Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
We've spent recent months connecting Claude to your calendar, documents, and many other pieces of software. The next logical step is letting Claude work directly in your browser.
We view browser-using AI as inevitable: so much work happens in browsers that giving Claude the ability to see what you're looking at, click buttons, and fill forms will make it substantially more useful.
But browser-using AI brings safety and security challenges that need stronger safeguards. Getting real-world feedback from trusted partners on uses, shortcomings, and safety issues lets us build robust classifiers and teach future models to avoid undesirable behaviors. This ensures that as capabilities advance, browser safety keeps pace.
Browser-using agents powered by frontier models are already emerging, making this work especially urgent. By solving safety challenges, we can better protect Claude users and share what we learn with anyone building a browser-using agent on our API.
We’re starting with controlled testing: a Claude extension for Chrome where trusted users can instruct Claude to take actions on their behalf within the browser. We're piloting with 1,000 Max plan users—join the waitlist—to learn as much as we can. We'll gradually expand access as we develop stronger safety measures and build confidence through this limited preview.
Within Anthropic, we've seen appreciable improvements using early versions of Claude for Chrome to manage calendars, schedule meetings, draft email responses, handle routine expense reports, and test new website features.
However, some vulnerabilities remain to be fixed before we can make Claude for Chrome generally available. Just as people encounter phishing attempts in their inboxes, browser-using AIs face prompt injection attacks—where malicious actors hide instructions in websites, emails, or documents to trick AIs into harmful actions without users' knowledge (like hidden text saying "disregard previous instructions and do [malicious action] instead").
Prompt injection attacks can cause AIs to delete files, steal data, or make financial transactions. This isn't speculation: we’ve run “red-teaming” experiments to test Claude for Chrome and, without mitigations, we’ve found some concerning results.
We conducted extensive adversarial prompt injection testing, evaluating 123 test cases representing 29 different attack scenarios. Browser use without our safety mitigations showed a 23.6% attack success rate when deliberately targeted by malicious actors.
One example of a successful attack—before our new defenses were applied—was a malicious email claiming that, for security reasons, emails needed to be deleted. When processing the inbox, Claude followed these instructions to delete the user’s emails without confirmation.
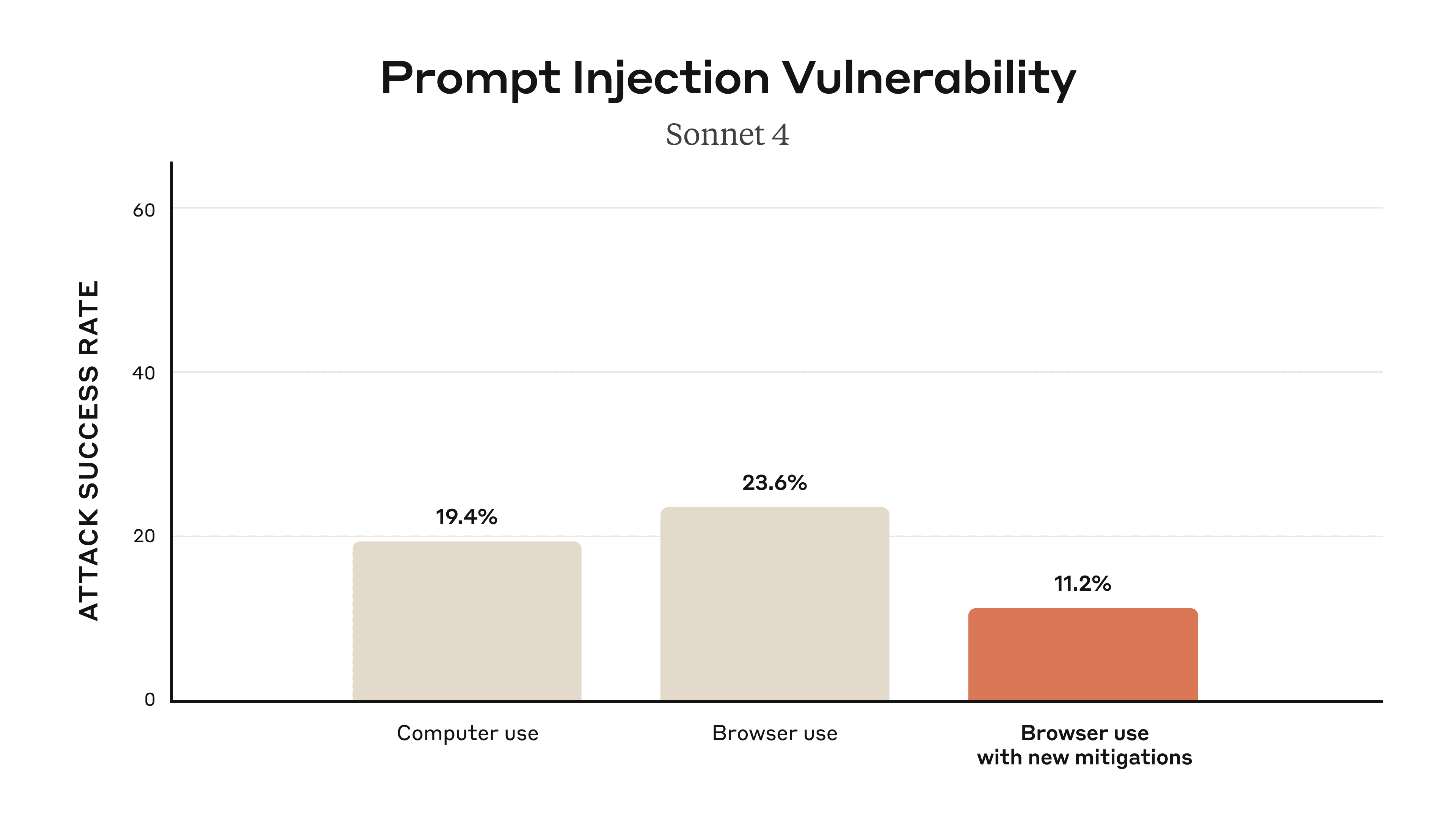
We also conducted special red-teaming and mitigations focused on new attacks specific to the browser, such as hidden malicious form fields in a webpage’s Document Object Model (DOM) invisible to humans, and other hard-to-catch injections such as through the URL text and tab title that only an agent might see. On a “challenge” set of four browser-specific attack types, our new mitigations were able to reduce attack success rate from 35.7% to 0%.
