
"Destroying silos" is a clumsy solution to team isolation
DevOps should not be about destroying silos; it should be about transforming them into a self-service bar.
In Kelsey’s words: “Silos are fine, as long as there is an API between them”
Merging various team responsibilities and domains by destroying silos can overwhelm them with cognitive load.
The pinnacle of inter-team interaction is providing an intuitive self-service (API, Library, CLI, UI etc)
If you google silos DevOps, the top page is filled with many articles telling you that you must destroy silos. In fact, there is only one article that says otherwise on the top page! So, if the consensus is so overwhelming that destroying silos is a good thing, Why am I writing this piece? First, let’s take a look at what a silo is
We use the word silo to refer to teams that are too isolated. These departments have no visibility of what’s going on with other teams; communication is minimal or non-existent, and naturally, they operate in a way that feels detached from the organization's goals or the needs of the teams that they should be aiming to serve.
Destroying silos is a bad angle because you often end up merging various domains and responsibilities in a single team and creating significant cognitive load. Using teams as discrete and small units of delivery is preferable; it is the way that teams are separated and how they communicate that needs to be tackled.
The problem with the DevOps movement is that it ended up taking “shifting left” to the extreme. In this sense, development teams weren’t so much empowered to deliver software faster; rather, they were over-encumbered with infrastructure tasks that were outside of their expertise.

This way of destroying silos is summarized in one of the top articles in my Google search:
“The first function of DevOps implementation is to get operations and development groups working together as two areas of specialization that form a complete team”
This “merging of two teams” sounds like a bad idea because the larger a team is, the more sluggish it becomes as trust breaks down and domains and responsibilities multiply. Teams should be small, with a single domain of responsibility for maximum agility. Team structure should also reflect the software architecture to maximize the effects of Conway's law.
Another suggestion to destroy silos found online is to create cross-functional teams. This is certainly better and desirable, but there is a small caveat. If your company is small to medium size with only a few teams, you may get away with using PaaS and SaaS tools that reduce the infrastructure complexity and give ease of use for operational tasks, but this becomes difficult to achieve as organizations get very large and have complex requirements. In this case, you will need to have a dedicated, product-driven platform teams that create an internal developer platform for your teams to be able to self-serve their infrastructure teams in standard, secure and compliant ways.
Kelsey Hightower said something that echoed my feelings on this interview:
“Silos are fine as long as there is an API between them”
That is the best possible summary you can give to this entire post. Indeed, the best way to have inter-team communication in large organizations is not talking to each other all the time; it’s creating work that can speak for itself.
This usually takes the form of an API that’s intuitive, easy to use, and treating other teams as your valued users and customers. An API abstracts away your domain for other teams to focus on their expertise rather than being overloaded with infrastructure, compliance and other intricacies that slow down software delivery.
So in that sense, DevOps should NOT be about destroying silos, but about turning teams into self-service bars where they serve their domain expertise to other teams with an API, library, or other form of work that can be easily and intuitively consumed.
The communication between teams is done via elegant user experience and by treating your teams as customers. As opposed to inter-team communication by meetings, Slack, or even relying too heavily on documentation.
Two teams can collaborate as one to achieve a common goal or to understand each other’s needs better, but usually this is temporary until the teams are able to deliver their domain expertise as a service to speed up delivery.
It is desirable for a developer team to be able to deploy and operate their own software, and it is also preferable for them to be able to create their own infrastructure; what’s not very productive is to task developers with onerous infrastructure chores to get there.
In that sense, giving an AWS account with admin permissions is just not enough; AWS is very complex to use, and even if your team has one or two experts that can do it, it takes a lot of time and effort to implement, and how do you ensure that it remains consistent and compliant with the rest of the organization?
This is why it is desirable to have a segmentation of domains where a platform team is able to provide an API or tool with self-service capabilities for developer teams. In small companies, this may take the shape of using a PaaS or a smaller, simpler cloud provider; in big companies, it will take the shape of product-driven platform teams implementing an internal developer platform.
