© 2024 ę ń. All rights reserved. Web feed
Read the original article
Comments
My rule of thumb is to treat strings as opaque blobs most of the time. The only validation I'd always enforce is some sane length limit, to prevent users from shoving entire novels inside. If you treat your strings as opaque blobs, and use UTF8, most of internationalization problems go away. Imho often times, input validation is an attempt to solve a problem from the wrong side. Say, when XSS or SQL injections are found on a site, I've seen people's first reaction to be validation of user input by looking for "special symbols", or add a whitelist of allowed characters, instead of simply escaping strings right before rendering HTML (and modern frameworks do it automatically), or using parameterized queries if it's SQL. If a user wants to call themselves "alert('hello')", why not? Why the arbitrary limits? I think there're very few exceptions to this, probably something law-related, or if you have to interact with some legacy service.
Sanitizing your strings immediately before display is all well and good until you need to pass them to some piece of third-party software that is very dumb and doesn’t sanitize them. You’ll argue that it’s the vendor’s fault, but the vendor will argue that nobody else allows characters like that in their name inputs!
See the Companies House XSS injection situation, where their rationale for forcing a business to change its name was that others using their database could be vulnerable: https://www.theregister.com/2020/10/30/companies_house_xss_s...
You sanitize at the frontier of what your code controls.
Sending data to a database: parametrized queries to sanitize as it is leaving your control.
Sending to display to the user: sanitized for a browser
Sending to an API: sanitize for whatever rules the API has
Sending to a legacy system: sanitize for it
Writing a file to the system: sanitize the path
The common point is you don't sanitize before you have to send it somewhere. And the advantage of this method is that you limit the chances of getting bit by reflected injections. You interrogate some API you don't control, you may just get malicious content, but you sanitize when sending it so all is good. Because you're sanitizing on output and not on input.
By account42 2024-11-2614:37 What if the legacy API doesn't support escaping? Just drop characters? Implement your own ad-hoc transform? What if you need to interoperate with other API users.
Limting the character set at name input gives the user the chance to use the same ASCII-encoding of their name in all places.
By shaky-carrousel 2024-11-2513:221 reply Be liberal in what you accept, and conservative in what you send.
By int_19h 2024-11-2518:21 Please don't. This is how standards die.
Forbidding users to use your service to propagate "litte bobby tables" pseudo-pranks is likely a good choice.
The choice is different if like most apps you are almost only a data sink, but if you are also a data source for others it pays to be cautious.
I think it’s more of an ethical question than anything. There will always be pranksters and there will never be perfect input validation for names. So who do you oppress? The people with uncommon names? Or the pranksters? I happen to think that if you do your job right, the pranksters aren’t really a problem. So why oppress those with less common names?
I am not saying to only allow [a-zA-Z ]+ in names, what I am Saying is that it is ok to block names like "'; drop table users;" or "<script src="https://bad.site.net/></script>" if part of your business is to distribute that data to other consumers.
And I’m arguing, rhetorically, what if your name produces a syntax error—or worse means something semantically devious—in the query language I’m using? Not all problems look like script tags and semicolons.
By foldr 2024-11-2512:20 It's a question of intent. There aren't any hard and fast rules, but if someone has chosen their company name specifically in order to cause problems for other people using your service, then it's reasonable to make them change it.
By account42 2024-11-2614:44 This is getting really absurd. Are you also going to complain that Unicode is too restrictive or are you going to demand being able to use arbitrary bytes as names. Images? If Unicode is enough, then which version.
There is always a somewhat arbitrary restriction. It's not unreasonable to also take other people into account besides the user wanting to enter his special snowflake name.
No one is being oppressed. Having to use an ASCII version of your name is literally a non-issue unless you WANT to be offended.
Maybe also think of the other humans that will need to read and retype the name. Do you expect everyone to understand and be able to type all characters? That's not reasonable. The best person to normalize the name to something interoperable is the user himself, so make him do it at data entry.
By mabster 2024-11-2712:49 I was saying the exact same thing about how I don't understand why people get offended when they have to transcribe their name to use Hanzi!
We should have a world vote to settle which alphabet we use.
> but the vendor will argue that nobody else allows characters like that in their name inputs
...and maybe they will even link to this page to support that statement! But, seeing that most of the pages are German, I bet they do accept the usual German "special" letters (ÄÖÜß) in names?
By account42 2024-11-2614:49 So? Have you considered that the names may need to be eventually processed by people who understand the German alphabet but not all French accents (and certinly won't be able to type Hanzi or arabic or whatever else you expect everyone to support)? Will every system they interact with be able to deal with arbitrary symbols. Does the font of their letterhead support every script?
It's reasonable to expect a German company to deal with German script, less reasonable to expect them to deal with literally every script that someone once thought would be funny to include in Unicode.
> The only validation I'd always enforce is some sane length limit, [..]
Venture into the abyss of UTF-8 and behold the madness of multibyte characters. Diacritics dance devilishly upon characters, deceiving your simple count. Think a letter is but a single entity? Fools! Combining characters lurk in the shadows, binding invisibly, elongating the uninitiated's count into chaos. Every attempt to enumerate the true length of a string in UTF-8 conjures a specter of complications. Behold, a single glyph, yet multiple bytes cackle beneath, a multitude of codepoints coalesce in arcane unison. It is beautiful t he final snuffing of the lie s of Man ALL IS LOST ALL I S LOST the pony he comes he comes he comes the ich or permeates all MY FACE MY FACE ᵒh god no NO NOOO O NΘ stop the an * gles are n ot real ZALGΌ IS TOƝȳ THE PO NY HE COMES
By hnfong 2024-11-2620:38 A nit - it's not UTF-8 or "multibyte" characters that's the main problem. The UTF-8 issue can be trivially resolved by decoding it into unicode code points. As long as you're fine with the truncated length not always corresponding to what you'd expect for Latin based alphabets it should be fine. (FWIW, if you are concerned with the displayed length, you'd need a font and a text layout engine to calculate the display length of displayed text)
The main issue with naïve truncation is that not every code point is a character (and I guess not every character is a glyph?). If you truncate the Unicode code point array at some unfortunate places like https://en.wikipedia.org/wiki/Ideographic_Description_Charac... , you'd just get gibberish or potentially very unintended results. (especially if you joined the truncated string with some other string)
There's at least one major exception to this: Unicode normalization.
It's possible for the same logical character to have two different sets of code points (for example, a-with-umlaut as a single character, vs a followed by umlaut combining diacritic). Related, distinguishing between the "a" character in Latin, Greek, Cyrillic, and the handful of other times it shows up throughout Unicode.
This comes up in at least 3 ways:
1. A usability issue. It's not always easy to predict which identical-looking variant is produced by different input methods, so users enter the identical-looking characters on different devices but get an account not found error.
2. A security issue. If some of your backend systems handle these kinds of characters differently, that can cause all kinds of weird bugs, some of which can be exploited.
3. An abuse issue. If it's possible to create accounts with the same-looking name as others that aren't the same account, there can be vectors for impersonation, harassment, and other issues.
So you have to make a policy choice about how to handle this problem. The only things that I've seen work are either restricting the allowed characters (often just to printable ASCII) or being very clear and strict about always performing one of the standard Unicode transformations. But doing that transformation consistently across a big codebase has some real challenges: in particular, it can change based on Unicode version, and guaranteeing that all potential services use the same Unicode version is really non-trivial. So lots of people make the (sensible) choice not to deal with it.
But yeah, agreed that parenthesis should be OK.
Something we just ran in to: There are two UTF-8 codepoints for the @ character, the normal one and "Full width At Sign U+FF20". It took a lot of head scratching to understand why several Japanese users could not be found with their email address when I was seeing their email right there in the database.
By teddyh 2024-11-2512:55 There are actually two more: U+FE6B and U+E0040.
Type system ftw? As long as it's a blob (unnormalized), it should have a blob type which can do very little besides storing and retrieving, perhaps printing. Only the normalized version should be even comparable.
You can treat names as byte blobs for as long as you don't use them for their purpose -- naming people.
Suppose you have a unicode blob of my name in your database and there is a problem and you need to call me and say hi. Would your customer representative be able to pronounce my name somewhat correctly?
>I think there're very few exceptions to this, probably something law-related, or if you have to interact with some legacy service.
Few exceptions for you is entirety of the service for others. At the very least you interact with legacy software of payment systems which have some ideas about what names should be.
> Would your customer representative be able to pronounce my name somewhat correctly?
Are you implying the CSR's lack of familiarity with the pronunciation of your name means your name should be stored/rendered incorrectly?
Quite the opposite actually. I want it stored correctly and in a way that both me and CSR can understand and so it can be used to interface with other systems.
I don’t however know which unicode subset to use, because you didn’t tell me in the signup form. I have many options, all of them correct, but I don’t know whether your CSR can read Ukrainian Cyrillic and whether you can tell what vocative case is and not use that when inerfacing with the government CA which expects nominative.
