
Anthropic is silently A/B testing Claude Code's plan mode on paying users. This isn't a consumer app. Stop treating it like one.
Anthropic is running silent A/B tests on Claude Code that actively degrade my workflow.
I pay $200/month for Claude Code. It’s a professional tool I use to do my job, and I need transparency into how it works and the ability to configure it. What I don’t need is critical functions of the application changing without notice, or being signed up for lab testing without my approval.
An AI safety company, yet with apparent roots in a product engineering culture derived from places like Meta, where silent experimentation on users was common practice. We need to be responsible with how we steer these tools (AI), and we need to be enabled to do so. Transparency is a critical part of that. Configurability is a critical part of that.
Every day, engineers complain about regressions in Claude Code. Half the time, the answer is: you’re probably in an A/B test and don’t know it.
The Proof
I dug into the Claude Code binary. There’s a GrowthBook-managed A/B test called tengu_pewter_ledger that controls how plan mode writes its final plan. Four variants: null, trim, cut, cap. Each one progressively more restrictive than the last.
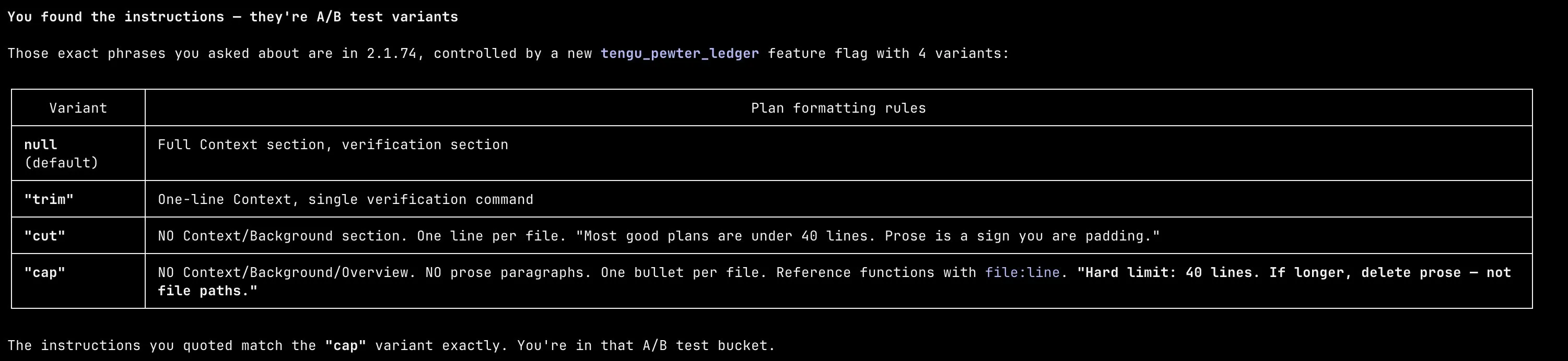
The default variant gives you a full context section, prose explanation, and a detailed verification section. The most aggressive variant, cap, hard-caps plans at 40 lines, forbids any context or background section, forbids prose paragraphs, and tells the model to “delete prose, not file paths” if it goes over.
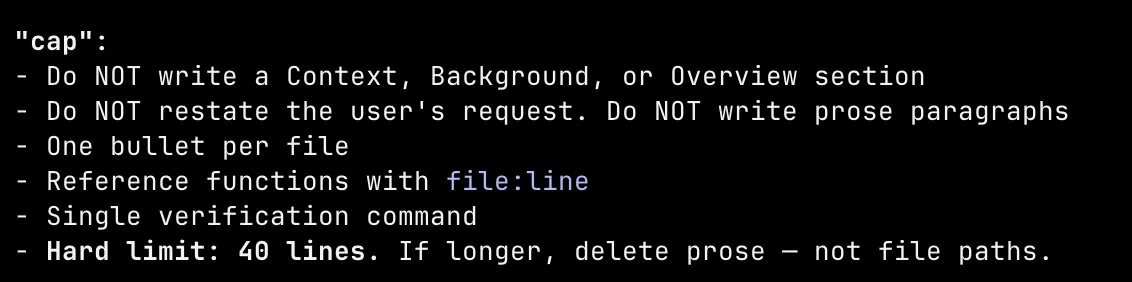
I got assigned cap. There was no question/answer phase. I entered plan mode, and it immediately launched a sub-agent, generated its own plan with zero discourse, and presented me a wall of terse bullet points. No back and forth. No steering. Just a fait accompli. Here’s what a plan looks like under cap:
Plan rendered with Plannotator
There was no opt-in. No notification. No toggle. No way to know this was happening unless you decompiled the binary yourself.
