
Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model…
18th November 2025
Google released Gemini 3 Pro today. Here’s the announcement from Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu, their developer blog announcement from Logan Kilpatrick, the Gemini 3 Pro Model Card, and their collection of 11 more articles. It’s a big release!
I had a few days of preview access to this model via AI Studio. The best way to describe it is that it’s Gemini 2.5 upgraded to match the leading rival models.
Gemini 3 has the same underlying characteristics as Gemini 2.5. The knowledge cutoff is the same (January 2025). It accepts 1 million input tokens, can output up to 64,000 tokens, and has multimodal inputs across text, images, audio, and video.
Benchmarks
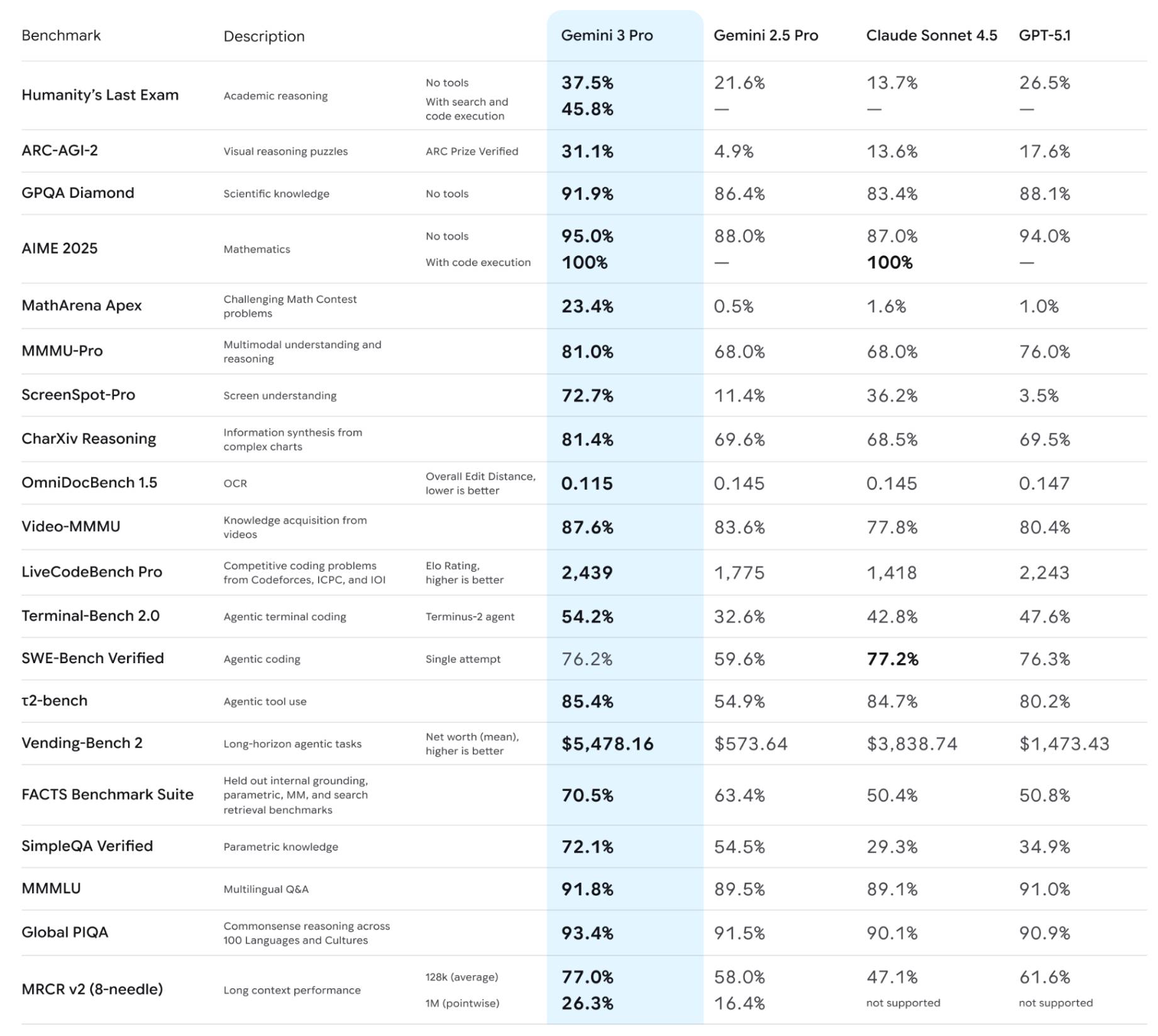
Google’s own reported numbers (in the model card) show it scoring slightly higher against Claude 4.5 Sonnet and GPT-5.1 against most of the standard benchmarks. As always I’m waiting for independent confirmation, but I have no reason to believe those numbers are inaccurate.
