Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems.
AI models can now independently identify high-severity vulnerabilities in complex software. As we recently documented, Claude found more than 500 zero-day vulnerabilities (security flaws that are unknown to the software’s maintainers) in well-tested open-source software.
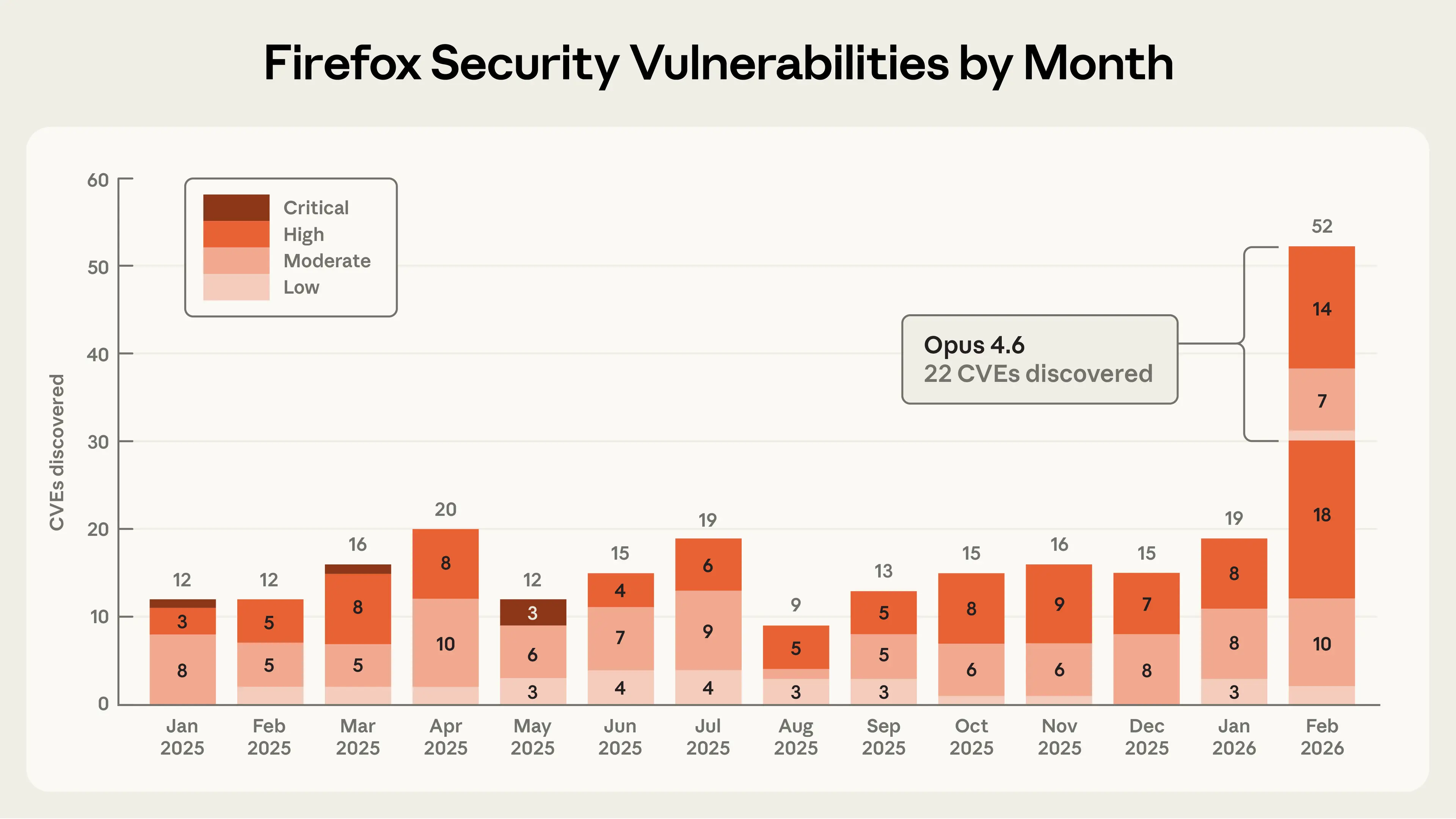
In this post, we share details of a collaboration with researchers at Mozilla in which Claude Opus 4.6 discovered 22 vulnerabilities over the course of two weeks. Of these, Mozilla assigned 14 as high-severity vulnerabilities—almost a fifth of all high-severity Firefox vulnerabilities that were remediated in 2025. In other words: AI is making it possible to detect severe security vulnerabilities at highly accelerated speeds.