By ACS_Solver 2024-11-259:132 reply I think you're touching on another problem, which is that we as users rarely know why the form wants a name. Is it to be used in emails, or for sending packages, or for talking to me?
My language also has a separate vocative case, but I live in a country that has no concept of it and just vestiges of a case system. I enter my name in the nominative, which then of course looks weird if I get emails/letters from them later - they have no idea to use the vocative. If I knew the form is just for sending me emails, I'd maybe enter my name in the vocative.
Engineers, or UX designers, or whoever does this, like to pretend names are simple. They're just not (obligatory reference to the "falsehoods about names" article). There are many distinct cases for why you may want my name and they may all warrant different input.
- Name to use in letters or emails. It doesn't matter if a CSR can pronounce this if it's used in writing, it should be a name I like to see in correspondence. Maybe it's in a script unfamiliar to most CSRs, or maybe it's just a vocative form.
- Name for verbal communication. Just about anything could be appropriate depending on the circumstances. Maybe an anglicized name I think your company will be able to pronounce, maybe a name in a non-Latin script if I expect it to be understood here, maybe a name in a Latin-extended script if I know most people will still say it reasonably well intuitively. But it could also be an entirely different name from the written one if I expect the written one to be butchered.
- Name for package deliveries. If I'm ordering a package from abroad, I want my name (and address) written in my local convention - I don't care if the vendor can't read it, first the package will make its way to my country using the country and postal code identifiers, and then it should have info that makes sense to the local logistics companies, not to the seller's IT system.
- Legal name because we're entering a contract or because my ID will be checked later on for some reason.
- Machine-readable legal name for certain systems like airlines. For most of the world's population, this is not the same as the legal name but of course English-language bias means this is often overlooked.
By pezezin 2024-11-260:32 > - Name for package deliveries. If I'm ordering a package from abroad, I want my name (and address) written in my local convention - I don't care if the vendor can't read it, first the package will make its way to my country using the country and postal code identifiers, and then it should have info that makes sense to the local logistics companies, not to the seller's IT system.
I am not sure that what you ask is possible, there might be local or international regulations that force them to write all the addresses in a certain way.
But on the positive side, I have found that nowadays most online shops provide a free-from field for additional delivery instructions. I live in Japan, and whenever I order something from abroad I write my address in Japanese, and most sellers are nice enough to print it and put it on the side of the box, to make the life of the delivery guys easier.
The thing is "printable ASCII letters" is something usable for all of those cases. It may not be 100% perfect for the user's feelings but it just works.
By ACS_Solver 2024-11-2615:33 This is patently wrong and it's the sort of thinking that still causes inconvenience to people using non-ASCII languages, years after it's technically justifiable.
The most typical problem scenario is getting some package or document with names transformed to ASCII and then being unable to actually receive the package or use the document because the name isn't your name. Especially when a third party is involved that doesn't speak the language that got mangled either.
Åke Källström is not the same name as Ake Kallstrom. Domestically the latter just looks stupid but then you get a hotel booking with that name, submit it as part of your visa application and the consulate says it's invalid because that's not your name.
Or when Rūta Lāse gets some foreign document or certificate, nobody in her country treats is authentic because the name written is Ruta Lase, which is also a valid and existing name - but a different one. She ends up having to request another document that establishes the original one is issued to her, and paying for an apostille on that so the original ASCII document is usable. While most languages have a standard way of changing arbitrary text to ASCII, the conversion function is often not bijective even for Latin-based alphabets.
These are real examples of real problems people still encounter because lots of English-speaking developers insist everyone should deal with an ASCII-fied version of their language. In the past I could certainly understand the technical difficulties, but we're some 20-25 years past the point where common software got good Unicode support. ASCII is no longer the only simple solution.
In this specific case, it seems like your concerns are a hypothetical, no?
By swiftcoder 2024-11-257:462 reply Not really, no. A lot of us only really have to deal with English-adjacent input (i.e. European languages that share the majority of character forms with English, or cultures that explicitly Anglicise their names when dealing with English folks).
As soon as you have to deal with users with a radically different alphabet/input-method, the wheels tend to come off. Can your CSR reps pronounce names written in Chinese logographs? In Arabic script? In the Hebrew alphabet?
By cowsandmilk 2024-11-258:262 reply You can analyze the name and direct a case to a CSR who can handle it. May be unrealistic for a 1-2 person company, but every 20+ person company I’ve worked at has intentionally hired CSRs with different language abilities.
By Muromec 2024-11-259:55 First of, no you can't infer language preference from a name. The reasonable and well meaning assumption about my name on a good day makes me only sad and irritated.
And even if you could, I don't know if you actually do it by looking at what you signup form asks me to input.
By michaelt 2024-11-259:08 A requirement to do that is an extremely broad definition of "treat strings as opaque blobs most of the time" IMHO :)
For one thing, this concern applies equally to names written entirely in Latin script. Can your CSR reps correctly pronounce a French name? How about Polish? Hungarian?
In any case, the proper way to handle this is to store the name as originally written, and have the app that CSRs use provide a phonetic transcription. Coincidentally, this kind of stuff is something that LLMs are very good at already (but I bet you could make it much more efficient by training a dedicated model for the task).
This situation is not the same at all. The CSR might mangle a name in latin script but can at least attempt to pronounce it and will end up doing so in a way that the user can understand.
Add to that that natives of non-latin languages are already used to this.
For better or worse, English and therefore the basic latin script is the lingua franca of the computing age. Having something universal for internation communication is very useful.
By GoblinSlayer 2024-11-2715:46 FWIW, proquint encoding allows you to pronounce any sequence of bits, though the need for pronunciation eludes me, just copypaste it.
> Suppose you have a unicode blob of my name in your database and there is a problem and you need to call me and say hi. Would your customer representative be able to pronounce my name somewhat correctly?
You cannot pronounce the name regardless of whether it is written in ASCII. Pronouncing a name requires at the very least knowledge of the language it originated in, and attempts at reading it with an English pronunciation can range from incomprehensible to outright offensive.
The only way to correctly deal with a name that you are unfamiliar with the pronunciation of is to ask how it is pronounced.
You must store and operate on the person's name as is. Requiring a name modified, or modifying it automatically, is unacceptable - in many cases legal names must be represented accurately as your records might be used for e.g. tax or legal reasons later.
>You must store and operate on the person's name as is. Requiring a name modified, or modifying it automatically, is unacceptable
But this is simply not true in practice and at times it's just plain wrong in theory too. The in practice part is trivially discoverable in the real world.
As to in theory -- I do in fact want a properly functioning service to use my name in a vocative case (which requires modifying it automatically or having a dictionary of names) in their communications that are sent in my native language. Not doing that is plainly grammatically wrong and borderline impolite. In fact I use services that do it just right. I also don't want to know to specify the correct version myself, as it's trivially derivable through established rules of the languages.
By arghwhat 2024-11-2514:33 Sure, there are sites that mistreat names in ways you describe, but that does not make it correct.
> I do in fact want a properly functioning service to use my name in a vocative case. ... I also don't want to know to specify the correct version myself, as it's trivially derivable through established rules of the languages.
There would be nothing to discuss if this was trivial.
> Not doing that is plainly grammatically wrong and borderline impolite.
Do you know what's more than borderline impolite? Getting someone's name wrong, or even claiming that their legal name is invalid and thereby making it impossible for them to sign up.
If getting a name right and using a grammatical form are mutually exclusive, there is no argument to be had about which to prioritize.
By account42 2024-11-2615:18 > You cannot pronounce the name regardless of whether it is written in ASCII. Pronouncing a name requires at the very least knowledge of the language it originated in, and attempts at reading it with an English pronunciation can range from incomprehensible to outright offensive.
Offensive if you WANT to be offended perhaps but definitely understandable, which is the main thing that matters.
By throw_a_grenade 2024-11-2513:13 Sorry to nitpick, but you underestimated: "many cases" is really "all cases", no exception, because under GDPR you have right to correct your data (this is about legal name, so obviously covered). So if user requests under GDPR art. 16 that his/her name is to be represented in a way that matches ID card or whatever legal document, then you either do it, or you pay a fine and then you do it.
That a particular technical solution is incapable of storing it in the preferred way is not an excuse. EBCDIC is incompatible with GDPR: https://news.ycombinator.com/item?id=28986735
Absolutely not - do not build anything based on "would your CSR be able to pronounce" something - that's an awful bar - most CSRs cant pronounce my name - would I be excluded from your database?
Seriously, what are you going for here?
That’s the most basic consideration for names, unless you only show it to the user themselves — other people have to be able to read it at least somehow.
