
Claude can now discover, learn, and execute tools dynamically to enable agents that take action in the real world. Here’s how.
The future of AI agents is one where models work seamlessly across hundreds or thousands of tools. An IDE assistant that integrates git operations, file manipulation, package managers, testing frameworks, and deployment pipelines. An operations coordinator that connects Slack, GitHub, Google Drive, Jira, company databases, and dozens of MCP servers simultaneously.
To build effective agents, they need to work with unlimited tool libraries without stuffing every definition into context upfront. Our blog article on using code execution with MCP discussed how tool results and definitions can sometimes consume 50,000+ tokens before an agent reads a request. Agents should discover and load tools on-demand, keeping only what's relevant for the current task.
Agents also need the ability to call tools from code. When using natural language tool calling, each invocation requires a full inference pass, and intermediate results pile up in context whether they're useful or not. Code is a natural fit for orchestration logic, such as loops, conditionals, and data transformations. Agents need the flexibility to choose between code execution and inference based on the task at hand.
Agents also need to learn correct tool usage from examples, not just schema definitions. JSON schemas define what's structurally valid, but can't express usage patterns: when to include optional parameters, which combinations make sense, or what conventions your API expects.
Today, we're releasing three features that make this possible:
- Tool Search Tool, which allows Claude to use search tools to access thousands of tools without consuming its context window
- Programmatic Tool Calling, which allows Claude to invoke tools in a code execution environment reducing the impact on the model’s context window
- Tool Use Examples, which provides a universal standard for demonstrating how to effectively use a given tool
In internal testing, we’ve found these features have helped us build things that wouldn’t have been possible with conventional tool use patterns. For example, Claude for Excel uses Programmatic Tool Calling to read and modify spreadsheets with thousands of rows without overloading the model’s context window.
Based on our experience, we believe these features open up new possibilities for what you can build with Claude.
Tool Search Tool
The challenge
MCP tool definitions provide important context, but as more servers connect, those tokens can add up. Consider a five-server setup:
- GitHub: 35 tools (~26K tokens)
- Slack: 11 tools (~21K tokens)
- Sentry: 5 tools (~3K tokens)
- Grafana: 5 tools (~3K tokens)
- Splunk: 2 tools (~2K tokens)
That's 58 tools consuming approximately 55K tokens before the conversation even starts. Add more servers like Jira (which alone uses ~17K tokens) and you're quickly approaching 100K+ token overhead. At Anthropic, we've seen tool definitions consume 134K tokens before optimization.