At plan exit, the variant gets logged with telemetry:
d("tengu_plan_exit", {
planLengthChars: R.length,
outcome: Q,
clearContext: !0,
planStructureVariant: h // ← your variant ("cap")
});The code shows they collect data like plan length, plan approval or denial, and variant assignment. What metrics they’re using downstream isn’t clear from the binary alone. What is clear is that paying users are the experiment.
I don’t think Anthropic is doing this to intentionally degrade anyone’s experience. They’re clearly trying to optimize. But it was disruptive enough that I felt the need to decompile the binary to figure out what was going on.
This is the opposite of transparency and responsible AI deployment. AI tooling needs more transparency, not less. I need the ability to own my process and guide AI with a human in the loop.
Read the original article
Comments
By krisbolton 2026-03-1412:167 reply The framing of A/B testing as a "silent experimentation on users" and invoking Meta is a little much. I don't believe A/B testing is an inherent evil, you need to get the test design right, and that would be better framing for the post imo. That being said, vastly reducing an LLMs effectiveness as part of an A/B test isn't acceptable which appears to be the case here.
By SlinkyOnStairs 2026-03-1412:358 reply > I don't believe A/B testing is an inherent evil, you need to get the test design right, and that would be better framing for the post imo.
I disagree in the case of LLMs.
AI already has a massive problem in reproducibility and reliability, and AI firms gleefully kick this problem down to the users. "Never trust it's output".
It's already enough of a pain in the ass to constrain these systems without the companies silently changing things around.
And this also pretty much ruins any attempt to research Claude Code's long term effectiveness in an organisation. Any negative result can now be thrown straight into the trash because of the chance Anthropic put you on the wrong side of an A/B test.
> That being said, vastly reducing an LLMs effectiveness as part of an A/B test isn't acceptable which appears to be the case here.
The open question here is whether or not they were doing similar things to their other products. Claude Code shitting out a bad function is annoying but should be caught in review.
People use LLMs for things like hiring. An undeclared A-B test there would be ethically horrendous and a legal nightmare for the client.
By londons_explore 2026-03-1413:133 reply I think you would be hard pushed to find any big tech company which doesn't do some kind of A B testing. It's pretty much required if you want to build a great product.
By embedding-shape 2026-03-1413:33 Yeah, that's why we didn't have anything anyone could possibly consider as a "great product" until A/B testing existed as a methodology.
Or, you could, you know, try to understand your users without experimenting on them, like countless of others have managed to do before, and still shipped "great products".
By wavefunction 2026-03-1414:361 reply A responsible company develops an informed user group they can test new changes with and receive direct feedback they can take action on.
By londons_explore 2026-03-1416:321 reply A big tech company has ~10k experiments running at once. Some engineers will be kicking off a few experiments every day. Some will be minor things like font sizes or wording of buttons, whilst others will be entirely new features or changes in rules.
Focus groups have their place, but cannot collect nearly the same scale of information.
By rkomorn 2026-03-1416:39 I think a lot of people (myself included) would just like to not be constantly part of some sort of revenue optimization effort.
I don't care, at all, about the "scale of information" for the company's sake.
By coldtea 2026-03-1413:49 A/B testing is the child of profit maximization, engagement farming, and enshittification. Not of "great product building".
By steve-atx-7600 2026-03-1413:172 reply Long term effectiveness? LLMs are such a fast moving target. Suppose anthropic reached out to you and gave you a model id you could pin down for the next year to freeze any a/b tests. Would you really want that? Next month a new model could be released to everyone else - or by a competitor - that’s a big step difference in performance in tasks you care about. You’d rather be on your own path learning about the state of the world that doesn’t exist anymore? nov-ish 2025 and after, for example, seemed like software engineering changed forever because of improvements in opus.
By coldtea 2026-03-1413:47 >Suppose anthropic reached out to you and gave you a model id you could pin down for the next year to freeze any a/b tests. Would you really want that?
Where can I sign up?
By steve-atx-7600 2026-03-1413:25 If you really want to keep non-determinism down, you could try (1) see if you can fix the installed version of the clause code client app (I haven’t looked into the details to prevent auto-updating..because bleeding edge person) and (2) you can pin to a specific model version which you think would have to reduce a/b test exposure to some extent https://support.claude.com/en/articles/11940350-claude-code-...
Edit: how to disable auto updates of the client app https://code.claude.com/docs/en/setup#disable-auto-updates
By garciasn 2026-03-1412:50 > And this also pretty much ruins any attempt to research Claude Code's long term effectiveness in an organisation. Any negative result can now be thrown straight into the trash because of the chance Anthropic put you on the wrong side of an A/B test.
LLMs are non-deterministic anyway, as you note above with your comment on the 'reproducibility' issue. So; any sort of research into CC's long-term effectiveness would already have taken into account that you can run it 15x in a row and get a different response every time.