Communication is not about every team talking all the time, which just slows things down; it’s about creating channels of communication via self-service tooling that speaks for itself, or as Manual Pais and Matthew Skelton put it in their phenomenal Team Topologies book:
If, logically, two teams shouldn’t need to communicate based on the software architecture design, then something must be wrong if the teams are communicating. Is the API not good enough? Is the platform not suitable? Is a component missing? If we can achieve low-bandwidth communication—or even zero-bandwidth communication—between teams and still build and release software in a safe, effective, rapid way, then we should.
And also:
“Flow is difficult to achieve when each team depends on a complicated web of interactions with many other teams”
When a team uses another team’s API, there is a communication happening there, but this is done via design and user experience, not by talking. In this scenario, the self-service interaction is much faster and more conducive to flow state than many teams talking to each other all the time to get the job done.
Close collaboration (more talking, more meetings, more slack and sharing of documents) between two teams can happen at discovery phase or during periods of big change and innovation, but once the needs to a development teams become more predictable, then team collaboration evolves into X-as-service as shown in the graph below from the book Team Topologies:
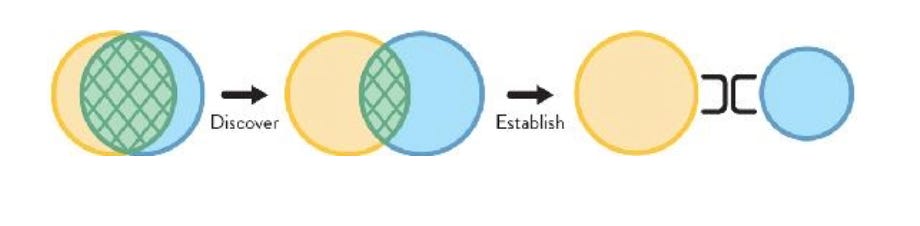
But it is worth noting that this scenario is generally temporary as it significantly slows down the pace of delivery and puts a strain on cognitive load on both teams. This is also different from merging two teams together as both teams remain independent.
Platform engineering has a lot of marketing driven buzz these days and it is becoming the hot topic. While I understand that people get tired of hearing these things, there is one thing I like about it, the focus is on turning the silo into a sushi bar, not destroying the silo:

The problem with platform engineering and designing solutions in this way for teams to work together is that it is harder than just throwing a script or writing a how to document for other teams to use. And to be fair, the amount of tools available to make the task easier are scarce. Recently Microsoft has released an open source tool called Radius that promises to make it easy to deliver self service infrastructure and cloud native apps for developers, and there are multiple(CNOE, platform whitepaper) open source blueprints on how to make internal developer platforms, but the work involved is still very significant and daunting for most organizations.
Destroying silos should be more about turning them into self-service stream-aligned teams than it is about destroying them. Team segmentation is desirable, it reduces cognitive load, it maximizes focus and enables easier flow state. When creating small teams organized by domain and in a way that mirrors the software architecture, the delivery of software will be faster and more effective. In order to achieve this, teams must understand what great user experience means and treat other teams and colleagues as their customers.
Reading about DevOps and destroying silos from the articles on the top search results in Google is a little underwhelming as most of them are a little fluffy and marketingy. In order to understand team collaboration and team dynamics better, I strongly recommend a careful read of the Team Topologies book, it brilliantly describes all team categories, types of interaction and how you should organize them according to Conway’s law.
Fernando Villalba is a Developer Relations at OpsLevel, he has over a decade of miscellaneous IT experience. He started in IT support ("Have you tried turning it on and off?"), veered to become a SysAdmin ("Don't you dare turn it off") and later segued into DevOps type of roles ("Destroy and replace!"). He has been a consultant for various multi-billion dollar organizations helping them achieve their highest potential with their DevOps processes. Now he is passionate about platform engineering, developer portals and DevEx, which he feels is where the future of software delivery shines brightest.
Read the original article
Comments
By acjohnson55 2024-01-1914:456 reply My overall reaction is that this is a great piece for products/teams that have reached significant scale, once the job to be done is too big and complex for one team to own, end-to-end, or there are truly reusable concerns that can be separated from the core product (e.g. auth, observability).
Because interfacing via API is expensive. Writing APIs for others to use productively isn't easy and change management also adds a lot of overhead. And if we're talking about network APIs, there's a ton of distributed systems complexity to account for.
