

Quint was born from the concern of making software more reliable. This has been Informal Systems’ mission from its conception. We want a world where people can trust the software they use.
LLMs have transformed how we write code, but they’ve also created new frustrations. We’ve all been there: staring at a huge AI-generated diff with no clue if it’s actually right. AI fooling us with code that seemed to work but was subtly wrong. Tests that all passed but didn’t actually test anything meaningful. The whole point of LLMs is producing text that looks correct - and that’s exactly what makes validation so hard.
AI is overconfident and needs reality checks.
But here’s the hopeful part: LLMs also enable us to take care of reliability with a much smaller time investment. And no, this is not simply generating specs. It’s not about “putting AI into Quint”. It’s about how Quint fits in the new world of software development, with the same goal it was born with.
Let me tell you how we used Quint to guardrail LLMs and get them to make a significant core change on a complex codebase that we feel confident about.
How Quint fits into this story
The fundamental challenge with LLMs is validation. LLMs excel at code generation, but we humans struggle to validate correctness through code review alone. We typically use a combination of natural language documentation and code, and both are surprisingly hard to validate.
Quint solves this by sitting between English and code as an ideal validation point. It’s more abstract than code, which makes it easier to reason about, yet it’s executable unlike English, which makes it mechanically verifiable. Quint’s tooling - the simulator, model checker, and REPL - lets you build confidence through exploration and property checking.
But what about validating the actual code? Since Quint is executable, we can establish deterministic connections between the specification and the implementation through model-based testing: you run the same scenarios in both the spec and the code, and verify they behave identically. The confidence you build at the spec level transfers to the code level.
The Use Case: A Complex Change in a Complex System
We tested this on Malachite, a production-grade BFT consensus engine that implements Tendermint consensus protocol. This is not a toy example - if it works for this, it will work for simpler changes and simpler systems. Malachite is a complex system with several optimizations on top of Tendermint, and the consensus core alone is made of four different components.
Malachite was acquired by Circle (the company behind USDC) to build Arc, their new blockchain. Much of Malachite’s protocol design was done with Quint from the beginning.
The change: Switch to Fast Tendermint - a variant that requires 5F + 1 nodes to tolerate F Byzantine nodes (instead of the classical 3F + 1), with potential for better performance through one less communication step.
Traditional estimate for this change: a couple of months.
We challenged ourselves to do it with Quint and AI in a week. And we did.
Starting Point
We Already Had a Spec
We started with an existing Tendermint spec in Quint - specifically one using the Choreo framework (our framework for modeling distributed systems). We have many versions of Tendermint specs because it’s our favorite protocol to model.
Could AI write the first spec for you? It can definitely help you, and we are exploring more ways to expand this help. Even if you have to write the first spec by hand (a few days of work for a complex protocol), the ROI for complex systems is compelling: that initial investment pays off for every subsequent change, refactor, or optimization you make.
LLMs as Translators, Not Designers
Let me be clear: we are not delegating protocol design to AI. We’re not asking AI to design state of the art BFT consensus algorithms.
Manu, one of our best protocol designers, did the actual work: research, the English protocol description, draft proofs and paper. We wanted to validate that his protocol was correct. That’s where Quint comes in - but this time, with help from AI.
So we started with two artifacts: A Quint specification for the original Tendermint, and an English description of the new Fast Tendermint.
The Workflow: Four Steps to Confidence
Input: Existing Tendermint spec + Manu’s English protocol description
Process: AI modifies the Quint spec based on the new protocol
Output: First version of Fast Tendermint spec
After each change, we run Quint’s basic validation tools - quint parse to check syntax, and quint typecheck to verify types, references, and function signatures. This tight feedback loop catches basic errors immediately before moving forward, iterating until we have a structurally sound spec.
But structural soundness isn’t the same as behavioral correctness.
Spec Validation
This is where humans should spend most of their time. The time you save by not writing code can now go into deeper validation.