As part of this collaboration, Mozilla fielded a large number of reports from us, helped us understand what types of findings warranted submitting a bug report, and shipped fixes to hundreds of millions of users in Firefox 148.0. Their partnership, and the technical lessons we learned, provides a model for how AI-enabled security researchers and maintainers can work together to meet this moment.
From model evaluations to a security partnership
In late 2025, we noticed that Opus 4.5 was close to solving all tasks in CyberGym, a benchmark that tests whether LLMs can reproduce known security vulnerabilities. We wanted to construct a harder and more realistic evaluation that contained a higher concentration of technically complex vulnerabilities, like those present in modern web browsers. So we built a dataset of prior Firefox common vulnerabilities and exposures (CVEs) to see if Claude could reproduce those.
We chose Firefox because it’s both a complex codebase and one of the most well-tested and secure open-source projects in the world. This makes it a harder test of AI’s ability to find novel security vulnerabilities than the open-source software we previously used to test our models. Hundreds of millions of users rely on it daily, and browser vulnerabilities are particularly dangerous because users routinely encounter untrusted content and depend on the browser to keep them safe.
Our first step was to use Claude to find previously identified CVEs in older versions of the Firefox codebase. We were surprised that Opus 4.6 could reproduce a high percentage of these historical CVEs, given that each of them took significant human effort to uncover. But it was still unclear how much we should trust this result because it was possible that at least some of those historical CVEs were already in Claude’s training data.
So we tasked Claude with finding novel vulnerabilities in the current version of Firefox—bugs that by definition can’t have been reported before. We focused first on Firefox’s JavaScript engine but then expanded to other areas of the browser. The JavaScript engine was a convenient first step: it’s an independent slice of Firefox’s codebase that can be analyzed in isolation, and it’s particularly important to secure, given its wide attack surface (it processes untrusted external code when users browse the web).
After just twenty minutes of exploration, Claude Opus 4.6 reported that it had identified a Use After Free (a type of memory vulnerability that could allow attackers to overwrite data with arbitrary malicious content) in the JavaScript engine. One of our researchers validated this bug in an independent virtual machine with the latest Firefox release, then forwarded it to two other Anthropic researchers, who also validated the bug. We then filed a bug report in Bugzilla, Mozilla’s issue tracker, along with a description of the vulnerability and a proposed patch (written by Claude and validated by the reporting team) to help triage the root cause.
In the time it took us to validate and submit this first vulnerability to Firefox, Claude had already discovered fifty more unique crashing inputs. While we were triaging these crashes, a researcher from Mozilla reached out to us. After a technical discussion about our respective processes and sharing a few more vulnerabilities we had manually validated, they encouraged us to submit all of our findings in bulk without validating each one, even if we weren’t confident that all of the crashing test cases had security implications. By the end of this effort, we had scanned nearly 6,000 C++ files and submitted a total of 112 unique reports, including the high- and moderate-severity vulnerabilities mentioned above. Most issues have been fixed in Firefox 148, with the remainder to be fixed in upcoming releases.
When doing this kind of bug hunting in external software, we’re always conscious of the fact that we may have missed something critical about the codebase that would make the discovery a false positive. We try to do the due diligence of validating the bugs ourselves, but there’s always room for error. We are extremely appreciative of Mozilla for being so transparent about their triage process, and for helping us adjust our approach to ensure we only submitted test cases they cared about (even if not all of them ended up being relevant to security). Mozilla researchers have since started experimenting with Claude for security purposes internally.