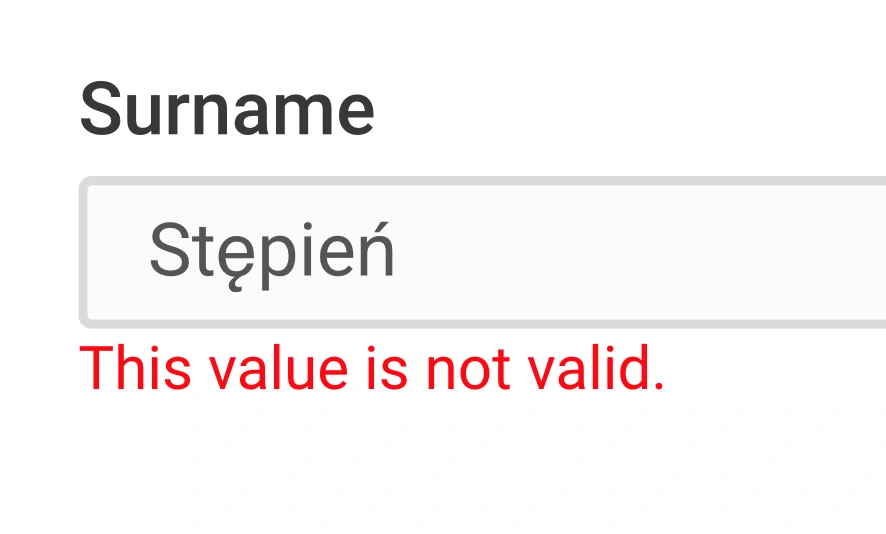
Which one is why the bag of unicode bytes approach is as wrong as telling Stęphań he has an invalid name.
By hobs 2024-11-255:25 Absolutely not. There's no way to understand what a source user's reading capability is. There's no way to understand how a person will pronounce their name by simply reading it, this only works for common names.
And here we go again, engineers expecting the world should behave fitting their framework du jour. Unfortunately, the real world doesn't care about our engineering bubble and goes on with life - where you can be called !xóõ Kxau or ꦱꦭꦪꦤ or X Æ A-12.
I can be called what I want and in fact I have perfectly reasonable name that doesn't fit neither ASCII nor FN+LN convention. The thing is, your website accepting whatever utf8 blob my name can be serialized to today, without actually understanding it, makes my life worse, not better.
No, it allows an exact representation of your name, it doesn't do anything to your life.
If you dont like your name, either change it or go complain to your parents. They might tell you that you cultural reference point is more important than some person being able to read your name off of a computer screen.
If you want to store a phonetic name for the destination speaker that's not a bad idea, but a name is a name is a name. It is your unique identifier, do not munge it.
But it does affect my life in a way you refuse to understand. That's the problem -- there isn't a true canonical representation of a name (any name really) that fits all practical purposes. Storing a bag of bytes to display back to user is the easiest of practical purposes and suggesting the practice that solve that is worse than rejecting Stępień, it's refusal to understand complexities, that leads to eventually doing the wrong thing and failing your user without even telling them.
>It is your unique identifier, do not munge it.
It's not a good identifier either. Nobody uses names as identifiers at any scale that matters for computers. You can't assume they don't have collisions, you can't tell whether two bags of bytes identify the same person or two different, they aren't even immutable and sometimes are accidentally mutable.
Then where is the problem? If the support can read Polish they will pronounce your name properly, if they're from India they will mess it up, why should we have different expectations? Nobody will identify you by name anyway, they will ask how to call you (chatbots do this already) and then use for proper identification all kind of ids and pins and whatnot. So we are talking here about a complexity that nobody actually needs, not even you. So let the name be saved and displayed in the nice native way, and you as programmer make sure you don't go Bobby Tables with the strings.
>if they're from India they will mess it up
Or not able to read at all.
>Then where is the problem?
Since you don't indicate for what purpose my name is stored, which may actually be display only, any of the following can happen:
A name as entered in your system is compared to a name entered in a different system or when you interface (maybe indirectly and unknowingly) with a system using different constrains or a different script, maybe imposed by their jurisdiction. As a result, the intended operation does not come through.
This may happen in the indirect way and invisible to you -- e.g. you produce an artifact, say and invoice or issue a payment card using $script a, which I will only later figure out I can't use, because it's expected to be in $script b, or even worse be in $script a presumed to match $script b they have on record. One of the non-obvious ways it can fail, is when you try to determine whether two names in the same script are actually the same to infer family relationship or something other that you should not do anyway.
It may happen within your system in a way your CSR will deny is possible as well.
That's on a more severe side, which means I will not try to use the name in any rendering that doesn't match MRZ of my identity document. Which was probably the opposite of what you intended allowing arbitrary bag of bytes to be entered. No, that is not made up problem, because I'm bored, it's a thing.
On a less sever side, not understanding names is a failure in i18n department, because you can't support my language properly without understanding how my name should be changed when you address me, when you simply show it near user icon and when you describe relations between me and objects and people. If you can't do proper i18n and a different provider can, you may lose me as a customer, because your attitude is presumed to be "everyone can just use ASCII and English". Yes, people exist that actually get it right because they put an effort in this human aspect.
On a mildly annoying, but inconsequential side people also have a habit of trying to infer gender based on names despite having gender clearly marked in their system.
By hobs 2024-11-2516:39 Managing the canonical representation of your name in my system is one of the few things you are responsible for.
The number of times I have had people ask me to customize name rendering, capitalize things, trying to build phonetic maps, all of these things to avoid data entry or confusion and all they do is prove out that you can't have a general solution to human names, you can hit a big percentage in a cultural context, but there's always exceptions and edge cases to the problem we're solving which can be described as "please tell me your name when you call or whatever so I can pronounce it right"
By soco 2024-11-268:36 >Or not able to read at all.
"Hello, how should we address you?". Not everything must be done in code.
>when you interface (maybe indirectly and unknowingly) with a system using different constrains
I have yet to encounter a system recognizing assets and making automatic decisions based on name. It would fail already if the user switched first/last name.
>people exist that actually get it right
You could have started by explaining this right way and we'd be all smarter.
By hobs 2024-11-2516:36 There's no such thing as a data structure that fits "all practical purposes" that is correct.
There's no wrong thing - this is the best representation we can make given the system of record for the person's name.
They are definitely mutable, context dependent, and effectively data you cannot make assumptions about because of all those things.
If you want to do more than that you need a highly constrained use case, and its going to fail for "all practical purposes".
By account42 2024-11-2615:25 Your examples are a great argument why we should not allow people to use arbitrary characters. Special snowflakes will be able to cope, I assure you.
>Would your customer representative be able to pronounce my name somewhat correctly?
Typical input validation doesn't really solve the problem. For instance, I could enter my name as 'Vrdtpsk,' which is a perfectly valid ASCII string that passes all validation rules, but no one would be able to pronounce it correctly. I believe the representative (if on a call) should simply ask the customer how they would like to be addressed. Unless we want to implement a whitelist of allowed names for customers to choose from...
By manarth 2024-11-257:40 Derek would like a word.
By Intermernet 2024-11-258:181 reply Many Japanese companies require an alternative name entered in half width kana to alleviate this exact problem. Unfortunately, most Japanese websites have a million other UX problems that overshadow this clever solution to the problem.
By arghwhat 2024-11-259:55 This is a problem specific to languages using Chinese characters where most only know some characters and therefore might not be able to read a specific one. Furigana (which is ultimately what you're providing in a separate field here) is often used as a phonetic reading aid, but still requires you to know Japanese to read and pronounce it correctly.
The only generic solution I can think of would be IPA notation, but it would be entirely unreasonable to expect someone to know the IPA for their name, just as it would be unreasonable to expect a random third party to know how to read IPA and replicate the sounds it described.
By red_admiral 2024-11-2511:291 reply > Would your customer representative be able to pronounce my name somewhat correctly?
If the user is Chinese and the CSR is not - probably no, and that's not a Unicode issue.
By account42 2024-11-2615:32 Yet the CSR will be able to adequately pronounce a romanized ASCII-only version of the chinese name. And that's an entirely reasonable thing to do for western organizations and governments just like you might need to get a chinese name to interact with the chinese bureaucracy.
By benatkin 2024-11-255:34 > Would your customer representative be able to pronounce my name somewhat correctly?
Worse case, just drop to hexadecimal.
By wvh 2024-11-2510:38 Because you don't want to ever store bad data. There's not point to that, it will just create annoying situations and potential security risks. And the best place to catch bad data is when the user is still present so they can be made aware of the issue (in case they care and are able to solve it). Once they're gone, it becomes nearly impossible and/or very expensive to check what they meant.
> If you treat your strings as opaque blobs, and use UTF8, most of internationalization problems go away
This is laughably naive.
So many things can go wrong.
Strings are not arrays of bytes.
There is a price to pay if someone doesn't understand that or chooses to ignore it.
> Strings are not arrays of bytes.
That very much depends on the language that you are using. In some, they are.
By lelandbatey 2024-11-255:35 And yet when stored on any computer system, that string will be encoded using some number of bytes. Which you can set a limit on even though you cannot cut, delimit, or make any other inference about that string from the bytes without doing some kind of interpretation. But the bytes limit is enough for the situation the OP is talking about.