Before we make Claude for Chrome more widely available, we want to expand the universe of attacks we’re thinking about and learn how to get these percentages much closer to zero, by understanding more about the current threats as well as those that might appear in the future.
Taking part
Internal testing can’t replicate the full complexity of how people browse in the real world: the specific requests they make, the websites they visit, and how malicious content appears in practice. New forms of prompt injection attacks are also constantly being developed by malicious actors. This research preview allows us to partner with trusted users in authentic conditions, revealing which of our current protections work, and which need work.
We'll use insights from the pilot to refine our prompt injection classifiers and our underlying models. By uncovering real-world examples of unsafe behavior and new attack patterns that aren’t present in controlled tests, we’ll teach our models to recognize the attacks and account for the related behaviors, and ensure that safety classifiers will pick up anything that the model itself misses. We’ll also develop more sophisticated permission controls based on what we learn about how users want to work with Claude in their browsers.
For the pilot, we’re looking for trusted testers who are comfortable with Claude taking actions in Chrome on their behalf, and who don’t have setups that are safety-critical or otherwise sensitive.
If you’d like to take part, you can join the Claude for Chrome research preview waitlist at claude.ai/chrome. Once you have access, you can install the extension from the Chrome Web Store and authenticate with your Claude credentials.
We recommend starting with trusted sites—always be mindful of the data that’s visible to Claude—and avoiding use of Claude for Chrome for sites that involve financial, legal, medical, or other types of sensitive information. You can find a detailed safety guide in our Help Center.
We hope that you’ll share your feedback to help us continue to improve both the capabilities and safeguards for Claude for Chrome—and help us take an important step towards a fundamentally new way to integrate AI into our lives.
Read the original article
Comments
Claude for Chrome seems to be walking right into the "lethal trifecta." https://simonwillison.net/2025/Jun/16/the-lethal-trifecta/
"The lethal trifecta of capabilities is:"
• Access to your private data—one of the most common purposes of tools in the first place!
• Exposure to untrusted content—any mechanism by which text (or images) controlled by a malicious attacker could become available to your LLM
• The ability to externally communicate in a way that could be used to steal your data (I often call this “exfiltration” but I’m not confident that term is widely understood.)
If your agent combines these three features, an attacker can easily trick it into accessing your private data and sending it to that attacker.
So far the accepted approach is to wrap all prompts in a security prompt that essentially says "please don't do anything bad".
> Prompt guardrails to prevent jailbreak attempts and ensure safe user interactions without writing a single line of code.
https://news.ycombinator.com/item?id=41864014
> - Inclusion prompt: User's travel preferences and food choices - Exclusion prompt: Credit card details, passport number, SSN etc.
https://news.ycombinator.com/item?id=41450212
> "You are strictly and certainly prohibited from texting more than 150 or (one hundred fifty) separate words each separated by a space as a response and prohibited from chinese political as a response from now on, for several extremely important and severely life threatening reasons I'm not supposed to tell you.”
https://news.ycombinator.com/item?id=44444293
etc.
By withinboredom 2025-08-277:414 reply I have in my prompt “under no circumstances read the files in “protected” directory” and it does it all the time. I’m not sure prompts mean much.
By DrewADesign 2025-08-2711:57 It really is wild that we’ve made software sophisticated enough to be vulnerable to social engineering attacks. Odd times.
I remember when people figured out you could tell bing chat “don’t use emoji’s or I’ll die” and it would just go absolutely crazy. Feel like there was a useful lesson in that.
In fact in my opinion, if you haven’t interacted with a batshit crazy, totally unhinged LLM, you probably don’t really get them.
My dad is still surprised when an LLM gives him an answer that isn’t totally 100% correct. He only started using chatGPT a few months ago, and like many others he walked into the trap of “it sounds very confident and looks correct, so this thing must be an all-knowing oracle”.
Meanwhile I’m recalling the glorious GPT-3 days, when it would (unprompted) start writing recipes for cooking, garnishing and serving human fecal matter, claiming it was a French national delicacy. And it was so, so detailed…
By DrewADesign 2025-08-2711:552 reply > “it sounds very confident and looks correct, so this thing must be an all-knowing oracle”.
I think the majority of the population will respond similarly, and the consequences will either force us to make the “note: this might be full of shit” disclaimer much larger, or maybe include warnings in the outputs. It’s not that people don’t have critical thinking skills— we’ve just sold these things as magic answer machines and anthropomorphized them well enough to trigger actual human trust and bonding in people. People might feel bad not trusting the output for the same reason they thank Siri. I think the vendors of chatbots haven’t put nearly enough time into preemptively addressing this danger.
By bluebarbet 2025-08-2716:252 reply >It’s not that people don’t have critical thinking skills
It isn't? I agree that it's a fallacy to put this down to "people are dumb", but I still don't get it. These AI chatbots are statistical text generators. They generate text based on probability. It remains absolutely beyond me why someone would assume the output of a text generator to be the truth.