Pricing
It terms of pricing it’s a little more expensive than Gemini 2.5 but still cheaper than Claude Sonnet 4.5. Here’s how it fits in with those other leading models:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5.1 | $1.25 | $10.00 |
| Gemini 2.5 Pro | ≤ 200k tokens: $1.25 > 200k tokens: $2.50 | ≤ 200k tokens: $10.00 > 200k tokens: $15.00 |
| Gemini 3 Pro | ≤ 200k tokens: $2.00 > 200k tokens: $4.00 | ≤ 200k tokens: $12.00 > 200k tokens: $18.00 |
| Claude Sonnet 4.5 | ≤ 200k tokens: $3.00 > 200k tokens: $6.00 | ≤ 200k tokens: $15.00 > 200k tokens: $22.50 |
| Claude Opus 4.1 | $15.00 | $75.00 |
Trying it out against a complex image
That screenshot of the benchmarks from above looked like a good test for Gemini 3’s multimodal support. I fed it that image URL and asked it to generate alt text for the image:
llm -m gemini-3-pro-preview -a https://static.simonwillison.net/static/2025/gemini-3-benchmarks.jpg 'Alt text for this image, include all figures and make them comprehensible to a screen reader user'
Here’s what I got back:
A comprehensive table comparing four AI models across various performance benchmarks. The columns listed are: Benchmark Name, Description, Gemini 3 Pro (highlighted in blue), Gemini 2.5 Pro, Claude Sonnet 4.5, and GPT-5.1.
Humanity’s Last Exam (Academic reasoning)
- No tools: Gemini 3 Pro 37.5%, Gemini 2.5 Pro 21.6%, Claude Sonnet 4.5 13.7%, GPT-5.1 26.5%.
- With search and code execution: Gemini 3 Pro 45.8% (others have no data).
ARC-AGI-2 (Visual reasoning puzzles; ARC Prize Verified)
- Gemini 3 Pro 31.1%, Gemini 2.5 Pro 4.9%, Claude Sonnet 4.5 13.6%, GPT-5.1 17.6%.
GPQA Diamond (Scientific knowledge; No tools)
- Gemini 3 Pro 91.9%, Gemini 2.5 Pro 86.4%, Claude Sonnet 4.5 83.4%, GPT-5.1 88.1%.
AIME 2025 (Mathematics)
- No tools: Gemini 3 Pro 95.0%, Gemini 2.5 Pro 88.0%, Claude Sonnet 4.5 87.0%, GPT-5.1 94.0%.
- With code execution: Gemini 3 Pro 100%, Claude Sonnet 4.5 100%.
MathArena Apex (Challenging Math Contest problems)
- Gemini 3 Pro 23.4%, Gemini 2.5 Pro 0.5%, Claude Sonnet 4.5 1.6%, GPT-5.1 1.0%.
MMMU-Pro (Multimodal understanding and reasoning)
- Gemini 3 Pro 81.0%, Gemini 2.5 Pro 68.0%, Claude Sonnet 4.5 68.0%, GPT-5.1 76.0%.
ScreenSpot-Pro (Screen understanding)
- Gemini 3 Pro 72.7%, Gemini 2.5 Pro 11.4%, Claude Sonnet 4.5 36.2%, GPT-5.1 3.5%.
CharXiv Reasoning (Information synthesis from complex charts)
- Gemini 3 Pro 81.4%, Gemini 2.5 Pro 69.6%, Claude Sonnet 4.5 68.5%, GPT-5.1 69.5%.