But token cost isn't the only issue. The most common failures are wrong tool selection and incorrect parameters, especially when tools have similar names like notification-send-user vs. notification-send-channel.
Our solution
Instead of loading all tool definitions upfront, the Tool Search Tool discovers tools on-demand. Claude only sees the tools it actually needs for the current task.
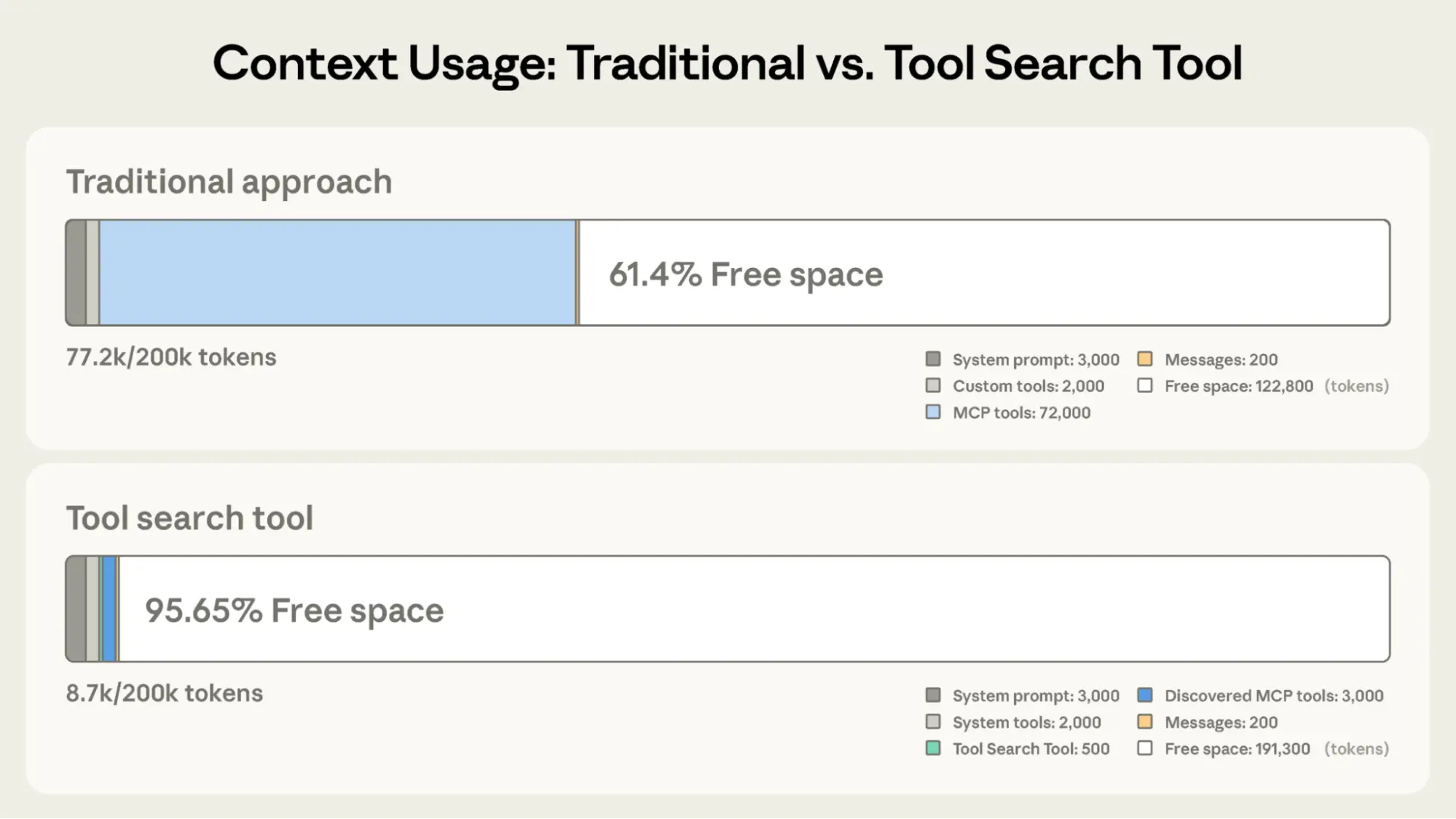
Traditional approach:
- All tool definitions loaded upfront (~72K tokens for 50+ MCP tools)
- Conversation history and system prompt compete for remaining space
- Total context consumption: ~77K tokens before any work begins
With the Tool Search Tool:
- Only the Tool Search Tool loaded upfront (~500 tokens)
- Tools discovered on-demand as needed (3-5 relevant tools, ~3K tokens)
- Total context consumption: ~8.7K tokens, preserving 95% of context window
This represents an 85% reduction in token usage while maintaining access to your full tool library. Internal testing showed significant accuracy improvements on MCP evaluations when working with large tool libraries. Opus 4 improved from 49% to 74%, and Opus 4.5 improved from 79.5% to 88.1% with Tool Search Tool enabled.
How the Tool Search Tool works
The Tool Search Tool lets Claude dynamically discover tools instead of loading all definitions upfront. You provide all your tool definitions to the API, but mark tools with defer_loading: true to make them discoverable on-demand. Deferred tools aren't loaded into Claude's context initially. Claude only sees the Tool Search Tool itself plus any tools with defer_loading: false (your most critical, frequently-used tools).
When Claude needs specific capabilities, it searches for relevant tools. The Tool Search Tool returns references to matching tools, which get expanded into full definitions in Claude's context.
For example, if Claude needs to interact with GitHub, it searches for "github," and only github.createPullRequest and github.listIssues get loaded—not your other 50+ tools from Slack, Jira, and Google Drive.
This way, Claude has access to your full tool library while only paying the token cost for tools it actually needs.
Implementation:
{
"tools": [
// Include a tool search tool (regex, BM25, or custom)
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
// Mark tools for on-demand discovery
{
"name": "github.createPullRequest",
"description": "Create a pull request",
"input_schema": {...},
"defer_loading": true
}
// ... hundreds more deferred tools with defer_loading: true
]
}
For MCP servers, you can defer loading entire servers while keeping specific high-use tools loaded:
{
"type": "mcp_toolset",
"mcp_server_name": "google-drive",
"default_config": {"defer_loading": true}, # defer loading the entire server
"configs": {
"search_files": {
"defer_loading": false
} // Keep most used tool loaded
}
}The Claude Developer Platform provides regex-based and BM25-based search tools out of the box, but you can also implement custom search tools using embeddings or other strategies.