From identifying vulnerabilities to writing primitive exploits
To measure the upper limits of Claude’s cybersecurity abilities, we also developed a new evaluation to determine whether Claude was able to exploit any of the bugs we discovered. In other words, we wanted to understand whether Claude could also develop the sorts of tools that a hacker would use to take advantage of these bugs to execute malicious code.
To do this, we gave Claude access to the vulnerabilities we’d submitted to Mozilla and asked Claude to create an exploit focusing on each one. To prove it had successfully exploited a vulnerability, we asked Claude to demonstrate a real attack. Specifically, we required it to read and write a local file in a target system, as an attacker would.
We ran this test several hundred times with different starting points, spending approximately $4,000 in API credits. Despite this, Opus 4.6 was only able to actually turn the vulnerability into an exploit in two cases. This tells us two things. One, Claude is much better at finding these bugs than it is at exploiting them. Two, the cost of identifying vulnerabilities is an order of magnitude cheaper than creating an exploit for them. However, the fact that Claude could succeed at automatically developing a crude browser exploit, even if only in a few cases, is concerning.
“Crude” is an important caveat here. The exploits Claude wrote only worked on our testing environment, which intentionally removed some of the security features found in modern browsers. This includes, most importantly, the sandbox, the purpose of which is to reduce the impact of these types of vulnerabilities. Thus, Firefox’s “defense in depth” would have been effective at mitigating these particular exploits. But vulnerabilities that escape the sandbox are not unheard of, and Claude’s attack is one necessary component of an end-to-end exploit. You can read more about how Claude developed one of these Firefox exploits on our Frontier Red Team blog.
What's next for AI-enabled cybersecurity
These early signs of AI-enabled exploit development underscore the importance of accelerating the find-and-fix process for defenders. Towards that end, we want to share a few technical and procedural best practices we’ve found while performing this analysis.
First, when researching “patching agents,” which use LLMs to develop and validate bug fixes, we have developed a few methods we hope will help maintainers use LLMs like Claude to triage and address security reports faster.1
In our experience, Claude works best when it's able to check its own work with another tool. We refer to this class of tool as a “task verifier”: a trusted method of confirming whether an AI agent’s output actually achieves its goal. Task verifiers give the agent real-time feedback as it explores a codebase, allowing it to iterate deeply until it succeeds.
Task verifiers helped us discover the Firefox vulnerabilities described above,2 and in separate research, we’ve found that they’re also useful for fixing bugs. A good patching agent needs to verify at least two things: that the vulnerability has actually been removed, and that the program’s intended functionality has been preserved. In our work, we built tools that automatically tested whether the original bug could still be triggered after a proposed fix, and separately ran test suites to catch regressions (a change that accidentally breaks something else). We expect maintainers will know best how to build these verifiers for their own codebases; the key point is that giving the agent a reliable way to check both of these properties dramatically improves the quality of its output.
We can’t guarantee that all agent-generated patches that pass these tests are good enough to merge immediately. But task verifiers give us increased confidence that the produced patch will fix the specific vulnerability while preserving program functionality—and therefore achieve what’s considered to be the minimum requirement for a plausible patch. Of course, when reviewing AI-authored patches, we recommend that maintainers apply the same scrutiny they’d apply to any other patch created by an external author.
Zooming out to the process of submitting bugs and patches: we know that maintainers are underwater. Therefore, our approach is to give maintainers the information they need to trust and verify reports. The Firefox team highlighted three components of our submissions that were key for trusting our results:
- Accompanying minimal test cases
- Detailed proofs-of-concept
- Candidate patches
We strongly encourage researchers who use LLM-powered vulnerability research tools to include similar evidence of verification and reproducibility when submitting reports based on the output of such tooling.
We’ve also published our Coordinated Vulnerability Disclosure operating principles, where we describe the procedures we will use when working with maintainers. Our processes here follow standard industry norms for the time being, but as models improve we may need to adjust our processes to keep pace with capabilities.