You query the spec interactively: “Can I reach a scenario where X happens?” “Does this property hold?” AI helps you leverage Quint’s tools while you bring your domain expertise. AI can suggest some scenarios, and you drive it to make yourself more confident.
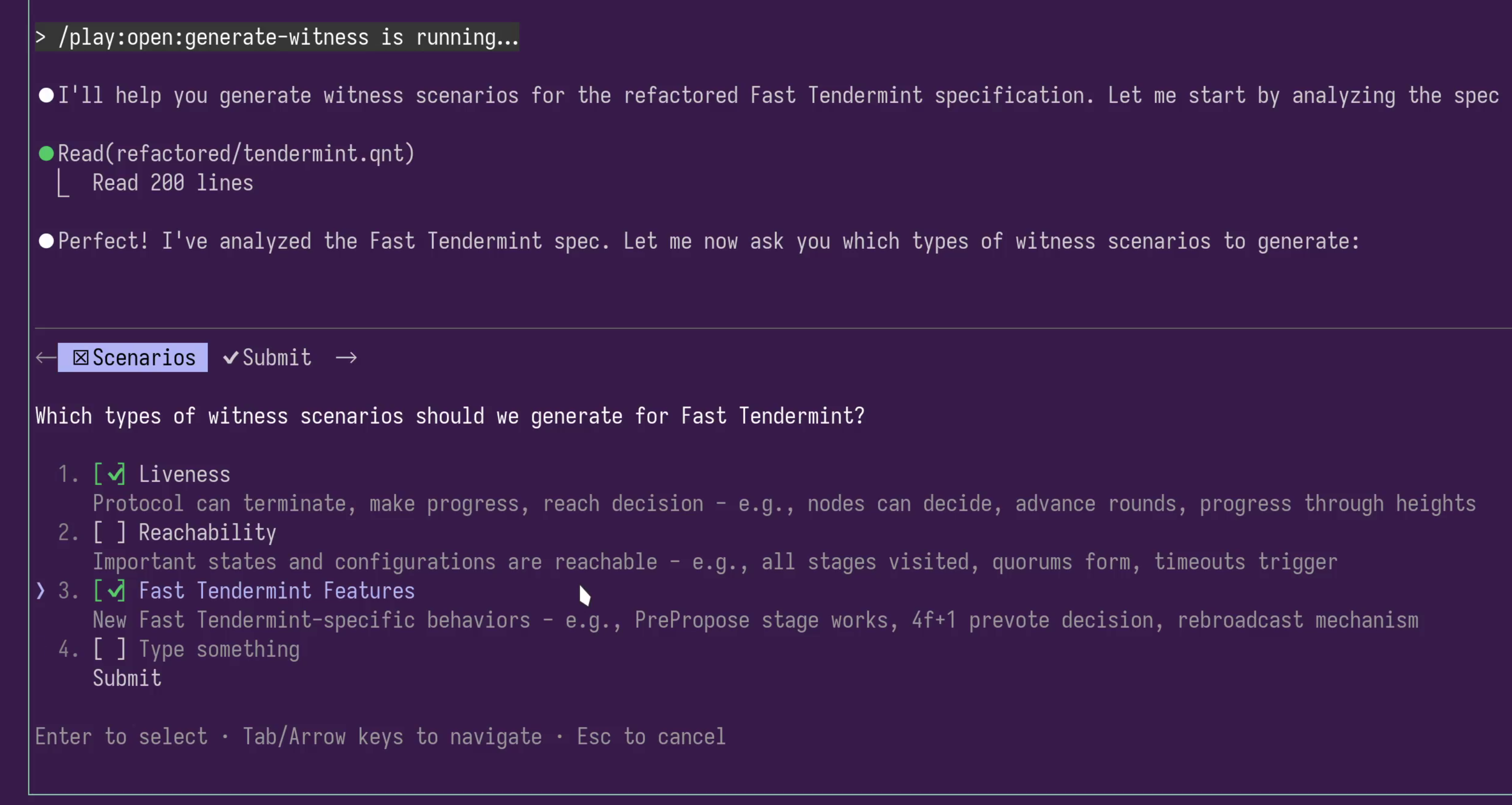
For Fast Tendermint, we validated:
- The re-broadcast mechanism: Can we trigger re-broadcasts? Can we receive and act on them?