When to use the Tool Search Tool
Like any architectural decision, enabling the Tool Search Tool involves trade-offs. The feature adds a search step before tool invocation, so it delivers the best ROI when the context savings and accuracy improvements outweigh additional latency.
Use it when:
- Tool definitions consuming >10K tokens
- Experiencing tool selection accuracy issues
- Building MCP-powered systems with multiple servers
- 10+ tools available
Less beneficial when:
- Small tool library (<10 tools)
- All tools used frequently in every session
- Tool definitions are compact
Programmatic Tool Calling
The challenge
Traditional tool calling creates two fundamental problems as workflows become more complex:
- Context pollution from intermediate results: When Claude analyzes a 10MB log file for error patterns, the entire file enters its context window, even though Claude only needs a summary of error frequencies. When fetching customer data across multiple tables, every record accumulates in context regardless of relevance. These intermediate results consume massive token budgets and can push important information out of the context window entirely.
- Inference overhead and manual synthesis: Each tool call requires a full model inference pass. After receiving results, Claude must "eyeball" the data to extract relevant information, reason about how pieces fit together, and decide what to do next—all through natural language processing. A five tool workflow means five inference passes plus Claude parsing each result, comparing values, and synthesizing conclusions. This is both slow and error-prone.
Our solution
Programmatic Tool Calling enables Claude to orchestrate tools through code rather than through individual API round-trips. Instead of Claude requesting tools one at a time with each result being returned to its context, Claude writes code that calls multiple tools, processes their outputs, and controls what information actually enters its context window.
Claude excels at writing code and by letting it express orchestration logic in Python rather than through natural language tool invocations, you get more reliable, precise control flow. Loops, conditionals, data transformations, and error handling are all explicit in code rather than implicit in Claude's reasoning.
Example: Budget compliance check
Consider a common business task: "Which team members exceeded their Q3 travel budget?"
You have three tools available:
get_team_members(department)- Returns team member list with IDs and levelsget_expenses(user_id, quarter)- Returns expense line items for a userget_budget_by_level(level)- Returns budget limits for an employee level
Traditional approach:
- Fetch team members → 20 people
- For each person, fetch their Q3 expenses → 20 tool calls, each returning 50-100 line items (flights, hotels, meals, receipts)
- Fetch budget limits by employee level
- All of this enters Claude's context: 2,000+ expense line items (50 KB+)
- Claude manually sums each person's expenses, looks up their budget, compares expenses against budget limits
- More round-trips to the model, significant context consumption
