
In normal operation of EC2, the DWFM maintains a large number (~10^6) of active leases against physical servers and a very small number (~10^2) of broken leases, the latter of which the manager is actively attempting to reestablish.
The DynamoDB outage, which lasted almost 3 hours, caused widespread heartbeat timeouts and thus thousands of leases broke. I’d estimate that the number of broken leases reached at least 10^5, or three OOMs larger than normal.
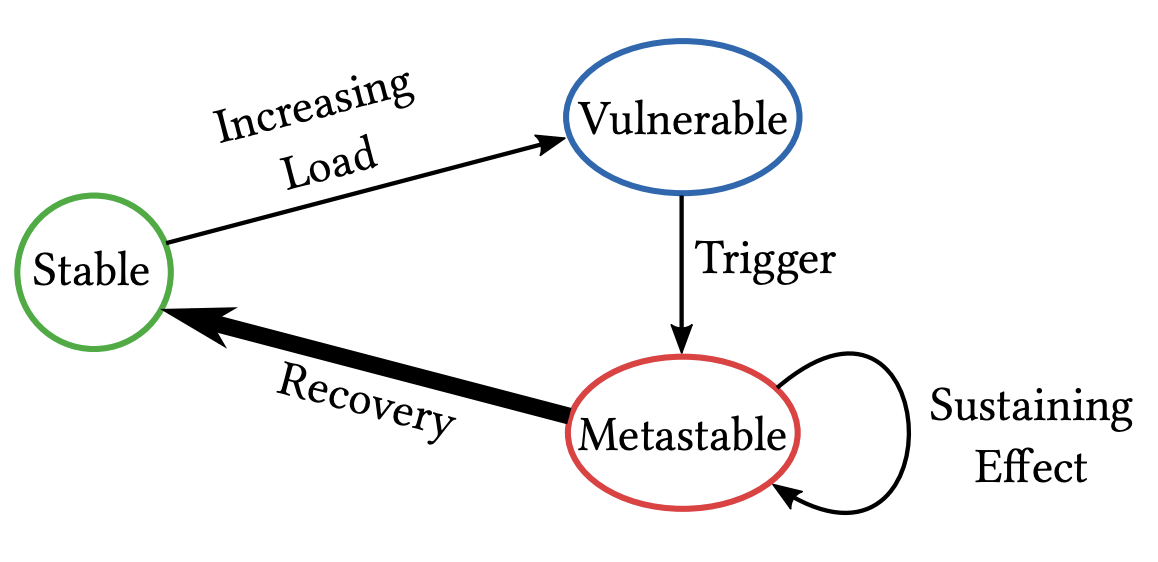
With a huge queue of leases to reestablish, the DWFM system has two possible transitions. One is a slow, gradual burn down of the lease backlog (recovery). The other is a congestive collapse, where the lease queue remains high (a “sustaining effect”) until manual intervention.
Unfortunately, the DWFM entered congestive collapse.
…, due to the large number of droplets, efforts to establish new droplet leases took long enough that the work could not be completed before they timed out. — AWS Summary
It’s most interesting here to consider why collapse occurred. Was the unit of work completion somehow O(queue depth), ie. instead of processing one lease at a time the DWFM processes an all-or-nothing block of leases? Or, did the DWFM become a thundering herd and overwhelm a downstream component between it and the Droplets?
The congestive collapse of EC2 could only be restored by manual intervention by engineers, where they restarted DWFM servers presumably to drop the in-memory queued lease work and restore goodput in the system.
For a while now I’ve eagerly followed the public blogging of Marc Brooker, a distinguished engineer at AWS with key contributions to Lambda, EBS, and EC2. I’m sure he’s wired up after this outage, because he has been evangelizing the analysis of metastable failure for years now.
The presence and peril of the metastable failure state has likely been widely known within AWS engineering leadership for around 4 years. And yet it bit them in their darling EC2. I eagerly await Marc’s blog post.
NLB
At around 16:00 UTC in the now internally famous #incident-41-hfm_failures incident channel I began investigating a degradation in our Sandbox product. It turned out that AWS NLB trouble was causing Modal clients to fail to establish a gRPC connection with api.modal.com (which points at NLB load balancers).
The NLB service went down because EC2 has a Network Manager responsible for propagating network configuration when new EC2 instances are created or instance transitions (e.g. stopping) occur, and this manager fell behind under the weight of backlogged work.
The most interesting bit of the NLB service outage was that the NLB healthcheck system received bad feedback because of network configuration staleness and incorrectly performed AZ failovers.
The alternating health check results increased the load on the health check subsystem, causing it to degrade, resulting in delays in health checks and triggering automatic AZ DNS failover to occur.
Under control systems analysis, the potential for bad feedback is exactly the kind of thing that gets designed for. The healthcheck system behaved exactly as intended giving the inputs it received— it was a reliable component interacting unsafely with a broken environment.
In their discussion of remediations, the line item for NLB is about control for bad feedback.
For NLB, we are adding a velocity control mechanism to limit the capacity a single NLB can remove when health check failures cause AZ failover.
Humble conclusions
You only get so many major AWS incidents in your career, so appreciate the ones that you get. AWS’s reliability is the best in the world. I have used all major US cloud providers for years now, and until Monday’s us-east-1 outage AWS was clearly the most reliable. This is perhaps their biggest reliability failure in a decade. We should learn something from it.
I disagree with the popular early explanations. The “brain drain” theory has a high burden of proof and very little evidence. It possible that brain drain delayed remediation—this was a 14 hour outage—but we can’t see their response timeline. There’s also no evidence that us-east-1, being the oldest region, suffered from its age.3 The systems involved (DynamoDB, DNS Enactor, DWFM) are probably running globally. Also, those suggesting AWS’s reliability has fallen behind its competitors are too hasty. GCP had a severe global outage just last June.
My main takeaway is that in our industry the design, implementation, and operation of production systems still regularly falls short of what we think we’re capable of. DynamoDB hit a fairly straightforward race condition and entered into unrecoverable state corruption. EC2 went into congestion collapse. NLB’s healthcheck system got misdirected by bad data. We’ve seen these before, we’ll see them again. We’re still early with the cloud.
Software systems are far more complex and buggy than we realize. Useful software systems, such as EC2, always operate in a degraded state with dozens of present or latent bugs and faults. The presence of constant safety, of the cherished five 9s, is not a miracle, but a very challenging design and operational endeavor.
Monday was a bad day for hyper-scaled distributed systems. But in in the long run the public cloud industry will root out its unsound design and operation. Today’s advanced correctness and reliability practices will become normal.
