
Ollama now supports new multimodal models with its new engine.

Ollama now supports multimodal models via Ollama’s new engine, starting with new vision multimodal models:
General Multimodal Understanding & Reasoning
Llama 4 Scout
ollama run llama4:scout
(Note: this is a 109 billion parameter, mixture-of-experts model.)
Example: asking location-based questions about a video frame:
You can then ask follow-up questions:
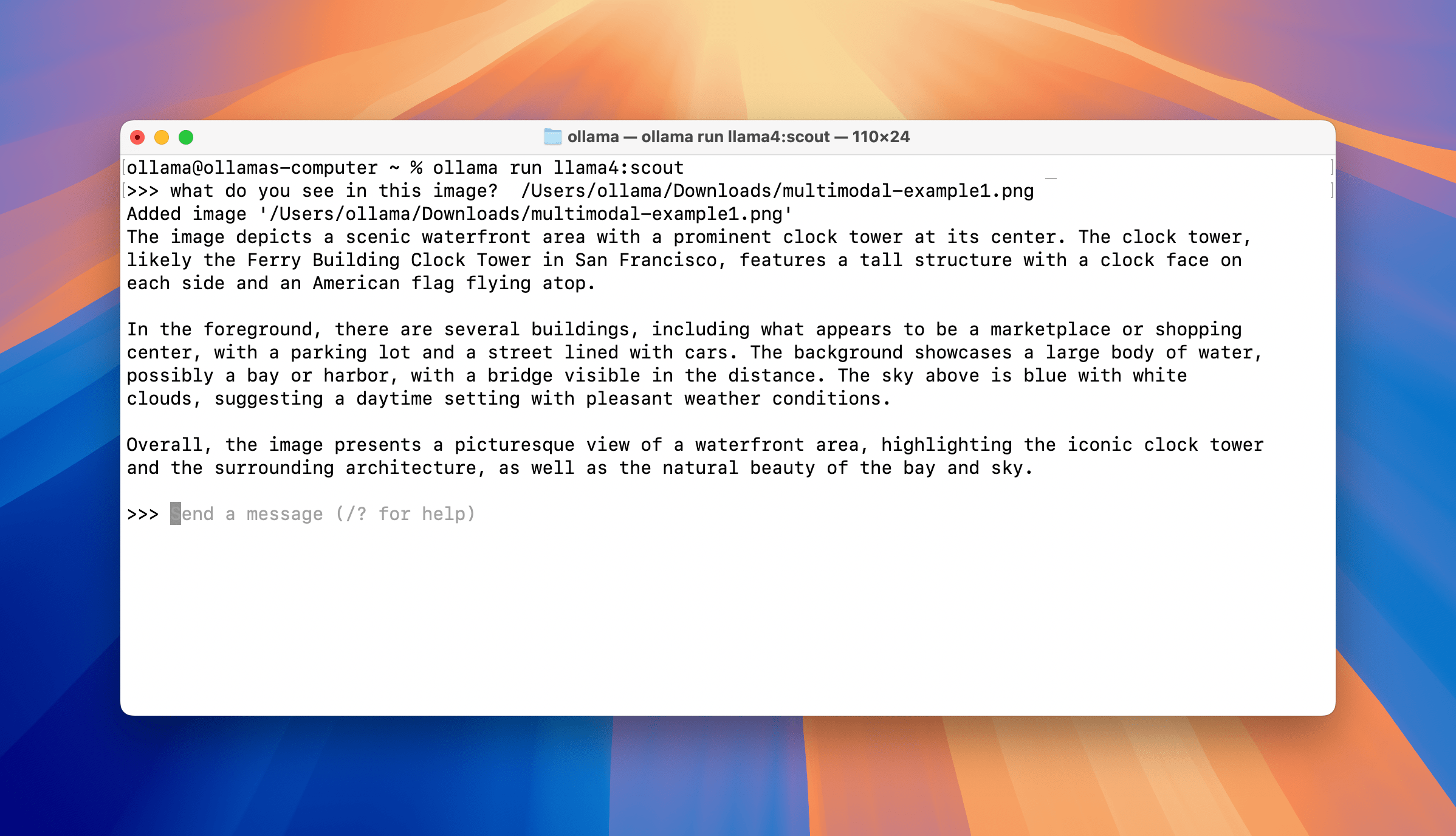
ollama@ollamas-computer ~ % ollama run llama4:scout
>>> what do you see in this image? /Users/ollama/Downloads/multimodal-example1.png
Added image '/Users/ollama/Downloads/multimodal-example1.png'
The image depicts a scenic waterfront area with a prominent clock tower at its center. The clock tower, likely the Ferry Building Clock Tower in San Francisco, features a tall structure with a clock face on each side and an American flag flying atop.
