
Comments
By postalcoder 2026-01-2323:067 reply The best part about this blog post is that none of it is a surprise – Codex CLI is open source. It's nice to be able to go through the internals without having to reverse engineer it.
Their communication is exceptional, too. Eric Traut (of Pyright fame) is all over the issues and PRs.
This came as a big surprise to me last year. I remember they announced that Codex CLI is opensource, and the codex-rs [0] from TypeScript to Rust, with the entire CLI now open source. This is a big deal and very useful for anyone wanting to learn how coding agents work, especially coming from a major lab like OpenAI. I've also contributed some improvements to their CLI a while ago and have been following their releases and PRs to broaden my knowledge.
I know very little about typescript and even less about rust. Am I getting the rust version of codex when I do `npm i -g @openai/codex`?
A stand alone rust binary would be nicer than installing node.
By vorticalbox 2026-01-2414:471 reply yes [0]
> The Rust implementation is now the maintained Codex CLI and serves as the default experience
[0] https://github.com/openai/codex/tree/main/codex-rs#whats-new...
By alabhyajindal 2026-01-2414:543 reply They should switch to a native installer then. Quite confusing
By quinncom 2026-01-2418:28
https://developers.openai.com/codex/quickstart/?setup=clibrew install codexBy phrotoma 2026-01-2711:04 Yeah I'm out here installing a billion node things to have codex hack on my python app. Def gonna look into a standalone rust binary.
By Leynos 2026-01-2421:23 They're leveraging the (relative) ubiquity of npm amongst developers.
For some reason a lot of people are unaware that Claude Code is proprietary.
If the software is, say, Audacity, who's target market isn't specifically software developers, sure, but seeing as how Claude code's target market has a lot of people who can read code and write software (some of them for a living!) it becomes material. Especially when CC has numerous bugs that have gone unaddressed for months that people in their target market could fix. I mean, I have my own beliefs as to why they haven't opened it, but at the same time, it's frustrating hitting the same bugs day after day.
> ... numerous bugs that have gone unaddressed for months that people in their target market could fix.
THIS. I get so annoyed when there's a longstanding bug that I know how to fix, the fix would be easy for me, but I'm not given the access I need in order to fix it.
For example, I use Docker Desktop on Linux rather than native Docker, because other team members (on Windows) use it, and there were some quirks in how it handled file permissions that differed from Linux-native Docker; after one too many times trying to sort out the issues, my team lead said, "Just use Docker Desktop so you have the same setup as everyone else, I don't want to spend more time on permissions issues that only affect one dev on the team". So I switched.
But there's a bug in Docker Desktop that was bugging me for the longest time. If you quit Docker Desktop, all your terminals would go away. I eventually figured out that this only happened to gnome-terminal, because Docker Desktop was trying to kill the instance of gnome-terminal that it kicked off for its internal terminal functionality, and getting the logic wrong. Once I switched to Ghostty, I stopped having the issue. But the bug has persisted for over three years (https://github.com/docker/desktop-linux/issues/109 was reported on Dec 27, 2022) without ever being resolved, because 1) it's just not a huge priority for the Docker Desktop team (who aren't experiencing it), and 2) the people for whom it IS a huge priority (because it's bothering them a lot) aren't allowed to fix it.
Though what's worse is a project that is open-source, has open PRs fixing a bug, and lets those PRs go unaddressed, eventually posting a notice in their repo that they're no longer accepting PRs because their team is focusing on other things right now. (Cough, cough, githubactions...)
By pxc 2026-01-244:59 > I get so annoyed when there's a longstanding bug that I know how to fix, the fix would be easy for me, but I'm not given the access I need in order to fix it.
This exact frustration (in his case, with a printer driver) is responsible for provoking RMS to kick off the free software movement.
By fragmede 2026-01-254:54 GitHubactions is a bit of a special case, because it's mostly run in their systems, but that's when you just fork and, I mean, the problems with their (original) branch is their problem.
By arthurcolle 2026-01-245:031 reply They are turning it into a distributed system that you'll have to pay to access. Anyone can see this. CLI is easy to make and easy to support, but you have to invest in the underlying infrastructure to really have this pay off.
Especially if they want to get into enterprise VPCs and "build and manage organizational intelligence"
By storystarling 2026-01-2415:23 The CLI is just the tip of the iceberg. I've been building a similar loop using LangGraph and Celery, and the complexity explodes once you need to manage state across async workers reliably. You basically end up architecting a distributed state machine on top of Redis and Postgres just to handle retries and long-running context properly.
By lomase 2026-01-241:53 [dead]
Same. If you're already using a proprietary model might as well just double down
But you don't have to be restricted to one model either? Codex being open source means you can choose to use Claude models, or Gemini, or...
It's fair enough to decide you want to just stick with a single provider for both the tool and the models, but surely still better to have an easy change possible even if not expecting to use it.