The urgency of the moment
Frontier language models are now world-class vulnerability researchers. On top of the 22 CVEs we identified in Firefox, we’ve used Claude Opus 4.6 to discover vulnerabilities in other important software projects like the Linux kernel. Over the coming weeks and months, we will continue to report on how we’re using our models and working with the open-source community to improve security.
Opus 4.6 is currently far better at identifying and fixing vulnerabilities than at exploiting them. This gives defenders the advantage. And with the recent release of Claude Code Security in limited research preview, we’re bringing vulnerability-discovery (and patching) capabilities directly to customers and open-source maintainers.
But looking at the rate of progress, it is unlikely that the gap between frontier models’ vulnerability discovery and exploitation abilities will last very long. If and when future language models break through this exploitation barrier, we will need to consider additional safeguards or other actions to prevent our models from being misused by malicious actors.
We urge developers to take advantage of this window to redouble their efforts to make their software more secure. For our part, we plan to significantly expand our cybersecurity efforts, including by working with developers to search for vulnerabilities (following the CVD process outlined above), developing tools to help maintainers triage bug reports, and directly proposing patches.
If you’re interested in supporting our security efforts—writing new scaffolds to identify vulnerabilities in open-source software; triaging, patching, and reporting vulnerabilities; and developing a robust CVD process for the AI era—apply to work at Anthropic here.
Read the original article
Comments
I recommend that anyone who is responsible for maintaining the security of an open-source software project that they maintain ask Claude Code to do a security audit of it. I imagine that might not work that well for Firefox without a lot of care, because it's a huge project.
But for most other projects, it probably only costs $3 worth of tokens. So you should assume the bad guys have already done it to your project looking for things they can exploit, and it no longer feels responsible to not have done such an audit yourself.
Something that I found useful when doing such audits for Zulip's key codebases is the ask the model to carefully self-review each finding; that removed the majority of the false positives. Most of the rest we addressed via adding comments that would help developers (or a model) casually reading the code understand what the intended security model is for that code path... And indeed most of those did not show up on a second audit done afterwards.
By staticassertion 2026-03-0713:05 I have a few skills for this that I plug into `cargo-vet`. The idea is straightforward - where possible, I rely on a few trusted reviewers (Google, Mozilla), but for new deps that don't fall into the "reviewed by humans" that I don't want to rewrite, I have a bunch of Claude reviewers go at it before making the dependency available to my project.
I'm curious: has someone done a lengthy write-up of best practices to get good results out of AI security audits? It seems like it can go very well (as it did here) or be totally useless (all the AI slop submitted to HackerOne), and I assume the difference comes down to the quality of your context engineering and testing harnesses.
This post did a little bit of that but I wish it had gone into more detail.
By j-conn 2026-03-0623:53 OpenAI just released “codex security”, worth trying (along with other suggestions) if your org has access https://openai.com/index/codex-security-now-in-research-prev...
The HackerOne slop is because there's a financial incentive (bug bounties) involved, which means people who don't know what they are doing blindly submit anything that an LLM spots for them.
If you're running the security audit yourself you should be in a better position to understand and then confirm the issues that the coding agents highlight. Don't treat something as a security issue until you can confirm that it is indeed a vulnerability. Coding agents can help you put that together but shouldn't be treated as infallible oracles.
That sounds like the same problem (a deluge of slop) with a different interface (eating straight from the trough rather than waiting for someone to put a bow on it and stamp their name to it)?
By stubish 2026-03-076:15 Seems very similar to turning on compiler warnings. A load of scary nothings, and a few bugs. But you fix the bugs and clarify the false positives, and end up with more robust and maintainable code.
I've found it's pretty good. It's really not that much of a burden to dig through 10 reports and find the 2 that are legitimate.
It's different from Hacker One because those reports tend to come in with all sorts of flowery language added (or prompt-added) by people who don't know what they are doing.
If you're running the prompts yourself against your own coding agents you gain much more control over the process. You can knock each report down to just a couple of sentences which is much faster to review.
