening. I’m not convinced there’s any real progress occurring here.
By knes 2025-04-174:42 Right now the Swe-Bench leader Augment Agent still use Claude 3.7 in combo with o1. https://www.augmentcode.com/blog/1-open-source-agent-on-swe-...
The findings are open sourced on a repo too https://github.com/augmentcode/augment-swebench-agent
By thefourthchime 2025-04-1618:06 Also, if you're using Cursor AI, it seems to have much better integration with Claude where it can reflect on its own things and go off and run commands. I don't see it doing that with Gemini or the O1 models.
By ksec 2025-04-1713:12 I often wonder if we could expect that to reach 80% - 90% within next 5 years.

{kind=link}