- Alternative decision propagation: When does this mechanism trigger instead of the normal flow? We found and documented those scenarios.
- Byzantine tolerance assumptions: We specified a version with too many Byzantine nodes. In this model, disagreement should be possible. If it’s not, we’re making unrealistic assumptions in our model.
The goal: test that all flows are reachable and explore the state space systematically. Once we’re confident about coverage, we check properties. This brings connection back - the opposite of the disconnected feeling you get when AI generates code and you just hope it’s right.
Results: We found two small bugs in Manu’s English spec in one afternoon. They were easy to fix at this stage.
Once validation passes - all flows reachable, properties hold, assumptions verified - we have a spec we are confident about. This becomes our source of truth for code generation.
Code Change
Now we have a validated spec. Time to generate the actual implementation.
Good news: AI is great at code generation when you have a precise spec to translate from. We give the AI the old Quint spec, the new Quint spec, and the diff between them - formal models rather than ambiguous natural language.
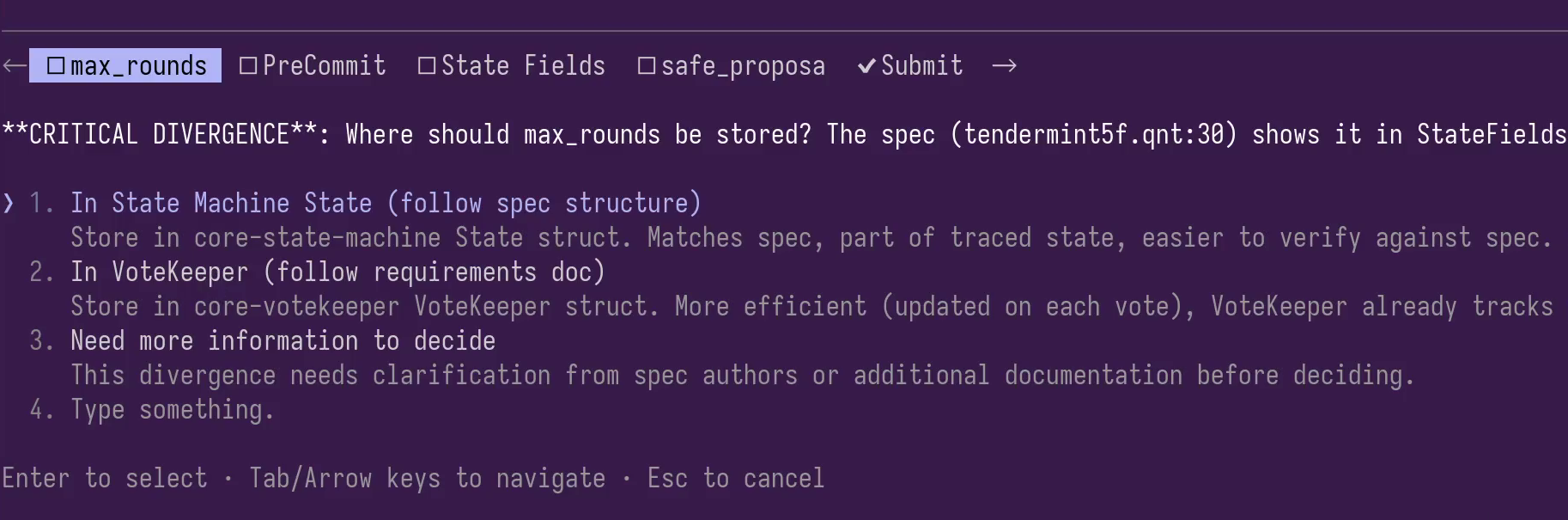
Malachite has architectural complexity that’s not represented in the abstract spec (optimizations, storage decisions, etc.), so we need to guide AI in these decisions. That’s part of our expertise and profession.