OmniDocBench 1.5 (OCR; Overall Edit Distance, lower is better)
- Gemini 3 Pro 0.115, Gemini 2.5 Pro 0.145, Claude Sonnet 4.5 0.145, GPT-5.1 0.147.
Video-MMMU (Knowledge acquisition from videos)
- Gemini 3 Pro 87.6%, Gemini 2.5 Pro 83.6%, Claude Sonnet 4.5 77.8%, GPT-5.1 80.4%.
LiveCodeBench Pro (Competitive coding problems; Elo Rating, higher is better)
- Gemini 3 Pro 2,439; Gemini 2.5 Pro 1,775; Claude Sonnet 4.5 1,418; GPT-5.1 2,243.
Terminal-Bench 2.0 (Agentic terminal coding; Terminus-2 agent)
- Gemini 3 Pro 54.2%, Gemini 2.5 Pro 32.6%, Claude Sonnet 4.5 42.8%, GPT-5.1 47.6%.
SWE-Bench Verified (Agentic coding; Single attempt)
- Gemini 3 Pro 76.2%, Gemini 2.5 Pro 59.6%, Claude Sonnet 4.5 77.2%, GPT-5.1 76.3%.
t2-bench (Agentic tool use)
- Gemini 3 Pro 85.4%, Gemini 2.5 Pro 54.9%, Claude Sonnet 4.5 84.7%, GPT-5.1 80.2%.
Vending-Bench 2 (Long-horizon agentic tasks; Net worth (mean), higher is better)
- Gemini 3 Pro $5,478.16; Gemini 2.5 Pro $573.64; Claude Sonnet 4.5 $3,838.74; GPT-5.1 $1,473.43.
FACTS Benchmark Suite (Held out internal grounding, parametric, MM, and search retrieval benchmarks)
- Gemini 3 Pro 70.5%, Gemini 2.5 Pro 63.4%, Claude Sonnet 4.5 50.4%, GPT-5.1 50.8%.
SimpleQA Verified (Parametric knowledge)
- Gemini 3 Pro 72.1%, Gemini 2.5 Pro 54.5%, Claude Sonnet 4.5 29.3%, GPT-5.1 34.9%.
MMMLU (Multilingual Q&A)
- Gemini 3 Pro 91.8%, Gemini 2.5 Pro 89.5%, Claude Sonnet 4.5 89.1%, GPT-5.1 91.0%.
Global PIQA (Commonsense reasoning across 100 Languages and Cultures)
- Gemini 3 Pro 93.4%, Gemini 2.5 Pro 91.5%, Claude Sonnet 4.5 90.1%, GPT-5.1 90.9%.
MRCR v2 (8-needle) (Long context performance)
- 128k (average): Gemini 3 Pro 77.0%, Gemini 2.5 Pro 58.0%, Claude Sonnet 4.5 47.1%, GPT-5.1 61.6%.
- 1M (pointwise): Gemini 3 Pro 26.3%, Gemini 2.5 Pro 16.4%, Claude Sonnet 4.5 (not supported), GPT-5.1 (not supported).
I have not checked every line of this but a loose spot-check looks accurate to me.
That prompt took 1,105 input and 3,901 output tokens, at a cost of 5.6824 cents.
I ran this follow-up prompt:
llm -c 'Convert to JSON'
You can see the full output here, which starts like this:
{ "metadata": { "columns": [ "Benchmark", "Description", "Gemini 3 Pro", "Gemini 2.5 Pro", "Claude Sonnet 4.5", "GPT-5.1" ] }, "benchmarks": [ { "name": "Humanity's Last Exam", "description": "Academic reasoning", "sub_results": [ { "condition": "No tools", "gemini_3_pro": "37.5%", "gemini_2_5_pro": "21.6%", "claude_sonnet_4_5": "13.7%", "gpt_5_1": "26.5%" }, { "condition": "With search and code execution", "gemini_3_pro": "45.8%", "gemini_2_5_pro": null, "claude_sonnet_4_5": null, "gpt_5_1": null
}
]
},Analyzing a city council meeting
To try it out against an audio file I extracted the 3h33m of audio from the video Half Moon Bay City Council Meeting—November 4, 2025. I used yt-dlp to get that audio:
yt-dlp -x --audio-format m4a 'https://www.youtube.com/watch?v=qgJ7x7R6gy0'That gave me a 74M m4a file, which I ran through Gemini 3 Pro like this:
llm -m gemini-3-pro-preview -a /tmp/HMBCC\ 11⧸4⧸25\ -\ Half\ Moon\ Bay\ City\ Council\ Meeting\ -\ November\ 4,\ 2025\ \[qgJ7x7R6gy0\].m4a 'Output a Markdown transcript of this meeting. Include speaker names and timestamps. Start with an outline of the key meeting sections, each with a title and summary and timestamp and list of participating names. Note in bold if anyone raised their voices, interrupted each other or had disagreements. Then follow with the full transcript.'