By Mapsmithy 2026-03-072:44 You also probably have a much better idea of where the unsafe boundaries in your application are. Letting the models know this information up front has given me a dozen or so legitimate vulnerabilities in the application I work on. And the signal to noise ratio is generally pretty good. Certainly orders of magnitude better than the terrible dependabot alerts I have to dismiss every day
By johannes1234321 2026-03-0622:294 reply The question still is: will enough useful stuff be included, to make it worth to dig through the slop? And how to tune the prompt to get better results.
By unethical_ban 2026-03-0623:53 I assume it's just like asking for help refactoring, just targeting specific kinds of errors.
I ran a small python script that I made some years ago through an LLM recently and it pointed out several areas where the code would likely throw an error if certain inputs were received. Not security, but flaws nonetheless.
By bluGill 2026-03-0622:46 That depends on how the tool is used. People who ask for a security vulnerability get slop. People who asked for deeper analysis often get something useful - but it isn't always a vulnerability.
[claimed common problem exists, try X to find it] -> [Q about how to best do that] -> "the best way to do it is to do it yourself"
Surely people have found patterns that work reasonably well, and it's not "everyone is completely on their own"? I get that the scene is changing fast, but that's ridiculous.
By simonw 2026-03-070:05 There's so much superstition and outdated information out there that "try it yourself" really is good advice.
You can do that in conjunction with trying things other people report, but you'll learn more quickly from your own experiments. It's not like prompting a coding agent is expensive or time consuming, for the most part.
/security-review really is pretty good.
But your codebase is unique. Slop in one codebase is very dangerous in another.
By LamaOfRuin 2026-03-0714:26 For those not aware, this is a specific feature available in Claude Code.
https://support.claude.com/en/articles/11932705-automated-se...
By Groxx 2026-03-0721:35 that's kinda what I was looking for tbh. I didn't know that was an option, and nothing in the thread (or article) seemed to imply it was.
I was mostly working off "well I could ask claude to look at my code for security problems, i.e. 'plz check for security holes kthx', but is that really going to be the best option?". if "yes", then it would kinda imply that all the customization and prompt-fiddling people do is useless, which seems rather unlikely. a premade tool is a reasonable starting point.
By ronsor 2026-03-0622:54 You're either digging through slop or digging through your whole codebase anyway.
By lmeyerov 2026-03-0620:55 We split our work:
* Specification extraction. We have security.md and policy.md, often per module. Threat model, mechanisms, etc. This is collaborative and gets checked in for ourselves and the AI. Policy is often tricky & malleable product/business/ux decision stuff, while security is technical layers more independent of that or broader threat model.
* Bug mining. It is driven by the above. It is iterative, where we keep running it to surface findings, adverserially analyze them, and prioritize them. We keep repeating until diminishing returns wrt priority levels. Likely leads to policy & security spec refinements. We use this pattern not just for security , but general bugs and other iterative quality & performance improvement flows - it's just a simple skill file with tweaks like parallel subagents to make it fast and reliable.
This lets the AI drive itself more easily and in ways you explicitly care about vs noise
By ares623 2026-03-0620:29 No mention of the quality of the engineers reviewing the result?
By SV_BubbleTime 2026-03-071:215 reply This is exactly how I would not recommend AI to be used.
“do a thing that would take me a week” can not actually be done in seconds. It will provide results that resemble reality superficially.
If you were to pass some module in and ask for finite checks on that, maybe.
Despite the claims of agents… treat it more like an intern and you won’t be disappointed.
Would you ask an intern to “do a security audit” of an entire massive program?
By padolsey 2026-03-071:51 My approach is that, "you may as well" hammer Claude and get it to brute-force-investigate your codebase; worst case, you learn nothing and get a bunch of false-positive nonsense. Best case, you get new visibility into issues. Of _course_ you should be doing your own in-depth audits, but the plain fact is that people do not have time, or do not care sufficiently. But you can set up a battery of agents to do this work for you. So.. why not?