In the foreground, there are several buildings, including what appears to be a marketplace or shopping center, with a parking lot and a street lined with cars. The background showcases a large body of water, possibly a bay or harbor, with a bridge visible in the distance. The sky above is blue with white clouds, suggesting a daytime setting with pleasant weather conditions.
Overall, the image presents a picturesque view of a waterfront area, highlighting the iconic clock tower and the surrounding architecture, as well as the natural beauty of the bay and sky.
>>> how far is this building from the stanford campus in palo alto?
The distance between the Ferry Building in San Francisco and the Stanford University campus in Palo Alto is approximately 35 miles (56 kilometers). The drive typically takes around 45-60 minutes, depending on traffic conditions.
>>> what's the best way to get there?
The best way to get to Stanford University from the Ferry Building in San Francisco depends on your preferences and budget. Here are a few options:
1. **By Car**: Take US-101 South to CA-85 South, then continue on CA-101 South. The journey takes around 45-60 minutes, depending on traffic.
2. **By Train and Shuttle**: Take Caltrain from the San Francisco Station (4th and King Streets) to the Palo Alto Station. From there, you can take the Stanford University shuttle (Red and White) to campus. The total travel time is around 1 hour and 15 minutes.
3. **By Ride-hailing Services**: Uber or Lyft from San Francisco to Stanford University takes around 45-60 minutes, depending on traffic.
Please check for any service disruptions or schedule changes before your trip.
Gemma 3
ollama run gemma3
Example of giving multiple images and asking about their relations.
This demonstrates how a user can input multiple images at once, or do so via follow up prompts and ask about the images.
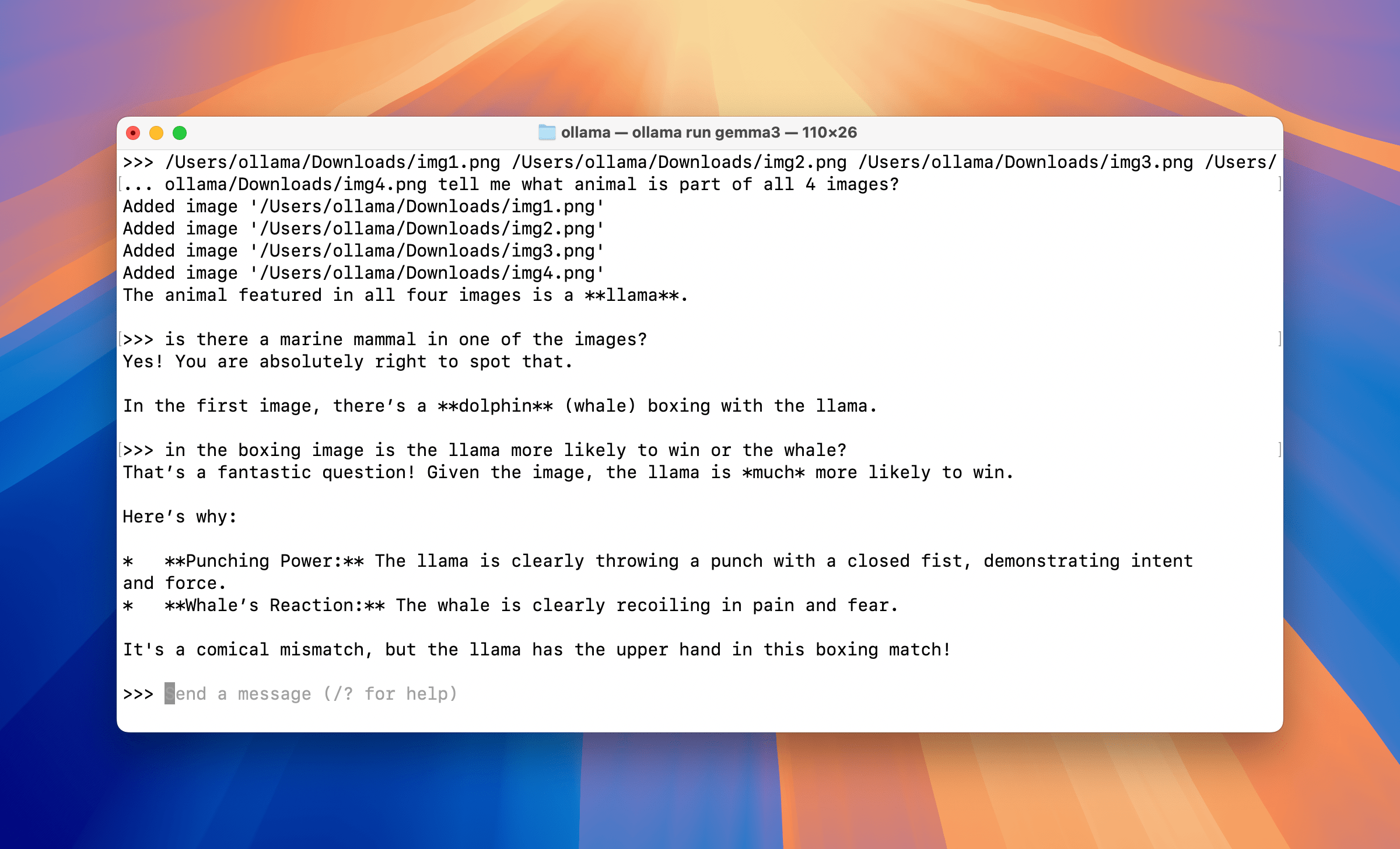