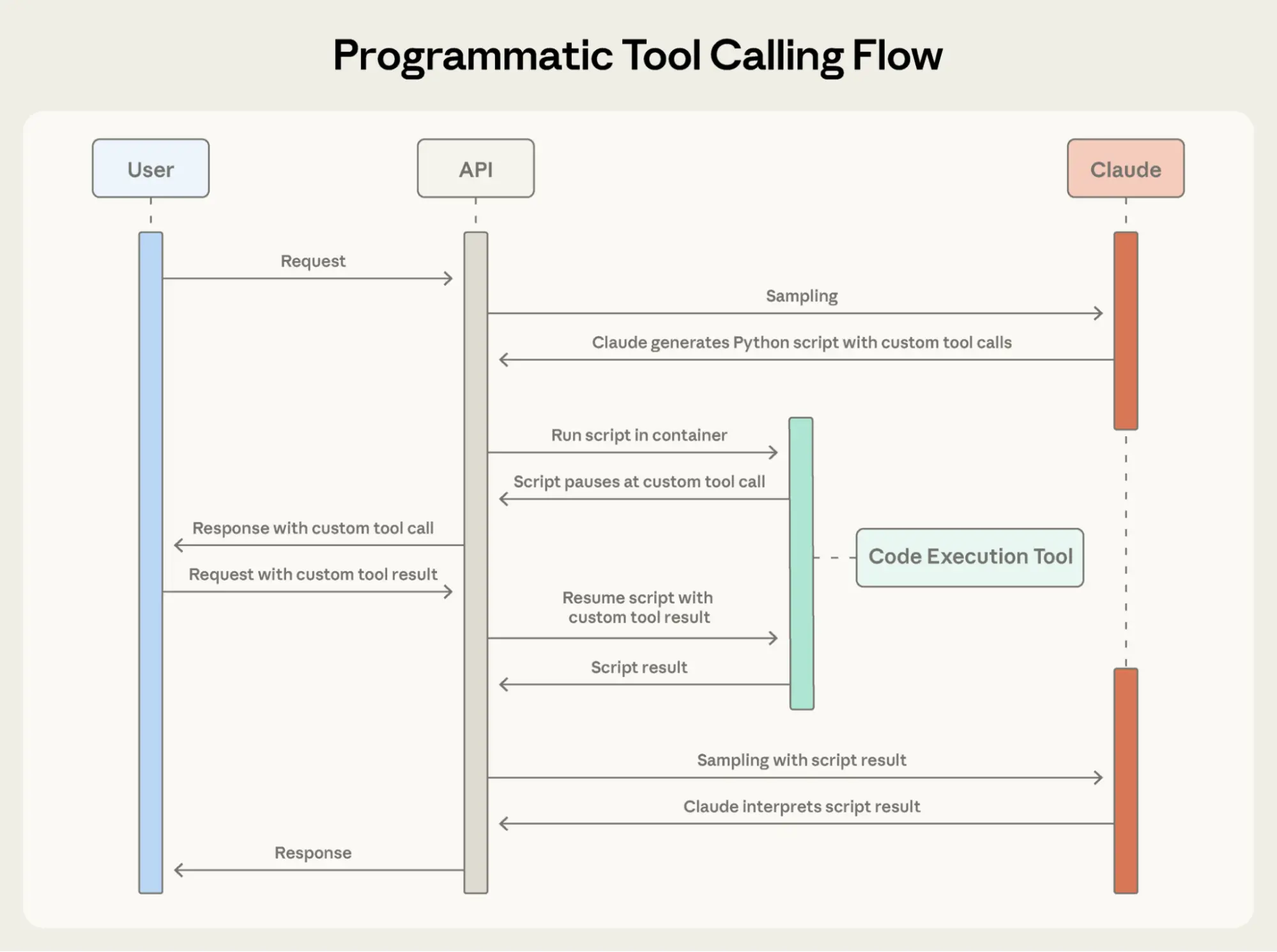
With Programmatic Tool Calling:
Instead of each tool result returning to Claude, Claude writes a Python script that orchestrates the entire workflow. The script runs in the Code Execution tool (a sandboxed environment), pausing when it needs results from your tools. When you return tool results via the API, they're processed by the script rather than consumed by the model. The script continues executing, and Claude only sees the final output.
Here's what Claude's orchestration code looks like for the budget compliance task:
team = await get_team_members("engineering")
# Fetch budgets for each unique level
levels = list(set(m["level"] for m in team))
budget_results = await asyncio.gather(*[
get_budget_by_level(level) for level in levels
])
# Create a lookup dictionary: {"junior": budget1, "senior": budget2, ...}
budgets = {level: budget for level, budget in zip(levels, budget_results)}
# Fetch all expenses in parallel
expenses = await asyncio.gather(*[
get_expenses(m["id"], "Q3") for m in team
])
# Find employees who exceeded their travel budget
exceeded = []
for member, exp in zip(team, expenses):
budget = budgets[member["level"]]
total = sum(e["amount"] for e in exp)
if total > budget["travel_limit"]:
exceeded.append({
"name": member["name"],
"spent": total,
"limit": budget["travel_limit"]
})
print(json.dumps(exceeded))Claude's context receives only the final result: the two to three people who exceeded their budget. The 2,000+ line items, the intermediate sums, and the budget lookups do not affect Claude’s context, reducing consumption from 200KB of raw expense data to just 1KB of results.
The efficiency gains are substantial:
- Token savings: By keeping intermediate results out of Claude's context, PTC dramatically reduces token consumption. Average usage dropped from 43,588 to 27,297 tokens, a 37% reduction on complex research tasks.
- Reduced latency: Each API round-trip requires model inference (hundreds of milliseconds to seconds). When Claude orchestrates 20+ tool calls in a single code block, you eliminate 19+ inference passes. The API handles tool execution without returning to the model each time.
- Improved accuracy: By writing explicit orchestration logic, Claude makes fewer errors than when juggling multiple tool results in natural language. Internal knowledge retrieval improved from 25.6% to 28.5%; GIA benchmarks from 46.5% to 51.2%.
Production workflows involve messy data, conditional logic, and operations that need to scale. Programmatic Tool Calling lets Claude handle that complexity programmatically while keeping its focus on actionable results rather than raw data processing.
How Programmatic Tool Calling works
Add code_execution to tools, and set allowed_callers to opt-in tools for programmatic execution:
{
"tools": [
{
"type": "code_execution_20250825",
"name": "code_execution"
},
{
"name": "get_team_members",
"description": "Get all members of a department...",
"input_schema": {...},
"allowed_callers": ["code_execution_20250825"] # opt-in to programmatic tool calling
},
{
"name": "get_expenses",
...