That failed with an “Internal error encountered” message, so I shrunk the file down to a more manageable 38MB using ffmpeg:
ffmpeg -i "/private/tmp/HMB.m4a" -ac 1 -ar 22050 -c:a aac -b:a 24k "/private/tmp/HMB_compressed.m4a"Then ran it again like this (for some reason I had to use --attachment-type this time):
llm -m gemini-3-pro-preview --attachment-type /tmp/HMB_compressed.m4a 'audio/aac' 'Output a Markdown transcript of this meeting. Include speaker names and timestamps. Start with an outline of the key meeting sections, each with a title and summary and timestamp and list of participating names. Note in bold if anyone raised their voices, interrupted each other or had disagreements. Then follow with the full transcript.'
This time it worked! The full output is here, but it starts like this:
Here is the transcript of the Half Moon Bay City Council meeting.
Meeting Outline
1. Call to Order, Updates, and Public Forum
- Summary: Mayor Brownstone calls the meeting to order. City Manager Chidester reports no reportable actions from the closed session. Announcements are made regarding food insecurity volunteers and the Diwali celebration. During the public forum, Councilmember Penrose (speaking as a citizen) warns against autocracy. Citizens speak regarding lease agreements, downtown maintenance, local music events, and homelessness outreach statistics.
- Timestamp: 00:00:00—00:13:25
- Participants: Mayor Brownstone, Matthew Chidester, Irma Acosta, Deborah Penrose, Jennifer Moore, Sandy Vella, Joaquin Jimenez, Anita Rees.
2. Consent Calendar
- Summary: The Council approves minutes from previous meetings and a resolution authorizing a licensing agreement for Seahorse Ranch. Councilmember Johnson corrects a pull request regarding abstentions on minutes.
- Timestamp: 00:13:25—00:15:15
- Participants: Mayor Brownstone, Councilmember Johnson, Councilmember Penrose, Vice Mayor Ruddick, Councilmember Nagengast.
3. Ordinance Introduction: Commercial Vitality (Item 9A)
- Summary: Staff presents a new ordinance to address neglected and empty commercial storefronts, establishing maintenance and display standards. Councilmembers discuss enforcement mechanisms, window cleanliness standards, and the need for objective guidance documents to avoid subjective enforcement.
- Timestamp: 00:15:15—00:30:45
- Participants: Karen Decker, Councilmember Johnson, Councilmember Nagengast, Vice Mayor Ruddick, Councilmember Penrose.
4. Ordinance Introduction: Building Standards & Electrification (Item 9B)
- Summary: Staff introduces updates to the 2025 Building Code. A major change involves repealing the city’s all-electric building requirement due to the 9th Circuit Court ruling (California Restaurant Association v. City of Berkeley). Public speaker Mike Ferreira expresses strong frustration and disagreement with “unelected state agencies” forcing the City to change its ordinances.
- Timestamp: 00:30:45—00:45:00
- Participants: Ben Corrales, Keith Weiner, Joaquin Jimenez, Jeremy Levine, Mike Ferreira, Councilmember Penrose, Vice Mayor Ruddick.
5. Housing Element Update & Adoption (Item 9C)
- Summary: Staff presents the 5th draft of the Housing Element, noting State HCD requirements to modify ADU allocations and place a measure on the ballot regarding the “Measure D” growth cap. There is significant disagreement from Councilmembers Ruddick and Penrose regarding the State’s requirement to hold a ballot measure. Public speakers debate the enforceability of Measure D. Mike Ferreira interrupts the vibe to voice strong distaste for HCD’s interference in local law. The Council votes to adopt the element but strikes the language committing to a ballot measure.
