Every token you send to an LLM costs money. Every token increases latency. And past a certain point, every additional token makes your agent dumber. This is the triple penalty of context bloat: higher costs, slower responses, and degraded performance through context rot, where the agent gets lost in its own accumulated noise.
Context engineering is very important. The difference between a $0.50 query and a $5.00 query is often just how thoughtfully you manage context. Here’s what I’ll cover:
Stable Prefixes for KV Cache Hits - The single most important optimization for production agents
Append-Only Context - Why mutating context destroys your cache hit rate
Store Tool Outputs in the Filesystem - Cursor’s approach to avoiding context bloat
Design Precise Tools - How smart tool design reduces token consumption by 10x
Clean Your Data First (Maximize Your Deductions) - Strip the garbage before it enters context
Delegate to Cheaper Subagents (Offshore to Tax Havens) - Route token-heavy operations to smaller models
Reusable Templates Over Regeneration (Standard Deductions) - Stop regenerating the same code
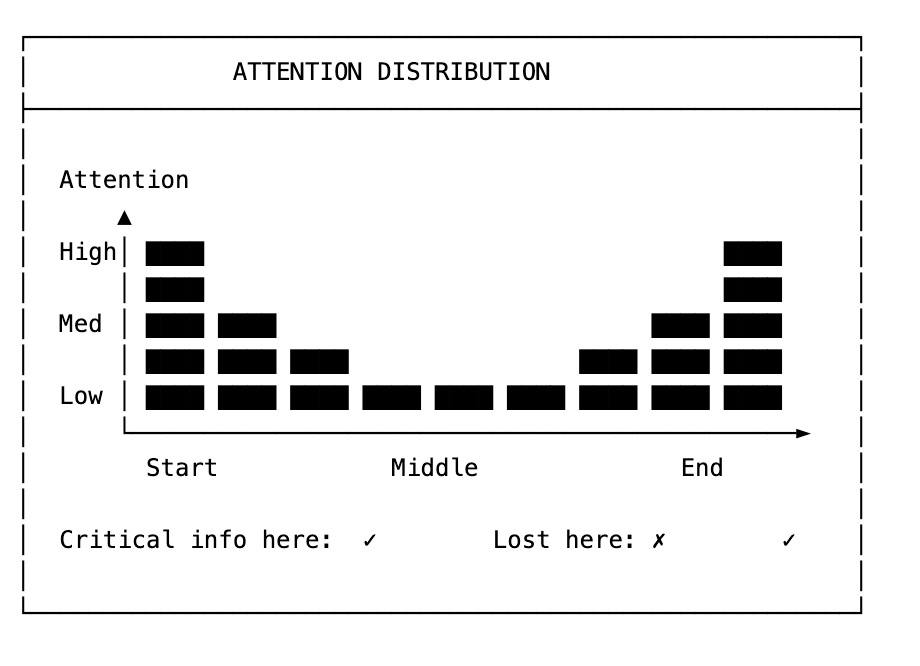
The Lost-in-the-Middle Problem - Strategic placement of critical information
Server-Side Compaction (Depreciation) - Let the API handle context decay automatically
Output Token Budgeting (Withholding Tax) - The most expensive tokens are the ones you generate
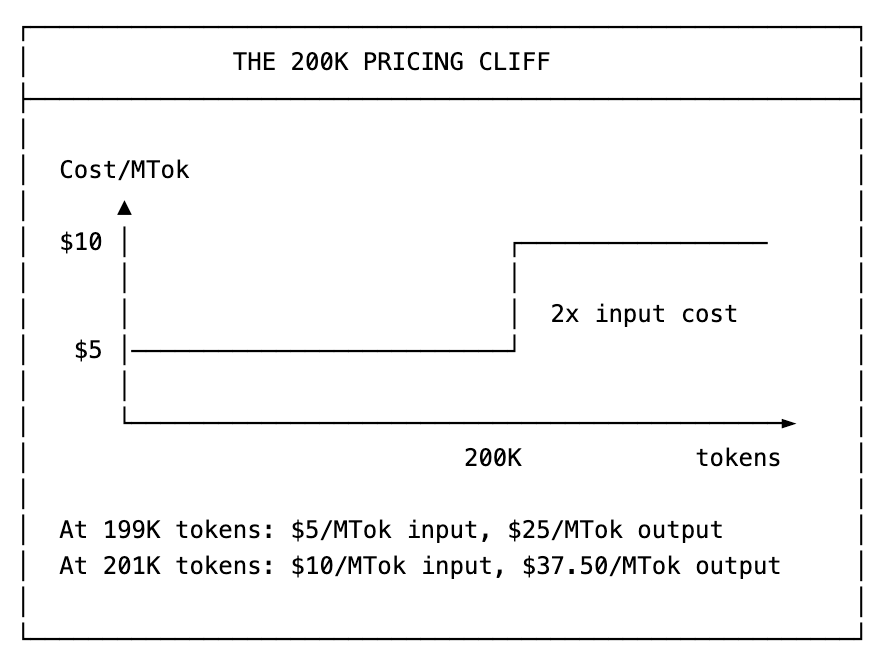