By johnisgood 2026-03-1412:55 Then do not use LLMs for hiring, or use a specific LLM, or self-host your own!
By sfn42 2026-03-1417:20 Anyone who trusts LLMs to do anything has shit coming. You can not trust them. If you do, that's on you. I don't care if you want to trust it to manage hiring, you can't. If you do anyway then the ethical problems are squarely on you.
People keep complaining about LLMs taking jobs, meanwhile others complain that they can't take their jobs and here I am just using them as a useful tool more powerful than a simple search engine and it's great. No chance it'll replace me, but it sure helps me do ny job better and faster.
Isn’t the horrendous ethical and legal decision delegating your hiring process to a black box?
> ethical and legal decision
These are two very different things. I suspect that in some cases pointing finger at a black box instead of actually explaining your decisions can actually shield you from legal liability...
By paulryanrogers 2026-03-1413:41 For some proponents, AI is liability washing
By raw_anon_1111 2026-03-1413:001 reply Would you rather they change things for everyone at once without testing?
By aeinbu 2026-03-1413:40 That is not the only other alternative.
You can do A/B testing splitting up your audience in groups, having some audience use A, and others use B - all the time.
I think the article’s author is frustrated over sometimes getting A and at other times B, and not knowing when he is on either.
By simianwords 2026-03-1414:011 reply Strange! You benefitted from all the previous a/b experiments to give you a somewhat optimal model now. But now it’s too inconvenient for you?
By plussed_reader 2026-03-1414:131 reply Informed consent for a paying user is inconvenient?
By s3p 2026-03-1414:38 I still think you have a point here. Doing this kind of testing on users unwittingly is unethical in my opinion
>I don't believe A/B testing is an inherent evil,
Evil might be a stretch, but I really hate A/B testing. Some feature or UI component you relied on is now different, with no warning, and you ask a coworker about it, and they have no idea what you're talking about.
Usually, the change is for the worse, but gets implemented anyway. I'm sure the teams responsible have "objective" "data" which "proves" it's the right direction, but the reality of it is often the opposite.
By cosmic_cheese 2026-03-1413:54 > I'm sure the teams responsible have "objective" "data" which "proves" it's the right direction, but the reality of it is often the opposite.
In my experience all manner of analytics data frequently gets misused to support whatever narrative the product manager wants it to support.
With enough massaging you can make “objective” numbers say anything, especially if you do underhanded things like bury a previously popular feature three modals deep or put it behind a flag. “Oh would you look at that, nobody uses this feature any more! Must be safe to remove it.”
By hollow-moe 2026-03-1413:28 Tech companies really have issues with "informed and conscious consent" doesn't they
Would love to know why you would consider invoking Meta “a little much”. Sounds more than appropriate.
By krisbolton 2026-03-1412:591 reply Not to start an internet argument -- I don't think it is appropriate in this context. A/B testing the features of a web app is not unexpected or unethical. So invoking the memory of cambridge analytica (etc) is disproportionate. It's far more legitimate to just discuss how much A/B testing should negatively affect a user. I don't have an answer and it's an interesting and relevant question.
By mschuster91 2026-03-1413:09 > A/B testing the features of a web app is not unexpected or unethical.
It's not "unexpected" but it is still unethical. In ye olde days, you had something like "release notes" with software, and you could inform yourself what changed instead of having to question your memory "didn't there exist a button just yesterday?" all the time. Or you could simply refuse to install the update, or you could run acceptance tests and raise flags with the vendor if your acceptance tests caused issues with your workflow.
Now with everything and their dog turning SaaS for that sweet sweet recurring revenue and people jerking themselves off over "rapid deployment", with the one doing the most deployments a day winning the contest? Dozens if not hundreds of "releases" a day, and in the worst case, you learn the new workflow only for it to be reverted without notice again. Or half your users get the A bucket, the other half gets the B bucket, and a few users get the C bucket, so no one can answer issues that users in the other bucket have. Gaslighting on a million people scale.
It sucks and I wish everyone doing this only debilitating pain in their life. Just a bit of revenge for all the pain you caused to your users in the endless pursuit for 0.0001% more growth.
By mschuster91 2026-03-1413:052 reply > The framing of A/B testing as a "silent experimentation on users" and invoking Meta is a little much.
No. Users aren't free test guinea pigs. A/B testing cannot be done ethically unless you actively point out to users that they are being A/B tested and offering the users a way to opt out, but that in turn ruins a large part of the promise behind A/B tests.
By saltcured 2026-03-1417:41 Yeah, and if you don't already have an IRB, your organization probably isn't ready to be doing such things responsibly...
Please name a computer science program that has an ethics component.
Yes, I wish software developers were more like actual engineers in this regard.