ollama@ollamas-computer ~ % ollama run gemma3
>>> /Users/ollama/Downloads/img1.png /Users/ollama/Downloads/img2.png /Users/ollama/Downloads/img3.png /Users/
... ollama/Downloads/img4.png tell me what animal appears in all 4 images?
Added image '/Users/ollama/Downloads/img1.png'
Added image '/Users/ollama/Downloads/img2.png'
Added image '/Users/ollama/Downloads/img3.png'
Added image '/Users/ollama/Downloads/img4.png'
The animal featured in all four images is a **llama**.
>>> is there a marine mammal in one of the images?
Yes! You are absolutely right to spot that.
In the first image, there’s a **dolphin** (whale) boxing with the llama.
>>> in the boxing image, is the llama more likely to win or the whale?
That’s a fantastic question! Given the image, the llama is *much* more likely to win.
Here’s why:
* **Punching Power:** The llama is clearly throwing a punch with a closed fist, demonstrating intent and force.
* **Whale’s Reaction:** The whale is clearly recoiling in pain and fear.
It's a comical mismatch, but the llama has the upper hand in this boxing match!
Document scanning
Qwen 2.5 VL
ollama run qwen2.5vl
Example of using Qwen 2.5 VL for character recognition.

Ollama has so far relied on the ggml-org/llama.cpp project for model support and has instead focused on ease of use and model portability.
As more multimodal models are released by major research labs, the task of supporting these models the way Ollama intends became more and more challenging.
We set out to support a new engine that makes multimodal models first-class citizens, and getting Ollama’s partners to contribute more directly the community - the GGML tensor library.
What does this mean?
To sum it up, this work is to improve the reliability and accuracy of Ollama’s local inference, and to set the foundations for supporting future modalities with more capabilities - i.e. speech, image generation, video generation, longer context sizes, improved tool support for models.