> The problem with the DevOps movement is that it ended up taking “shifting left” to the extreme. In this sense, development teams weren’t so much empowered to deliver software faster; rather, they were over-encumbered with infrastructure tasks that were outside of their expertise.
This. In truth, I think this is a major misinterpretation of DevOps, which is meant to empower devs without loading them down with incidental complexity. But I experienced exactly this misinterpretation at the first place I worked that had embraced DevOps culture.
> Because interfacing via API is expensive. Writing APIs for others to use productively isn't easy and change management also adds a lot of overhead.
I agree in principle, but there is a lot of “unseen coordination/communication” costs that it’s easy taken for granted.
When I was working on telecom doing interfacing with carriers (e.g T-Mobile, Verizon, etc.) on thing that I noticed was how simple was to work with those folks: Ok, this is the standard XML, those are the endpoints, that’s the list of error codes, the rate limit is X requests per second, a bunch of files will be on this FTP at 5AM daily basis, and if you face more than 100ms latency from our side just call this number.
Working with “product” companies without silos most of the time it’s design by committee, folks that won’t keep the service running wanting to have a say in our payload wanting us to change our overly reliable RabbitMQ to use their Kafka.
By The_Colonel 2024-01-1917:111 reply This is an interesting example, becase telco has an actual API standards committee (TM Forum). Telcos have decades of experience and extremely well defined (and to a large degree shared / interchangeable) domain model. It's an ideal scenario for APIs.
Meanwhile your product companies each develop different product, there's little standardization. API designers have only vague idea what the API will be used for and how. Fast evolution is important.
By adamzochowski 2024-01-2014:56 TM Forum provides a bloated format. It has everything and a kitchen sink. This means that something simple like customer name can be written in multiple places, and different architects will recommend different location. Two different silos within same company won't be able to talk to each other because although they are using same format, they interpret the usage different.
Additionally, this is XML/XSD, different teams will end up using different version of the standard. They won't be able to interface with each other without additional layers of translations. It is not uncommon for one team to need to load multiple versions of the XSDs because different end points use different versions.
By acjohnson55 2024-01-1915:09 > When I was working on telecom doing interfacing with carriers (e.g T-Mobile, Verizon, etc.) on thing that I noticed was how simple was to work with those folks: Ok, this is the standard XML, those are the endpoints, that’s the list of error codes, the rate limit is X requests per second, a bunch of files will be on this FTP at 5AM daily basis, and if you face more than 100ms latency from our side just call this number.
To me, that probably reflects the maturity of the services the carriers provide. And presumably that there's an explicit customer-producer relationship? These things justify the complexity of maintaining a well curated and operated API.
> Working with “product” companies without silos most of the time it’s design by committee, folks that won’t keep the service running wanting to have a say in our payload wanting us to change our overly reliable RabbitMQ to use their Kafka.
If I understand what you're saying, you've experienced platform people telling you what tech to use, without having real skin in the game for operating your services? If so, that sounds very irritating. To me, a truly silo-less approach would not have that.
To the extent that there are platform teams with a say in architecture, I think they should develop requirements around the external characteristics of the deliverable (performance, cost, observability, contract with other teams, etc) and largely leave the implementation concerns to the people developing and running the service.
> folks that won’t keep the service running wanting to have a say in our payload wanting us to change
This is my single biggest gripe with DevOps. If you’re not going to be fixing it, why on earth do you get a say as to how I build it? It’s nearly _always_ a one-way street, too – when’s the last time Ops successfully ordered Dev to change some specific part of their code (modulo things like, “hey, you really need to add a rate-limiter”)?
By acjohnson55 2024-01-222:33 IMO, this phenomenon is not specific to DevOps. I've seen this happen when there are official architects or architecture committees.
One of the problems about debating DevOps is that there's no single agreed upon meaning. That probably also impedes its success.
To me, the essence is that there are engineers whose job it is to give product and service devs the ability to do their own operations through software that simplifies basic shared concerns. That does not mean mandating solutions.
“Working with “product” companies without silos most of the time it’s design by committee,”
With siloes you may end up with design by ego trip.
By danielovichdk 2024-01-2013:411 reply Egos only exists if the team let them exist. A strong leader will make sure this is not happening.