By mi_lk 2026-01-2413:24 Codex CLI with Opus, or Gemini CLI with 5.2-codex, because they're open sourced agents? Go ahead if you want but show me where it actually happens with practical values
By consumer451 2026-01-245:433 reply This is a fun thought experiment. I believe that we are now at the $5 Uber (2014) phase of LLMs. Where will it go from here?
How much will a synthetic mid-level dev (Opus 4.5) cost in 2028, after the VC subsidies are gone? I would imagine as much as possible? Dynamic pricing?
Will the SOTA model labs even sell API keys to anyone other than partners/whales? Why even that? They are the personalized app devs and hosts!
Man, this is the golden age of building. Not everyone can do it yet, and every project you can imagine is greatly subsidized. How long will that last?
While I remember $5 Ubers fondly, I think this situation is significantly more complex:
- Models will get cheaper, maybe way cheaper
- Model harnesses will get more complex, maybe way more complex
- Local models may become competitive
- Capital-backed access to more tokens may become absurdly advantaged, or not
The only thing I think you can count on is that more money buys more tokens, so the more money you have, the more power you will have ... as always.
But whether some version of the current subsidy, which levels the playing field, will persist seems really hard to model.
All I can say is, the bad scenarios I can imagine are pretty bad indeed—much worse than that it's now cheaper for me to own a car, while it wasn't 10 years ago.
By depr 2026-01-2410:56 If the electric grid cannot keep up with the additional demand, inference may not get cheaper. The cost of electricity would go up for LLM providers, and VCs would have to subsidize them more until the price of electricity goes down, which may take longer than they can wait, if they have been expecting LLM's to replace many more workers within the next few years.
The real question is how long it'll take for Z.ai to clone it at 80% quality and offer it at cost. The answer appears to be "like 3 months".
By consumer451 2026-01-246:161 reply This is a super interesting dynamic! The CCP is really good at subsidizing and flooding global markets, but in the end, it takes power to generate tokens.
In my Uber comparison, it was physical hardware on location... taxis, but this is not the case with token delivery.
This is such a complex situation in that regard, however, once the market settles and monopolies are created, eventually the price will be what market can bear. Will that actually create an increase in gross planet product, or will the SOTA token providers just eat up the existing gross planet product, with no increase?
I suppose whoever has the cheapest electricity will win this race to the bottom? But... will that ever increase global product?
___
Upon reflection, the comment above was likely influenced by this truly amazing quote from Satya Nadella's interview on the Dwarkesh podcast. This might be one of the most enlightened things that I have ever heard in regard to modern times:
> Us self-claiming some AGI milestone, that's just nonsensical benchmark hacking to me. The real benchmark is: the world growing at 10%.
https://www.dwarkesh.com/p/satya-nadella#:~:text=Us%20self%2...
By YetAnotherNick 2026-01-2413:15 With optimizations and new hardware, power is almost a negligible cost that $5/month would be sufficient for all users, contrary to people's belief. You can get 5.5M tokens/s/MW[1] for kimi k2(=20M/KWH=181M tokens/$) which is 400x cheaper than current pricing even if you exclude architecture/model improvements. The thing is currently Nvidia is swallowing up a massive revenue which China could possible solve by investing in R and D.
[1]: https://developer-blogs.nvidia.com/wp-content/uploads/2026/0...
By FuckButtons 2026-01-247:532 reply I can run Minimax-m2.1 on my m4 MacBook Pro at ~26 tokens/second. It’s not opus, but it can definitely do useful work when kept on a tight leash. If models improve at anything like the rate we have seen over the last 2 years I would imagine something as good as opus 4.5 will run on similarly specced new hardware by then.
By consumer451 2026-01-248:271 reply I appreciate this, however, as a ChatGPT, Claude.ai, Claude Code, and Windsurf user... who has tried nearly every single variation of Claude, GPT, and Gemini in those harnesses, and has tested all the those models via API for LLM integrations into my own apps... I just want SOTA, 99% of the time, for myself, and my users.
I have never seen a use case where a "lower" model was useful, for me, and especially my users.
I am about to get almost the exact MacBook that you have, but I still don't want to inflict non-SOTA models on my code, or my users.
This is not a judgement against you, or the downloadable weights, I just don't know when it would be appropriate to use those models.
BTW, I very much wish that I could run Opus 4.5 locally. The best that I can do for my users is the Azure agreement that they will not train on their data. I also have that setting set on my claude.ai sub, but I trust them far less.
Disclaimer: No model is even close to Opus 4.5 for agentic tasks. In my own apps, I process a lot of text/complex context and I use Azure GPT 4.1 for limited llm tasks... but for my "chat with the data" UX, Opus 4.5 all day long. It has tested so superior.
Is Azure's pricing competitive on openAI's offerings through the api? Thanks!
By consumer451 2026-01-249:38 The last I checked, it is exactly equivalent per token to direct OpenAI model inference.
The one thing I wish for is that Azure Opus 4.5 had json structured output. Last I checked that was in "beta" and only allowed via direct Anthropic API. However, after many thousands of Opus 4.5 Azure API calls with the correct system and user prompts, not even one API call has returned invalid json.