The 200K Pricing Cliff (The Tax Bracket) - The tax bracket that doubles your bill overnight
Parallel Tool Calls (Filing Jointly) - Fewer round trips, less context accumulation
Application-Level Response Caching (Tax-Exempt Status) - The cheapest token is the one you never send
With Claude Opus 4.6, the math is brutal:
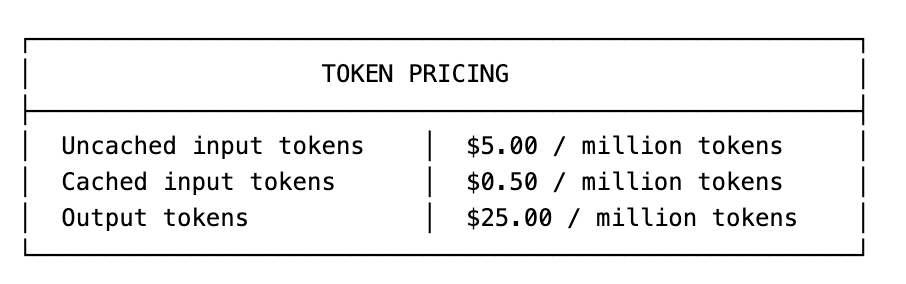
That’s a 10x difference between cached and uncached inputs. Output tokens cost 5x more than uncached inputs. Most agent builders focus on prompt engineering while hemorrhaging money on context inefficiency.
In most agent workflows, context grows substantially with each step while outputs remain compact. This makes input token optimization critical: a typical agent task might involve 50 tool calls, each accumulating context.
The performance penalty is equally severe. Research shows that past 32K tokens, most models show sharp performance degradation. Your agent isn’t just getting expensive. It’s getting confused.
This is the single most important metric for production agents: KV cache hit rate.
TheManus team considers this the most important optimization for their agent infrastructure, and I agree completely. The principle is simple: LLMs process prompts autoregressively, token by token. If your prompt starts identically to a previous request, the model can reuse cached key-value computations for that prefix.
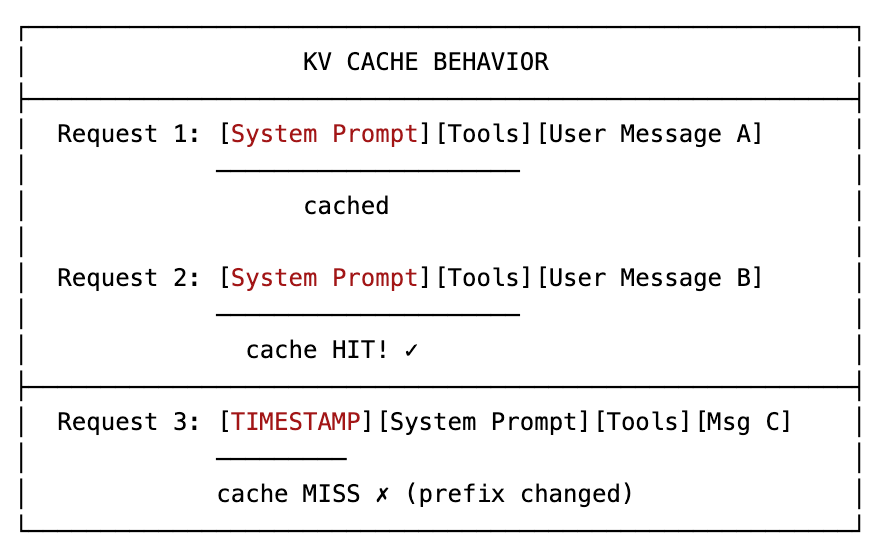
The killer of cache hit rates? Timestamps.