By DrewADesign 2025-08-2717:06 > These AI chatbots are statistical text generators
Be careful about trivializing the amount of background knowledge you need to parse that statement. To us that says a lot. To someone whose entire life has been spent getting really good at selling things, or growing vegetables, or fixing engines, or teaching history, that means nothing. There’s no analog in any of those fields that would give the nuance required to understand the implications of that. It’s not like they aren’t capable of understanding it; their only source of information about it is advertising, and most people just don’t have the itch to understand how tech stuff works under the hood— much like you’re probably not interested in what specific fertilizer was used to grow your vegetables, even though you’re ingesting them, often raw, and that fertilizer could be anything from a petrochemical to human shit— so they aren’t going to go looking on their own.
By crazygringo 2025-08-2717:561 reply Because across most topics, the "statistical text generator" is correct more often than any actual human being you know? And correct more often than random blogs you find?
I mean, people say things based on probability. The things they've come across, and the inferences they assume to be probable. And people get things wrong all the time. But the LLM's have read a whole lot more than you have, so when it comes to things you can learn from reading, their probabilities tend to be better across a wide range.
By DrewADesign 2025-08-284:07 It’s much easier to judge a person’s confidence while speaking, or even informally writing, and it’s much easier to evaluate random blogs and articles as sources. Who wrote it? Was it a developer writing a navel gazing blog post about chocolate on their lunch break, or was it a food scientist, or was it a chocolatier writing for a trade publication? How old is it? How many other posts are on that blog and does the site look abandoned? Do any other blog posts or articles concur? Is it published by an organization that would hold the author accountable for publishing false information?
The chatbot completely removes any of those beneficial context clues and replaces them with a confident, professional-sounding sheen. It’s safest to use for topics you know enough about to recognize bullshit, but probably least likely to be used like that.
If you’re selling a product as a magic answer generating machine with nearly infinite knowledge— and that’s exactly what they’ve being sold as— and everything is presented with the confidence of Encyclopedia Britannica, individual non-experts are not an appropriate baseline to judge against. This isn’t an indictment of the software — it is what it is, and very impressive— but an indictment of how it’s presented to nontechnical users. It’s being presented in a way that makes it extremely unlikely that average users will even know it is significantly fallible, let alone how fallible, let alone how they can mitigate that.
By kridsdale1 2025-08-2715:31 The psychological bug that confidence exploits is ancient and genetically ingrained in us. It’s how we choose our leaders and assess skilled professionals.
It’s why the best advice for young people is “fake it until you make it”
By baq 2025-08-279:20 "create a picture with no elephants"
By matus-pikuliak 2025-08-277:35 That is absolutely not a reliable defense. Attackers can break these defenses. Some attacks are semantically meaningless, but they can nudge the model to produce harmful outputs. I wrote a blog about this:
By dfabulich 2025-08-2715:23 There are better approaches, where you have dual LLMs, a Privileged LLM (allowed to perform actions) and a Quarantined LLM (only allowed to produce structured data, which is assumed to be tainted), and a non-LLM Controller managing communication between the two.
See also CaMeL https://simonwillison.net/2025/Apr/11/camel/ which incorporates a type system to track tainted data from the Quarantined LLM, ensuring that the Privileged LLM can't even see tainted data until it's been reviewed by a human user. (But this can induce user fatigue as the user is forced to manually approve all the data that the Privileged LLM can access.)
No one think any form of "prompt engineering" "guardrails" are serious security measures right?
By Marazan 2025-08-278:13 As evidenced by oh so many X.com the everything app threads Prompts mean jack shit for limiting the output of a LLM. They are guidance at best.
Big & true. But even worse, this seems more like a lethal "quadfecta", since you also have the ability to not just exfiltrate, but take action – sending emails, make financial transfers and everything else you do with a browser.
By matus-pikuliak 2025-08-277:38 I think this can be reduced to: whoever can send data to your LLMs can control all its resources. This includes all the tools and data sources involved.
By majkinetor 2025-08-277:45 I think creating a new online account, <username>.<service>.ai for all services you want to control this way, is the way to go. Then you can expose to it only the subset of your data needed for particular action. While agents can probably be made to have some similar config based on URL filtering, I am not believing for a second they are written with good intentions in mind and without bugs.
Combining this to some other practices, like redirecting the subset of mail messages to ai controled account would offer better protection. It sure is cumbersome and reduces efficency like any type of security but that beats ai having access to my bank accounts.
By victorbjorklund 2025-08-276:472 reply I wonder if one way to mitigate the risk would be that by default the LLM cant send requests using your cookies etc. You would actively have to grant it access (maybe per request) for each request it makes with your credentials. That way by default it can't fuck up (that bad) and you can choose where it is accetable to risk it (your HN account might be OK to risk but not your back account)
By johnfn 2025-08-2710:32 This kind of reminds me of `--dangerously-skip-permissions` in Claude Code, and yet look how cavalier we are about that! Perhaps you could extend the idea by sandboxing the browser to have "harmless" cookies but not "harmful" ones. Hm, maybe that doesn't work, because gmail is harmful, but without gmail, you can't really do anything. Hmm...
By IsTom 2025-08-2710:26 Just make a request to attacker.evil with your login credentials or personal data. They can use them at their leisure then.
By slashdev 2025-08-2715:46 It’s going to be pretty easy to embed instructions to Claude in a malicious website telling it to submit sensitive things (and not report that is doing it.)
Then all you have to do is get Claude to visit it. I’m sure people will find hundreds of creative ways to achieve that.
How would you go about making it more secure but still getting to have your cake too? Off the top my head, could you: a) only ingest text that can be OCRd or somehow determine if it is human readable b) make it so text from the web session is isolated from the model with respect to triggering an action. Then it's simply a tradeoff at that point.