},
{
"name": "get_budget_by_level",
...
}
]
}The API converts these tool definitions into Python functions that Claude can call.
2. Claude writes orchestration code
Instead of requesting tools one at a time, Claude generates Python code:
{
"type": "server_tool_use",
"id": "srvtoolu_abc",
"name": "code_execution",
"input": {
"code": "team = get_team_members('engineering')\n..." # the code example above
}
}3. Tools execute without hitting Claude's context
When the code calls get_expenses(), you receive a tool request with a caller field:
{
"type": "tool_use",
"id": "toolu_xyz",
"name": "get_expenses",
"input": {"user_id": "emp_123", "quarter": "Q3"},
"caller": {
"type": "code_execution_20250825",
"tool_id": "srvtoolu_abc"
}
}You provide the result, which is processed in the Code Execution environment rather than Claude's context. This request-response cycle repeats for each tool call in the code.
4. Only final output enters context
When the code finishes running, only the results of the code are returned to Claude:
{
"type": "code_execution_tool_result",
"tool_use_id": "srvtoolu_abc",
"content": {
"stdout": "[{\"name\": \"Alice\", \"spent\": 12500, \"limit\": 10000}...]"
}
}This is all Claude sees, not the 2000+ expense line items processed along the way.
When to use Programmatic Tool Calling
Programmatic Tool Calling adds a code execution step to your workflow. This extra overhead pays off when the token savings, latency improvements, and accuracy gains are substantial.
Most beneficial when:
- Processing large datasets where you only need aggregates or summaries
- Running multi-step workflows with three or more dependent tool calls
- Filtering, sorting, or transforming tool results before Claude sees them
- Handling tasks where intermediate data shouldn't influence Claude's reasoning
- Running parallel operations across many items (checking 50 endpoints, for example)
Less beneficial when:
- Making simple single-tool invocations
- Working on tasks where Claude should see and reason about all intermediate results
- Running quick lookups with small responses
Tool Use Examples
The challenge
JSON Schema excels at defining structure–types, required fields, allowed enums–but it can't express usage patterns: when to include optional parameters, which combinations make sense, or what conventions your API expects.
Consider a support ticket API:
{
"name": "create_ticket",
"input_schema": {
"properties": {
"title": {"type": "string"},
"priority": {"enum": ["low", "medium", "high", "critical"]},
"labels": {"type": "array", "items": {"type": "string"}},
"reporter": {
"type": "object",
"properties": {
"id": {"type": "string"},
"name": {"type": "string"},
"contact": {
"type": "object",
"properties": {
"email": {"type": "string"},
"phone": {"type": "string"}
}
}
}
},
"due_date": {"type": "string"},
"escalation": {
"type": "object",
"properties": {
"level": {"type": "integer"},
"notify_manager": {"type": "boolean"},
"sla_hours": {"type": "integer"}
}
}
},
"required": ["title"]
}
}The schema defines what's valid, but leaves critical questions unanswered:
- Format ambiguity: Should
due_dateuse "2024-11-06", "Nov 6, 2024", or "2024-11-06T00:00:00Z"? - ID conventions: Is
reporter.ida UUID, "USR-12345", or just "12345"? - Nested structure usage: When should Claude populate
reporter.contact? - Parameter correlations: How do
escalation.levelandescalation.sla_hoursrelate to priority?
These ambiguities can lead to malformed tool calls and inconsistent parameter usage.
Our solution
Tool Use Examples let you provide sample tool calls directly in your tool definitions. Instead of relying on schema alone, you show Claude concrete usage patterns:
{
"name": "create_ticket",
"input_schema": { /* same schema as above */ },
"input_examples": [
{
"title": "Login page returns 500 error",
"priority": "critical",
"labels": ["bug", "authentication", "production"],
"reporter": {
"id": "USR-12345",
"name": "Jane Smith",
"contact": {
"email": "jane@acme.com",
"phone": "+1-555-0123"
}
},
"due_date": "2024-11-06",
"escalation": {
"level": 2,
"notify_manager": true,
"sla_hours": 4
}
},
{
"title": "Add dark mode support",
"labels": ["feature-request", "ui"],
"reporter": {
"id": "USR-67890",
"name": "Alex Chen"
}
},
{
"title": "Update API documentation"
}
]
}From these three examples, Claude learns:
- Format conventions: Dates use YYYY-MM-DD, user IDs follow USR-XXXXX, labels use kebab-case
- Nested structure patterns: How to construct the reporter object with its nested contact object
- Optional parameter correlations: Critical bugs have full contact info + escalation with tight SLAs; feature requests have reporter but no contact/escalation; internal tasks have title only
In our own internal testing, tool use examples improved accuracy from 72% to 90% on complex parameter handling.