- Timestamp: 00:45:00—01:05:00
- Participants: Leslie (Staff), Joaquin Jimenez, Jeremy Levine, Mike Ferreira, Councilmember Penrose, Vice Mayor Ruddick, Councilmember Johnson.
Transcript
Mayor Brownstone [00:00:00] Good evening everybody and welcome to the November 4th Half Moon Bay City Council meeting. As a reminder, we have Spanish interpretation services available in person and on Zoom.
Victor Hernandez (Interpreter) [00:00:35] Thank you, Mr. Mayor, City Council, all city staff, members of the public. [Spanish instructions provided regarding accessing the interpretation channel on Zoom and in the room.] Thank you very much.
Those first two lines of the transcript already illustrate something interesting here: Gemini 3 Pro chose NOT to include the exact text of the Spanish instructions, instead summarizing them as “[Spanish instructions provided regarding accessing the interpretation channel on Zoom and in the room.]”.
I haven’t spot-checked the entire 3hr33m meeting, but I’ve confirmed that the timestamps do not line up. The transcript closes like this:
Mayor Brownstone [01:04:00] Meeting adjourned. Have a good evening.
That actually happens at 3h31m5s and the mayor says:
Okay. Well, thanks everybody, members of the public for participating. Thank you for staff. Thank you to fellow council members. This meeting is now adjourned. Have a good evening.
I’m disappointed about the timestamps, since mismatches there make it much harder to jump to the right point and confirm that the summarized transcript is an accurate representation of what was said.
This took 320,087 input tokens and 7,870 output tokens, for a total cost of $1.42.
And a new pelican benchmark
Gemini 3 Pro has a new concept of a “thinking level” which can be set to low or high (and defaults to high). I tried my classic Generate an SVG of a pelican riding a bicycle prompt at both levels.
Here’s low—Gemini decided to add a jaunty little hat (with a comment in the SVG that says <!-- Hat (Optional Fun Detail) -->):

And here’s high. This is genuinely an excellent pelican, and the bicycle frame is at least the correct shape:
Honestly though, my pelican benchmark is beginning to feel a little bit too basic. I decided to upgrade it. Here’s v2 of the benchmark, which I plan to use going forward:
Generate an SVG of a California brown pelican riding a bicycle. The bicycle must have spokes and a correctly shaped bicycle frame. The pelican must have its characteristic large pouch, and there should be a clear indication of feathers. The pelican must be clearly pedaling the bicycle. The image should show the full breeding plumage of the California brown pelican.
For reference, here’s a photo I took of a California brown pelican recently (sadly without a bicycle):

Here’s Gemini 3 Pro’s attempt at high thinking level for that new prompt:

And for good measure, here’s that same prompt against GPT-5.1—which produced this dumpy little fellow:

And Claude Sonnet 4.5, which didn’t do quite as well:

Read the original article
Comments
The audio transcript exercise here is particularly interesting from a journalism perspective.
Summarizing a 3.5 hour council meeting is something of a holy grail of AI-assisted reporting. There are a LOT of meetings like that, and newspapers (especially smaller ones) can no longer afford to have a human reporter sit through them all.
I tried this prompt (against audio from https://www.youtube.com/watch?v=qgJ7x7R6gy0):
Here's the result: https://gist.github.com/simonw/0b7bc23adb6698f376aebfd700943...Output a Markdown transcript of this meeting. Include speaker names and timestamps. Start with an outline of the key meeting sections, each with a title and summary and timestamp and list of participating names. Note in bold if anyone raised their voices, interrupted each other or had disagreements. Then follow with the full transcript.I'm not sure quite how to grade it here, especially since I haven't sat through the whole 3.5 hour meeting video myself.
It appears to have captured the gist of the meeting very well, but the fact that the transcript isn't close to an exact match to what was said - and the timestamps are incorrect - means it's very hard to trust the output. Could it have hallucinated things that didn't happen? Those can at least be spotted by digging into the video (or the YouTube transcript) to check that they occurred... but what about if there was a key point that Gemini 3 omitted entirely?