By jpc0 2024-01-2014:22 A strong leader at the same time can cause it to happen...
By steveBK123 2024-01-1918:10 > Because interfacing via API is expensive. Writing APIs for others to use productively isn't easy and change management also adds a lot of overhead.
An under appreciated point. Something that is affordable for giant monopoly profit driven FAANGs, but harder in smaller orgs.
Even within my team, the "level of difficulty" of writing an API depends on its user base. If I am the primary user, it's easy. There's one really sharp kind on my team, if he is going to use it, then 2x the difficulty. If I need it to handle the median dev on my team, then 2x again. By the time you get to the below median dev, add another 2x. So even within my team, the intended user base can change the difficult from 1x->8x.
What are some of the pain points - input validation that drives useful informative errors, flexibility on inputs like having sensible defaults to reduce the number of inputs users must pass, performance/scaling, and edge cases.
>> In this sense, development teams weren’t so much empowered to deliver software faster; rather, they were over-encumbered with infrastructure tasks that were outside of their expertise.
And agreed on this point. Amusingly I have had HN thread arguments just this week with DevOps advocates telling me that akshully their job isn't to empower devs, but some sort of "tail that wags that dog" interpretation around devops organizational / standardization / cost / etc.
By toss1 2024-01-1915:18 Yes APIs are expensive and require significant overhead.
But clean, maintained interfaces between separate domains are far LESS expensive than multi-domain/team mashups.
Maintaining separate teams AND well- maintained interfaces surfaces and makes explicit the myriad inter-silo interactions.
Instead of a quick backchannel conversation and a quick hack, it is an explicit conversation and an API adjustment.
Yes, it's more expensive up front, but far cheaper and more powerful in the long run.
So for high-speed prototyping, not so suitable- breaj the silos, do the backchannel hack & move on (this version will likely be binned or massively refactored anyway). But when the domain is more stable, modular with solid interfaces is the way to go.
By 6gvONxR4sf7o 2024-01-1917:36 > My overall reaction is that this is a great piece for products/teams that have reached significant scale, once the job to be done is too big and complex for one team to own, end-to-end, or there are truly reusable concerns that can be separated from the core product (e.g. auth, observability).
I'd say it's critical in the small scale too. When you get down to a single person size, this is just what well factored code is: you write down little reasonably independent pieces that can be learned about and thought about without having to think about all the other things. After all, we've all had that experience when you go back and revisit your code after vacation or something, and it might as well have been written by someone else.
I was on a tiny team not long ago where my teammates kept writing tightly coupled systems, then rewriting everything from scratch every time. It was hell. Our product moved slowly, broke constantly, and we couldn't build off of our prior work, and could barely even build off of each others' work, so velocity stayed constant (read: slow).
(as a tangent, the communication patterns of remote work seem to make this more important)
Siloing teams, siloing concerns, and writing modular code are all kind of the same thing, just at different scales.
By acjohnson55 2024-01-1915:003 reply As a coda to this, I think that we are entering a new world where services truly can have minimal operational overhead.
At my last company, we were all in on serverless, with AWS tools like SQS coupling things together. It worked extremely well for keeping the architecture simple to operate and approachable for new people.
But even better, I think we want logical services that interface with each other as though they were in a single process. We want the ability to write code as though it is monolithic (e.g. lexical scope and native-language APIs), while availing ourselves of the advantages of independently deployed services. I believe projects like Temporal point the way. I haven't had the opportunity to use it, but philosophically, I think it's the right direction.
By throw04323 2024-01-1915:081 reply I don't have experience with it myself, but Polylith architecture looks interesting. There you compose services based on shared components. You can start developing it as a monolith, and then extract components to separate services by just changing the interface between components.
By acjohnson55 2024-01-1915:23 If I'm understanding Polylith, it seems like a way to do monoglot monorepo in a way that avoids explicitly using libraries.
That looks pretty interesting and similar to what Artsy did with Ezel for front-end development.
By osigurdson 2024-01-1917:351 reply >> as though they were in a single process
The problem is, you cannot abstract away a 3 order of magnitude difference in performance and latency. This problem increases with larger teams as people don't understand what is happening. Abstractions shorten the learning curve but also greatly slow the formation of an accurate mental model of how a system works.