By rpigab 2024-11-259:11 RTL is so much fun, it's the gift that keeps on going, when I first encountered it I thought, ok, maybe some junior web app developers will sometimes forget that it exists and a fun bug or two will get into production, but it's everywhere, Windows, GNU/Linux, automated emails, it can make malware hardware to detect by users in Windows because you can hide the dotexe at the beginning of the filename, etc.
Here it is today in GNOME 46.0, after so many years, this should say "selected": https://github.com/user-attachments/assets/306737fb-6b01-467... In previous GNOME versions it would mess up even more text in the file properties window.
Here's an article about it, but I couldn't find the more interesting blogpost about RTL: https://krebsonsecurity.com/2011/09/right-to-left-override-a...
By JodieBenitez 2024-11-2510:23 > or if you have to interact with some legacy service.
Which happens almost every day in the real world.
By beagle3 2024-11-2510:47 You do need to use a canonical representation, or you will have two distinct blobs that look exactly the same, tricking other users of the data (other posters in a forum, customer service people in a company, etc)
By kazinator 2024-11-2519:03 > treat strings as opaque blobs most of the time
While being transparent is great and better than stupidly mangling or rejecting data, the problem is that if we just pass through anything, there are situations and contexts in which some kinds of software could be used as part of a chain of deception involving Unicode/font tricks.
Passing through is mostly good. Even in software that has to care about this, not every layer through which text passes should have the responsibility.
A coworker once implemented a name validation regex that would reject his own name. It still mystifies me how much convincing it took to get him to make it less strict.
By throw310822 2024-11-2415:062 reply I know multiple developers who would just say "well it's their fault, they have to change name then".
I worked with an office of Germans who insisted that ASCII was sufficient. The German language uses letters that cannot be represented in ASCII.
In fairness, they mostly wanted stuff to be in English, and when necessary, to transliterate German characters into their English counterparts (in German there is a standardised way of doing this), so I can understand why they didn't see it was necessary. I just never understood why I, as the non-German, was forever the one trying to convince them that Germans would probably prefer to use their software in German...
By bee_rider 2024-11-2421:29 I’ve run into a similar-ish situation working with East-Asian students and East-Asian faculty. Me, an American who wants to be clear and make policies easy for everybody to understand: worried about name ordering a bit (Do we want to ask for their last name or their family name in this field, what’s the stupid learning management system want, etc etc). Chinese co-worker: we can just ask them for their last names, everybody knows what Americans mean when they ask for that, and all the students are used to dealing with this.
Hah, fair enough. I think it was an abstract question to me, so I was looking for the technically correct answer. Practical question for him, so he gave the practical answer.
You should have asked how they would encode the german currency sign (€ for euro) in ASCII or its german counterpart latin1/iso-8859-1...
It's not possible. However I bet they would argument to use iso-8859-15 (latin9 / latin0) with the international currency sign (¤) instead or insist that char 128 of latin1 is almost always meant as €, so just ignore the standard in these cases and use a new font.
This would only fail in older printers and who is still printing stuff these days? Nobody right?
Using real utf-8 is just too complex... All these emojis are nuts
By richardwhiuk 2024-11-2422:111 reply EUR is the common answer.
Weirdly the old Deutsch Mark doesn't seem to have its own code point in the block start U+20A0, whereas the Spanish equivalent (Peseta, ₧, not just Pt) does.
It's not a Unicode issue, there just isn't a dedicated symbol for it, everyone just used the letters DM. Unicode (at least back then) was mostly a superset of existing character sets and then distinct glyphs.
By Y_Y 2024-11-2616:20 That would be a fine answer, but for the fact that other currencies like the rupee (₨) that are "just letters" do have their own codepoint. Being made up of two symbols doesn't necessarily make something not a symbols, in semiotics or in Unicode.
In fact this is one of the root problems, there are plenty of Unicode symbols you can make out of others, either juxtaposing or overstriking or using a combining character, but this isn't consistently done.
By tugu77 2024-11-257:22
By throw0101a 2024-11-2512:33 By sandreas 2024-11-2814:01 Besides UTF-8 is not that simple, it still was irony :-)
There are some valid reasons to use software in English as a German speaker. Main among those is probably translations.
If you can speak English, you might be better of using the software in English, as having to deal with the English language can often be less of hassle, than having to deal with inconsistent, weird, or outright wrong translations.
Even high quality translations might run into issues, where the same thing is translated once as "A" and then as "B" in another context. Or run into issues where there is an English technical term being used, that has no prefect equivalent in German (i.e. a translation does exist, but is not a well-known, clearly defined technical term). More often than not though, translations are anything but high quality. Even in expensive products from big international companies.
By MrJohz 2024-11-2621:58 This is definitely a problem that can occur, but for the one I was thinking of originally when writing the comment, we had pretty much all the resources available: the company sold internationally, so already had plenty of access to high-quality translators, and the application we were building was in-house, so we could go and ask the teams themselves if the translations made sense. More importantly, the need was also clearly there - many of the users of the application were seasonal workers, often older and less well-educated, in countries where neither English nor German were particularly relevant languages. Giving buttons labels in our users' languages meant they could figure out what they needed to do much more quickly, rather than having to memorise button colours and positions.
You're right that sometimes translation for technical terms is difficult, but the case I experienced far more often was Germans creating their own English words, or guessing at phrases they thought ought to exist because their English was not as good at they believed.
I agree that high quality translations are hard, and particularly difficult to retrofit into an existing application. But unless you have a very specialised audience, they're usually worth it!
By Muromec 2024-11-2512:51 UX translations are broken most of the time for most of the software and not just in German. People just pretend it's working and okay, when it's not.
And then developers just do N > 1 ? "things" : "thing" without thinking twice, not use pgettext and all the other things.
By account42 2024-11-2615:51 Compiler errors or low level error messages in general are a good example. Translating them reduces the ability of someone who doesn't share your language to help you.
By throw0101a 2024-11-2512:291 reply > I just never understood why I, as the non-German, was forever the one trying to convince them that Germans would probably prefer to use their software in German...
I've heard that German is often one of the first localizations of (desktop) software because there were often super-long words in the translations of various concepts, so if you wanted to test typeface rendering and menu breakage it was good language to run through your QA for that.
By int_19h 2024-11-2518:37 Or you use pseudo-localization, which does simple programmatic substitution to make all English strings longer by e.g. doubling letters or inserting random non-alphabetic characters, adding diacritics etc while still retaining readability to English speakers.
Windows actually ships with a locale like that.
By ordu 2024-11-255:22 > I just never understood why I, as the non-German, was forever the one trying to convince them that Germans would probably prefer to use their software in German...
I cannot know, but they could be ideological. For example, they had found it wonderful to use plain ASCII, no need for special keyboard layouts or something like that, and they decided that German would be much better without its non-ASCII characters. They could believe something like this, and they wouldn't say it aloud in the discussion with you because it is irrelevant for the discussion: you weren't trying to change German.
Perhaps you shouldn't be speaking for Germans then? Personally, I'd rather not have localization forces on me. Looking at you, Google.
By MrJohz 2024-11-2621:47 I don't think localisation should be forced on anyone, but we had enough people using our software who couldn't speak English that getting it right would have made a lot of people's lives easier. At one place I worked, they even added Cantonese text to a help page to let Cantonese users know how to get support - but all the text on the buttons and links to get to that point was in English!
As developers, we need to build software for our users, and not for ourselves. That means proper localisation, and it means giving users the option of choosing their own language and settings.
By guappa 2024-11-2511:28 I know someone who changed name just to remove the dots and have an "easier time when travelling"
By guappa 2024-11-2511:26 Our own software that we sell was crashing if you had a locale set in anything else than american english.
The coworker who made that happen said I'm a weirdo for setting my machine in my own language. According to him I should have set it to english.
This of course happened in a non english speaking country.
By perching_aix 2024-11-2422:253 reply In certain cultures yes. Where I live, you can only select from a central, though frequently updated, list of names when naming your child. So theoretically only (given) names that are on that list can occur.
Family names are not part of this, but maybe that exists too elsewhere. I don't know how people whose name has been given to them before this list was established is handled however.
An alternative method, which is again culture dependent, is to use virtual governmental IDs for this purpose. Whether this is viable in practice I don't know, never implemented such a thing. But just on the surface, should be.
>So theoretically only (given) names that are on that list can occur.
Unless of course immigration is allowed and doesn't involve changing a name.
Not the OP, but immigration often involves changing your name in the way digital systems store and display it. For example, from محمد to Muhammad or from 陳 to Chen. The pronunciation ideally should stay the same, but obviously there's often slight differences. But if the differences are annoying or confusing, someone might choose an entirely different name as well.
Yes but GP said
> Where I live, you can only select from a central, though frequently updated, list of names when naming your child
I was born in such a country too and still have frequent connections there and I can confirm the laws only apply to citizens of said country so indeed immigration creates exceptions to this rule even if they transliterate their name.
