
Amazon Web Services (AWS) strives to deliver reliable services that customers can trust completely. This requires maintaining the highest standards of security, durability, integrity, and availability—with systems correctness serving as the cornerstone for achieving these priorities. An April 2015 article published in Communications of the ACM, titled “How Amazon Web Services Uses Formal Methods,” highlighted the approach for ensuring the correctness of critical services that have since become among the most widely used by AWS customers.21
Central to this approach was TLA+,14 a formal specification language developed by Leslie Lamport. Our experience at AWS with TLA+ revealed two significant advantages of applying formal methods in practice. First, we could identify and eliminate subtle bugs early in development—bugs that would have eluded traditional approaches such as testing. Second, we gained the deep understanding and confidence needed to implement aggressive performance optimizations while maintaining systems correctness.
Moreover, 15 years ago, AWS’s software testing practice relied primarily on build-time unit testing, often against mocks, and limited deployment-time integration testing. Since then, we have significantly evolved our correctness practices, integrating both formal and semi-formal approaches into the development process. As AWS has grown, formal methods have become increasingly valuable—not only for ensuring correctness but also for performance improvements, particularly in verifying the correctness of both low- and high-level optimizations. This systematic approach toward systems correctness has become a force multiplier at AWS’s scale, enabling faster development cycles through improved developer velocity while delivering more cost-effective services to customers.
This article surveys the portfolio of formal methods used across AWS to deliver complex services with high confidence in its correctness. We consider an umbrella definition of formal methods that encompasses these rigorous techniques—from traditional formal approaches (such as theorem proving,7,10 deductive verification,18 and model checking8,14) to more lightweight semi-formal approaches (such as property-based testing,6,19 fuzzing,9 and runtime monitoring11).
As the use of formal methods was expanded beyond the initial teams at AWS in the early 2010s, we discovered that many engineers struggled to learn and become productive with TLA+. This difficulty seemed to stem from TLA+’s defining feature: It is a high-level, abstract language that more closely resembles mathematics than the imperative programming languages most developers are familiar with. While this mathematical nature is a significant strength of TLA+, and we continue to agree with Lamport’s views on the benefits of mathematical thinking,15 we also sought a language that would allow us to model check (and later prove) key aspects of systems design while being more approachable to programmers.
We found this balance in the P programming language.8 P is a state-machine-based language for modeling and analysis of distributed systems. Using P, developers model their system designs as communicating state machines, a mental model familiar to Amazon’s developer population—most of whom develop systems based on microservices and service-oriented architectures (SOAs). P has been developed at AWS since 2019 and is maintained as a strategic open source project.22 Teams across AWS that build some of its flagship products—from storage (for example, Amazon S3, EBS), to databases (for example, Amazon DynamoDB, MemoryDB, Aurora), to compute (for example, EC2, IoT)—have been using P to reason about the correctness of their system designs.
For example, P was used in migrating Simple Storage Service (S3) from eventual to strong read-after-write consistency.1 A key component of S3 is its index subsystem, an object metadata store that enables fast data lookups. To achieve strong consistency, the S3 team had to make several nontrivial changes to the S3 index protocol stack.25 Because these changes were difficult to get right at S3 scale, and the team wanted to deliver strong consistency with high confidence in correctness, they used P to formally model and validate the protocol design. P helped eliminate several design-level bugs early in the development process and allowed the team to deliver risky optimizations with confidence, as they could be validated using model checking.
In 2023, the P team at AWS built PObserve, which provides a new tool for validating the correctness of distributed systems both during testing and in production. With PObserve, we take structured logs from the execution of distributed systems and validate post hoc that they match behaviors allowed by the formal P specification of the system. This allows for bridging the gap between the P specification of the system design and the production implementation (typically in languages like Rust or Java). While there are significant benefits from verifying protocols at design time, runtime monitoring of the same properties for the implementation makes the investment in formal specification much more valuable and addresses classic concerns with the deployment of formal methods in practice (that is, connecting design-time validation with system implementation).
Another way that AWS has brought formal methods closer to its engineering teams is through the adoption of lightweight formal methods.
Property-based testing. The most notable single example of leveraging lightweight formal methods is in Amazon S3’s ShardStore, where the team used property-based testing throughout the development cycle both to test correctness and to speed up development (described in detail by Bornholt, et al.4). The key idea in their approach was combining property-based testing with developer-provided correctness specifications, coverage-guided fuzzing (an approach where the distribution of inputs is guided by code coverage metrics), failure injection (where hardware and other system failures are simulated during testing), and minimization (where counterexamples are automatically reduced to aid human-guided debugging).
Deterministic simulation. Another lightweight method widely used at AWS is deterministic simulation testing, in which a distributed system is executed on a single-threaded simulator with control over all sources of randomness, such as thread scheduling, timing, and message delivery order. Tests are then written for particular failure or success scenarios, such as the failure of a participant at a particular stage in a distributed protocol. The nondeterminism in the system is controlled by the test framework, allowing developers to specify orderings they believe are interesting (such as ones that have caused bugs in the past). The scheduler in the testing framework can also be extended for fuzzing of orderings or exploring all possible orderings to be tested.