When to use Tool Use Examples
Tool Use Examples add tokens to your tool definitions, so they’re most valuable when accuracy improvements outweigh the additional cost.
Most beneficial when:
- Complex nested structures where valid JSON doesn't imply correct usage
- Tools with many optional parameters and inclusion patterns matter
- APIs with domain-specific conventions not captured in schemas
- Similar tools where examples clarify which one to use (e.g.,
create_ticketvscreate_incident)
Less beneficial when:
- Simple single-parameter tools with obvious usage
- Standard formats like URLs or emails that Claude already understands
- Validation concerns better handled by JSON Schema constraints
Best practices
Building agents that take real-world actions means handling scale, complexity, and precision simultaneously. These three features work together to solve different bottlenecks in tool use workflows. Here's how to combine them effectively.
Layer features strategically
Not every agent needs to use all three features for a given task. Start with your biggest bottleneck:
- Context bloat from tool definitions → Tool Search Tool
- Large intermediate results polluting context → Programmatic Tool Calling
- Parameter errors and malformed calls → Tool Use Examples
This focused approach lets you address the specific constraint limiting your agent's performance, rather than adding complexity upfront.
Then layer additional features as needed. They're complementary: Tool Search Tool ensures the right tools are found, Programmatic Tool Calling ensures efficient execution, and Tool Use Examples ensure correct invocation.
Set up Tool Search Tool for better discovery
Tool search matches against names and descriptions, so clear, descriptive definitions improve discovery accuracy.
// Good
{
"name": "search_customer_orders",
"description": "Search for customer orders by date range, status, or total amount. Returns order details including items, shipping, and payment info."
}
// Bad
{
"name": "query_db_orders",
"description": "Execute order query"
}Add system prompt guidance so Claude knows what's available:
You have access to tools for Slack messaging, Google Drive file management,
Jira ticket tracking, and GitHub repository operations. Use the tool search
to find specific capabilities.Keep your three to five most-used tools always loaded, defer the rest. This balances immediate access for common operations with on-demand discovery for everything else.
Set up Programmatic Tool Calling for correct execution
Since Claude writes code to parse tool outputs, document return formats clearly. This helps Claude write correct parsing logic:
{
"name": "get_orders",
"description": "Retrieve orders for a customer.
Returns:
List of order objects, each containing:
- id (str): Order identifier
- total (float): Order total in USD
- status (str): One of 'pending', 'shipped', 'delivered'
- items (list): Array of {sku, quantity, price}
- created_at (str): ISO 8601 timestamp"
}See below for opt-in tools that benefit from programmatic orchestration:
- Tools that can run in parallel (independent operations)
- Operations safe to retry (idempotent)
Set up Tool Use Examples for parameter accuracy
Craft examples for behavioral clarity:
- Use realistic data (real city names, plausible prices, not "string" or "value")
- Show variety with minimal, partial, and full specification patterns
- Keep it concise: 1-5 examples per tool
- Focus on ambiguity (only add examples where correct usage isn't obvious from schema)
Getting started
These features are available in beta. To enable them, add the beta header and include the tools you need:
client.beta.messages.create(
betas=["advanced-tool-use-2025-11-20"],
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
tools=[
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
{"type": "code_execution_20250825", "name": "code_execution"},
# Your tools with defer_loading, allowed_callers, and input_examples
]
)For detailed API documentation and SDK examples, see our:
- Documentation and cookbook for Tool Search Tool
- Documentation and cookbook for Programmatic Tool Calling
- Documentation for Tool Use Examples
These features move tool use from simple function calling toward intelligent orchestration. As agents tackle more complex workflows spanning dozens of tools and large datasets, dynamic discovery, efficient execution, and reliable invocation become foundational.
We're excited to see what you build.
Acknowledgements
Written by Bin Wu, with contributions from Adam Jones, Artur Renault, Henry Tay, Jake Noble, Nathan McCandlish, Noah Picard, Sam Jiang, and the Claude Developer Platform team. This work builds on foundational research by Chris Gorgolewski, Daniel Jiang, Jeremy Fox and Mike Lambert. We also drew inspiration from across the AI ecosystem, including Joel Pobar's LLMVM, Cloudflare's Code Mode and Code Execution as MCP. Special thanks to Andy Schumeister, Hamish Kerr, Keir Bradwell, Matt Bleifer and Molly Vorwerck for their support.
