
Like many organizations, Wiki Education has grappled with generative AI, its impacts, opportunities, and threats, for several years. As an organization that runs large-scale programs to bring new editors to Wikipedia (we’re responsible for about 19% of all new active editors on English Wikipedia), we have deep understanding of what challenges face new content contributors to Wikipedia — and how to support them to successfully edit. As many people have begun using generative AI chatbots like ChatGPT, Gemini, or Claude in their daily lives, it’s unsurprising that people will also consider using them to help draft contributions to Wikipedia. Since Wiki Education’s programs provide a cohort of content contributors whose work we can evaluate, we’ve looked into how our participants are using GenAI tools.
We are choosing to share our perspective through this blog post because we hope it will help inform discussions of GenAI-created content on Wikipedia. In an open environment like the Wikimedia movement, it’s important to share what you’ve learned. In this case, we believe our learnings can help Wikipedia editors who are trying to protect the integrity of content on the encyclopedia, Wikipedians who may be interested in using generative AI tools themselves, other program leaders globally who are trying to onboard new contributors who may be interested in using these tools, and the Wikimedia Foundation, whose product and technology team builds software to help support the development of high-quality content on Wikipedia.
Our fundamental conclusion about generative AI is: Wikipedia editors should never copy and paste the output from generative AI chatbots like ChatGPT into Wikipedia articles.
Let me explain more.
AI detection and investigation
Since the launch of ChatGPT in November 2022, we’ve been paying close attention to GenAI-created content, and how it relates to Wikipedia. We’ve spot-checked work of new editors from our programs, primarily focusing on citations to ensure they were real and not hallucinated. We experimented with tools ourselves, we led video sessions about GenAI for our program participants, and we closely tracked on-wiki policy discussions around GenAI. Currently, English Wikipedia prohibits the use of generative AI to create images or in talk page discussions, and recently adopted a guideline against using large language models to generate new articles.
As our Wiki Experts Brianda Felix and Ian Ramjohn worked with program participants throughout the first half of 2025, they found more and more text bearing the hallmarks of generative AI in article content, like bolded words or bulleted lists in odd places. But the use of generative AI wasn’t necessarily problematic, as long as the content was accurate. Wikipedia’s open editing process encourages stylistic revisions to factual text to better fit Wikipedia’s style.
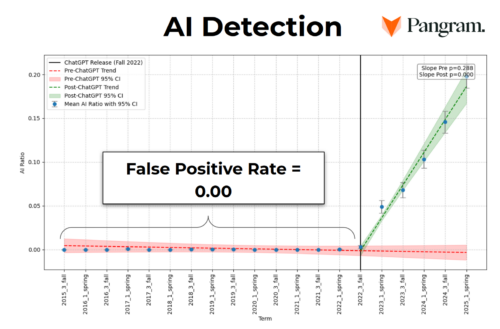
But was the text factually accurate? This fundamental question led our Chief Technology Officer, Sage Ross, to investigate different generative AI detectors. He landed on a tool called Pangram, which we have found to be highly accurate for Wikipedia text. Sage generated a list of all the new articles created through our work since 2022, and ran them all through Pangram. A total of 178 out of the 3,078 articles came back as flagged for AI — none before the launch of ChatGPT in late 2022, with increasing percentages term over term since then. About half of our staff spent a month during summer 2025 painstakingly reviewing the text from these 178 articles.
Based on the discourse around AI hallucinations, we were expecting these articles to contain citations to sources that didn’t exist, but this wasn’t true: only 7% of the articles had fake sources. The rest had information cited to real, relevant sources.
Far more insidious, however, was something else we discovered: More than two-thirds of these articles failed verification. That means the article contained a plausible-sounding sentence, cited to a real, relevant-sounding source. But when you read the source it’s cited to, the information on Wikipedia does not exist in that specific source. When a claim fails verification, it’s impossible to tell whether the information is true or not. For most of the articles Pangram flagged as written by GenAI, nearly every cited sentence in the article failed verification.