A common mistake is including a timestamp at the beginning of the system prompt. It’s a simple mistake but the impact is massive. The key is granularity: including the date is fine. Including the hour is acceptable since cache durations are typically 5 minutes (Anthropic default) to 10 minutes (OpenAI default), with longer options available.
But never include seconds or milliseconds. A timestamp precise to the second guarantees every single request has a unique prefix. Zero cache hits. Maximum cost.
Move all dynamic content (including timestamps) to the END of your prompt. System instructions, tool definitions, few-shot examples, all of these should come first and remain identical across requests.
For distributed systems, ensure consistent request routing. Use session IDs to route requests to the same worker, maximizing the chance of hitting warm caches.
Context should be append-only. Any modification to earlier content invalidates the KV cache from that point forward.
This seems obvious but the violations are subtle:

The tool definition problem is particularly insidious. If you dynamically add or remove tools based on context, you invalidate the cache for everything after the tool definitions.
Manus solved this elegantly: instead of removing tools, they mask token logits during decoding to constrain which actions the model can select. The tool definitions stay constant (cache preserved), but the model is guided toward valid choices through output constraints.
For simpler implementations, keep your tool definitions static and handle invalid tool calls gracefully in your orchestration layer.
Deterministic serialization matters too. Python dicts don’t guarantee order. If you’re serializing tool definitions or context as JSON, use sort_keys=True or a library that guarantees deterministic output. A different key order = different tokens = cache miss.
to context management changed how I think about agent architecture. Instead of stuffing tool outputs into the conversation, write them to files.

In their A/B testing, this reduced total agent tokens by 46.9% for runs using MCP tools.
The insight: agents don’t need complete information upfront. They need the ability to access information on demand. Files are the perfect abstraction for this.
We apply this pattern everywhere:
Shell command outputs: Write to files, let agent tail or grep as needed
Search results: Return file paths, not full document contents
API responses: Store raw responses, let agent extract what matters
Intermediate computations: Persist to disk, reference by path
When context windows fill up, Cursor triggers a summarization step but exposes chat history as files. The agent can search through past conversations to recover details lost in the lossy compression. Clever.
A vague tool returns everything. A precise tool returns exactly what the agent needs.
Consider an email search tool:

The two-phase pattern: search returns metadata, separate tool returns full content. The agent decides which items deserve full retrieval.
This is exactly how our conversation history tool works at Fintool. It passes date ranges or search terms and returns up to 100-200 results with only user messages and metadata. The agent then reads specific conversations by passing the conversation ID. Filter parameters like has_attachment, time_range, and sender let the agent narrow results before reading anything.
The same pattern applies everywhere:
Document search: Return titles and snippets, not full documents
Database queries: Return row counts and sample rows, not full result sets
File listings: Return paths and metadata, not contents
API integrations: Return summaries, let agent drill down
Each parameter you add to a tool is a chance to reduce returned tokens by an order of magnitude.
Garbage tokens are still tokens. Clean your data before it enters context.
For emails, this means:

For HTML content, the gains are even larger. A typical webpage might be 100KB of HTML but only 5KB of actual content. CSS selectors that extract semantic regions (article, main, section) and discard navigation, ads, and tracking can reduce token counts by 90%+.
Markdown uses significantly fewer tokens than HTML
, making conversion valuable for any web content entering your pipeline.
For financial data specifically:
Strip SEC filing boilerplate (every 10-K has the same legal disclaimers)
Collapse repeated table headers across pages
Remove watermarks and page numbers from extracted text
Normalize whitespace (multiple spaces, tabs, excessive newlines)
Convert HTML tables to markdown tables
The principle: remove noise at the earliest possible stage, not after tokenization. Every preprocessing step that runs before the LLM call saves money and improves quality.
Not every task needs your most expensive model.
