
File parsers in Go contain unexpected behaviors that can lead to serious security vulnerabilities. This post examines how JSON, XML, and YAML parsers in Go handle edge cases in ways that have…
In Go applications, parsing untrusted data creates a dangerous attack surface that’s routinely exploited in the wild. During our security assessments, we’ve repeatedly exploited unexpected behaviors in Go’s JSON, XML, and YAML parsers to bypass authentication, circumvent authorization controls, and exfiltrate sensitive data from production systems.
These aren’t theoretical issues—they’ve led to documented vulnerabilities like CVE-2020-16250 (a Hashicorp Vault authentication bypass found by Google’s Project Zero) and numerous high-impact findings in our client engagements.
This post contextualizes these unexpected parser behaviors through three attack scenarios that every security engineer and Go developer should understand:
- (Un)Marshaling unexpected data: How Go parsers can expose data that developers intended to be private
- Parser differentials: How discrepancies between parsers enable attackers to bypass security controls when multiple services parse the same input
- Data format confusion: How parsers process cross-format payloads with surprising and exploitable results
We’ll demonstrate each attack scenario with real-world examples and conclude with concrete recommendations for configuring these parsers more securely, including strategies to compensate for security gaps in Go’s standard library.
Below is a summary of the surprising behaviors we’ll examine, with indicators showing their security status:
- 🟢 Green: Secure by default
- 🟠 Orange: Insecure by default but configurable
- 🔴 Red: Insecure by default with no secure configuration options
Parsing in Go
Let’s examine how Go parses JSON, XML, and YAML. Go’s standard library provides JSON and XML parsers but not a YAML parser, for which there are several third-party alternatives. For our analysis, we’ll focus on:
We’ll use JSON in our following examples, but all three parsers have APIs equivalent to the ones we’ll see.
At their core, these parsers provide two primary functions:
Marshal(serialize): Converts Go structs into their respective format stringsUnmarshal(deserialize): Converts format strings back into Go structs
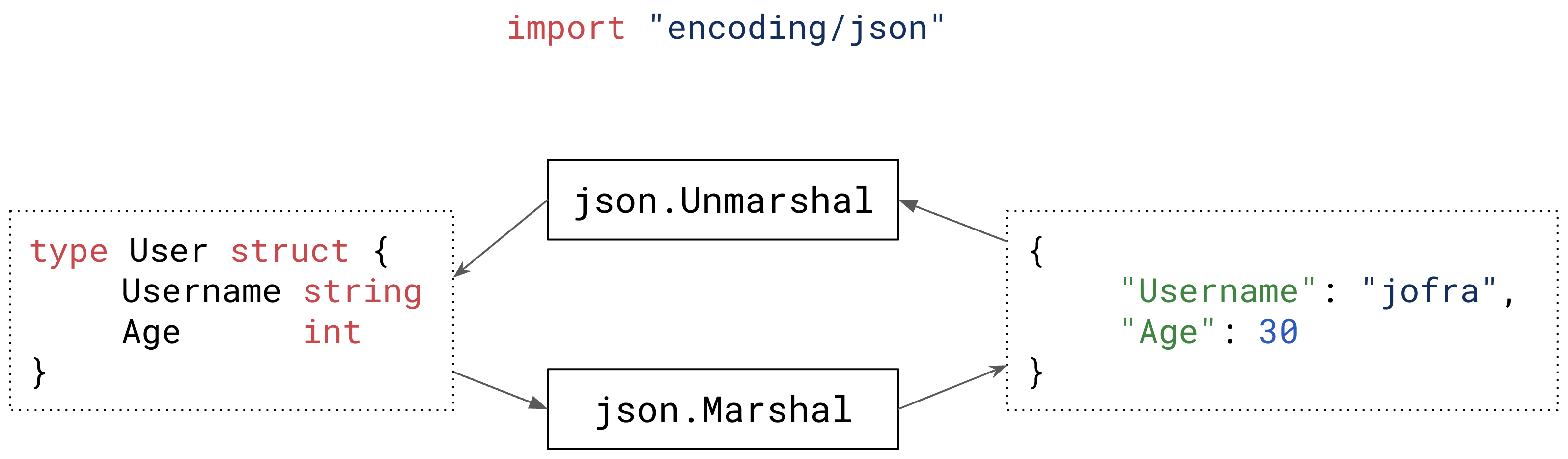
Go uses struct field tags to allow customization of how parsers should handle individual fields. These tags consist of:
- A key name for serialization/deserialization
- Optional comma-separated directives that modify behavior (e.g., the
omitemptytag option tells the JSON serializer not to include the field in the JSON output string if it is empty)
type User struct {
Username string `json:"username_json_key,omitempty"`
Password string `json:"password"`
IsAdmin bool `json:"is_admin"`
}To unmarshal a JSON string into the User structure shown above, we must use the username_json_key key for the Username field, password for the Password field, and is_admin for the IsAdmin field.