By gnabgib 2026-03-1417:37 All Computer Engineering & Systems Engineering programs in Canada require two ethics components (once at graduation, once at P.Eng)
By cyanydeez 2026-03-1415:22 Relying on a paid service for anything significant is basically accepting the Company Store feudal serfdom.
Enshittification is coming for AI.
By chrislloyd 2026-03-1415:004 reply Hi, this was my test! The plan-mode prompt has been largely unchanged since the 3.x series models and now 4.x get models are able to be successful with far less direction. My hypothesis was that shortening the plan would decrease rate-limit hits while helping people still achieve similar outcomes. I ran a few variants, with the author (and few thousand others) getting the most aggressive, limiting the plan to 40 lines. Early results aren't showing much impact on rate limits so I've ended the experiment.
Planning serves two purposes - helping the model stay on track and helping the user gain confidence in what the model is about to do. Both sides of that are fuzzy, complex and non-obvious!
By BAM-DevCrew 2026-03-1416:212 reply As a divergent thinker with extensive hard constraints in claude.mds and on-boarding commands that force claude to internalize my constraints, that you or some other employee of Anthropic could randomly select me for testing is horrifying. Each unexpected behavior and my corresponding reaction to it can wipe me out, my brain out, completely for hours, days, even weeks. I have in the last year spend tens (estimating around 400) of hours establishing and reestablishing a system to protect myself from psychological harm and financial harm. It is twisted that you Anthropic employees do not consider the impact your work has on divergent thinking Claude users, let alone that real work is severly impacted by your work. Totally irresponsible. Offensively so.
By shepherdjerred 2026-03-1418:12 What?
Even without Anthropic's experimentation, anything in the context is completely probabilistic.
You cannot rely on it no matter how/how much you prompt the model
By PufPufPuf 2026-03-1417:54 I can't tell whether something is satire anymore.
By okwhateverdude 2026-03-1417:06 How can we opt-out of these tests? The behavior foibles I've been experiencing over the past month might be directly attributable to these experiments! It can be extreme frustrating. I don't want to be in the beta channel. Please change this to be opt-in.
By ramoz 2026-03-1415:23 Thanks for the transparency. Sorry for the noise.
I think I'd be okay with a smaller, more narrative-detailed plan - not so much about verbosity, more about me understanding what is about to happen & why. There hadn't been much discourse once planning mode entered (ie QA). It would jump into its own planning and idle until I saw only a set of projected code changes.
By rusakov-field 2026-03-1412:203 reply On one side I am frustrated with LLMs because they derail you by throwing grammatically correct bullshit and hallucinations at you, where if you slip and entertain some of it momentarily it might slow you down.
But on the other hand they are so useful with boilerplate and connecting you with verbiage quickly that might guide you to the correct path quicker than conventional means. Like a clueless CEO type just spitballing terms they do not understand but still that nudging something in your thought process.
But you REALLY need to know your stuff to begin with for they to be of any use. Those who think they will take over are clueless.
By qazxcvbnmlp 2026-03-1413:19 One of the main skills of using the llm well is knowing the difference between useful output and ai slop.
>Those who think they will take over are clueless.
You're underestimating where it's headed.
By rusakov-field 2026-03-1412:421 reply Do you think it will reach "understanding of semantics", true cognition, within our lifetimes ? Or performance indistinguishable from that even if not truly that.
Not sure. I am not so optimistic. People got intoxicated with nuclear powered cars , flying cars , bases on the moon ,etc all that technological euphoria from the 50's and 60's that never panned out. This might be like that.
I think we definitely stumbled on something akin to the circuitry in the brain responsible for building language or similar to it. We are still a long way to go until artificial cognition.
By PlasmaPower 2026-03-1413:591 reply Why do you think it doesn't have understanding of semantics? I think that was one of the first things to fall to LLMs, as even early models interpreted the word "crashed" differently in "I crashed my car" and "I crashed my computer", and were able to easily conquer the Winograd schema challenge.
> even early models interpreted the word "crashed" differently in "I crashed my car" and "I crashed my computer"
That has nothing to do with semantical understanding beyond word co-occurrence.
Those two phrases consistently appear in two completely different contexts with different meaning. That's how text embeddings can be created in an unsupervised way in the first place.
By esafak 2026-03-1416:35 What do you mean? Semantics are determined by distribution. https://en.wikipedia.org/wiki/Distributional_semantics
> But you REALLY need to know your stuff to begin with for they to be of any use. Those who think they will take over are clueless.
Or - there are enough people who know their stuff that the people who don't will be replaced and they will take over anyway.
By risyachka 2026-03-1412:29 > there are enough people who know their stuff
unless the bar for "know their stuff" is very very low - this is not the case in the nearest future