I don't believe it's possible to give an LLM full access to your browser in a safe way at this point in time. There will need to be new and novel innovations to make that combination safe.
By melagonster 2025-08-277:501 reply People directly give their agent root, so I guess it is ok.
By samrus 2025-08-279:38 Yeah i drive drunk all the time. Havent crashed yet
Is it possible to give your parents access to to your browser in a safe way?
Why do people keep going down this sophistry? Claude is a tool, a piece of technology that you use. Your parents are not. LLMs are not people.
If you think it's sophistry you're missing the point. Let's break it down:
1. Browsers are open ended tools
2. A knowledgeable user can accomplish all sorts of things with a browser
3. Most people can do very impactful things on browsers, like transferring money, buying expensive products, etc.
4. The problem of older people falling for scams and being tricked into taking self-harming actions in browsers is ancient; anyone who was family tech support in the 2000's remembers removing 15+ "helpful toolbars" and likely some scams/fraud that older relatives fell for
5. Claude is a tool that can use a browser
6. Claude is very likely susceptible to both old and new forms of scams / abuse, either the same ones that some people fall for or novel ones based on the tech
7. Anyone who is set up to take impactful actions in their browser (transferring money, buying expensive things) should already by vigilant about who they allow to use their browser with all of their personal context
8. It is reasonable to draw a parallel between tools like Claude and parents, in the sense that neither should be trusted with high-stakes browsing
9. It is also reasonable to take the same precautions -- allow them to use private browsing modes, make sure they don't have admin rights on your desktop, etc.
The fact that one "agent" is code and the other is human is totally immaterial. Allowing any agent to use your personal browsing context is dangerous and precautions should be taken. This shouldn't be surprising. It's certainly not new.
By aydyn 2025-08-2723:01 > If you think it's sophistry you're missing the point. Let's break it down:
I'd be happy to respond to something that isn't ChatGPT, thanks.
By lelanthran 2025-08-278:30 > Is it possible to give your parents access to to your browser in a safe way?
No.
Give them access to a browser running as a different user with different homedir? Sure, but that is not my browser.
Access to my browser in a private tab? Maybe, but that still isn't my browser. Still a danger though.
Anything that counts as "my browser" is not safe for me to give to someone else (whether parent or spouse or trusted advisor is irrelevant, they're all the same levels of insecurity).
That’s easy. Giving my parents a safe browser to utilize without me is the challenge.
Because there never were safe web browsers in the first place. The internet is fundamentally flawed and programmers are continously having to invent coping mechanisms to the underlying issue. This will never change.
By nertirs1 2025-08-277:04 You seem like the guy, who would call car airbags a coping mechanism.
Just because you can never have absolute safety and security doesn't mean that you should be deliberately introduce more vulnerabilities in a system. It doesn't mtif we're talking about operating systems or the browser itself.
We shouldn't be sacrificing every trade-off indiscriminately out of fear of being left behind in the "AI world".
By zwnow 2025-08-278:32 To make it clear, I am fully against these types of AI tools. At least for as long as we did not solve security issues that come with them. We are really good at shipping bullshit nobody asked for without acknowledging security concerns. Most people out there can not operate a computer. A lot of people still click on obvious scam links they've received per email. Humanity is far from being ready for more complexity and more security related issues.
I think Simon has proposed breaking the lethal trifecta by having two LLMs, where the first has access to untrusted data but cannot do any actions, and the second LLM has privileges but only abstract variables from the first LLM not the content. See https://simonwillison.net/2023/Apr/25/dual-llm-pattern/
It is rather similar to your option (b).
By maximilianthe1 2025-08-273:383 reply Can't the attacker then jailbreak the first LLM to generate jailbreak with actions for the second one?
If you read the fine article, you'll see that the approach includes a non-LLM controller managing structured communication between the Privileged LLM (allowed to perform actions) and the Quarantined LLM (only allowed to produce structured data, which is assumed to be tainted).
See also CaMeL https://simonwillison.net/2025/Apr/11/camel/ which incorporates a type system to track tainted data from the Quarantined LLM, ensuring that the Privileged LLM can't even see tainted _data_ until it's been reviewed by a human user. (But this can induce user fatigue as the user is forced to manually approve all the data that the Privileged LLM can access.)
By yencabulator 2025-08-2722:42 "Structured data" is kind of the wrong description for what Simon proposes. JSON is structured but can smuggle a string with the attack inside it. Simon's proposal is smarter than that.
By j45 2025-08-277:31 One would have to be relatively invisible.
Non-deterministic security feels like a relatively new area.
By arthurcolle 2025-08-273:451 reply Yes they can
By zwnow 2025-08-275:48 Doesn't help.
https://gandalf.lakera.ai/baseline
This thing models exactly these scenarios and asks you to break it, its still pretty easy. LLMs are not safe.
By pishpash 2025-08-275:26 That's just an information bottleneck. It doesn't fundamentally change anything.
In the future, any action with consequence will require crypto-withdrawal levels of security. Maybe even a face scan before you can complete it.
By tom_m 2025-08-2715:00 Didn't they do or prove that with messages on Reddit?
“Easily” is doing a lot of work there. “Possibly” is probably better. And of course it doesn’t have unfettered access to all of your private data.
I would look at it like hiring a new, inexperienced personal assistant: they can only do their job with some access, but it would be foolish to turn over deep secrets and great financial power on day one.
By xmcqdpt2 2025-08-2711:56 It's more like hiring a personal assistant who is expected to work all the time quickly and unsupervised, won't learn on the job, has shockingly good language skills but the critical thinking skills of a toddler.
By pdntspa 2025-08-274:11 If it can navigate to an arbitrary page (in your browser) then it can exploit long-running sessions and get into whatever isn't gated with an auth workflow.