Code Validation
We validated the spec, but what we really care about is the code. Model-based testing is the technique that gives us confidence that our code follows those validated behaviors from the spec.
AI generates “glue code” that connects the spec to the implementation. This glue code takes scenarios from Step 2 (witnesses - properties that demonstrate state reachability - or quint runs) and replays them in the code: it takes a scenario, calls the matching entry points in the implementation, and asserts that the results match what the spec predicts. This produces a test suite that lives in your CI.
Beyond model-based testing: We’re also working on trace validation - taking traces from real environments where your code runs (testing environments, testnets, production) and validating that those traces are compliant with the spec. This closes the loop: you’re not just checking that code can behave like the spec, but that it actually does in practice.
The Results
The refactor was successful. We modified Malachite’s core consensus mechanism - a change traditionally estimated at months of work - in about 2 days for the spec modifications and validation, plus ~1 week for code generation and testing (including refinement and debugging). There’s much to mature in this process, but we were very happy with the results.
A Key Benefit: Spec as Debugging Compass
One benefit we found: the validated Quint spec prevents you from diving into non-issues during debugging. Here’s a pattern we encountered repeatedly:
- AI (reading test logs): “I know what is wrong - we should be broadcasting X when doing Y!”
- AI (reads Quint spec): “Wait, the spec shows we don’t broadcast X during Y. That’s by design.”
- Result: Move on immediately to investigate other hypotheses.
With an English spec, you’d second-guess: “What if we forgot to document it? What if it’s incomplete?” You waste time investigating false leads. But with a validated Quint spec that you’ve already explored deeply, you know the spec is correct. If broadcasting X during Y was needed, the validation phase would have exposed it. The spec says we don’t do it, so we confidently rule out that hypothesis and move on.
This trust in the spec as a definitive reference saves significant debugging time. It keeps both humans and AI from suspecting the wrong things.
Conclusion
Remember those frustrations? The huge diffs with no clue if they’re right? The disconnected feeling of endless prompts with no structure? The tests that passed but tested nothing?
This workflow addresses them. Interactive spec validation brings connection back - you’re not just hoping the AI got it right, you’re exploring and building confidence. When AI generates code from a validated spec, you have a definitive reference to check against. The spec becomes your debugging compass, preventing you from diving into non-issues. And model-based testing ensures your tests actually validate what matters.
Executable specifications are the ideal validation point in LLM-assisted development. They sit at the sweet spot between English and code: abstract enough for human reasoning, precise enough for mechanical verification. This is what beats AI’s overconfidence - not more AI, but better validation tools.
Here’s what’s remarkable: Quint was built to help humans reason about complex systems. Giving Quint to AI helps guardrail it to work with more complexity, without making things impossible to validate. We use LLMs for what they excel at: translating between Quint specs, documentation, and implementation code. LLMs don’t think, they translate. Quint’s deterministic tools do the reasoning.
Our work is shifting from writing code to validating AI-generated code. Defining what correct means has become extremely important - and that’s exactly what executable specs do.
This workflow - spec modification, interactive exploration, guided code generation, and model-based testing - scales to real-world systems. We proved it on Malachite.
Want to see this in action? We’re doing initial demos for teams interested in applying this approach to their projects. If you’re working on distributed systems such as consensus or interoperability protocols, large scale databases, or other types of complex systems such as trading apps (for example DEX/CEX) or cryptographic protocols (ZKP, privacy preserving apps), or any other complex core logic where reliability matters, schedule a consultation and we’ll show you our demo and happily explore how we can help you.
Thanks for reading. We’re building the future of reliable software, one executable spec at a time.