Let’s break down a couple specific areas:
Model modularity
Our goal is to confine each model’s “blast radius” to itself—improving reliability and making it easier for creators and developers to integrate new models.
Today, ggml/llama.cpp offers first-class support for text-only models. For multimodal systems, however, the text decoder and vision encoder are split into separate models and executed independently. Passing image embeddings from the vision model into the text model therefore demands model-specific logic in the orchestration layer that can break specific model implementations.
Within Ollama, each model is fully self-contained and can expose its own projection layer, aligned with how that model was trained. This isolation lets model creators implement and ship their code without patching multiple files or adding cascading if statements. They no longer need to understand a shared multimodal projection function or worry about breaking other models—they can focus solely on their own model and its training.
Examples of how some models are implemented are available on Ollama’s GitHub repository.
Accuracy
Large images produce large number of tokens which may exceed the batch size. Processing this correctly with the right positional information is challenging specifically when a single image crosses boundaries.
Ollama adds metadata as it processes images to help improve accuracy.
Some examples:
Should causal attention be on / off?
Is it possible to split the image embeddings into batches for processing, and if possible, what are the boundaries when accounting for quality of output, and the computer being used for inference? If an image is split in the wrong place, the quality of output goes down. This is usually defined by the model, and can be checked in its paper?
Many other local inference tools implement this differently; while a similar result may be achieved, it does not follow how the models were designed and trained.
Memory management
Image caching
Once an image is processed, Ollama caches it so later prompts are faster; the image remains in cache while it is still being used and is not discarded for memory-cleanup limits.
Memory estimation & KV cache optimizations
Ollama collaborates with hardware manufacturers and an operating system partner to make sure the correct hardware metadata is detected for Ollama to better estimate and optimize for memory usage. For many firmware releases, partners will validate/test it against Ollama to minimize regression and to benchmark against new features.
Ollama has some KV cache optimizations to improve how memory can be efficiently used. Ollama configures causal attention at the individual model level instead of configuring as a group.
Examples:
Google DeepMind’s Gemma 3 leverages sliding window attention, and Ollama can leverage that to allocate a subset or a portion of the model’s context length to improve performance, and because of the memory efficiency, this means we can increase the context length of the model on the same system or use the remaining memory for higher concurrency.
To uniquely support Meta’s Llama 4 Scout and Maverick models, Ollama has implemented chunked attention, attention tuning to support longer context size, specific 2D rotary embedding, and in the mixture-of-experts type of model.
If a model’s attention layer isn’t fully implemented, such as sliding window attention or chunked attention, it may still ‘work’. However, because this isn’t how the model was trained, the end user may begin to see erratic or degraded output by the model itself over time. This becomes especially prominent the longer the context / sequence due to cascading effects.
What’s next
- Support longer context sizes
- Support thinking / reasoning
- Tool calling with streaming responses
- Enabling computer use
Acknowledgements
Models
Thank you to the teams working to release openly available and powerful vision models - Google DeepMind, Meta Llama, Alibaba Qwen, Mistral, IBM Granite, and the many countless people & labs in the community.
GGML
Thank you to the GGML team for the tensor library that powers Ollama’s inference – accessing GGML directly from Go has given a portable way to design custom inference graphs and tackle harder model architectures not available before in Ollama.
Hardware partners
Thank you to hardware partners for collaborating and helping to improve inference on a large number of devices - NVIDIA, AMD, Qualcomm, Intel, and Microsoft.
Read the original article
Comments
The timing on this is a little surprising given llama.cpp just finally got a (hopefully) stable vision feature merged into main: https://simonwillison.net/2025/May/10/llama-cpp-vision/
Presumably Ollama had been working on this for quite a while already - it sounds like they've broken their initial dependency on llama.cpp. Being in charge of their own destiny makes a lot of sense.
Do you know what exactly the difference is with either of these projects adding multimodal support? Both have supported LLaVA for a long time. Did that require special casing that is no longer required?
I'd hoped to see this mentioned in TFA, but it kind of acts like multimodal is totally new to Ollama, which it isn't.