This finding led us to invest significant staff time into cleaning up these articles — far more than these editors had likely spent creating them. Wiki Education’s core mission is to improve Wikipedia, and when we discover our program has unknowingly contributed to misinformation on Wikipedia, we are committed to cleaning it up. In the clean-up process, Wiki Education staff moved more recent work back to sandboxes, we stub-ified articles that passed notability but mostly failed verification, and we PRODed some articles that from our judgment weren’t salvageable. All these are ways of addressing Wikipedia articles with flaws in their content. (While there are many grumblings about Wikipedia’s deletion processes, we found several of the articles we PRODed due to their fully hallucinated GenAI content were then de-PRODed by other editors, showing the diversity of opinion about generative AI among the Wikipedia community.
Revising our guidance
Given what we found through our investigation into the work from prior terms, and given the increasing usage of generative AI, we wanted to proactively address generative AI usage within our programs. Thanks to in-kind support from our friends at Pangram, we began running our participants’ Wikipedia edits, including in their sandboxes, through Pangram nearly in real time. This is possible because of the Dashboard course management platform Sage built, which tracks edits and generates tickets for our Wiki Experts based on on-wiki edits.
We created a brand-new training module on Using generative AI tools with Wikipedia. This training emphasizes where participants could use generative AI tools in their work, and where they should not. The core message of these trainings is, do not copy and paste anything from a GenAI chatbot into Wikipedia.
We crafted a variety of automated emails to participants who Pangram detected were adding text created by generative AI chatbots. Sage also recorded some videos, since many young people are accustomed to learning via video rather than reading text. We also provided opportunities for engagement and conversation with program participants.
Our findings from the second half of 2025
In total, we had 1,406 AI edit alerts in the second half of 2025, although only 314 of these (or 22%) were in the article namespace on Wikipedia (meaning edits to live articles). In most cases, Pangram detected participants using GenAI in their sandboxes during early exercises, when we ask them to do things like choose an article, evaluate an article, create a bibliography, and outline their contribution.
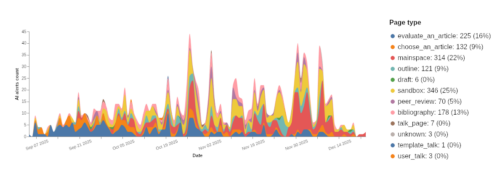
Pangram struggled with false positives in a few sandbox scenarios:
- Bibliographies, which are often a combination of human-written prose (describing a source and its relevance) and non-prose text (the citation for a source, in some standard format)
- Outlines with a high portion of non-prose content (such as bullet lists, section headers, text fragments, and so on)
We also had a handful of cases where sandboxes were flagged for AI after a participant copied an AI-written section from an existing article to use as a starting point to edit or to expand. (This isn’t a flaw of Pangram, but a reminder of how much AI-generated content editors outside our programs are adding to Wikipedia!)
In broad strokes, we found that Pangram is great at analyzing plain prose — the kind of sentences and paragraphs you’ll find in the body of a Wikipedia article — but sometimes it gets tripped up by formatting, markup, and non-prose text. Early on, we disabled alert emails for participants’ bibliography and outline exercises, and throughout the end of 2025, we refined the Dashboard’s preprocessing steps to extract the prose portions of revisions and convert them to plain text before sending them to Pangram.
Many participants also reported “just using Grammarly to copy edit.” In our experience, however, the smallest fixes done with Grammarly never trigger Pangram’s detection, but if you use its more advanced content creation features, the resulting text registers as being AI generated.
But overwhelmingly, we were pleased with Pangram’s results. Our early interventions with participants who were flagged as using generative AI for exercises that would not enter mainspace seemed to head off their future use of generative AI. We supported 6,357 new editors in fall 2025, and only 217 of them (or 3%) had multiple AI alerts. Only 5% of the participants we supported had mainspace AI alerts. That means thousands of participants successfully edited Wikipedia without using generative AI to draft their content.