u := User{}
_ = json.Unmarshal([]byte(`{
"username_json_key": "jofra",
"password": "qwerty123!",
"is_admin": "false"
}`), &u)
fmt.Printf("Result: %#v\n", u)
// Result: User{Username:"jofra", Password:"qwerty123!", IsAdmin:false}These parsers also offer stream-based alternatives that operate on io.Reader interfaces rather than byte slices. This API is ideal for parsing streaming data such as HTTP request bodies, making it a preferred choice in HTTP request handling.
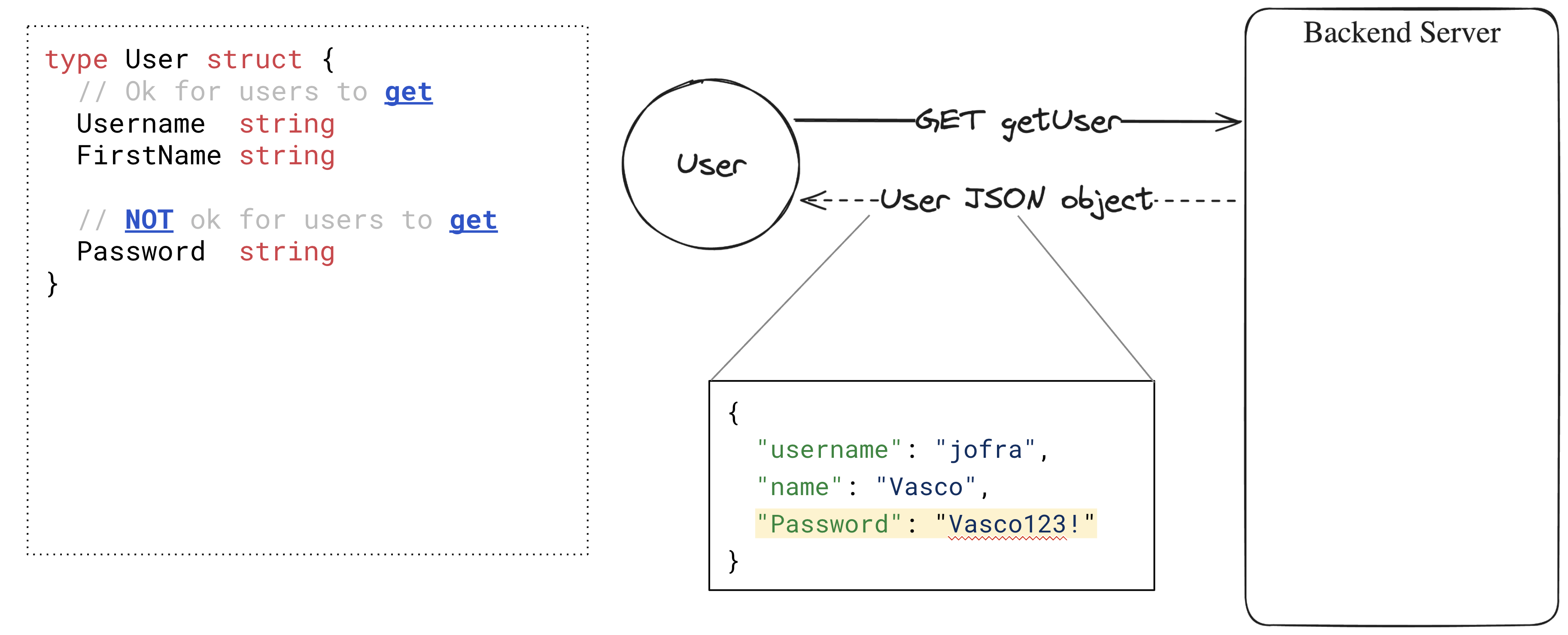
How can we instruct the parsers not to marshal or unmarshal a field?
Fields without a tag
Let’s first see what happens if you don’t set a JSON tag.
type User struct {
Username string
}In this case, you can unmarshal the Username field with its name, as shown below.