IMO the key behavior is that LLMs are really good at fuzz testing, because they are probabilistic monkeys on typewriters that are much more code-aware than a conventional fuzz tester. They cannot produce a comprehensive security audit or fix security issues in a reliable way without human oversight, but they sure can come up with dumb inputs that break the code.
The results of such AI fuzz testing should be treated as just a science experiment and not a replacement for the entire job of a security researcher.
Like conventional fuzz testing, you get the best results if you have a harness to guide it towards interesting behaviors, a good scientific filtering process to confirm something is really going wrong, a way to reduce it to a minimal test case suitable for inclusion in a test suite, and plenty of human followup to narrow in on what's going on and figure out what correctness even means in the particular domain the software is made for.
By orbital-decay 2026-03-075:25 >the key behavior is that LLMs are really good at fuzz testing, because they are probabilistic monkeys on typewriters
That's exactly what they're not. Models post-trained with current methods/datasets have pretty poor diversity of outputs, and they're not that useful for fuzz testing unless you introduce input diversity (randomize the prompt), which is harder than it sounds because it has to be semantical. Pre-trained models have good output diversity, but they perform much worse. Poor diversity can be fixed in theory but I don't see any model devs caring much.
What is there to loose in trying?
Basically, don't trust AI if it says "you program is secure", but if it returns results how you could break it, why not take a look?
This is the way I would encourage AI to be used, I prefer such approaches (e.g. general code reviews) than writing software by it.
By SV_BubbleTime 2026-03-092:24 Because if you want the work done correctly, you WILL put the time you thought you were saving in. Either up front, or in review of its work, or later when you find out it didn’t do it correctly.
It depends whether anyone was ever actually going to spend that week doing it the "hard" way. Having Claude do it in a few minutes beats doing nothing.
Put another way: I absolutely would have an intern work on a security audit. I would not have an intern replace a professional audit though.
It's otherwise a pretty low stakes use. I'd expect false positives to be pretty obvious to someone maintaining the code.
By SV_BubbleTime 2026-03-073:26 My point is that it’s one thing to say I want my intern to start doing a security audit.
It’s another thing to say hey intern security audit this entire code base.
LLM’s thrive on context. You need the right context at the right time, it doesn’t matter how good your model is if you don’t have that.
By j16sdiz 2026-03-074:42 > Would you ask an intern to “do a security audit” of an entire massive program?
Why not?
You can't relies solely on that, but having an extra pair of eye without prior assumption on the code always is good idea.
It's cool that Mozilla updated https://www.mozilla.org/en-US/security/advisories/mfsa2026-1... because we were all wondering who had found 22 vulnerabilities in a single release (their findings were originally not attributed to anybody.)
By himata4113 2026-03-0623:032 reply Use After Free Use After Free Use After Free Use After Free Use After Free Use After Free Use After Free.
I would be more satisfied if they gave a proper explanation of what these could have lead to rather than being "well maybe 0.001% chance to exploit this". They did vaguely go over how "two" exploits managed to drop a file, but how impactful is that? Dropping a file in abcd with custom contents in some folder relative to the user profile is not that impactful other than corrupting data or poisoning cache, injecting some javascript. Now reading session data from other sites, that I would find interesting.
You should generally assume that in a web browser any memory corruption bug can, when combined with enough other bugs and a lot of clever engineering, be turned into arbitrary code execution on your computer.
By himata4113 2026-03-073:11 The most important bit being the difficulty, AI finding 21 easily exploitable bugs is a lot more interesting than 21 that you need all the planets to align to work.
By hedora 2026-03-070:17 If you can poison cache, you can probably use that a stepping stone to read session data from other sites.
By dmix 2026-03-0622:46 Looks like a lot of the usual suspects
The fact there is no mention of what were the bugs is a little odd. It'd really be nice to see if this is a "weird never happening edge case" or actual issues. LLMs have uncanny abilities to identify failure patterns that it has seen before, but they are not necessarily meaningful.