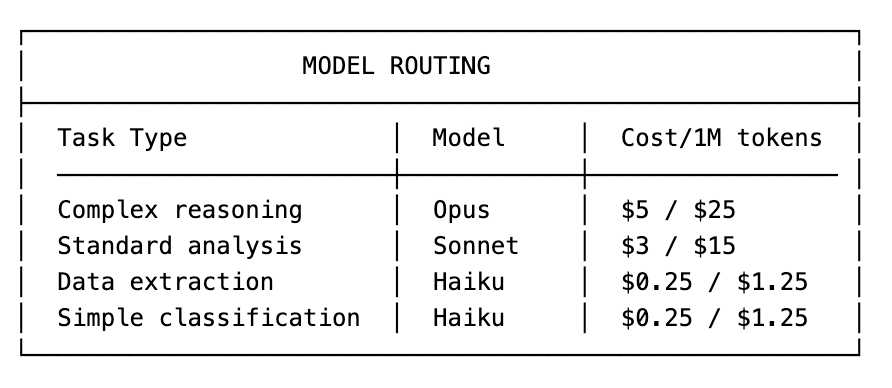
The Claude Code subagent pattern processes 67% fewer tokens overall due to context isolation. Instead of stuffing every intermediate search result into a single global context, workers keep only what’s relevant inside their own window and return distilled outputs.
Tasks perfect for cheaper subagents:
Data extraction: Pull specific fields from documents
Classification: Categorize emails, documents, or intents
Summarization: Compress long documents before main agent sees them
Validation: Check outputs against criteria
Formatting: Convert between data formats
The orchestrator sees condensed results, not raw context. This prevents hitting context limits and reduces the risk of the main agent getting confused by irrelevant details.
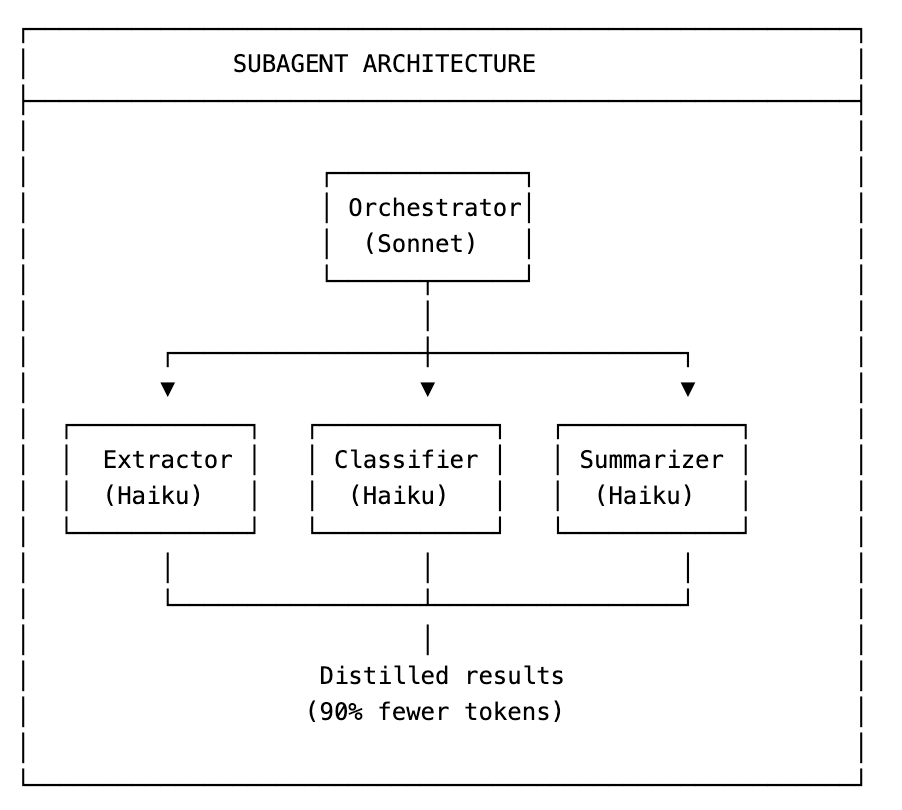
Scope subagent tasks tightly. The more iterations a subagent requires, the more context it accumulates and the more tokens it consumes. Design for single-turn completion when possible.
Every time an agent generates code from scratch, you’re paying for output tokens. Output tokens cost 5x input tokens with Claude. Stop regenerating the same patterns.
Our document generation workflow used to be painfully inefficient:
OLD APPROACH:
User: “Create a DCF model for Apple”
Agent: *generates 2,000 lines of Excel formulas from scratch*
Cost: ~$0.50 in output tokens aloneNEW APPROACH:
User: “Create a DCF model for Apple”
Agent: *loads DCF template, fills in Apple-specific values*
Cost: ~$0.05