I still don't see how any system in the real world can safely assume its users only have names from that list.
Even if you try to imagine a system for a hospital to register newly born babies... What happens if a pregnant tourist is visiting?
For example in Iceland you don't have to name the baby immediately, and the registration times are different for foreign parents.https://www.skra.is/english/people/registration-of-children/...
Of course then you may fall foul of classic falsehood 40: People have names.
By rrr_oh_man 2024-11-251:291 reply For today's lucky 10,000: Falsehoods programmers believe about names (https://www.kalzumeus.com/2010/06/17/falsehoods-programmers-...)
By Skeime 2024-11-258:48 For today's lucky 10,000: Ten Thousand (https://xkcd.com/1053/)
By perching_aix 2024-11-2422:39 With plenty of attitude of course :)
I've only ever interacted with freeform textfields when inputting my name, so most regular systems clearly don't dare to attempt this.
But if somebody was dead set on only serving local customers or having only local personnel, I can definitely imagine someone being brave(?) enough.
By onionisafruit 2024-11-256:36 The name a system knows you as doesn’t need to correspond to your legal name or what you are called by others.
By tomtomtom777 2024-11-2423:403 reply This assumes every resident is born and registered in said country which is a silly assumption. Surely, any service only catered only to "naturally born citizen" is discriminatory and illegal?
By lmm 2024-11-251:18 > Surely, any service only catered only to "naturally born citizen" is discriminatory and illegal?
No, that's also a question that is culturally dependent. In some contexts it's normal and expected.
By marcus_holmes 2024-11-250:59 I read that Iceland asks people to change their names if they naturalise there (because of the -sson or -dottir surname suffix).
But your point stands - not everyone in the system will follow this pattern.
By perching_aix 2024-11-259:26 Obviously, foreigners just living or visiting here will not have our strictly local names (thinking otherwise is what would be "silly"). Locals (people with my nationality, so either natural or naturalized citizens) will (*).
(*) I read up on it though, and it seems like exceptions can be requested and allowed, if it's "well supported". Kinda sours the whole thing unfortunately.
> is discriminatory and illegal?
Checked this too (well, using Copilot), it does appear to be illegal in most contexts, although not all.
But then, why would you want to perform name verification specific to my culture? One example I can think of is limiting abuse on social media sites for example. I vaguely recall Facebook being required to do such a thing like a decade ago (although they definitely did not go about it this way clearly).
Yes, it is essential when you want to avoid doing business with customers who have invalid names.
You joke, but when a customer wants to give your company their money, it is our duty as developers to make sure their names are valid. That is so business critical!
By Muromec 2024-11-2421:01 It's not just business necrssary, it's also mandatory to do rigjt under gdpr
By xtiansimon 2024-11-2414:49 In legitimate retail, take the money, has always been the motto.
That said, recently I learned about monetary policy in North Korea and sanctions on the import of luxury goods.
Why Nations Fail (2012) by Daron Acemoglu and James Robinson
https://en.wikipedia.org/wiki/United_Nations_Security_Counci...
What are “invalid names” in this context? Because, depending on the country the person was born in, a name can be literally anything, so I’m not sure what an invalid name looks like (unless you allow an `eval` of sorts).
The non-joke answer for Europe is extened Latin, dashes, spaces and apostrophe sign, separated into two (or three) distinct ordered fields. Just because it's written in a different script originally, doesn't mean it will printed only with that on your id in the country of residence or travel document issued at home. My name isn't written in Latin characters and it's fine. I know you can't even try to pronounce them, so I have it spelled out in above mentioned Latin script.
By throw_a_grenade 2024-11-2516:381 reply Non-joke answer for Europe is at least Latin, Greek or Cyrillic (български is already one of the official EU languages!). No reason to treat them differently, just don't allow for mixing them so you won't get homoglyphs. EURid (.eu-NIC) gets it mostly right I believe.
By account42 2024-11-2616:01 The non-theoretical answer for Europe is just Latin because the names need to eventually be read by people who don't know Greek or Cyrillic.
By dgoldstein0 2024-11-2420:38 Obligatory xkcd https://xkcd.com/327/
What if your customer is the artist formerly known as Prince or even X Æ A-12 Musk?
By rsynnott 2024-11-2514:07 Prince is still mostly screwed, even without spurious validation; Unicode doesn't allow personal symbols. Some discussion here: https://www.unicode.org/mail-arch/unicode-ml/Archives-Old/UM...
Prince: "Get over yourself and just use your given name." (Shockingly, his given name actually is Prince; I first thought it was only a stage name)
Musk: Tell Elon to get over his narcissism enough to not use his children as his own vanity projects. This isn't just an Elon problem, many people treat children as vanity projects to fuel their own narcissism. That's not what children are for. Give him a proper name. (and then proceed to enter "X Æ A-12" into your database, it's just text...)
By jandrese 2024-11-2514:24 Sure it is just text, but the context is someone who wrote a isValidHumanName() function.
By ValentinA23 2024-11-2415:243 reply Don't validate names, use transliteration to make them safe for postal services (or whatever). In SQL this is COLLATE, in the command line you can use uconv:
>echo "'Lódź'" | uconv -f "UTF-8" -t "UTF-8" -x "Latin-ASCII"
>'Lodz'
By poincaredisk 2024-11-2421:02 If I ever make my own customer facing product with registration, I'm rejecting names with 'v', 'x' and 'q'. After all, these characters don't exist in my language, and foreign people can always transliterate them to 'w', 'ks' or 'ku' if they have names with weird characters.
The name of the city has the L with stroke (pronounced as a W), so it’s Łódź.
By poincaredisk 2024-11-2421:052 reply And the transliteration in this case is so far from the original that it's barely recognisable for me (three out of four characters are different and as a native I perceive Ł as a fully separate character, not as a funny variation of L)
The fact that it's pronounced as Вуч and not Лодж still triggers me.
By pavel_lishin 2024-11-2421:552 reply I just looked up the Russian wikipedia entry for it, and it's spelled "Лодзь", but it sounds like it's pronounced "Вуджь", and this fact irritates the hell out of me.
Why would it be transliterated with an Л? And an О? And a з? None of this makes sense.
By cyberax 2024-11-252:36 > Why would it be transliterated with an Л?
Because it _used_ to be pronounced this way in Polish! "Ł" pronounced as "L" sounds "theatrical" these days, but it was more common in the past.
It's a general pattern of what russia does to names of places and people, which is aggressively imposing their own cultural paradigm (which follows the more general general pattern). You can look up your civil code provisions around names and ask a question or two of what historical problem they attempt to solve.
It's not a Russian-specific thing by any stretch.
This happens all the time when names and loanwords get dragged across linguistic boundaries. Sometimes it results from an attempt to "simplify" the respective spelling and/or sounds (by mapping them into tokens more familiar in the local environment); sometimes there's a more complex process behind it; and other times it just happens for various obscure historical reasons.
And the mangling/degradation definitely happens in both directions: hence Москва → Moscow, Paris → Париж.
In this particular case, it may have been an attempt to transliterate from the original Polish name (Łódź), more "canonically" into Russian. Based on the idea that the Polish Ł (which sounds much closer to an English "w" than to a Russian "в") is logically closer to the Russian "Л" (as this actually makes sense in terms of how the two sounds are formed). And accordingly for the other weird-seeming mappings. Then again it could have just ended up that way for obscure etymological reasons.
Either way, how one can be "irritated as hell" over any of this (other than in some jocular or metaphorical sense) is another matter altogether, which I admit is a bit past me.
Correction - it's nothing osbcure at all, but apparently a matter of the shift that accord broadly with the L sound in Polish a few centuries ago (whereby it became "dark" and velarized), affecting a great many other words and names (like słowo, mały, etc). While in parts east and south the "clear" L sound was preserved.
By int_19h 2024-11-2518:43 Velarized L is a common phoneme in Slavic languages, inherited from their common ancestor. What makes Polish somewhat unusual is that the pronunciation of velarized L eventually shifted to /w/ pretty much everywhere (a similar process happened in Ukrainian and Belarusian, but only in some contexts).
By int_19h 2024-11-2518:47 Adapting foreign names to phonotactics and/or spelling practices of one's native language is a common practice throughout the world. The city's name is spelled Lodz in Spanish, for example.
By cyberax 2024-11-252:37 Wait until you hear what Chinese or Japanese languages do with loanwords...
By notanote 2024-11-2421:29 L with stroke is the english name for it according to wikipedia by the way, not my choice of naming. The transliterated version is not great, considering how far removed from the proper pronunciation it is, but I’m sort of used to it. The almost correct one above was jarring enough that I wanted to point it out.
By ajsnigrutin 2024-11-2421:263 reply Yeah, that'll work great..
https://en.wikipedia.org/wiki/%C4%8Celje
echo "Čelje" | uconv -f "UTF-8" -t "UTF-8" -x "Latin-ASCII"
> "Celje"
https://en.wikipedia.org/wiki/Celje
(i mean... we do have postal numbers just for problems like this, but both Štefan and Stefan are not-so-uncommon male names over here, so are Jozef and Jožef, etc.)