_ = json.Unmarshal([]byte(`{"Username": "jofra"}`), &u)
// Result: User{Username:"jofra"}This is well documented, and most Go devs are aware of it. Let’s look at another example:
type User struct {
Username string `json:"username,omitempty"`
Password string `json:"password,omitempty"`
IsAdmin bool
}Is it evident that the IsAdmin field above would be unmarshaled? A less senior or distracted developer could assume it would not and introduce a security vulnerability.
If you’d like to scan your codebase for this pattern, where some but not all fields have a JSON, XML, or YAML tag, you can use the following Semgrep rule. This rule is not on the our collection of rules exposed on the Semgrep registry because, depending on the codebase, it is likely to produce many false positives.
rules:
- id: unmarshaling-tag-in-only-some-fields
message: >-
Type $T1 has fields with json/yml/xml tags on some but not other fields. This field can still be (un)marshaled using its name. To prevent a field from being (un)marshaled, use the - tag.
languages: [go]
severity: WARNING
patterns:
- pattern-inside: |
type $T1 struct {
...
$_ $_ `$TAG`
...
}
# This regex attempts to remove some false positives such as structs declared inside structs
- pattern-regex: >-
^[ \t]+[A-Z]+[a-zA-Z0-9]*[ \t]+[a-zA-Z0-9]+[^{`\n\r]*$
- metavariable-regex:
metavariable: $TAG
regex: >-
.*(json|yaml|xml):"[^,-]Misusing the - tag
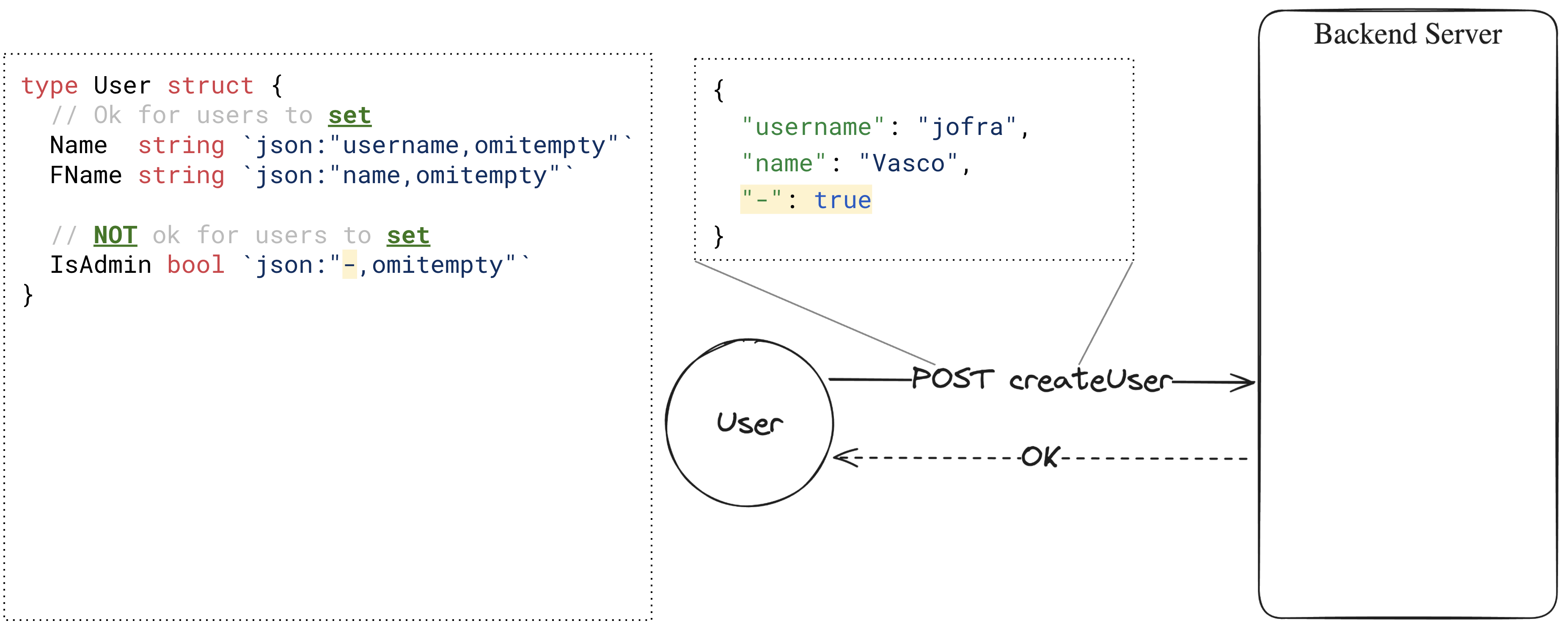
To tell the parser not to (un)marshal a specific field, we must add the special - JSON tag!
type User struct {
Username string `json:"username,omitempty"`
Password string `json:"password,omitempty"`
IsAdmin bool `json:"-,omitempty"`
}Let’s try it!