For those who did add GenAI-drafted text, we ensured that the content was reverted. In fact, participants sometimes self-reverted once they received our email letting them know Pangram had detected their contributions as being AI created. Instructors also jumped in to revert, as did some Wikipedians who found the content on their own. Our ticketing system also alerted our Wiki Expert staff, who reverted the text as soon as they could.
While some instructors in our Wikipedia Student Program had concerns about AI detection, we had a lot of success focusing the conversation on the concept of verifiability. If the instructor as subject matter expert could attest the information was accurate, and they could find the specific facts in the sources they were cited to, we permitted text to come back to Wikipedia. However, the process of attempting to verify student-created work (which in many cases the students swore they’d written themselves) led many instructors to realize what we had found in our own assessment: In their current states, GenAI-powered chatbots cannot write factually accurate text for Wikipedia that is verifiable.
We believe our Pangram-based detection interventions led to fewer participants adding GenAI-created content to Wikipedia. Following the trend lines, we anticipated about 25% of participants to add GenAI content to Wikipedia articles; instead, it was only 5%, and our staff were able to revert all problematic content.
I’m deeply appreciative of everyone who made this success possible this term: Participants who followed our recommendations, Pangram who gave us access to their detection service, Wiki Education staff who did the heavy lift of working with all of the positive detections, and the Wikipedia community, some of whom got to the problematic work from our program participants before we did.
How can generative AI help?
So far, I’ve focused on the problems with generative AI-created content. But that’s not all these tools can do, and we did find some ways they were useful. Our training module encourages editors — if their institution’s policies permit it — to consider using generative AI tools for:
- Identifying gaps in articles
- Finding access to sources
- Finding relevant sources
To evaluate the success of these use scenarios, we worked directly with 7 of the classes we supported in fall 2025 in our Wikipedia Student Program. We asked students to anonymously fill out a survey every time they used generative AI tools in their Wikipedia work. We asked what tool they used, what prompt they used, how they used the output, and whether they found it helpful. While some students filled the survey out multiple times, others filled it out once. We had 102 responses reporting usage at various stages in the project. Overwhelmingly, 87% of the responses who reported using generative AI said it was helpful for them in the task. The most popular tool by far was ChatGPT, with Grammarly as a distant second, and the others in the single-digits of usage.
Students reported AI tools very helpful in:
- Identifying articles to work on that were relevant to the course they were taking
- Highlighting gaps within existing articles, including missing sections or more recent information that was missing
- Finding reliable sources that they hadn’t already located
- Pointing to which database a certain journal article could be found
- When prompted with the text they had drafted and the checklist of requirements, evaluating the draft against those requirements
- Identifying categories they could add to the article they’d edited
- Correcting grammar and spelling mistakes
Critically, no participants reported using AI tools to draft text for their assignments. One student reported: “I pasted all of my writing from my sandbox and said ‘Put this in a casual, less academic tone’ … I figured I’d try this but it didn’t sound like what I normally write and I didn’t feel that it captured what I was trying to get across so I scrapped it.”
While this was an informal research project, we received enough positive feedback from it to believe using ChatGPT and other tools can be helpful in the research stage if editors then critically evaluate the output they get, instead of blindly accepting it. Even participants who found AI helpful reported that they didn’t use everything it gave them, as some was irrelevant. Undoubtedly, it’s crucial to maintain the human thinking component throughout the process.
What does this all mean for Wiki Education?
My conclusion is that, at least as of now, generative AI-powered chatbots like ChatGPT should never be used to generate text for Wikipedia; too much of it will simply be unverifiable. Our staff would spend far more time attempting to verify facts in AI-generated articles than if we’d simply done the research and writing ourselves.
That being said, AI tools can be helpful in the research process, especially to help identify content gaps or sources, when used in conjunction with a human brain that carefully evaluates the information. Editors should never simply take a chatbot’s suggestion; instead, if they want to use a chatbot, they should use it as a brainstorm partner to help them think through their plans for an article.