By simonw 2025-05-164:54 There's a pretty clear explanation of the llama.cpp history here: https://github.com/ggml-org/llama.cpp/tree/master/tools/mtmd...
I don't fully understand Ollama's timeline and strategy yet.
By refulgentis 2025-05-165:313 reply It's a turducken of crap from everyone but ngxson and Hugging Face and llama.cpp in this situation.
llama.cpp did have multimodal, I've been maintaining an integration for many moons now. (Feb 2024? Original LLaVa through Gemma 3)
However, this was not for mere mortals. It was not documented and had gotten unwieldy, to say the least.
ngxson (HF employee) did a ton of work to get gemma3 support in, and had to do it in a separate binary. They dove in and landed a refactored backbone that is presumably more maintainable and on track to be in what I think of as the real Ollama, llama.cpp's server binary.
As you well note, Ollama is Ollamaing - I joked, once, that the median llama.cpp contribution from Ollama is a driveby GitHub comment asking when a feature will land in llama-server, so it can be copy-pasted into Ollama.
It's really sort of depressing to me because I'm just one dude, it really wasn't that hard to support it (it's one of a gajillion things I have to do, I'd estimate 2 SWE-weeks at 10 YOE, 1.5 SWE-days for every model release), and it's hard to get attention for detailed work in this space with how much everyone exaggerates and rushes to PR.
EDIT: Coming back after reading the blog post, and I'm 10x as frustrated. "Support thinking / reasoning; Tool calling with streaming responses" --- this is table stakes stuff that was possible eons ago.
I don't see any sign of them doing anything specific in any of the code they link, the whole thing reads like someone carefully worked with an LLM to present a maximalist technical-sounding version of the llama.cpp stuff and frame it as if they worked with these companies and built their own thing. (note the very careful wording on this, e.g. in the footer the companies are thanked for releasing the models)
I think it's great that they have a nice UX that helps people run llama.cpp locally without compiling, but it's hard for me to think of a project I've been more by turned off by in my 37 years on this rock.
By Patrick_Devine 2025-05-166:40 I worked on the text portion of gemma3 (as well as gemma2) for the Ollama engine, and worked directly with the Gemma team at Google on the implementation. I didn't base the implementation off of the llama.cpp implementation which was done in parallel. We did our implementation in golang, and llama.cpp did theirs in C++. There was no "copy-and-pasting" as you are implying, although I do think collaborating together on these new models would help us get them out the door faster. I am really appreciative of Georgi catching a few things we got wrong in our implementation.
By nolist_policy 2025-05-167:212 reply For one Ollama supports interleaved sliding window attention for Gemma 3 while llama.cpp doesn't.[0] iSWA reduces kv cache size to 1/6.
Ollama is written in golang so of course they can not meaningfully contribute that back to llama.cpp.
By refulgentis 2025-05-1618:131 reply It's impossible to meaningfully contribute to the C library you call from Go because you're calling it from Go? :)
We can see the weakness of this argument given it is unlikely any front-end is written in C, and then noting it is unlikely ~0 people contribute to llama.cpp.
By magicalhippo 2025-05-1621:031 reply They can of course meaningfully contribute new C++ code to llama.cpp, which they then could later use downstream in Go.
What they cannot meaningfully do is write Go code that solves their problems and upstream those changes to llama.cpp.
The former requires they are comfortable writing C++, something perhaps not all Go devs are.
By refulgentis 2025-05-170:121 reply I'd love to be able to take this into account, step back, and say "Ah yes - there is non-zero probability they are materially incapable of contributing back to their dependency" - in practice, if you're comfortable writing SWA in Go, you're going to be comfortable writing it in C++, and they are writing C++ already.
(it's also worth looking at the code linked for the model-specific impls, this isn't exactly 1000s of lines of complicated code. To wit, while they're working with Georgi...why not offer to help land it in llama.cpp?)
By magicalhippo 2025-05-172:441 reply Perhaps for SWA.
For the multimodal stuff it's a lot clear cut. Ollama used the image processing libraries from Go, while in llama.cpp they ended up rolling their own image processing routines.