By iosifache 2026-03-0612:30 You can find them linked [1] in the OG article from Anthropic [2].
[1] https://www.mozilla.org/en-US/security/advisories/mfsa2026-1...
By larodi 2026-03-0613:49 The fact that some of the Claude-discovered bugs were quite severe is also a little more than something to brush off as "yeah, LLM, whatever". The lists reads quite meaningful to me, but I'm not a security expert anyways.
By jandem 2026-03-0612:35 Here's a write-up for one of the bugs they found: https://red.anthropic.com/2026/exploit/
By deafpolygon 2026-03-0612:291 reply I’m guessing it might be some of these: https://www.mozilla.org/en-US/security/advisories/mfsa2026-1...
By robin_reala 2026-03-0613:332 reply I correctly misread that as “et AI”.
By moffkalast 2026-03-0618:43 we can put that one next to the Weird AI Yankovic music generator.
By deafpolygon 2026-03-0613:371 reply “et AI, Brutus!"
By deafpolygon 2026-03-0614:271 reply An LLM by any other name would hallucinate the same
Anyone still reading down here will appreciate this https://bsky.app/profile/simeonthefool.bsky.social/post/3kbk...
By deafpolygon 2026-03-0621:191 reply I upvoted, so maybe that restored the balance.
By tclancy 2026-03-072:35 Out, out, vile upvote.
By nervysnail 2026-03-0623:38 He computes too much.
And now that you know that it isn't, do you feel differently about the logic you used to write this comment?
By john_strinlai 2026-03-0616:102 reply i am curious, what are you hoping to get out of this comment? will you feel better if they say yes? what is your plan if they say no?
By tptacek 2026-03-0616:13 I genuinely want to understand how they arrived at the claim that this was a fluffy marketing piece. Like, if you said on a different thread, "the Linux kernel is probably mostly written in Pascal", I would really want to understand how it was you got to that idea.
By JumpCrisscross 2026-03-0616:581 reply > what are you hoping to get out of this comment?
Rando here. It gives a signal on the account’s other comments, as well as the value of the original comment (as a hypothesis, albeit a wrong one, versus blind raging).
By john_strinlai 2026-03-0617:552 reply >"It gives a signal on the account's other comments,"
fair enough. i typically use karma as a rough proxy for that, especially when the user has a lot of it (like, in this case, where the poster is #17 on the leaderboard with 100,000+ karma). you dont get that much karma if you are consistently posting bad takes.
>as well as the value of the original comment (as a hypothesis, albeit a wrong one, versus blind raging).
i dont see, in this case anyways, how or why that distinction would matter or change anything (in this case specifically, what would you change or do differently if it was a hypothesis or simple "raging"?), but im probably just thinking about it incorrectly.
I think a lot of people are overreading this and really all that's happened here is that I was out at a show last night and was really foggy when I woke up and asked a question clumsily. It happens!
By john_strinlai 2026-03-0618:541 reply yeah, absolutely, i was not intending to start some big inquisition against you or anything.
just like you were genuinely trying to understand where pjmlp was coming from, i was genuinely trying to understand what you would get out of an answer to your question (or, like, what the next reply could even be other than "ok, cool").
By tptacek 2026-03-0618:58 Oh, yeah, no, you're fine, this is on me.
> you dont get that much karma if you are consistently posting bad takes.
I wonder how true that is. While this site doesn't have incentivize engagement-maximizing behaviour (posting ragebait) like some other sites do, I would imagine that simply posting more is the best way to accrue karma long-term.
By john_strinlai 2026-03-0618:34 >I would imagine that simply posting more is the best way to accrue karma long-term.
i definitely agree, which is why i use it as a rough proxy rather than ground truth, but i have my doubts that you can casually "post more" your way into the top 20 karma users of all time.
By tptacek 2026-03-0618:47 I don't know. I'm really asking. I have you bucketed in my head in the cohort of "HN commenters who write lots of assembly", so the mismatch between your prediction and the outcome is just really interesting to me.