To date, Wiki Education’s interventions as our program participants edit Wikipedia show promise for keeping unverifiable, GenAI-drafted content off Wikipedia. Based on our experiences in the fall term, we have high confidence in Pangram as a detector of AI content, at least in Wikipedia articles. We will continue our current strategy in 2026 (with more small adjustments to make the system as reliable as we can).
More generally, we found participants had less AI literacy than popular discourse might suggest. Because of this, we created a supplemental large language models training that we’ve offered as an optional module for all participants. Many participants indicated that they found our guidance regarding AI to be welcome and helpful as they attempt to navigate the new complexities created by AI tools.
We are also looking forward to more research on our work. A team of researchers — Francesco Salvi and Manoel Horta Ribeiro at Princeton University, Robert Cummings at the University of Mississippi, and Wiki Education’s Sage Ross — have been looking into Wiki Education’s Wikipedia Student Program editors’ use of generative AI over time. Preliminary results have backed up our anecdotal understanding, while also revealing nuances of how text produced by our students over time has changed with the introduction of GenAI chatbots. They also confirmed our belief in Pangram: After running student edits from 2015 up until the launch of ChatGPT through Pangram, without any date information involved, the team found Pangram correctly identified that it was all 100% human written. This research will continue into the spring, as the team explores ways of unpacking the effects of AI on different aspects of article quality.
And, of course, generative AI is a rapidly changing field. Just because these were our findings in 2025 doesn’t mean they will hold true throughout 2026. Wiki Education remains committed to monitoring, evaluating, iterating, and adapting as needed. Fundamentally, we are committed to ensuring we add high quality content to Wikipedia through our programs. And when we miss the mark, we are committed to cleaning up any damage.
What does this all mean for Wikipedia?
While I’ve focused this post on what Wiki Education has learned from working with our program participants, the lessons are extendable to others who are editing Wikipedia. Already, 10% of adults worldwide are using ChatGPT, and drafting text is one of the top use cases. As generative AI usage proliferates, its usage by well-meaning people to draft content for Wikipedia will as well. It’s unlikely that longtime, daily Wikipedia editors would add content copied and pasted from a GenAI chatbot without verifying all the information is in the sources it cites. But many casual Wikipedia contributors or new editors may unknowingly add bad content to Wikipedia when using a chatbot. After all, it provides what looks like accurate facts, cited to what are often real, relevant, reliable sources. Most edits we ended up reverting seemed acceptable with a cursory review; it was only after we attempted to verify the information that we understood the problems.
Because this unverifiable content often seems okay at first pass, it’s critical for Wikipedia editors to be equipped with tools like Pangram to more accurately detect when they should take a closer look at edits. Automating review of text for generative AI usage — as Wikipedians have done for copyright violation text for years — would help protect the integrity of Wikipedia content. In Wiki Education’s experience, Pangram is a tool that could provide accurate assessments of text for editors, and we would love to see a larger scale version of the tool we built to evaluate edits from our programs to be deployed across all edits on Wikipedia. Currently, editors can add a warning banner that highlights that the text might be LLM generated, but this is based solely on the assessment of the person adding the banner. Our experience suggests that judging by tone alone isn’t enough; instead, tools like Pangram can flag highly problematic information that should be reverted immediately but that might sound okay.
We’ve also found success in the training modules and support we’ve created for our program participants. Providing clear guidance — and the reason why that guidance exists — has been key in helping us head off poor usage of generative AI text. We encourage Wikipedians to consider revising guidance to new contributors in the welcome messages to emphasize the pitfalls of adding GenAI-drafted text. Software aimed at new contributors created by the Wikimedia Foundation should center starting with a list of sources and drawing information from them, using human intellect, instead of generative AI, to summarize information. Providing guidance upfront can help well-meaning contributors steer clear of bad GenAI-created text.
Wikipedia recently celebrated its 25th birthday. For it to survive into the future, it will need to adapt as technology around it changes. Wikipedia would be nothing without its corps of volunteer editors. The consensus-based decision-making model of Wikipedia means change doesn’t come quickly, but we hope this deep-dive will help spark a conversation about changes that are needed to protect Wikipedia into the future.