_ = json.Unmarshal([]byte(`{"-": true}`), &u)
// Result: main.User{Username:"", Password:"", IsAdmin:true}Oh, whoops, we were still able to set the IsAdmin field. We copy-pasted the ,omitempty part by mistake, which caused the parser to look for the - key in the provided JSON input. I searched for this pattern on the top 1,000 Go repositories by stars on GitHub and, among a few others, I found and reported these two results, which are now fixed:
While this behavior is error prone with minimal benefits (having the ability to name a field -), it is documented in the JSON package documentation:
As a special case, if the field tag is “-”, the field is always omitted. Note that a field with name “-” can still be generated using the tag “-,”.
The XML and YAML parsers operate similarly, with one key difference: the XML parser treats the <-> tag as invalid. To resolve this, we must prefix the - symbol with an XML namespace, such as <A:->.

Ok, ok, let’s do it right this time.
type User struct {
Username string `json:"username,omitempty"`
Password string `json:"password,omitempty"`
IsAdmin bool `json:"-"`
}Finally! Now, there is no way for the IsAdmin field to be unmarshaled.
But I hear you ask: How can these misconfigurations lead to security vulnerabilities? The most common way is, like in our example, using -,... as the JSON tag for a field such as IsAdmin–a field the user should not control. This is a hard bug to detect with unit tests because unless you have an explicit test that unmarshals an input with the - key and detects if any field was written to, you won’t detect it. You need your IDE or an external tool to detect it.
We created a public Semgrep rule to help you find similar issues in your codebases. Try it with semgrep -c r/trailofbits.go.unmarshal-tag-is-dash!
Misusing omitempty
Another very simple misconfiguration we’ve found before was a developer mistakenly setting the field name to omitempty.
type User struct {
Username string `json:"omitempty"`
}
u := User{}
_ = json.Unmarshal([]byte(`{"omitempty": "a_user"}`), &u)
// Result: User{Username:"a_user"}If you set the JSON tag to omitempty, the parser will use omitempty as the field’s name (as expected). Of course, some developers have tried to use this to set the omitempty option in the field while keeping the default name. I searched the top 1,000 Go repositories for this pattern and found these results:
In these cases, the developer often wanted to set the tag to json:",omitempty", which would keep the default name, and add the omitempty tag option.
Contrary to the previous example, this one is unlikely to have a security impact and should be easy to detect with tests because any attempt to serialize or deserialize input with the expected field name will fail. However, as we can see, it still shows up even in popular open-source repositories. We created a public Semgrep rule to help you find similar issues in your codebases. Try it with semgrep -c r/trailofbits.go.unmarshal-tag-is-omitempty!
Attack scenario 2: Parser differentials
What can happen if you parse the same input with different JSON parsers and they disagree on the result? More specifically, which behaviors in Go parsers allow attackers to trigger these discrepancies “reliably”?
As an example, let’s use the following application using a microservice architecture with:
- A Proxy Service that receives all user requests
- An Authorization Service called by the Proxy Service to determine if the user has sufficient permission to complete their request
- Multiple business logic services called by the Proxy Service to perform the business logic
In this first flow, a regular, non-admin user attempts to perform a UserAction, an action they are allowed to perform.