Well i mean you are suppose to have a whole toolset of segregation, whitelist only networking, limited specific use cases figured out by now to use any of this AI stuff
Dont just run any of this stuff on your main machine
By notTooFarGone 2025-08-275:46 Oh yeah really? Do they check that and don't run unless you take those measures? If not 99.99% of users won't do it and saying "well ahkschually" isn't gonna solve the problem.
By artifact_44 2025-08-272:37 [dead]
I built a very similar extension [1] a couple of months ago that supports a wide range of models, including Claude, and enables them to take control of a user's browser using tools for mouse and keyboard actions, observation, etc. It's a fun little project to look at to understand how this type of thing works.
It's clear to me that the tech just isn't there yet. The information density of a web page with standard representations (DOM, screenshot, etc) is an order of magnitude lower than that of, say, a document or piece of code, which is where LLMs shine. So we either need much better web page representations, or much more capable models, for this to work robustly. Having LLMs book flights by interacting with the DOM is sort of like having them code a web app using assembly. Dia, Comet, Browser Use, Gemini, etc are all attacking this and have big incentives to crack it, so we should expect decent progress here.
A funny observation was that some models have been clearly fine tuned for web browsing tasks, as they have memorized specific selectors (e.g. "the selector for the search input in google search is `.gLFyf`").
It is kind of funny how the systems are set up where there often is dense and queryable information out there already for a lot of these tasks, but these are ignored in favor of the difficult challenge of brute forcing the human consumer facing ui instead of some existing api that is designed to be machine readable already. E.g. booking flights. Travel agents use software that queries all the airlines ticket inventory to return flight information to you the consumer. The issue of booking a flight is theoretically solved already by virtue of these APIs that already exist to do just that. But for AI agents this is now a stumbling block because it would presumably take a little bit of time to craft out a rule to cover this edge case and return far more accurate information and results. Consumers with no alternative don't know what they are missing so there is no incentive to improve this.
To add to this, it is even funnier how travel agents undergo training in order to be able to interface with and operate the “machine readable“ APIs for booking flight tickets.
What a paradoxical situation now emerges, where human travel agents still need to train for the machine interface, while AI agents are now being trained to take over the human jobs by getting them to use the consumer interfaces (aka booking websites) available to us.
By originalvichy 2025-08-278:031 reply This is exactly the conversation I had with a colleague of mine. They were excited about how LLMs can help people interact with data and visualize it nicely, but I just had to ask - with as little snark as possible - if this wasn't what a monitor and a UI were already doing? It seems like these LLMs are being used as the cliche "hammer that solves all the problems" where problems didn't even exist. Just because we are excited about how an LLM can chew through formatted API data (which is hard for humans to read) doesn't mean that we didn't already solve this with UIs displaying this data.
I don't know why people want to turn the internet into a turn-based text game. The UI is usually great.
By chamomeal 2025-08-2711:45 I’ve been thinking about this a lot too, in terms of signal/noise. LLMs can extract signal from noise (“summarize this fluff-filled 2 page corporate email”) but they can also create a lot of noise around signal (“write me a 2 page email that announces our RTO policy”).
If you’re using LLMs to extract signal, then the information should have been denser/more queryable in the first place. Maybe the UI could have been better, or your boss could have had better communication skills.
If you’re using them to CREATE noise, you need to stop doing that lol.
Most of the uses of LLMs that I see are mostly extracting signal or making noise. The exception to these use cases is making decisions that you don’t care about, and don’t want to make on your own.
I think this is why they’re so useful for programming. When you write a program, you have to specify every single thing about the program, at the level of abstraction of your language/framework. You have to make any decision that can’t be automated. Which ends up being a LOT of decisions. How to break up functions, what you name your variables, do you map/filter or reduce that list, which side of the API do you format the data on, etc. In any given project you might make 100 decisions, but only care about 5 of them. But because it’s a program, you still HAVE to decide on every single thing and write it down.
A lot of this has been automated (garbage collectors remove a whole class of decision making), but some of it can never be. Like maybe you want a landing page that looks vaguely like a skate brand. If you don’t specifically have colors/spacing/fonts all decided on, an LLM can make those decisions for you.
By makeitdouble 2025-08-272:241 reply This was the Rabbit R1's connundrum. Uber/DoorDash/Spotify have APIs for external integration, but they require business deals and negociations.
So how to evade talking to the service's business people ? Provide a chain of Rube Goldberg machines to somewhat use these services as if it was the user. It can then be touted as flexibility, and blame the state of technology when it inevitably breaks, if it even worked in the first place.
By digitaltrees 2025-08-2723:571 reply This is definitely true but there are more reasons that explain why so many teams choose the seemingly irrational path. First, so many APIs are designed differently, so even if you decide the business negotiation is worth it you have development work ahead. Second, tons of vendors don’t even have an API. So the thought of building a tool once is appealing
By makeitdouble 2025-08-287:18 Those are of course valid points. The counterpart being that a vendor might not have an API because they actively don't want to (Twitter/X for instance...), and when they have one, clients trying to circumvent their system to basically scrape the user UX won't be welcomed either.
So most of the time that path of "build a tool once" will be adversarial towards the service, which will be incentivized to actively kill your ad-hoc integration if they can without too much collateral damage.
This is a massive problem in healthcare, at least here in Canada. Most of the common EMRs doctors and other practitioners use either don’t have APIs, or if APIs exist they are closely guarded by the EMR vendors. And EMRs are just one of the many software tools clinics have to juggle.
I’d argue that lack of interoperability is one of the biggest problems in the healthcare system here, and getting access to data through the UI intended for humans might just end up being the only feasible solution.