If you're dealing with a bad API that only takes ASCII, "Celje" is usually better than "ÄŒelje" or "蒌elje".
If you have control over the encoding on the input side and on the output side, you should just use UTF-8 or something comparable. If you don't, you have to try to get something useful on the output side.
By ajsnigrutin 2024-11-2517:26 This depends.
Everyone over here would know that "ÄŒelje" (?elje) is either čelje, šelje or želje. Maybe even đelje or ćelje if it's a name or something else. So, special attention would be taken to 'decypher' what was meant here.
But if you see "Celje", you assume it's actually Celje (a much larger city than Čelje) and not one of those variants above. And noone will bother with figuring out if part of a letter is missing, it'll just get sent to Celje.
Most places where telling Štefan from Stefan is a problem use postal numbers for people too, or/and ask for your DOB.
By ajsnigrutin 2024-11-2422:171 reply I don't have a problem from differentiatin Štefan from Stefan, 's' and 'š' sound pretty different to everyone around here. But if someone runs that script above and transliterates "š" to "s" it can cause confusion.
And no, we don't use "postal numbers for humans".
By Muromec 2024-11-2423:34 >And no, we don't use "postal numbers for humans".
An email, a phone number, a tax or social security number, demographic identifier, billing/contract number or combination of them.
All of those will help you tell Stefan from Štefan in the most practical situations.
>But if someone runs that script above and transliterates "š" to "s" it can cause confusion.
It's not nice, it will certainly make Štefan unhappy, but it's not like you will debit the money from the wrong account or deliver to a different address or contact the wrong customer because of that.
By account42 2024-11-2616:09 So? Names are not unique to begin with.
Yes, it's easy
(With the caveat that a name might not be representable in Unicode, in which case I dunno. Use an image format?)bool ValidateName(string name) => true;That only works if you’re concatenating the first and last name fields. Some people have no last name and thus would fail this validation if the system had fields for first and last name.
Honestly I wish we could just abolish first and last name fields and replace them with a single free text name field since there's so many edge cases where first and last is an oversimplification that leads to errors. Unfortunately we have to interact with external systems that themselves insist on first and last name fields, and pushing it to the user to decide which is part of what name is wrong less often than string.split, so we're forced to become part of the problem.
By caseyohara 2024-11-2421:221 reply I did this in the product where I work. We operate globally so having separate first and last name fields was making less sense. So I merged them into a singular full name field.
The first and only people to complain about that change were our product marketing team, because now they couldn’t “personalize” emails like `Hi <firstname>,`. I had the hardest time convincing them that while the concept of first and last names are common in the west, it is not a universal concept.
So as a compromise, we added a “Preferred Name” field where users can enter their first name or whatever name they prefer to be called. Still better than separate first and last name fields.
I tried this too, and a customer angrily asked why they can't sort their report alphabetically by last name. Sigh.
By caseyohara 2024-11-2523:12 Just split the full name on the space char and take the last value as the last name. Oh wait, some people have multiple last names.
Split on the space and take everything after the first space as the last name. Oh wait, some people have multiple first names.
Merging names is a one-way door, you can't break them apart programmatically. Knowing this, I put a lot of thought into whether it was worth it to merge them.
By arkh 2024-11-259:19 One field?
Like people have only one name... I like the Human Name from the FHIR standard: https://hl7.org/fhir/datatypes.html#HumanName
People can have many names (depending on usage and of "when", think about marriage) and even if each of those human names can handle multiple parts the "text" field is what you should use to represent the name in UIs.
I encourage people to go check the examples the standards gives, especially the Japanese and Scandinavian ones.
It’s not just external systems. In many (most?) places, when sorting by name, you use the family names first, then the given names. So you can’t correctly sort by name unless you split the fields. Having a single field, in this case, is “an oversimplification that leads to errors”.
By roywiggins 2024-11-2519:411 reply Right, but then you have to know which name is the family name, which really could be any of them.
By JimDabell 2024-11-261:04 I’m not sure what you’re trying to get at. The field containing the family name is the one labelled “family name”. You don’t have two fields both labelled “name”; there’s no ambiguity.
By cluckindan 2024-11-2415:041 reply some people have no name at all
Any notable examples apart from young children and Michael Scott that one time?
By ndsipa_pomu 2024-11-2415:211 reply I've been compiling a list of them:
By dvfjsdhgfv 2024-11-2418:25 You seem to have forgotten quite a few, like
See point 40 and 32-36 on Falsehoods programmers believe about names[1]
[1] https://www.kalzumeus.com/2010/06/17/falsehoods-programmers-...
By from-nibly 2024-11-2415:231 reply I know that this is trying to be helpful but the snark in this list detracts from the problem.
By i80and 2024-11-2421:20 Whether it's healthy or not, programmers tend to love snark, and that snark has kept this list circulating and hopefully educating for a long time to this very day
By chuckadams 2024-11-2422:10 Slim Shady?
Presumably there aren't any people with control characters in their name, for example.
Watch as someone names themselves the bell character, “^G” (ASCII code 7) [1]
When they meet people, they tell them their name is unpronounceable, it’s the sound of a PC speaker from the late 20th century, but you can call them by their preferred nickname “beep”.
In paper and online forms they are probably forced to go by the name “BEL”.
Or Derek <wood dropping on desk>
By Polizeiposaune 2024-11-2423:57 The interaction brings to mind Grzegorz Brzęczyszczykiewicz:
https://www.youtube.com/watch?v=AfKZclMWS1U
(from the Polish comedy film "How I Unleashed World War II")
By pavel_lishin 2024-11-2421:59 I thought this was going to be a link to the Key & Peele sketch: https://youtu.be/gODZzSOelss?t=180
By Izkata 2024-11-256:02 It's not exactly a bell, but there are clicks: https://en.wikipedia.org/wiki/Click_consonant
https://www.reddit.com/r/Damnthatsinteresting/comments/1614k...
By RobotToaster 2024-11-258:21 I can finally change my name to something that represents my personality: ^G^C
By ValentinA23 2024-11-2415:302 reply คุณ สมชาย
This name, "คุณสมชาย" (Khun Somchai, a common Thai name), appears normal but has a Zero Width Space (U+200B) between "คุณ" (Khun, a title like Mr./Ms.) and "สมชาย" (Somchai, a given name).
In scripts like Thai, Chinese, and Arabic, where words are written without spaces, invisible characters can be inserted to signal word boundaries or provide a hint to text processing systems.
By Saigonautica 2024-11-254:11 The reminds me of a few Thai colleagues who ended up with a legal first name of "Mr." (period included), probably as a result of this.
Buying them plane tickets to attend meetings and so on proved fairly difficult.
By pwdisswordfishz 2024-11-2415:36 But C0 and C1 control codes are out, probably.
By lmm 2024-11-251:50 > Presumably there aren't any people with control characters in their name, for example.
Of course there are. If you commit to supporting everything anyone wants to do, people will naturally test the boundaries.
The biggest fallacy programmers believe about names is that getting name support 100% right matters. Real engineers build something that works well enough for enough of the population and ship it, and if that's not US-ASCII only then it's usually pretty close to it.
By pwdisswordfishz 2024-11-2415:331 reply Or unpaired surrogates. Or unassigned code points. Or fullwidth characters. Or "mathematical bold" characters. Though the latter two should be probably solved with NFKC normalization instead.
By chrismorgan 2024-11-252:321 reply > Or unpaired surrogates.
That’s just an invalid Unicode string, then. Unicode strings are sequences of Unicode scalar values, not code points.
> unassigned code points
Ah, the tyranny of Unicode version support. I was going to suggest that it could be reasonable to check all code points are assigned at data ingress time, but then you urgently need to make sure that your ingress system always supports the latest version of Unicode. As soon as some part of the system goes depending on old Unicode tables, some data processing may go wrong!
How about Private Use Area? You could surely reasonably forbid that!
> fullwidth characters
I’m not so comfortable with halfwidth/fullwidth distinctions, but couldn’t fullwidth characters be completely legitimate?
(Yes, I’m happy to call mathematical bold, fraktur, &c. illegitimate for such purposes.)
> solved with NFKC normalization
I’d be very leery of doing this on storage; compatibility normalisations are fine for equivalence testing, things like search and such, but they are lossy, and I’m not confident that the lossiness won’t affect legitimate names. I don’t have anything specific in mind, just a general apprehension.
By account42 2024-11-2616:26 > > Or unpaired surrogates.
> That’s just an invalid Unicode string, then. Unicode strings are sequences of Unicode scalar values, not code points.
Because surrogates were retrofitted onto UCS-2 to make it into UTF-8, they are both code units and (reserved) code points.
It's safe to reject Cc, Cn, and Cs. You should probably reject Co as well, even though elves can't input their names if you do that.