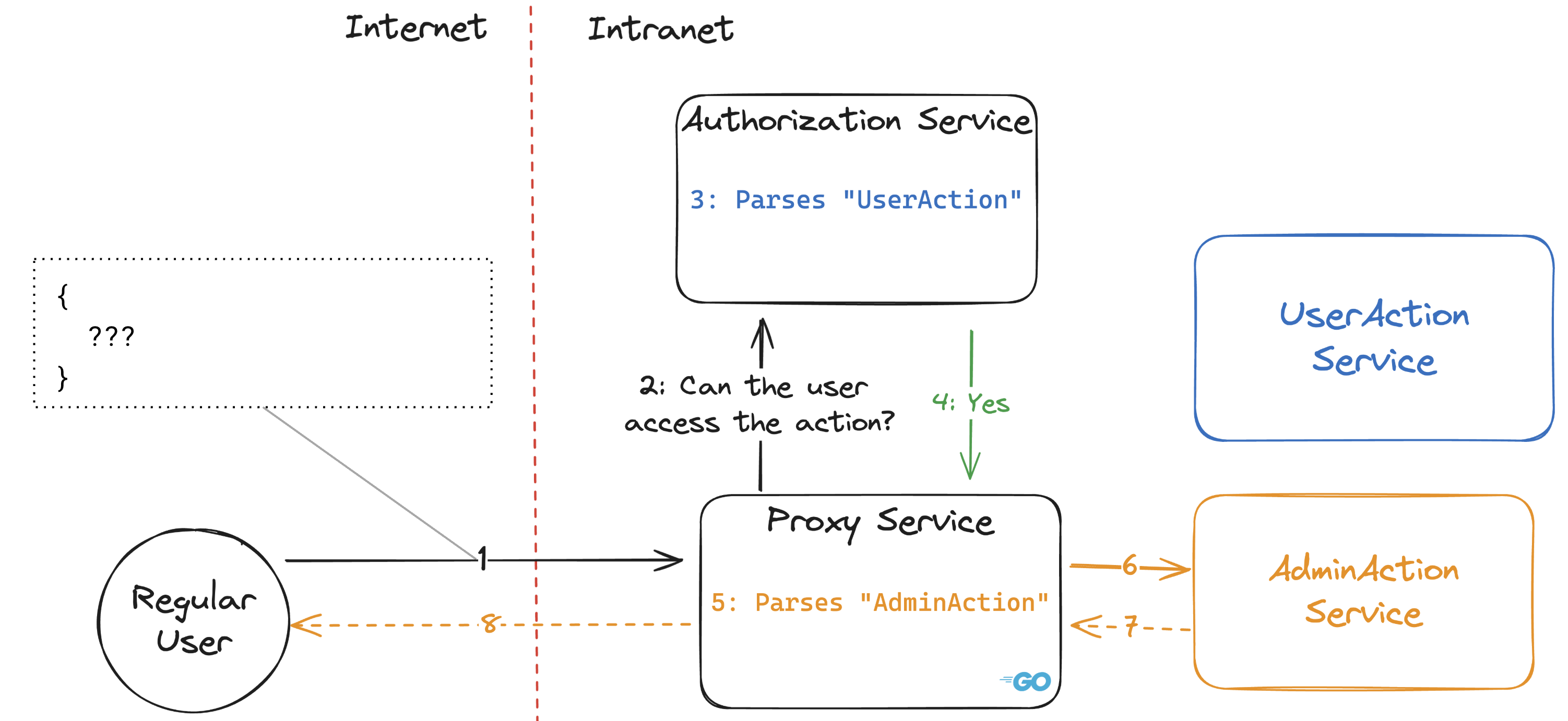
The Authorization Service, written in a different programming language or using a non-default Go parser, will parse UserAction and grant the user permission to perform the operation, while the Proxy Service, using Go’s default parser, will parse AdminAction and proxy it to the incorrect service. The remaining question is: Which payloads can we use to achieve this behavior?
This is a common architecture we’ve seen multiple times during our audits, and against which we’ve found authentication bypasses because of the problems we’ll describe below. Other examples exist, but most follow the same pattern: the component that does security checks and the component that performs the actions differ in their view of the input data. Here are some of those examples in a variety of scenarios:
Duplicate fields
The first differential attack vector we’ll explore is duplicate keys. What happens when your JSON input has the same key twice? It depends on the parser!
In Go, the JSON parser will always take the last one. There is no way to prevent this behavior.
_ = json.Unmarshal([]byte(`{
"action": "Action1",
"action": "Action2"
}`), &a)
// Result: ActionRequest{Action:"Action2"}This is the default behavior of most parsers. However, as shown in the JSON interoperability vulnerabilities blog post from Bishop Fox, seven out of the 49 parsers tested take the first key:
- Go: jsonparser and gojay
- C++: rapidjson
- Java: json-iterator
- Elixir: Jason and Poison
- Erlang: jsone
None of these are the most common JSON parsers in their corresponding languages, even though some are common alternatives.
So, if our Proxy Service uses the Go JSON parser and the Authorization Service uses one of these parsers, we get our discrepancy, as shown in the figure below.

While not ideal, at least this behavior is consistent with the most commonly used JSON and XML parsers. Let’s now take a look at a much worse behavior that will almost always get you a discrepancy between Go’s default parser and any other parser.
Case insensitive key matching
Go’s JSON parser parses field names case-insensitively. Whether you write action action, ACTION, or aCtIoN, the parser treats them as identical!