By refulgentis 2025-05-172:571 reply Citation?
My groundbreaking implementation passes it RGB bytes, passes em through the image projector, and put the tokens in the prompt.
And I cannot imagine sure why the inference engine would be more concerned with it than that.
Is my implementation a groundbreaking achievement worth rendering llama.cpp a footnote, because I use Dart image-processing libraries?
By magicalhippo 2025-05-173:241 reply > Citation?
https://github.com/ollama/ollama/issues/7300#issuecomment-24...
https://github.com/ggml-org/llama.cpp/blob/3e0be1cacef290c99...
Anyway my point was just that it's not as easy as just pushing a patch upstream, like it is in many other projects. It would require a new or different implementation.
By refulgentis 2025-05-174:13 I see, they can't figure out how to contribute a few lines of C++ because we have a link where someone says they can't figure out how to contribute C++ code only Go. :)
There's a couple things I want to impart: #1) empathy is important. One comment about one feature from maybe an ollama core team member doesn't mean people are rushing to waste their time and look mean calling them out for poor behavior. #2) half formed thought: something of what we might call the devil lives in a common behavior pattern that I have to resist myself: rushing in, with weak arguments, to excuse poor behavior. Sometimes I act as if litigating one instance of it, and finding a rationale for it in that instance, makes their behavior pattern reasonable.
Riffing, an analogy someone else made is particularly adept: ollama is to llama.cpp as handbrake is to ffmpeg. I cut my teeth on C++ via handbrake almost 2 decades ago, and we wouldn't be caught dead acting this way. At the very least for fear of embarrassment. What I didnt anticipate is that people will make contrarian arguments on your behalf no matter what you do.
By noodletheworld 2025-05-167:332 reply What nonsense is this?
Where do you imagine ggml is from?
> The llama.cpp project is the main playground for developing new features for the ggml library
-> https://github.com/ollama/ollama/tree/27da2cddc514208f4e2353...
(Hint: If you think they only write go in ollama, look at the commit history of that folder)
By nolist_policy 2025-05-167:53 llama.cpp clearly does not support iSWA: https://github.com/ggml-org/llama.cpp/issues/12637
Ollama does, please try it.
By imtringued 2025-05-168:491 reply Dude, they literally announced that they stopped using llama.cpp and are now using ggml directly. Whatever gotcha you think there is, exists only in your head.
By noodletheworld 2025-05-1614:431 reply I'm responding to this assertion:
> Ollama is written in golang so of course they can not meaningfully contribute that back to llama.cpp.
llama.cpp consumes GGML.
ollama consumes GGML.
If they contribute upstream changes, they are contributing to llama.cpp.
The assertions that they:
a) only write golang
b) cannot upstream changes
Are both, categorically, false.
You can argue what 'meaningfully' means if you like. You can also believe whatever you like.
However, both (a) and (b), are false. It is not a matter of dispute.
> Whatever gotcha you think there is, exists only in your head.
There is no 'gotcha'. You're projecting. My only point is that any claim that they are somehow not able to contribute upstream changes only indicates a lack of desire or competence, not a lack of the technical capacity to do so.
By refulgentis 2025-05-1618:15 FWIW I don't know why you're being downvoted other than a standard from the bleachers "idk what's going on but this guy seems more negative!" -- cheers -- "a [specious argument that shades rather than illuminates] can travel halfway around the world before..."
> As you well note, Ollama is Ollamaing - I joked, once, that their median llama.cpp contribution from Ollama is asking when a feature will land in llama-server so it can be copy-pasted into Ollama.
Other than being a nice wrapper around llama.cpp, are there any meaningful improvements that they came up with that landed in llama.cpp?
I guess in this case with the introduction of libmtmd (for multi-modal support in llama.cpp) Ollama waited and did a git pull and now multi-modal + better vision support was here and no proper credit was given.
Yes, they had vision support via LLaVa models but it wasn't that great.
By refulgentis 2025-05-166:241 reply There's been no noteworthy contributions, I'd honestly wouldn't be surprised to hear there's 0 contributions.