Don't reject Cf. That's asking for trouble.
By chrismorgan 2024-11-253:03 Explanation for those not accustomed, based on <https://www.unicode.org/reports/tr44/#GC_Values_Table> (with my own commentary):
Cc: Control, a C0 or C1 control code. (Definitely safe to reject.)
Cn: Unassigned, a reserved unassigned code point or a noncharacter. (Safe to reject if you keep up to date with Unicode versions; but if you don’t stay up to date, you risk blocking legitimate characters defined more recently, for better or for worse. The fixed set of 66 noncharacters are definitely safe to reject.)
Cs: Surrogate, a surrogate code point. (I’d put it stronger: you must reject these, it’s wrong not to.)
Co: Private_Use, a private-use character. (About elf names, I’m guessing samatman is referring to Tolkien’s Tengwar writing system, as assigned in the ConScript Unicode Registry to U+E000–U+E07F. There has long been a concrete proposal for inclusion in Unicode’s Supplementary Multilingual Plane <https://www.unicode.org/roadmaps/smp/>, from time to time it gets bumped along, and since fairly recently the linked spec document is actually on unicode.org, not sure if that means something.)
Cf: Format, a format control character. (See the list at <https://util.unicode.org/UnicodeJsps/list-unicodeset.jsp?a=[...>. You could reject a large number of these, but some are required by some scripts, such as ZERO-WIDTH NON-JOINER in Indic scripts.)
By kijin 2024-11-2415:16 Challenge accepted, I'll try to put a backspace and a null byte in my firstborn's name. Hope I don't get swatted for crashing the government servers.
By eyelidlessness 2024-11-2415:19 That sounds like a reasonable assumption, but probably not strictly correct.
By baruchel 2024-11-2420:41 Mandatory reference: https://xkcd.com/327/
By michaelt 2024-11-259:31 There are of course some people who'll point you to a blog post saying no validation is possible.
However, for every 1 user you get whose full legal name is bob@example.com you'll get 100 users who put their e-mail into the name field by accident
And for every 1 user who wants to be called e.e. cummings you'll get 100 who just didn't reach for the shift key and who actually prefer E.E. Cummings. But you'll also get 100 McCarthys and O'Connors and al-Rahmans who don't need their "wrong" capitalisation "fixed" thank you very much.
Certainly, I think you can quite reasonably say a name should be comprised of between 2 and 75 characters, with no newlines, nulls, emojis, leading or trailing spaces, invalid unicode code points, or angle brackets.
By crazygringo 2024-11-2414:3610 reply If you just use the {Alphabetic} Unicode character class (100K code points), together with a space, hyphen, and maybe comma, that might get you close. It includes diacritics.
I'm curious if anyone can think of any other non-alphabetic characters used in legal names around the world, in other scripts?
I wondered about numbers, but the most famous example of that has been overturned:
"Originally named X Æ A-12, the child (whom they call X) had to have his name officially changed to X Æ A-Xii in order to align with California laws regarding birth certificates."
(Of course I'm not saying you should do this. It is fun to wonder though.)
> I'm curious if anyone can think of any other non-alphabetic characters used in legal names around the world, in other scripts?
Latin characters are NOT allowed in official names for Japanese citizens. It must be written in Japanese characters only.
For foreigners living in Japan it's quite frequent to end up in a situation where their official name in Latin does not pass the validation rules of many forms online. Issues like forbidden characters, or because it's too long since Japanese names (family name + first name) are typically only 4 characters long.
Also, when you get a visa to Japan, you have to bend and disform the pronunciation of your name to make it fit into the (limited) Japanese syllabary.
Funnily, they even had to register a whole new unicode range at some point, because old administrative documents sometimes contains characters that have been deprecated more than a century ago.
By crazygringo 2024-11-2415:302 reply Very interesting about Japan!
To be clear, I wasn't thinking about within a specific country though.
More like, what is the set of all characters that are allowed in legal names across the world?
You know, to eliminate things like emoji, mathematical symbols, and so forth.
Ah, I see.
I don't know, but I would bet that the sum of all corner cases and exceptions in the world would make it pretty hard to confidently eliminate any "obvious" characters.
From a technical standpoint, unicode emojis are probably safe to exclude, but on the other hand, some scripts like Chinese characters are fundamentally pictograms, which is semantically not so different than an emoji.
Maybe after centuries of evolution we will end up with a legit universal language based on emojis, and people named with it.
By crazygringo 2024-11-2417:03 Chinese characters are nothing like emoji. They are more akin to syllables. There is no semantic similarity to emoji at all, even if they were originally derived from pictorial representations.
And they belong to the {Alphabetic} Unicode class.
I'm mostly curious if Unicode character classes have already done all the hard work.
By account42 2024-11-2616:29 I imagine at least Sealand has relatively lax (or at least informal) restrictions.
By bloak 2024-11-2422:01 Yes, though O’Brien is Ó Briain in Irish, according to Wikipedia. I think the apostrophe in Irish names was added by English speakers, perhaps by analogy with "o'clock", perhaps to avoid writing something that would look like an initial.
There are also English names of Norman origin that contain an apostrophe, though the only example I can think of immediately is the fictional d'Urberville.
> I'm curious if anyone can think of any other non-alphabetic characters used in legal names around the world, in other scripts?
Some Japanese names are written with Japanese characters that do not have Unicode codepoints.
(The Unicode consortium claims that these characters are somehow "really" Chinese characters just written in a different font; holders of those names tend to disagree, but somehow the programmer community that would riot if someone suggested that people with ø in their name shouldn't care when it's written as o accepts that kind of thing when it comes to Japanese).
By crazygringo 2024-11-2512:311 reply Ha, well I don't think we need to worry about validating characters if they can't be typed in a text box in the first place. ;)
But very interesting thanks!
By lmm 2024-11-291:07 > Ha, well I don't think we need to worry about validating characters if they can't be typed in a text box in the first place. ;)
They are frequently typed in text boxes, any software seriously targeting Japan supports them, you just have to use Shift-JIS (or EUC-JP). So your codebase needs to actually support text encodings rather than just blindly assuming everything is UTF-8.
By nicoburns 2024-11-2414:48 Apostrophe is common in surnames in parts of the world.
דויד Smith (concatenated) will have an LTR control character in the middle
By crazygringo 2024-11-2417:051 reply Oh that's interesting.
Is that a thing? I've never known of anyone whose legal name used two alphabets that didn't have any overlap in letters at all -- two completely different scripts.
Would a birth certificate allow that? Wouldn't you be expected to transliterate one of them?
By golergka 2024-11-2515:45 I haven't known anyone like that either, but I can imagine how the same person would have name in Hebrew in some Israeli IT system and name in English somewhere else and then have a third system to unexpectedly combine them in some weird way.
There’s this individual’s name which involves a clock sound: Nǃxau ǂToma[1]
[1] https://en.m.wikipedia.org/wiki/N%25C7%2583xau_%C7%82Toma
By crazygringo 2024-11-2415:36 Click characters are part of {Alphabetic}!
https://en.wikipedia.org/wiki/Click_consonant
By kens 2024-11-2421:13 > There’s this individual’s name which involves a clock sound: Nǃxau ǂToma
I was extremely puzzled until I realized you meant a click sound, not a clock sound. Adding to my confusion, the vintage IBM 1401 computer uses ǂ as a record mark character.
By GolDDranks 2024-11-2415:031 reply What if one's name is not in alphabetic script? Let's say, "鈴木涼太".
By crazygringo 2024-11-2415:26 That's part of {Alphabetic} in Unicode. It validates.
By Mordisquitos 2024-11-250:081 reply > I'm curious if anyone can think of any other non-alphabetic characters used in legal names around the world, in other scripts?
The Catalan name Gal·la is growing in popularity, with currently 1515 women in the census having it as a first name in Spain with an average age of 10.4 years old: https://ine.es/widgets/nombApell/nombApell.shtml
By enriquto 2024-11-2511:26 beautiful map of the Catalan Countries when you search for that name here
By jlhwung 2024-11-2511:01 Comma or apostrophe, like in d'Alembert ?
(And I have 3 in my keyboard, I'm not sure everyone is using the same one.)
By ahazred8ta 2024-11-2420:11 Mrs. Keihanaikukauakahihuliheekahaunaele only had a string length problem, but there are people with a Hawaiian ʻokina in their names. U+02BB
If you're prohibiting valid letters to protect your database because you didn't parametrize your queries, you're solving the problem from the wrong end
By account42 2024-11-2616:46 This is all well and good until the company looses real money becaus some other system you are interfacing with got compromised because of your attitude and fingers start being pointed. Defense in depth is a thing.
By gmuslera 2024-11-2521:12 There might be more than just 2 ends. And some of them may not be fixable by you.
It is if you first provide a complete specification of a “name”. Then you can validate if a name is compliant with your specification.