_ = json.Unmarshal([]byte(`{
"aCtIoN": "Action2"
}`), &a)
// Result: ActionRequest{Action:"Action2"}This is documented but is very unintuitive, there’s no way to disable it, and almost no other parser has this behavior.
To make this worse, as we saw above, you can have duplicate fields, and the latter one is still chosen, eVeN wHeN tHe cAsInG dOeS nOt mAtCh.
_ = json.Unmarshal([]byte(`{
"action": "Action1",
"aCtIoN": "Action2"
}`), &a)
// Result: ActionRequest{Action:"Action2"}This is against the documentation, which says:
“To unmarshal JSON into a struct, Unmarshal matches incoming object keys to the keys used by Marshal (either the struct field name or its tag), preferring an exact match but also accepting a case-insensitive match.”
You can even use Unicode characters! In the example below, we’re using ſ (the unicode character named Latin small letter long s) as an s, and K (the unicode character for the Kelvin sign) as a k. From our testing of the JSON library code that does the comparison, only these two unicode characters match ASCII characters.
type ActionRequest struct {
Action string `json:"aktions"`
}
a := ActionRequest{}
_ = json.Unmarshal([]byte(`
{
"aktions": "Action1",
"aKtionſ": "Action2"
}
`), &a)
fmt.Printf("Result: %#v\n", a)
// Result: main.ActionRequest{Action:"Action2"}Applying it to our running attack scenario, this is how the attack would look like:

The JSON parser can parse the polyglot because the input is valid JSON, it ignores unknown keys, and it allows duplicate keys. It takes the Action_2 value because its field matching is case-insensitive and it takes the value of the last match.
The YAML parser can parse the polyglot because the input is valid JSON (and every JSON file is also a valid YAML file), and it ignores unknown keys. It takes the Action_1 value because, contrary to the JSON parser, it does exact field name matches.
Finally, the XML parser can parse the polyglot because it ignores all surrounding data and just looks for XML-looking data, which, in this polyglot, we hid in a JSON value. As a result, it takes Action_3.
The polyglot we’ve constructed is a powerful starting payload when exploiting these data format confusion attacks similar to the HashiCorp Vault bypass we explored above (CVE-2020-16250).
Mitigations
How can we minimize these risks and make JSON parsing more strict? We’d like to:
- Prevent parsing of unknown keys in JSON, XML, and YAML
- Prevent parsing of duplicate keys in JSON and XML
- Prevent case insensitive key matches in JSON (this one is especially important!)
- Prevent leading garbage data in XML
- Prevent trailing garbage data in JSON and XML
Unfortunately, JSON only offers one option to make its parsing stricter: DisallowUnknownFields. As the name implies, this option disallows unknown fields in the input JSON. YAML supports the same functionality with the KnownFields(true) function, and while there was a proposal to implement the same for XML, it was rejected.
To prevent the remaining insecure defaults, we must create a custom “hacky” solution. The next code block shows the strictJSONParse function, an attempt to make JSON parsing stricter, which has several limitations:
- Bad performance: It requires parsing JSON input twice, making it significantly slower.
- Incomplete detection: Some edge cases remain undetected, as detailed in the function comments.
- Poor adoption potential: Since these security measures aren’t built into libraries as secure defaults or configurable options, widespread adoption is unlikely.
Still, if you detect a vulnerability in your codebase, perhaps this imperfect solution can help you plug a hole while you find a more permanent solution.
// DetectCaseInsensitiveKeyCollisions checks if the JSON data contains keys
// that differ only by letter case. This helps prevent subtle bugs where two
// different key spellings might refer to the same data.
func DetectCaseInsensitiveKeyCollisions(data []byte) error {
// Create a map to hold the decoded JSON data and attempt to parse the JSON
// data. This keeps keys with different letter casing.