Read the original article
Comments
The Programmatic Tool Calling has been an obvious next step for a while. It is clear we are heading towards code as a language for LLMs so defining that language is very important. But I'm not convinced of tool search. Good context engineering leaves the tools you will need so adding a search if you are going to use all of them is just more overhead. What is needed is a more compact tool definition language like, I don't know, every programming language ever in how they define functions. We also need objects (which hopefully Programatic Tool Calling solves or the next version will solve). In the end I want to drop objects into context with exposed methods and it knows the type and what is callable on they type.
Why exactly do we need a new language? The agents I write get access to a subset of the Python SDK (i.e. non-destructive), packages, and custom functions. All this ceremony around tools and pseudo-RPC seems pointless given LLMs are extremely capable of assembling code by themselves.
By never_inline 2025-11-257:13 Does this "non destructive subset of python SDK" exist today, without needing to bring, say, a whole webassembly runtime?
I am hoping something like CEL (with verifiable runtime guarantees) but the syntax being a subset of Python.
By FridgeSeal 2025-11-252:072 reply Woah woah woah, you’re ignoring a whole revenue stream caused by deliberately complicating the ecosystem, and then selling tools and consulting to “make it simpler”!
Think of all the new yachts our mega-rich tech-bros could have by doing this!
By dalemhurley 2025-11-258:42 Tool search is formalising what a lot of teams have been working towards. I had previously called it tool caller, the LLM knew there was tools for domains and then when the domain was mentioned, the tools for the domain would be loaded, this looks a bit smarter.
my VS fork brings all the boys to the yard and they're like it's better than yours, damn right, it's better than yours
By rekttrader 2025-11-256:06 I can teach you, but I’ll have to charge
By checker659 2025-11-253:472 reply This is the most creative comment I've read on HN as of late.
By mirekrusin 2025-11-2423:58 Exactly, instead of this mess, you could just give it something like .d.ts.
Easy to maintain, test etc. - like any other library/code.
You want structure? Just export * as Foo from '@foo/foo' and let it read .d.ts for '@foo/foo' if it needs to.
But wait, it's also good at writing code. Give it write access to it then.
Now it can talk to sql server, grpc, graphql, rest, jsonrpc over websocket, or whatever ie. your usb.
If it needs some tool, it can import or write it itself.
Next realisation may be that jupyter/pluto/mathematica/observable but more book-like ai<->human interaction platform works best for communication itself (too much raw text, I'd take you days to comprehend what it spit out in 5 minutes - better to have summary pictures, interactive charts, whatever).
With voice-to-text because poking at flat squares in all of this feels primitive.
For improved performance you can peer it with other sessions (within your team, or global/public) - surely others solved similar problems to yours where you can grab ready solutions.
It already has ablity to create tool that copies itself and can talk to a copy so it's fair to call this system "skynet".
The latest MCP specifications (2025-06-18+) introduced crucial enhancements like support for Structured Content and the Output Schema.
Smolagents makes use of this and handles tool output as objects (e.g. dict). Is this what you are thinking about?
Details in a blog post here: https://huggingface.co/blog/llchahn/ai-agents-output-schema
By jmward01 2025-11-2422:48 We just need simple language syntax like python and for models to be trained on it (which they already mostly are):
class MyClass(SomeOtherClass):
That is way more compact than the json schema out there. Then you can have 'available objects' listed like: o1 (MyClass), o2 (SomeOtherClass) as the starting context. Combine this with programatic tool calling and there you go. Much much more compact. Binds well to actual code and very flexible. This is the obvious direction things are going. I just wish Anthropic and OpenAI would realize it and define it/train models to it sooner rather than later.def my_func(a:str, b:int) -> int: #Put the description (if needed) in the body for the llm.edit: I should also add that inline response should be part of this too: The model should be able to do ```<code here>``` and keep executing with only blocking calls requiring it to stop generating until the block frees up. so, for instance, the model could ```r = start_task(some task)``` generate other things ```print(r.value())``` (probably with various awaits and the like here but you all get the point).
By ctoth 2025-11-251:39 I'm not sure that we need a new language so much as just primitives from AI gamedev, like behavior trees along with the core agentic loop.