By nostrebored 2024-01-1918:151 reply The mental model of using SQS and serverless is extremely simple. You put a message in, get a message out, and have your code run.
This is something I’ve been able to teach teams how to do in a few hours. This is the a huge part of the value prop of these services.
Performance and latency have a trade off, sure. But you get teams who have complete ownership over their service. You get services that can scale to millions of requests per minute transparently. Some of the highest scale workloads I know use microservices behind SQS.
By chriswarbo 2024-01-2017:08 > You put a message in, get a message out, and have your code run.
In my experience it's more like put a message in, get an `AuthenticationException`, copy/paste some IAM stanzas into CloudFormation and redeploy, put a message in, get a configuration error, add dependency-injected config loaders to constructors, add env vars to CloudFormation and rededeploy, put a message in, get a deadlock from the threaded HTTP client due to class loading being single-threaded, refactor config loading to happen after construction but populate a cache, redeploy, put a message in, get a timeout due to a stampede on the cache, get a hefty bill from AWS for spinning up a load of long-lived serverless processes, ...
I have been working mostly with Kafka for five years, and I found SQS to be a little weird to work with. How do you keep an overview of all services that consume a queue? What if you want multiple services to read the same data in the same order? Granted I am very new to AWS.
By 8note 2024-01-1918:11 I think you're really looking to use kinesis rather than SQS.
SNS+SQS make a pub/sub setup, but every queue subscribed to the event is fully separate, and you wouldn't expect to try to couple the different listening queues together.
You could make all the queues into SQS fifo queues, and put them all on the same sorting group, but I think network time could still break the ordering on different subscribers?
The simple way to use SQS is to have a queue for each message type you plan to consume, and treat it as a bucket of work to do, where you can control how fast you pull the work out
By jakjak123 2024-01-1916:53 I'm not saying its a silver bullet, because sharing data via database makes change management way worse.
By candiddevmike 2024-01-1914:072 reply This is one of those utopian engineer fallacies that is on the same level as reliable networking and fsync. People don't work like computers and don't respond like API endpoints. There will always be backchannels, backburners, pidgeonholes, and all the other political games humans play happening even with an "API between them".
The problem is always management, and the solution is never "more management", IMO.
The whole point of the article is that silos are not intrinsically bad, partially because silos reduces communication (and therefor managers) required
Two teams agreeing on an API between themselves instead of one mega team fulfilling the needs of several client teams
By throw04323 2024-01-1914:321 reply > Two teams agreeing on an API between themselves
I think that depends on the type of service that the team provides. If you have a central team that many other teams interact with, they risk becoming a bottleneck. They may not be interested in maintaining custom APIs for each team interaction and you will need to agree on a contract that all can live with.
Another risk is that the team providing the service also have their own backlog, including work they want to do themselves and requests from other teams. This can cause unwanted dependencies and delays where managers try to fight to be prioritized on the expense of others.
By packetlost 2024-01-1914:424 reply All I'm saying is it appears to have worked at mega-scale for Amazon.
By acjohnson55 2024-01-1914:481 reply Most of us don't have mega-scale problems, though. A tremendous amount of waste has been created by applying FAANG tech and processes to completely different contexts.
By packetlost 2024-01-1915:551 reply Sure, but scaling of an organization is not the same as scaling for traffic in a technical sense. There are so many companies that employ comparable numbers of engineers that are not big tech companies.
By acjohnson55 2024-01-235:25 That makes sense to me. I think you're right that if you're a large enterprise, it may well make sense to adopt a very API-centric strategy for how teams interface, even if the scale doesn't demand it from a tech perspective.
By throw04323 2024-01-1914:482 reply I'm not saying it can't work, but that there are risks involved.
I have worked for several companies ranging from local startups to global enterprise (not FAANG). Each company tried the silo approach when they migrated to micro services and it caused significant delays and dependencies. They would have been better off if they focused more on larger domain services with fewer external dependencies.
I am open to the idea that Amazon has been able to avoid these problems, but it's clearly not a silver bullet.
In general I have to say I'm sceptical about comparisons with FAANG, because they live in a completely separate part of the technology sector. They have income similar to small countries and can live with inefficiencies that can break a startup.