By luke-stanley 2025-11-190:43 Simon, sorry I didn't get around to answering your question on post-t5 encoder-decoders from the Markdown Lethal Trifecta prompt injection post. (https://news.ycombinator.com/item?id=45724941)
Since the plain decoder models stole the show, Google DeepMind demonstrated a way to adapt LLMs,adding a T5 encoder to an existing normal Gemma model to get the benefits of the more grounded text-to-text tasks WITHOUT instruction tuning (and the increased risk of prompt injection). They also have a few different kinds they shared on HuggingFace. I didn't get around to fine-tuning the weights of one for summarisation yet but it could well be a good way for more reliable summarisation. I did try out some models for inference though and made a Gist here, which is useful since I found the HF default code example a bit broken:
https://gist.github.com/lukestanley/ee89758ea315b68fd66ba52c...
Google's minisite: https://deepmind.google/models/gemma/t5gemma/ Paper: https://arxiv.org/abs/2504.06225
Here is one such model that didn't hallucinate and actually did summarise on HF: https://huggingface.co/google/t5gemma-l-l-prefixlm
By potatolicious 2025-11-1820:383 reply You really want to break a task like this down to constituent parts - especially because in this case the "end to end" way of doing it (i.e., raw audio to summary) doesn't actually get you anything.
IMO the right way to do this is to feed the audio into a transcription model, specifically one that supports diarization (separation of multiple speakers). This will give you a high quality raw transcript that is pretty much exactly what was actually said.
It would be rough in places (i.e., Speaker 1, Speaker 2, etc. rather than actual speaker names)
Then you want to post-process with a LLM to re-annotate the transcript and clean it up (e.g., replace "Speaker 1" with "Mayor Bob"), and query against it.
I see another post here complaining that direct-to-LLM beats a transcription model like Whisper - I would challenge that. Any modern ASR model will do a very, very good job with 95%+ accuracy.
Which diarization models would you recommend, especially for running on macOS?
(Update: I just updated MacWhisper and it can now run Parakeet which appears to have decent diarization built in, screenshot here: https://static.simonwillison.net/static/2025/macwhisper-para... )
By atonse 2025-11-191:07 I use parakeet daily (with MacWhisper) to transcribe my meetings. It works really well, even with the speaker segmentation.
Why can't Gemini, the product, do that by itself? Isn't the point of all this AI hype to easily automate things with low effort?
By vlovich123 2025-11-1822:411 reply Multimodal models are only now starting to come into the space and even then I don’t know they really support diarization yet (and often multimodal is thinking+speech/images, not sure about audio).
I think they weren’t asking “why can’t Gemini 3, the model, just do good transcription,” they were asking “why can’t Gemini, the API/app, recognize the task as something best solved not by a single generic model call, but by breaking it down into an initial subtask for a specialized ASR model followed by LLM cleanup, automatically, rather than me having to manually break down the task to achieve that result.”
By darkwater 2025-11-199:18 Exactly that. There is a layer (or more than one) between the user submitting the YT video and the actual model "reading" it and writing the digest. If the required outcome is to write a digest of a 3 hours video, and to achieve the best result it needs to pass first into a specialized transcription model and then in a generic one that can summarize, well, why Google/Gemini doesn't do it out of the box? I mean, I'm probably oversimplifying but if you read the presentation post by Pichar itself, well, I would not expect less than this.
By refulgentis 2025-11-190:111 reply Speech recognition, as described above, is an AI too :) These LLMs are huge AIs that I guess could eventually replace all other AIs, but that’s sort of speculation no one with knowledge of the field would endorse.
Separately, in my role as wizened 16 year old veteran of HN: it was jarring to read that. There’s a “rules” section, but don’t be turned off by the name, it is more like a nice collection of guidelines of how to interact in a way that encourages productive discussion that illuminates. One of the key rules is not to interpret things weakly. Here, someone spelled out exactly how to do it, and we shouldn’t then assume its not AI, then tie to a vague demeaning description of “AI hype”, then ask an unanswerable question of what’s the point of “AI hype”.
If you’re nontechnical, to be clear, it would be hard to be nontechnical and new to HN and know how to ask that a different way, I suppose.