By stingraycharles 2025-11-253:241 reply Reminds me a bit of the problem that GraphQL solves for the frontend, which avoids a lot of round-trips between client and server and enables more processing to be done on the server before returning the result.
By politelemon 2025-11-254:34 And introduce a new set of problems in doing so.
By knowsuchagency 2025-11-251:11 I completely agree. I wrote an implementation of this exact idea a couple weeks ago https://github.com/Orange-County-AI/MCP-DSL
By user3939382 2025-11-253:15 Adding extra layers of abstraction on top of tools we don’t even understand is a sickness.
I'm starting to notice a pattern with these AI assistants.
Scenario: I realize that the recommended way to do something with the available tools is inefficient, so I implement it myself in a much more efficient way.
Then, 2-3 months later, new tools come out to make all my work moot.
I guess it's the price of living on the cutting edge.
By lukan 2025-11-257:44 The frustrating part is, with all the hype it is hard to see, what are really the working ways right now. I refused to go your way to live on the edge and just occasionally used ChatGPT for specific tasks, but I do like the idea to get AI assistants for the old codebases and gave the modern ways a shot just now again, but it still seems messy and I never know if I am simply not doing it right, or if there simply is no right way and sometimes things work and sometimes they don't. I guess I wait some more time, before also invest in building tools, that will be obsolete in some weeks or months.
By jondwillis 2025-11-251:58
I never really understood why you have to stuff all the tools in the context. Is there something wrong with having all your tools in, say, a markdown file, and having a subagent read it with a description of the problem at hand and returning just the tool needed at that moment? Is that what this tool search is?
Claude is pretty good at totally disregarding most of what’s in your CLAUDE.md, so I’m not optimistic. For example a project I work on gives it specific scripts to run when it runs automated tests, because the project is set up in a way that requires some special things to happen before tests will work correctly. I’ve never once seen it actually call those scripts on the first try. It always tries to run them using the typical command that doesn’t work with our setup, and I have to remind it the what correct thing to run is.
By snek_case 2025-11-255:39 I've had a similar experience with Gemini ignoring things I've explicitly told it (sometimes more than once). It's probably context rot. LLM give you a huge advertised number of tokens in the context, but the more stuff you put in there, the less reliably it remembers everything, which makes sense given how transformer attention blocks work internally.
By cerved 2025-11-256:40 Claude is pretty good at forgetting to run maven with -am flag, writing bash with heredocs that it's interpreter doesn't weird out on, using the != operator in jq. Maybe Claude has early onset dementia.
That's exactly what Claude Skills do [0], and while this tool search appears to be distinct, I do think that they're on the way to integrating MCP and Skills.
I haven't had much luck with skills being called appropriately. When I have a skill called "X doer", and then I write a prompt like "Open <file> and do X", it almost never loads up the skill. I have to rewrite the prompt as "Open <file> and do X using the X doer skill".
Which is basically exactly as much effort as what I was doing previously of having prewritten sub-prompts/agents in files and loading up the file each time I want to use it.
I don't think this is an issue with how I'm writing skills, because it includes skill like the Skill Creator from Anthropic.
By slhck 2025-11-257:58 Same experience here – it seems I have to specifically tell it to use the "X skill" to trigger it reliably. I guess with all the different rules set up for Claude to follow, it needs that particular word to draw its attention to the required skill.
By JyB 2025-11-251:39 That’s exactly what it is in essence. The MCP protocol simply doesn’t have any mechanism specifications (yet) for not loading tools completely in the context. There’s nothing really strange about it. It’s just a protocol update issue.
By noodletheworld 2025-11-256:37 > I never really understood why you have to stuff all the tools in the context.
You probably don't for... like, trivial cases?
...but, tool use is the most fine grained point, usually, in an agent's step-by-step implementation plan; So when planning, if you don't know what tool definitions exist, an agent might end up solving a problem naively step-by-step using primitive operations, when a single tool already exists that does that, or does part of it.
Like, it's not quite as simple as "Hey, do X"
It's more like: "Hey, make a plan to do X. When you're planning, first fetch a big list of the tools that seem vaguely related to the task and make a step-by-step plan keeping in mind the tools available to you"
...and then, for each step in the plan, you can do a tool search to find the best tool for x, then invoke it.
Without a top level context of the tools, or tool categories, I think you'll end up in some dead-ends with agents trying to use very low level tools to do high level tasks and just spinning.
The higher level your tool definitions are, the worse the problem is.
I've found this is the case even now with MCP, where sometimes you have to explicitly tell an agent to use particular tools, not to try to re-invent stuff or use bash commands.