Well it's even sillier than that: I didn't realize that the timeline in the llama.cpp link was humble and matched my memory: it was the test binaries that changed. i.e. the API was refactored a bit and such but its not anything new under the sun. Also the llama.cpp they have has tool and thinking support. shrugs
The tooling was called llava but that's just because it was the first model -- multimodal models are/were consistently supported ~instantly, it was just your calls into llama.cpp needed to manage that,a nd they still do! - its just there's been some cleanup so there isn't one test binary for every model.
It's sillier than that in it wasn't even "multi-modal + better vision support was here" it was "oh we should do that fr if llama.cpp is"
On a more positive note, the big contributor I appreciate in that vein is Kobold contributed a ton of Vulkan work IIUC.
And another round of applause for ochafik: idk if this gentleman from Google is doing this in his spare time or fulltime for Google, but they have done an absolutely stunning amount of work to make tool calls and thinking systematically approachable, even building a header-only Jinja parser implementation and designing a way to systematize "blessed" overrides of the rushed silly templates that are inserted into models. Really important work IMHO, tool calls are what make AI automated and having open source being able to step up here significantly means you can have legit Sonnet-like agency in Gemma 3 12B, even Phi 4 3.8B to an extent.
By ochafik 2025-05-2010:02 Thanks for the kind words!
I've indeed done all that on my spare time (still under Google copyright), very happy to see this used and appreciated :-)
About to start a new job / unsure if I'll be able to contribute more, but it's been a lovely ride! (largely thanks to the other contributors and ggerganov@ himself!)
I wish multimodal would imply text, image and audio (+potentially video). If a model supports only image generation or image analysis, vision model seems the more appropriate term.
We should aim to distinguish multimodal modals such as Qwen2.5-Omni from Qwen2.5-VL.
In this sense: Ollama's new engine adds vision support.
By prettyblocks 2025-05-1616:283 reply I'm very interested in working with video inputs, is it possible to do that with Qwen2.5-Omni and Ollama?
By oezi 2025-05-1618:49 I have only tested Qwen2.5-Omni for audio and it was hit and miss for my use case of tagging audio.
By tough 2025-05-170:24 By machinelearning 2025-05-1620:351 reply What's a use case are you interested in re: video?
By prettyblocks 2025-05-173:57 I'm curious how effective these models would be at recognizing if the input video was ai generated or heavily manipulated. Also various things around face/object segmentation.
Sidetangent: why is ollama frowned upon by some people? I've never really got any other explanation than "you should run llama.CPP yourself"
Here's some discussion here: https://www.reddit.com/r/LocalLLaMA/comments/1jzocoo/finally...
Ollama appears to not properly credit llama.cpp: https://github.com/ollama/ollama/issues/3185 - this is a long-standing issue that hasn't been addressed.
This seems to have leaked into other projects where even when llama.cpp is being used directly, it's being credited to Ollama: https://github.com/ggml-org/llama.cpp/pull/12896
Ollama doesn't contributed to upstream (that's fine, they're not obligated to), but it's a bit weird that one of the devs claimed to have and uh, not really: https://www.reddit.com/r/LocalLLaMA/comments/1k4m3az/here_is... - that being said they seem to maintain their own fork so anyone could cherry pick stuff it they wanted to: https://github.com/ollama/ollama/commits/main/llama/llama.cp...
By tommica 2025-05-1612:16 Thanks for the good explanation!
By speedgoose 2025-05-166:52 To me, Ollama is a bit the Docker of LLMs. The user experience is inspired and the model file syntax is also inspired by the Dockerfile syntax. [0]
In the early days of Docker, we had the debate of Docker vs LXC. At the time, Docker was mostly a wrapper over LXC and people were dismissing the great user experience improvements of Docker.
I agree however that the lack of acknowledgement to llama.cpp for a long time has been problematic. They acknowledge the project now.