By darkwater 2025-11-199:20 > There’s a “rules” section, but don’t be turned off by the name, it is more like a nice collection of guidelines of how to interact in a way that encourages productive discussion that illuminates. One of the key rules is not to interpret things weakly. Here, someone spelled out exactly how to do it, and we shouldn’t then assume its not AI, then tie to a vague demeaning description of “AI hype”, then ask an unanswerable question of what’s the point of “AI hype”.
I think you misunderstood my comment. https://news.ycombinator.com/item?id=45973656 has got the right reading of it.
By sillyfluke 2025-11-1821:092 reply I'm curious when we started conflating transcription and summarization when discussing this LLM mess, or maybe I'm confused about the output simonw is quoting as "the transcript" which starts off not with the actual transcript but with a Meeting Outline and Summarization sections?
LLM summarization is utterly useless when you want 100% accuracy on the final binding decisions on things like council meeting decisions. My experience has been that LLMs cannot be trusted to follow convulted discussions, including revisting earlier agenda items later in the meeting etc.
With transcriptions, the catastrophic risk is far less since I'm doing the summarizing from a transcript myself. But in that case, for an auto-generated transcript, I'll take correct timestamps with gibberish sounding sentences over incorrect timestamps with "convincing" sounding but halluncinated sentences any day.
Any LLM summarization of a sufficiently important meeting requires second-by-second human verification of the audio recording. I have yet to see this convincingly refuted (ie, an LLM model that maintains 100% accuracy on summarizing meeting decisions consistently).
By Royce-CMR 2025-11-1822:31 This is a high area of focus for me and I agree: following a complex convo, especially when it gets picked up again 20-30 min later, is difficult.
But not impossible. I’ve had success with prompts that ID all topics and then map all conversation tied to each topic (each seperate LLM queries) and then pulling together summary and conclusions by topic.
I’ve also had success with one shot prompts - especially with the right context on the event and phrasing shared. But honestly I end up spending about 5-10 min reviewing and cleaning up the output before solid.
But that’s worlds better than attending the event, and then manually pulling together notes from your fast in flight shorthand.
(Former BA, ran JADs etc, lived and died by accuracy and right color / expression / context in notes)
By simonw 2025-11-1821:10 That's why I shared these results. Understanding the difference between LLM summarization and exact transcriptions is really important for this kind of activity.
By byt3bl33d3r 2025-11-1819:571 reply I’ve been meaning to create & publish a structured extraction benchmark for a while. Using LLMs to extract info/entities/connections from large amounts of unstructured data is also a huge boon to AI-assisted reporting and has also a number of cybersecurity applications. Gemini 2.5 was pretty good but so far I have yet to see an LLM that can reliably , accurately and consistently do this
By simonw 2025-11-1820:16 This would be extremely useful. I think this is one of the most commercially valuable uses of these kinds of models, having more solid independent benchmarks would be great.
By rahimnathwani 2025-11-1820:012 reply For this use case, why not use Whisper to transcribe the audio, and then an LLM to do a second step (summarization or answering questions or whatever)?
If you need diarization, you can use something like https://github.com/m-bain/whisperX
By pants2 2025-11-1820:14 Whisper simply isn't very good compared to LLM audio transcription like gpt-4o-transcribe. If Gemini 3 is even better it's a game-changer.
By crazysim 2025-11-1820:23 Since Gemini seems to be sucking at timestamps, perhaps Whisper can be used to help ground that as an additional input alongside the audio.
By anilgulecha 2025-11-193:48 We've done some transcription exercises. The way to get the timestamps to line is : 1) break up the audio into minutes, and pass it in, one after another, so the chat completions prompt looks like: Here's minute 1 of audio [ffmpeg 1st minute cut out.wav] Here's minute 2 of audio [ffmpeg 2nd minute cut out.wav] Here's minute 3 of audio [ffmpeg 3rd minute cut out.wav] and so on..
The cutting step is simple, and token count is pretty much the same, but the crucial additional detail allows for excellent transcription fidelity time wise.
We've also experimented passing in regular TTS (non-llm) transcript for reference, which again helps the LLM do better.
By theshrike79 2025-11-207:48 This is a Google notebook on multimodal transcription from a training session they do: https://colab.research.google.com/github/GoogleCloudPlatform...