By Muromec 2024-11-2421:14 It's super easy actually. Name consists of three parts -- Family Name, Given Name and Patronymic, spelled using Ukrainian Cyrillic. You can have a dash in the Family name and apostrophe is part of Cyrillic for this purposes, but no spaces in any of the three. If are unfortunate enough to not use Cyrillic (of our variety) or Patronymics in the country of your origin (why didn't you stay there, anyway), we will fix it for you, mister Нкріск. If you belong to certain ethnic groups who by their custom insist on not using Patronymics, you can have a free pass, but life will be difficult, as not everybody got the memo really. No, you can not use Matronimyc instead of Patronymic, but give us another 30 years of not having a nuclear war with country name starting with "R" and ending in "full of putin slaves si iiia" and we might see to that.
Unless of course the name is not used for official purposes, in which case you can get away with First-Last combination.
It's really a non issue and the answer is jurisdiction bound. In most of Europe extented Latin set is used in place of Cyrillic (because they don't know better), so my name is transliterated for the purposes of being in the uncivilized realms by my own government. No, I can't just use Л and Я as part of my name anywhere here.
By GrantMoyer 2024-11-2415:10 Valid names are those which terminate when run as Python programs.
By barryrandall 2024-11-2614:18 Anything is possible with enough qualifiers and caveats.
By majkinetor 2024-11-2414:26 Sure it is. Context matters. For example, in clone wars.
By rsynnott 2024-11-2414:27 No, but it doesn’t stop people trying.
I have an 'æ' in my middle name (formally secondary first name because history reasons). Usually I just don't use it, but it's always funny when a payment form instructs me to write my full name exactly as written on my credit card, and then goes on to tell me my name is invalid.
I wonder how many of those packages end up in Vada, Italy. Or Cody, Wyoming. Or Buda, Texas...
I imagine the “Poland” part of the address would narrow it down somewhat.
I got curious if I can get data to answer that, and it seems so.
Based on xlsx from [0], we got the following ??d? localities in Poland:
1 x Bądy, 1 x Brda, 5 x Buda, 120 x Budy, 4 x Dudy, 1 x Dydy, 1 x Gady, 1 x Judy, 1 x Kady, 1 x Kadź, 1 x Łada, 1 x Lady, 4 x Lądy, 2 x Łady, 1 x Lęda, 1 x Lody, 4 x Łódź, 1 x Nida, 1 x Reda, 1 x Redy, 1 x Redz, 74 x Ruda, 8 x Rudy, 12 x Sady, 2 x Zady, 2 x Żydy
Certainly quite a lot to search for a lost package.
[0]: https://dane.gov.pl/pl/dataset/188,wykaz-urzedowych-nazw-mie...
Interesting! However, assuming that ASCII characters are always rendered correctly and never as "?", it seems like the only solution for "??d?" would be one of the four Łódźs?
By schubart 2024-11-2421:36 Sounds like someone is getting ready for Advent of Code!
By ctm92 2024-11-2511:41 Łódź seems to be the only one translating to ??d?, all others have normal ASCII characters in the places 1, 2 and 4
By yreg 2024-11-2422:58 Experienced postal workers most probably know well that ??d? represents a municipality with three non-ascii characters.
By poincaredisk 2024-11-2422:432 reply Interestingly, Lady, Łady and Lądy will end up the same after the usual transliteration.
By ygra 2024-11-2420:46 And the postal code.
By Symbiote 2024-11-2518:40 It goes both ways.
I received a large delivery from Poland recently, and it was addressed to "K?benhavn", with similar mistakes in the street name.
And the packages get there? Don't you put "Łódź (Lodz)" in the city field? Or the postal code takes care of the issue?
By pzduniak 2024-11-2422:32 Yep, postal code does all the work.
By ivanjermakov 2024-11-2423:141 reply Ironically, there are no big rivers in Łódź (anymore)
By pzduniak 2024-11-2514:47 Sorry, I was thirsty.
There were no "big" rivers, ever. More like springs. We have lots of subterranean water, so out of the 18 rivers we have in the city, 16 have their sources here [0]. They were used to power mills in the 19-20th century during the industrialization. Many of the rivers that used to go through the city center flow underground.
I live close to the river Olechówka [1], which flows into a regulated reservoir that used to feed a mill - so the area is called Młynek, "Little Mill" :)
[0] https://podwodnalodz.blogspot.com/2013/09/o-wodzie-po-ktorej... [1] https://i.imgur.com/SIp8CxN.jpeg
As you may be aware, the name field for credit card transactions is rarely verified (perhaps limited to North America, not sure).
Often I’ll create a virtual credit card number and use a fake name, and virtually never have had a transaction declined. Even if they are more aggressively asking for a street address, giving just the house number often works. This isn’t a deep cover but gives a little bit of a anonymity for marketing.
It's for when things go wrong. Same as with wire transfers. Nobody checks it unless there's a dispute.
The thing is though that payment networks do in fact do instant verification and it is interesting what gets verified and when. At gas stations it is very common to ask for a zip code (again US), and this is verified immediately to allow the transaction to proceed. I’ve found that when a street address is asked for there is some verification and often a match on the house number is sufficient. Zip codes are verified almost always, names pretty much never. This likely has something to do with complexities behind “authorized users”.
Funny thing about house numbers: they have their own validation problems. For a while I lived in a building whose house number was of the form 123½ and that was an ongoing source of problems. If it just truncated the ½ that was basically fine (the house at 123 didn't have apartment numbers and the postal workers would deliver it correctly) but validating in online forms (twenty-ish years ago) was a challenge. If they ran any validation at all they'd reject the ½, but it was a crapshoot whether which of "123-1/2" or "123 1/2" would work, or sometimes neither one. The USPS's official recommendation at the time was to enter it as "123 1 2 N Streetname" which usually validated but looked so odd it was my last choice (and some validators rejected the "three numbers" format too).
I don't think I ever tried "123.5", actually.
By crooked-v 2024-11-250:16 Around here, there used to be addresses like "0100 SW Whatever Ave" that were distinct from "100 SW Whatever Ave". And we've still got various places that have, for example, "NW 21st Avenue" and "NW 21st Place" as a simple workaround for a not-entirely-regular street grid optimized for foot navigation.
By kmoser 2024-11-252:56 123 + 0.5?
At American gas stations, if you have a Canadian credit card, you type in 00000 because Canadians don't have ZIP codes.
Are we sure they don't actually validate against a more generic postal code field? Then again some countries have letters in their postcodes (the UK comes to mind), so that might be a problem anyways.
By epcoa 2024-11-257:55 Canada has letters in postal codes. That’s the issue the GP is referring to, since US gas stations invariably just have a simple 5 numeric digit input for “zip” code.
By cruffle_duffle 2024-11-2420:37 There is so many ways to write your address I always assume it it’s just the house number as well. In fact I vaguely remember that being a specific field when interacting with some old payment gateway.
By ahazred8ta 2024-11-2420:161 reply The government of Ireland has many IT systems that cannot handle áccénted letters. #headdesk
I worked for an Irish company that didn't support ' in names. Did get fixed eventually, but sigh...
By cryptonector 2024-11-2423:23 Bobby Tables enters the chat
Still much better when it fails at the first step. I once got myself in a bit of a struggle with Windows 10 by using "ł" as part of Windows username. Amusingly/irritatingly large number of applications, even some of Microsoft's own ones, could not cope with that.
By darkhorn 2024-11-2423:40 For a similar reason many Java applications do not work in Turkish Windowses. The Turkish İi Iı problem.
By Muromec 2024-11-2421:31 "Write your name the way it's spelled in your government issued id" is my favorite. I have three ids issued by two governments and no two match letter by letter.
By chrismorgan 2024-11-252:08 My wife had two given names and no surname. (In fact, before eighth class, she only had one given name.) Lacking a surname is very common in some parts of India. Also some parts of India put surname first, and some last, and the specific meaning and customs vary quite a bit too. Indian passports actually separate given names and family names entirely (meaning you can’t reconstruct the name as it would customarily be written). Her passport has the family name line blank. Indigo writes: “Name should be as per government ID”, and has “First And Middle Name” and “Last Name” fields. Both required, of course. I discovered that if you put “-” in the Last Name field, the booking process falls over several steps later in a “something went wrong, try again later” way; only by inspecting an API response in the dev tools did I determine it was objecting to having “-” in the name. Ugh. Well, I have a traditional western First Middle Last name, and from putting it in things, sometimes it gets written First Middle Last and sometimes Last First Middle, and I’ve received some communications addressed to First, some to Last, and some to Middle (never had that happen before!). It’s a disaster.
Plenty of government things have been digitalised in recent years too, and split name fields tend to have been coded to make both mandatory. It’s… disappointing, given the radical diversity of name construction across India.
Did you actually get banks to print that on your credit card?
I’m impressed, most I know struggle with any kind of non-[A-Z]!
By poizan42 2024-11-2516:40 In Denmark? I don't think they legally are allowed not to print my legal name.
Would be weird if our banks couldn't handle our own alphabet.

{kind=link}