Deterministic simulation testing moves testing of system properties, like behavior under delay and failure, closer to build time instead of integration testing. This accelerates development and provides for more complete behavioral coverage during testing. Some of the work done at AWS on build-time testing of thread ordering and systems failures has been open sourced as part of the shuttlea and turmoilb projects.
Continuous fuzzing or random test-input generation. Continuous fuzzing, especially coverage-guided scalable test-input generation, is also effective for testing systems correctness at integration time. During the development of Amazon Aurora’s data-sharding feature (Aurora Limitless Database3), for example, we made extensive use of fuzzing to test two key properties of the system. First, by fuzzing SQL queries (and entire transactions), we validated that the logic partitioning SQL execution over shards is correct. Large volumes of random SQL schemas, datasets, and queries are synthesized and run through the engines under test, and the results compared with an oracle based on the non-sharded version of the engine (as well as other approaches to validation, like those pioneered by SQLancer23).
Fuzzing, combined with fault-injection testing, is also useful for testing other aspects of database correctness such as atomicity, consistency, and isolation. In database testing, transactions are automatically generated, their correct behavior is defined using a formally specified correctness oracle, and then all possible interleaving of transactions and statements within the transaction is executed against the system under test. We also use post hoc validation of properties such as isolation (following approaches such as Elle13).
In early 2021, AWS launched Fault Injection Service (FIS)2 with the goal of making testing based on fault injection accessible to a wide range of AWS customers. FIS allows customers to inject simulated faults, from API errors to I/O pauses and failed instances, into test or production deployments of their infrastructure on AWS. Injecting faults allows customers to validate that the resiliency mechanisms they have built into their architectures (such as failovers and health checks) actually improve availability and do not introduce correctness problems. Fault-injection testing based on FIS is widely used by AWS customers and internally within Amazon. For example, Amazon.com ran 733 FIS-based fault-injection experiments in preparation for Prime Day 2024.
In 2014, Yuan et al. found that 92% of catastrophic failures in tested distributed systems were triggered by incorrect handling of nonfatal errors. Many distributed-systems practitioners who were told about this research were surprised the percentage was not higher. Happy-case catastrophic failures are rare simply because the happy case of systems is executed often, tested better (both implicitly and explicitly), and is significantly simpler than the error cases. Fault-injection testing and FIS make it much easier for practitioners to test the behavior of their systems under faults and failures, closing the gap between happy-case and error-case bug density.
While fault injection is not considered a formal method, it can be combined with formal specifications. Defining the expected behavior using a formal specification, and then comparing results during and after fault injection to the specified behavior, allows for catching a lot more bugs than simply checking for errors in metrics and logs (or having a human look and say, “Yup, that looks about right”).
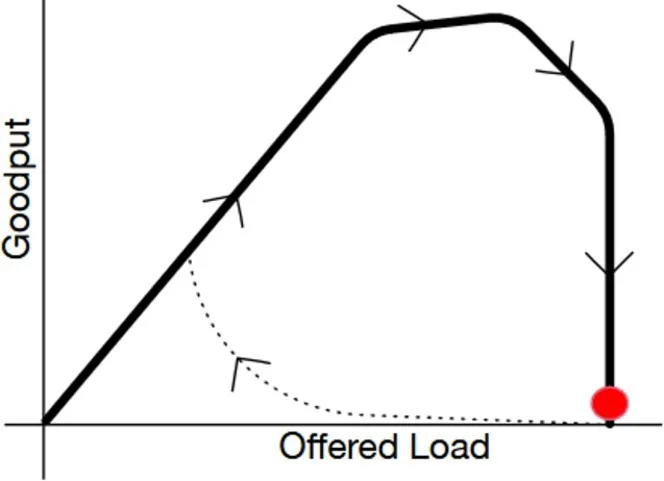
Over the past decade, there has been an emerging interest in a particular class of systems failure: those where some triggering event (like an overload or a cache emptying) causes a distributed system to enter a state where it does not recover without intervention (such as reducing load below normal). This class of failures, dubbed metastable failures,5 is one of the most important contributors to unavailability in cloud systems. The figure, adapted from Bronson et al.,5 illustrates a common type of metastable behavior: Load increases on the system are initially met with increasing goodput, followed by saturation, followed by congestion and goodput dropping to zero (or near zero). From there, the system cannot return to healthy state by slightly reducing load. Instead, it must follow the dotted line and may not recover until load is significantly reduced. This type of behavior is present even in simple systems. For example, it can be triggered in most systems with timeout-and-retry client logic.
ACM encourages its members to take a direct hand in shaping the future of the association. There are more ways than ever to get involved.
Get InvolvedBy opening CACM to the world, we hope to increase engagement among the broader computer science community and encourage non-members to discover the rich resources ACM has to offer.
Learn More
{kind=link}