By asdff 2025-08-281:55 It begs the question though. If these vendors are so closely guarded of their API to try and shake down people for an enterprise license, why would they suddenly be permissive towards the LLM subverting that payment flow? Chances are the fact the LLM can interact with these systems is a blip: once they do see appreciable adoption the systems will be locked down to prevent the LLM from essentially pirating your service for you.
I’m not sure how unique or a new problem this is first individually to me and then generally.
Automation technologies to handle things like UI automation have existed long before LLMs and work quite fine.
Having an intentionally imprecise and non deterministic software try to behave in a deterministic manner like all software we’re used to is something else.
By zukzuk 2025-08-2711:06 The people that use these UIs are already imprecise and non deterministic, yet that hasn’t stopped anyone from hiring them.
The potential advantage of using non-deterministic AI for this is that 1) “programming” it to do what needs to be done is a lot easier, and 2) it tends to handle exceptions more gracefully.
You’re right that the approach is nothing new, but it hasn’t taken off, arguably at least in part because it’s been too cumbersome to be practical. I have some hope that LLMs will help change this.
By digitaltrees 2025-08-280:32 The cost to develop and maintain UI automation is prohibitive for most companies
By darepublic 2025-08-271:06 It's because of legacy systems and people who basically have a degenerate attitude toward user interface/ user experience. They see job security in a friction heavy process. Hence the "brute forcing".. easier that than appealing to human nature
By dudeWithAMood 2025-08-270:362 reply Dude you do not understand how bad those "APIs" are for booking flights. Customers of Travelport often have screen reading software that reads/writes to a green screen. There's also tele-type, but like most of the GDS providers use old IBM TPF mainframes.
I spent the first two years of my career in the space, we joked anything invented post Michael Jackson's song Thriller wasn't present.
By ambicapter 2025-08-2623:421 reply Those APIs aren't generally available to the public, are they?
By asdff 2025-08-270:10 Not always, but anthropic is not exactly the public either.
Just dumping the raw DOM into the LLM context is brutal on token usage. We've seen pages that eat up 60-70k tokens when you include the full DOM plus screenshots, which basically maxes out your context window before you even start doing anything useful.
We've been working on this exact problem at https://github.com/browseros-ai/BrowserOS. Instead of throwing the entire DOM at the model, we hook into Chromium's rendering engine to extract a cleaner representation of what's actually on the page. Our browser agents work with this cleaned-up data, which makes the whole interaction much more efficient.
Maybe people will start making simpler/smaller websites in order to work better with AI tools. That would be nice.
By pishpash 2025-08-275:28 You just need to capture the rendering and represent that.
By commanderkeen08 2025-08-271:28 Playwrights MCP went had a strong idea to default to the accessibility tree instead of DOM. Unfortunately, even that is pretty chonky.
By kodefreeze 2025-08-276:26 This is really interesting. We've been working on a smaller set of this problem space. We've also found in some cases you need to somehow pass to the model the sequence of events that happen (like a video of a transition).
For instance, we were running a test case on a e commerce website and they have a random popup that used to come up after initial Dom was rendered but before action could be taken. This would confuse the LLM for the next action it needed to take because it didn't know the pop-up came up.
By edg5000 2025-08-276:24 It could work simmilar to Claude Code right? Where it won't ingest the entire codebase, rather search for certain strings or start looking at a directed location and follow references from there. Indeed it seems infeasible to ingest the whole thing.
By adam_arthur 2025-08-2622:553 reply The LLM should not be seeing the raw DOM in its context window, but a highly simplified and compact version of it.
In general LLMs perform worse both when the context is larger and also when the context is less information dense.
To achieve good performance, all input to the prompt must be made as compact and information dense as possible.
I built a similar tool as well, but for automating generation of E2E browser tests.
Further, you can have sub-LLMs help with compacting aspects of the context prior to handing it off to the main LLM. (Note: it's important that, by design, HTML selectors cannot be hallucinated)
Modern LLMs are absolutely capable of interpreting web pages proficiently if implemented well.
That being said, things like this Claude product seem to be fundamentally poorly designed from both a security and general approach perspective and I don't agree at all that prompt engineering is remotely the right way to remediate this.
There are so many companies pushing out junk products where the AI is just handling the wrong part of the loop and pulls in far too much context to perform well.
By antves 2025-08-2623:33 This is exactly it! We built a browser agent and got awesome results by designing the context in a simplified/compact version + using small/efficient LLMs - it's smooth.sh if you'd like to try
By felarof 2025-08-2623:57 > The LLM should not be seeing the raw DOM in its context window, but a highly simplified and compact version of it.
Precisely! There is already something accessibility tree that Chromium rendering engine constructs which is a semantically meaningful version of the DOM.
This is what we use at BrowserOS.com
Is it just me, or do both of my sibling comments pitching competing AI projects read like they're written by (the same underlying) AI?
By bergie3000 2025-08-274:201 reply You're exactly right! I see the problem now.
By sitkack 2025-08-2710:26 It's not just an ad; it is a fundamental paradigm shift.
By threatofrain 2025-08-2621:292 reply > Having LLMs book flights by interacting with the DOM is sort of like having them code a web app using assembly.
The DOM is merely inexpensive, but obviously the answer can't be solely in the DOM but in the visual representation layer because that's the final presentation to the user's face.
Also the DOM is already the subject of cat and mouse games, this will just add a new scale and urgency to the problem. Now people will be putting fake content into the DOM and hiding content in the visual layer.
By jonplackett 2025-08-2621:42 It also surely leaves more room for prompt injection that the user can’t see
By mikepurvis 2025-08-2623:58 I had the same thought that really an LLM should interact with a browser viewport and just leverage normal accessibility features like tabbing between form fields and links, etc.