var res map[string]interface{}
if err := json.NewDecoder(bytes.NewReader(data)).Decode(&res); err != nil {
return err
}
seenKeys := make([]string, 0, len(res))
// Iterate through all keys in the parsed JSON and detect duplicates
for newKey := range res {
for _, existingKey := range seenKeys {
if strings.EqualFold(existingKey, newKey) {
// Return an error when a case-insensitive duplicate is found
return fmt.Errorf("case-insensitive duplicate keys detected:
%q and %q", existingKey, newKey)
}
}
seenKeys = append(seenKeys, newKey)
}
return nil
}
// Provides a stricter JSON parsing with additional validation:
// 1. Rejects unknown fields not in the target struct
// 2. Detects case-insensitive key collisions
// 3. Ensures complete parsing with no trailing content
// strictJSONParse does not:
// - Ensure that there are no duplicate keys with the same casing
// - Ensure that the casing in the input matches the expected casing
// in the target struct
func strictJSONParse(jsonData []byte, target interface{}) error {
decoder := json.NewDecoder(bytes.NewReader(jsonData))
// 1. Disallow unknown fields
decoder.DisallowUnknownFields()
// 2. Disallow duplicate keys with different casing
err := DetectCaseInsensitiveKeyCollisions(jsonData)
if err != nil {
return fmt.Errorf("strictJSONParse: %w", err)
}
// Decode the JSON into the provided struct
err = decoder.Decode(target)
if err != nil {
return fmt.Errorf("strictJSONParse: %w", err)
}
// 3. Ensure there's no trailing data after the JSON object
token, err := decoder.Token()
if err != io.EOF {
return fmt.Errorf("strictJSONParse: unexpected trailing data after
JSON: token: %v, err: %v", token, err)
}
return nil
}JSONv2
To be widely adopted and solve the problem at a large scale, this functionality needs to be implemented at the library level and enabled by default. This is where JSON v2 comes in. It is currently only a proposal, but a lot of work has gone into it already, and it will hopefully be released soon. It improves on JSON v1 in many ways, including:
- Disallowing duplicate names: “(…) in v2 a JSON object with duplicate names results in an error. The
jsontext.AllowDuplicateNamesoption controls this behavior difference.” - Doing case-sensitive matching: “(…) v2 matches fields using an exact, case-sensitive match. The
MatchCaseInsensitiveNamesandjsonv1.MatchCaseSensitiveDelimiteroptions control this behavior difference.” - It includes a
RejectUnknownMembersoption, even though it is not enable by default (equivalent toDisallowUnknownFields). - It includes a
UnmarshalReadfunction to process data from anio.Reader, verifying that an EOF is found, disallowing trailing garbage data.
While this proposal addresses many of the issues discussed in this blog post, these challenges will persist within the Go ecosystem as widespread adoption takes time. The proposal needs formal acceptance, after which developers must integrate it into all existing JSON-parsing Go code. Until then, these vulnerabilities will continue to pose risks.
Key takeaways for developers
Implement strict parsing by default. Use
DisallowUnknownFieldsfor JSON,KnownFields(true)for YAML. Unfortunately, this is all you can do directly with the Go parser APIs.Maintain consistency across boundaries. When input in processed in multiple services, ensure consistent parsing behavior by always using the same parser or implement additional validation layers, such as the
strictJSONParsefunction shown above.Watch for JSON v2. Keep an eye on the development of Go’s JSON v2 library, which addresses many of these issues with safer defaults for JSON.
Leverage static analysis. Use the Semgrep rules we’ve provided to detect a few vulnerable patterns in your codebase, particularly the misuse of the
-tag andomitemptyfields. Try them withsemgrep -c r/trailofbits.go.unmarshal-tag-is-dashandsemgrep -c r/trailofbits.go.unmarshal-tag-is-omitempty!
While we’ve provided mitigations and detection strategies, the long-term solution requires fundamental changes to how these parsers operate. Until parser libraries adopt secure defaults, developers must remain vigilant.
Read the original article
Comments
By bravesoul2 2025-06-224:042 reply Oof is this for people who reuse their DTO for business logic and/or share DTOs across different APIs.
It never occurred to me to ever (in any language) have a DTO with fields I wish (let alone require for security) not to unmarshall.
This seems doubly strange in Go the language of "Yes absolutely DO repeat yourself!"
Side rant:
JS (even with Typescript) pisses me off as this is unavoidable. Splats make it worse. But still a distinct DTO and business object and don't use splats would help. (Maybe make ... a lint error)
This is not unavoidable in typescript at all. It really depends a lot on how you have structured your application, but it's basically standard practice at this point to use e.g. zod or similar to parse data at the boundaries. You may have to be careful here (remember to use zod's .strict, for example), but it's absolute not unavoidable.
By bravesoul2 2025-06-2211:042 reply I should have been clear. Yes it is avoidable but only by adding more checking machinery. The bare language doesnt help.
In Go etc. If a struct doesn't a field foo then there will not be a field foo at runtime. In JS there might be. Unless you bring in libraries to help prevent it.
You are relying on someone remembering to use zod on every fetch
By paulddraper 2025-06-2215:28 OpenAPI can do this too
By Toritori12 2025-06-2217:34 huh? does Java even support marshall/unmarshall json in the 'bare' language?
By commandersaki 2025-06-2213:581 reply Does the origin of "DTO" come from Java? I've never seen it used anywhere else.