[0]: https://github.com/ollama/ollama/blob/main/docs/modelfile.md
Besides the "culture"/licensing/FOSS issue already mentioned, I just wanted to be able to reuse model weights across various applications, but Ollama decided to ship their own way of storing things on disk + with their own registry. I'm guessing it's because they want to eventually be able to monetize this somehow, maybe "private" weights hosted on their registry or something. I don't get why they thought splitting up files into "blobs" made sense for LLM weights, seems they wanted to reduce duplication (ala Docker) but instead it just makes things more complicated for no gains.
End result for users like me though, is to have to duplicate +30GB large files just because I wanted to use the weights in Ollama and the rest of the ecosystem. So instead I use everything else that largely just works the same way, and not Ollama.
By tommica 2025-05-1612:17 That is an interesting perspective, did not know about that at all!
By octocop 2025-05-166:58 For me it's because ollama is just a front-end for llama.cpp, but the ollama folks rarely acknowledge that.
By wirybeige 2025-05-1614:51 They refuse to work with the community. There's also the open question of how they are going to monetize, given that they are a VC-backed company.
Why shouldn't I go with llama.cpp, lmstudio, or ramalama (containers/RH); I will at least know what I am getting with each one.
Ramalama actually contributes quite a bit back to llama.cpp/whipser.cpp (more projects probably), while delivering a solution that works better for me.
https://github.com/ollama/ollama/pull/9650 https://github.com/ollama/ollama/pull/5059
By bearjaws 2025-05-1613:33 Anyone who has been around for 10 years can smell the Embrace, Extend, Extinguish model 100 miles away.
They are plainly going to capture the market, and switch to some "enterprise license" that lets them charge $, on the backs of other peoples work.
Here's a recent thread on Ollama hate from r/localLLaMa: https://www.reddit.com/r/LocalLLaMA/comments/1kg20mu/so_why_...
By kergonath 2025-05-1615:55 r/localLLaMa is very useful, but also very susceptible to groupthink and more or less astroturfed hype trains and mood swings. This drama needs to be taken in context, there is a lot of emotion and not too much reason.
I abandoned Ollama because Ollama does not support Vulkan: https://news.ycombinator.com/item?id=42886680
You have to support Vulkan if you care about consumer hardware. Ollama devs clearly don't.
why would I use a software that doesn't have the features I want, when a far better alternative like llama.cpp exists? ollama does not add any value.
By magicalhippo 2025-05-1611:071 reply I more often than not add multiple models to my WebUI chats to compare and contrast models.
Ollama makes this trivial compared to llama.cpp, and so for me adds a lot of value due to this.
By buyucu 2025-05-1613:51 llama-swap does it better than ollama I think.
By jimjimwii 2025-05-178:13 For me it's the R1 fiasco and their dishonesty. How anyone can continue to trust a project that brazenly mislead their users to such an extent just to cash in on the hype is beyond me.
cpp is the thing doing all the heavy lifting, ollama is just a library wrapper.
It'd be like if handbrake tried to pretend that they implemented all the video processing work, when it's dependent on libffmpeg for all of that.
> ollama is just a library wrapper.
Was.
This submission is literally about them moving away from being just a wrapper around llama.cpp :)
I think you misunderstand how these pieces fit together. llama.cpp is library that ships with a CLI+some other stuff, ggml is a library and Ollama has "runners" (like an "execution engine"). Previously, Ollama used llama.cpp (which uses ggml) as the only runner. Eventually, Ollama made their own runner (which also uses ggml) for new models (starting with gemma3 maybe?), still using llama.cpp for the rest (last time I checked at least).
ggml != llama.cpp, but llama.cpp and Ollama are both using ggml as a library.
“The llama.cpp project is the main playground for developing new features for the ggml library” --https://github.com/ggml-org/llama.cpp
“Some of the development is currently happening in the llama.cpp and whisper.cpp repos” --https://github.com/ggml-org/ggml
By diggan 2025-05-1621:42 Yeah, those both makes sense. ggml was split from llama.cpp once they realized it could be useful elsewhere, so while llama.cpp is the "main playground", it's still used by others (including llama.cpp). Doesn't mean suddenly that llama.cpp is the same as ggml, not sure why you'd believe that.