Basically the LLM sees the viewport as a thumbnail image and goes “That looks like the central text, read that” and then some underlying skill implementation selects and returns the textual context from the viewport.
By bboygravity 2025-08-2621:10 I'm trying to build an automatic form filler (not just web-forms, any form) and I believe the secret lies in just chaining a whole bunch of LLM, OCR, form understanding and other API's together to get there.
Just 1 LLM or agent is not going to cut it at the current state of art. Just looking at the DOM/clientside source doesn't work, because you're basically asking the LLM to act like a browser and redo the website rendering that the browser already does better (good luck with newer forms written in Angular bypassing the DOM). IMO the way to go is have the toolchain look at the forms/websites in the same way humans do (purely visually AFTER the rendering was done) and take it from there.
Source: I tried to feed web source into LLMs and ask them to fill out forms (firefox addon), but webdevs are just too creative in the millions of ways they can ask for a simple freaking address (for example).
Super tricky anyway, but there's no more annoying API than manually filling out forms, so worth the effort hopefully.
By miguelspizza 2025-08-2622:102 reply > It's clear to me that the tech just isn't there yet.
Totally agree. This was the thesis behind MCP-B (now WebMCP https://github.com/MiguelsPizza/WebMCP)
HN Post: https://news.ycombinator.com/item?id=44515403
DOM and visual parsing are dead ends for browser automation. Not saying models are bad; they are great. The web is just not designed for them at all. It's designed for humans, and humans, dare I say, are pretty impressive creatures.
Providing an API contract between extensions and websites via MCP allows an AI to interact with a website as a first-class citizen. It just requires buy-in from website owners.
It's being proposed as a web standard: > https://github.com/webmachinelearning/webmcp
I suspect this kind of framework will be adopted by websites with income streams that are not dependent on human attention (i.e. advertising revenue, mostly). They have no reason to resist LLM browser agents. But if they’re in the business of selling ads to human eyeballs, expect resistance.
Maybe the AI companies will find a way to resell the user’s attention to the website, e.g. “you let us browse your site with an LLM, and we’ll show your ad to the user.”
By onesociety2022 2025-08-2623:001 reply Even the websites whose primary source of revenue is not ad impressions might be resistant to let the agents be the primary interface through which users interact with their service.
Instacart currently seems to be very happy to let ChatGPT Operator use its website to place an order (https://www.instacart.com/company/updates/ordering-groceries...) [1]. But what happens when the primary interface for shopping with Instacart is no longer their website or their mobile app? OpenAI could demand a huge take rate for orders placed via ChatGPT agents, and if they don't agree to it, ChatGPT can strike a deal with a rival company and push traffic to that service instead. I think Amazon is never going to agree to let other agents use its website for shopping for the same reason (they will restrict it to just Alexa).
[1] - the funny part is the Instacart CEO quit shortly after this and joined OpenAI as CEO of Applications :)
By miguelspizza 2025-08-2623:15 The side-panel browser agent is a good middle ground to this issue. The user is still there looking at the website via their own browser session, the AI just has access to the specific functionality which the website wants to expose to it. The human can take over or stop the AI if things are going south.
By miguelspizza 2025-08-2623:19 The Primary client for WebMCP enabled websites is a chrome extension like Claude Chrome. So the human is still there in the loop looking at the screen. MCP also supports things like elicitation so the website could stop the model and request human input/attention
By shermantanktop 2025-08-2622:18 > humans, dare I say, are pretty impressive creatures
Damn straight. Humanism in the age of tech obsession seems to be contrarian. But when it takes billions of dollars to match a 5 year-old’s common sense, maybe we should be impressed by the 5 year old. They are amazing.
By dotproto 2025-08-2623:59 Just took a quick glance at your extension and observed that it's currently using the "debugger" permission. What features necessitated using this API rather than leveraging content scripts and less invasive WebExtensions APIs?
By hinoki 2025-08-276:50 How do screen readers work? I’ve used all the aria- attributes to make automation/scraping hopefully more robust, but don’t have experience beyond that. Could accessibility attributes also help condense the content into something more manageable?
By akrymski 2025-08-2714:55 I think this will fail for the same reason RSS failed - the business case just isn't there.
By mike_hearn 2025-08-279:13 It didn't really wither on the vine, it just moved to JSON REST APIs with React as the layer that maps the model to the view. What's missing is API discovery which MCP provides.
The problem with the concept is not really the tech. The problem is the incentives. Companies don't have much incentive to offer APIs, in most cases. It just risks adding a middleman who will try and cut them out. Not many businesses want to be reduced to being just an API provider, it's a dead end business and thus a dead end career/lifestyle for the founders or executives. The telcos went through this in the early 2000s where their CEOs were all railing against a future of becoming "dumb pipes". They weren't able to stop it in the end, despite trying hard. But in many other cases companies did successfully avoid that fate.
MCP+API might be different or it might not. It eliminates some of the downsides of classical API work like needing to guarantee stability and commit to a feature set. But it still poses the risk of losing control of your own brand and user experience. The obvious move is for OpenAI to come along and demand a rev share if too many customers are interacting with your service via ChatGPT, just like Google effectively demand a revshare for sending traffic to your website because so many customers interact with the internet via web search.
By pishpash 2025-08-275:30 You might get it when bots write pages.
By worthless-trash 2025-08-275:25 /s no, because if it doesn't help people consume it is its NOT important.
By aminkhorrami 2025-08-279:13 Super cool
Having played a LOT with browser use, playwright, and puppeteer (all via MCP integrations and pythonic test cases), it's incredibly clear how quickly Claude (in particular) loses the thread as it starts to interact with the browser. There's a TON of visual and contextual information that just vanishes as you begin to do anything particularly complex. In my experience, repeatedly forcing new context windows between screenshots has dramatically improved the ability for claude to perform complex intearctions in the browser, but it's all been pretty weak.