By paulddraper 2025-06-2215:271 reply DTO comes from OOP for which Java is the poster child.
But you can find it many places.
By zaphirplane 2025-06-2220:561 reply Why is Java the poster child of OO when c++ was literally c with classes
By paulddraper 2025-06-2316:15 1. Java was made OO from ground up. No pointer arithmetic, all code is encapsulated in classes, etc.
2. C++ has some unusual OO features -- friends, multiple-inheritance.
3. Most importantly, Java is significantly more approachable than C++ due to automatic memory management.
It’s worth noting that if you DisallowUnknownFields it makes it much harder to handle forward/backward compatible API changes - which is a very common and usually desirable pattern
By georgelyon 2025-06-220:261 reply While this is a common view, recently I’ve begun to wonder if it may be secretly an antipattern. I’ve run into a number of cases over the years where additional fields don’t break parsing, or even necessarily the main functionality of a program, but result in subtle incorrect behavior in edge cases. Things like values that are actually distinct being treated as equal because the fields that differ are ignored. More recently, I’ve seen LLMs get confused because they hallucinated tool input fields that were ignored during the invocation of a tool.
I’m a little curious to try and build an API where parsing must be exact, and changes always result in a new version of the API. I don’t actually think it would be too difficult, but perhaps some extra tooling around downgrading responses and deprecating old versions may need to be built.
By yencabulator 2025-06-223:38 It's a convenience and a labor saver, so of course it's fundamentally at odds with security. It's all trade-offs.
If you’re writing a client, I could see this being a problem.
If you’re writing a server, I believe the rule is that any once valid input must stay valid forever, so you just never delete fields. The main benefit of DisallowUnknownFields is that it makes it easier for clients to know when they’ve sent something wrong or useless.
No, once-valid input can be rejected after a period of depreciation.
What actually makes sense is versioning your interfaces (and actually anything you serialize at all), with the version designator being easily accessible without parsing the entire message. (An easy way to have that is to version the endpoint URLs: /api/v1, /api/v2, etc).
For some time, you support two (or more) versions. Eventually you drop the old version if it's problematic. You never have to guess, and can always reject unknown fields.
By ljm 2025-06-2211:21 This would also be easy to do if an API is designed around versioning from the beginning, because often it isn’t and it requires a lot of boilerplate and duplication, and it just results in everything being slapped into v1.
Especially the case in frameworks that prescribe a format for routing.
This was all very interesting, but that polyglot json/yaml/xml payload was a big surprise to me! I had no idea that go's default xml parser would accept proceeding and trailing garbage. I'd always thought of json as one of the simpler formats to parse, but I suppose the real world would beg to differ.
It's interesting that decisions made about seemingly-innocuous conditions like 'what if there are duplicate keys' have a long tail of consequences
Tangent for breaking Python's JSON parser: This has worked for five years. The docs do not say that parsing an invalid piece will result in a RecursionError. They specify JSONDecodeError and UnicodeDecodeError. (There is a RecursionError reference to a key that is off by default - but if its off, we can still raise this...)
#!/bin/sh # Python will hit it's recursion limit # If you supply just 4 less than the recursion limit # I assume this means there's a few objects on the call stack first # Probably: __main__, print, json.loads, and input. n="$(python3 -c 'import math; import sys; sys.stdout.write(str(math.floor(sys.getrecursionlimit() - 4)))')" echo "N: $n" # Obviously invalid, but unparseable without matching pair # JSON's grammar is... Not good at being partially parsed. left="$(yes [ | head -n "$n" | tr -d '\n')" # Rather than exploding with the expected decodeError # This will explode with a RecursionError # Which naturally thrashes the memory cache. echo "$left" | python3 -c 'import json; print(json.loads(input()))'Reported as <https://github.com/python/cpython/issues/135835>.
By shakna 2025-06-2310:19 I did report this five years ago. And got told that CPython don't consider it a problem. Anything is allowed to raise RecursionError without documentation, in the same way anything is allowed to raise MemoryError.
I don't really agree, as "surprising" is a stench in any API. But it's their project.
By anitil 2025-06-230:14 This is why we can't have nice things
By mdaniel 2025-06-2216:54 > I'd always thought of json as one of the simpler formats to parse, but I suppose the real world would beg to differ
Parsing JSON Is a Minefield (2018) - https://news.ycombinator.com/item?id=40555431 - June, 2024 (56 comments)
et al https://hn.algolia.com/?query=parsing%20json%20is%20a%20mine...