By DanielHB 2024-01-1915:27 The problem I see are big companies with several products trying to break down silos between the products to share some infrastructure (be it code, libs, actual cloud infra, support teams, design systems etc) when there is very little overlap between the different products.
All in some grand hope of reducing costs by sharing things. It almost always ends with overly generic solutions that are harder to use, takes more people to support, can't be fitted well in most cases and that everyone involved hates (causing employee attrition).
This is different from having cohesive architecture within a single product.
By randomdata 2024-01-1915:22 > Each company tried the silo approach when they migrated to micro services
Doesn't that go without saying? That's literally what micro services is: The siloing of services, just as service is provided in the macro economy, but within the micro economy of a single organization. Without silos, your service is monolithic.
By pixl97 2024-01-1918:12 > appears to have worked
Mostly because someone at a higher level said "Your APIs are not a silo, and if you act like they are you will be terminated".
The communication cost will always be there, the question is one of how is it implemented. In the case of an API it tends to reduce the communication costs when someone is forcing all teams at gunpoint to write clear, concise, and well documented APIs and don't allow them to change said APIs without clear, concise, and well documented rules.
I've worked with teams that communicated via API and started randomly changing shit without proper documentation, and without management being held to the fire over their actions, it's just a new type of silo.
By marcosdumay 2024-01-1915:09 Yes, it scales up very well.
People upthread are trying to say it scales down badly.
By dkarl 2024-01-1918:17 Agreeing means the providing team understanding and meeting the needs of the consuming team. Teams that can work together to accomplish this wouldn't be called "silos."
However, when two teams work together to create an API, or a process or some other self-service mechanism, sometimes the API so good that the teams no longer need to talk to each other. The practices and relationships that enabled communication fade away. Walls go up, silos form, but nobody notices anything wrong, because it seems like efficiency is getting better and better. Over time, though, people start to notice that projects that encounter a need to change the API always fail. The API has become legacy, baggage, a problem.
There may still be somebody on the providing team who remembers that they used to get together in the same room with developers from the consuming team to come up with solutions together, and they'll naively suggest that as a solution, but there are now too many assumptions baked in at the management level for that to be allowed to happen. A change in the working relationship between teams means the managers will fight over what this means for different managers' prestige. Somebody's cheese is going to get moved. Managers gear up to go to war over things like that, so upper management dictates a solution that minimizes inter-manager violence, a solution that carefully circumscribes the kinds and amounts of contact that members of the two teams are allowed to have. Voila: silos with windows, and engineers sitting in their respective windows forlornly waving at each other like lovers separated by their parents.
an API does not mean there are no hidden dependencies, and that is often the biggest failure.
If an API call is not stateless, or requires to be chained with other calls, you're in for a world of pain in the long run
By nostrebored 2024-01-1918:20 But this is equivalent to saying “a monolith can never work because it’s highly coupled”. In both cases you need to follow best practices to make things work. API design and alignment with consumers of the API is table stakes.
By whynotmaybe 2024-01-1918:061 reply Unless you work at a place where ops don't write code because "it's the dev's job to write code", so everything is built and done manually; and devs don't have access to any infrastructure and don't bother about it, because "it's the ops' job".
And management of both sides agree with this vision.
"works on my machine" and "the issue must be with the code" are the most used excuses by both sides when something fails.
The ops "api" works by email, but the response delay is usually expressed in weeks.
Most memorable quote from that place : "Yes, a 4 month delay for an answer about your new server might seem long"
By slaymaker1907 2024-01-1919:311 reply "We can have that new release deployed in about 6-8 weeks."
By jahsome 2024-01-1920:24 I find myself these days on one of these ops teams. The lead time is the same for deploying either a code or infrastructure change, and probably closer to 3-4 months here.
It's not an operational capacity or competency issue for this org, it's the result of hours worth of "sync" or "review" meetings with no discernible agenda, negotiating maintenance windows, facilitating approvals from a dozen or more parties who don't even comprehend what they're approving, and weeks of manual acceptance testing.
On the other extreme, in past roles at different orgs, I've been on teams doing multiple deployments to production every day, both on the dev and ops sides.
I find it exhausting and soul crushing being completely untrusted because of the mistakes made by people who left the org years before I started.