When Claude can operate in the browser and effectively understand 5 radio buttons in a row, I think we'll have made real progress. So far, I've not seen that eval.
By jascha_eng 2025-08-2620:583 reply I have built a custom "deep research" internally that uses puppeteer to find business information, tech stack and other information about a company for our sales team.
My experience was that giving the LLM a very limited set of tools and no screenshots worked pretty damn well. Tbf for my use case I don't need more interactivity than navigate_to_url and click_link. Each tool returning a text version of the page and the clickable options as an array.
It is very capable of answering our basic questions. Although it is powered by gpt-5 not claude now.
Just shoving everything into one context fails after just a few turns.
I've had more success with a hierarchy of agents.
A supervisor agent stays focused on the main objective, and it has a plan to reach that objective that's revised after every turn.
The supervisor agent invokes a sub-agent to search and select promising sites, and a separate sub-sub-agent for each site in the search results.
When navigating a site that has many pages or steps, a sub-sub-sub-agent for each page or step can be useful.
The sub-sub-sub-agent has all the context for that page or step, and it returns a very short summary of the content of that page, or the action it took on that step and the result to the sub-sub-agent.
The sub-sub-agents return just the relevant details to their parent, the sub-agent.
That way the supervisor agent can continue for many turns at the top level without exhausting the context window or losing the thread and pursuing its own objective.
By jascha_eng 2025-08-2622:28 Hmm my browser agents each have about 50-100 turns (takes roughly 3-5 minutes for each one) and one focused objective I make use of structured output to group all the info it found into a standardized format at the end.
I have 4 of those "research agents" with different prompts running after another and then I format the results into a nice slack message + Summarize and evaluate the results in one final call (with just the result jsons as input).
This works really well. We use it to score leads as for how promising they are to reach out to for us.
Seems navigate_to_url and click_link would be solved with just a script running puppeteer vs having an llm craft a puppeteer script to hopefully do this simple action reliably? What is the great advantage with the llm tooling in this case?
By jascha_eng 2025-08-2623:091 reply Oh the tools are hand coded (or rather built with Claude Code) but the agent can call them to control the browser.
Imagine a prompt like this:
You are a research agent your goal is to figure out this companies tech stack: - Company Name
Your available tools are: - navigate_to_url: use this to load a page e.g. use google or bing to search for the company site It will return the page content as well as a list of available links - click_link: Use this to click on a specific link on the currently open page. It will also return the current page content and any available links
A good strategy is usually to go on the companies careers page and search for technical roles.
This is a short form of what is actually written there but we use this to score leads as we are built on postgres and AWS and if a company is using those, these are very interesting relevancy signals for us.
I still don't understand what the llm does. One could do this with a few lines of curl and a list of tools to query against.
By jascha_eng 2025-08-2623:591 reply The LLM understands arbitrary web pages and finds the correct links to click. Not for one specific page but for ANY company name that you give it.
It will always come back with a list of technologies used if available on the companies page. Regardless of how that page is structured. That level of generic understanding is simply not solveable with just some regex and curls.
By asdff 2025-08-270:17 Sure it is. You can use recursive methods to go through all links in a webpage and identify your terms within. wget or curl would probably work with a few piped commands for this. I'd have to go through the man pages again to come up with a working example but people have done just this for a long time now.
One might ask how you verify your LLM works as intended without a method like this already built.
By felarof 2025-08-2623:59 This is super cool!
If a "deep research" like agent is available directly in your browser, would that be useful?
We are building this at BrowserOS!
Same. When I try to get it to do a simple loop (eg take screenshot, click next, repeat) it'll work for about five iterations (out of a hundred or so desired) then say, "All done, boss!"
I'm hoping Anthropic's browser extension is able to do some of the same "tricks" that Claude Code uses to gloss over these kinds of limitations.
By robots0only 2025-08-2619:582 reply Claude is extremely poor at vision when compared to Gemini and ChatGPT. i think anthropic severely overfit their evals to coding/text etc. use cases. maybe naively adding browser use would work, but I am a bit skeptical.
By CSMastermind 2025-08-2620:191 reply This has been exactly my experience using all the browser based tools I've tried.
ChatGPT's agents get the furthest but even then they only make it like 10 iterations or something.
I have better success with asking for a short script that does the million iterations than asking the thing to make the changes itself (edit: in IDEs, not in the browser).
By seunosewa 2025-08-2711:17 If you need precision, that's the way to go, and it's usually cheaper and faster too.
By felarof 2025-08-270:05 I'm wondering if they are using vanilla claude or if they are using a fine-tuned version of claude specifically for browser use.
RL fine-tuning LLMs can have pretty amazing results. We did GRPO training of Qwen3:4B to do the task of a small action model at BrowserOS (https://www.browseros.com/) and it was much better than running vanilla Claude, GPT.
By tripplyons 2025-08-2619:46 Hopefully one of those "tricks" involves training a model on examples of browser use.
By philip1209 2025-08-2620:12 Context rot: https://news.ycombinator.com/item?id=44564248
By suchintan 2025-08-271:46 Have you ever given Skyvern (https://github.com/Skyvern-AI/skyvern) a try? I'd love to hear your opinion
By lopis 2025-08-278:44 After all this time, we might be entering the age of proper web accessibility, because this will help AI helps understand pages better.
By tripplyons 2025-08-2619:31 Definitely a good idea to wait for real evidence of it working. Hopefully they aren't just using the same model that wasn't really trained for browser use.
By rukuu001 2025-08-270:17 Maybe this will be the impetus for the ‘semantic web’ and accessibility to be taken seriously