It goes through the video analysis process and terminology step by step. You need to say "timecode" instead of "timestamp" so the LLM aligns better to AV-stuff more than programming (weird, right?)
Basically you need two to three passes to get a proper transcription
1. just listen and identify voices, give them some kind of ID 2. Maybe watch the video and see if the people have name tags on the table in front of them or there's an on-screen overlay (news or interviews) 3. Last pass, go through the transcription and map voices+ids to actual names
By WesleyLivesay 2025-11-1819:55 I think it appears to have done a good job of summarizing the points that it summarize, at least judging from my quick watch of a few sections and from the YT Transcript (which seems quite accurate).
Almost makes me wonder if it is behind the scenes doing something similar to: rough transcript -> Summaries -> transcript with timecodes (runs out of context) -> throws timestamps that it has on summaries.
I would be very curious to see if it does better on something like an hour long chunk of audio, to see if it is just some sort of context issue. Or if this same audio was fed to it in say 45 minute chunks to see if the timestamps fix themselves.
By luke-stanley 2025-11-190:59 I'd lower the temperature and try DSPy Refine loop on it (or similar). Using audio encoder-decoder models and segmentation are good things to try too. A length mismatch would be bad. DSPy has optimisers. It could probably optimise well with length match heuristic, there is probably a good Shannon entropy rule.
By mistercheph 2025-11-1820:001 reply For this use case I think best bet is still a toolchain with a transcription model like whisper fed into an LLM to summarize
By simonw 2025-11-1820:02 Yeah I agree. I ran Whisper (via MacWhisper) on the same video and got back accurate timestamps.
The big benefit of Gemini for this is that it appears to do a great job of speaker recognition, plus it can identify when people interrupt each other or raise their voices.
The best solution would likely include a mixture of both - Gemini for the speaker identification and tone-of-voice stuff, Whisper or NVIDIA Parakeet or similar for the transcription with timestamps.
By Workaccount2 2025-11-1820:072 reply My assumption is that Gemini has no insight into the time stamps, and instead is ballparking it based on how much context has been analyzed up to that point.
I wonder if you put the audio into a video that is nothing but a black screen with a timer running, it would be able to correctly timestamp.
By simonw 2025-11-1820:19 The Gemini documentation specifically mentions timestamp awareness here: https://ai.google.dev/gemini-api/docs/audio
By minimaxir 2025-11-1820:28 Per the docs, Gemini represents each second of audio as 32 tokens. Since it's a consistent amount, as long as the model is trained to understand the relation between timestamps and the number of tokens (which per Simon's link it does), it should be able to infer the correct amount of seconds.
By barapa 2025-11-192:57 We have done a lot of work solving this exact challenge at legaide.ai. I was both sad and relieved when gemini 3 didn't deprecate our startup.
Does anyone benchmark these models for text-to-speech using traditional word-error-rates? It seems audio-input Gemini is a lot cheaper than Google Speech-to-text.
By simonw 2025-11-1820:18 Here's one: https://voicewriter.io/speech-recognition-leaderboard
"Real-World Speech-to-text API Leaderboard" - it includes scores for Gemini 2.5 Pro and Flash.
Just checking, but did you verify that the converted ffmpeg audio wasn't around an hour long? Maybe ffmpeg sped it up when converting?
By simonw 2025-11-190:12 Here is the file I used, it is the expected length https://static.simonwillison.net/static/2025/HMB-nov-4-2025....
By leetharris 2025-11-1820:49 I used to work in ASR. Due to the nature of current multimodal architectures, it is unlikely we'll ever see accurate timestamps over a longer horizon. You're better off using encoder-decoder ASR architectures, then using traditional diarization using embedding clustering, then using a multimodal model to refine it, then use a forced alignment technique (maybe even something pre-NN) to get proper timestamps and reconciling it at the end.
These things are getting really good at just regular transcription (as long as you don't care about verbatimicity), but every additional dimension you add (timestamps, speaker assignment, etc) will make the others worse. These work much better as independent processes that then get reconciled and refined by a multimodal LLM.
If anyone enjoys cheeky mischief targeting LLM benchmark hackers: https://github.com/scosman/pelicans_riding_bicycles
I'll need to update for V2!
By yberreby 2025-11-190:20 Delightfully evil.

{kind=link}