By EnPissant 2026-01-2411:09 I'm guessing that's ~26 decode tokens/s for 2-bit or 3-bit quantized Minimax-m2.1 at 0 context, and it only gets worse as the context grows.
I'm also sure your prefill is slow enough to make the model mostly unusable, even at smallish context windows, but entirely at mid to large context.
Can't really fault them when this exists:
By bad_haircut72 2026-01-241:511 reply What even is this repo? Its very deceptive
Issue tracker for submitting bug reports that no one ever reads or responds to.
Now that's not fair, I'm sure they have Claude go through and ignore the reports.
By adastra22 2026-01-242:42 Unironically yes. If you file a bug report, expect a Claude bot to mark it as duplicate of other issues already reported and close. Upon investigation you will find either
(1) a circular chain of duplicate reports, all closed: or
(2) a game of telephone where each issue is subtly different from the next, eventually reaching an issue that has nothing at all to do with yours.
At no point along the way will you encounter an actual human from Anthropic.
By the way, I reversed engineered the Claude Code binary and started sharing different code snippets (on twitter/bluesky/mastadon/threads). There's a lot of code there, so I'm looking for requests in terms of what part of the code to share and analyze what it's doing. One of the requests I got was about the LSP functionality in CC. Anything else you would find interesting to explore there?
I'll post the whole thing in a Github repo too at some point, but it's taking a while to prettify the code, so it looks more natural :-)
By lifthrasiir 2026-01-243:053 reply Not only this would violate the ToS, but also a newer native version of Claude Code precompiles most JS source files into the JavaScriptCore's internal bytecode format, so reverse engineering would soon become much more annoying if not harder.
By arianvanp 2026-01-2410:23 Claude code is very good at reverse engineering. I reverse engineer Apple products in my MacBook all the time to debug issues
By kylequest 2026-01-243:36 Also some WASM there too... though WASM is mostly limited to Tree Sitter for language parsing. Not touching those in phase 1 :-)
By embedding-shape 2026-01-2413:25 > Not only this would violate the ToS
What specific parts of the ToS does "sharing different code snippets" violate? Not that I don't believe you, just curious about the specifics as it seems like you've already dug through it.
By pxc 2026-01-245:03 Using GitHub as an issue tracker for proprietary software should be prohibited. Not that it would, these days.
Codeberg at least has some integrity around such things.
By majkinetor 2026-01-247:39 That must be the worst repo I have ever seen.
By huevosabio 2026-01-2411:22 I frankly don't understand why they keep CC proprietary. Feels to me that the key part is the model, not the harness, and they should make the harness public so the public can contribute.
By causalmodels 2026-01-240:002 reply Yeah this has always seemed very silly. It is trivial to use claude code to reverse engineer itself.
By n2d4 2026-01-240:59 If you're curious to play around with it, you can use Clancy [1] which intercepts the network traffic of AI agents. Quite useful for figuring out what's actually being sent to Anthropic.
If only there were some sort of artificial intelligence that could be asked about asking it to look at the minified source code of some application.
Sometimes prompt engineering is too ridiculous a term for me to believe there's anything to it, other times it does seem there is something to knowing how to ask the AI juuuust the right questions.
By lsaferite 2026-01-2413:33 Something I try to explain to people I'm getting up to speed on talking to an LLM is that specific word choices matter. Mostly it matters that you use the right jargon to orient the model. Sure, it's good and getting the semantics of what you said, but if you adjust and use the correct jargon the model gets closer faster. I also explain that they can learn the right jargon from the LLM and that sometimes it's better to start over once you've adjusted you vocabulary.
By Der_Einzige 2026-01-241:571 reply GenAI was built on an original sin of mass copyright infringement that Aaron Swartz could only have dreamed of. Those who live in glass houses shouldn't throw stones, and Anthropic may very well get screwed HARD in a lawsuit against them from someone they banned.
Unironically, the ToS of most of these AI companies should be, and hopefully is legally unenforceable.
By adastra22 2026-01-242:35 Are you volunteering? Look, people should be aware that bans are being handed out for this, lest they discover it the hard way.
If you want to make this your cause and incur the legal fees and lost productivity, be my guest.
You're absolutely right! Hey Codex, Claude said you're not very good at reading obfuscated code. Can you tell me what this minified program does?
By adastra22 2026-01-2415:19 Claude is run on their servers.
By frumplestlatz 2026-01-2323:506 reply At this point I just assume Claude Code isn't OSS out of embarrassment for how poor the code actually is. I've got a $200/mo claude subscription I'm about to cancel out of frustration with just how consistently broken, slow, and annoying to use the claude CLI is.
By andy12_ 2026-01-249:33 > how poor the code actually is.
Very probably. Apparently, it's literally implemented with a React->Text pipeline and it was so badly implemented that they were having problems with the garbage collector executing too frequently.
By skerit 2026-01-248:55 I switched to Opencode a few weeks ago. What a pleasant experience. I can finally resume subagents (which has been Broken in CC for weeks), copy the source of the Assistant's output (even over SSH), have different main agents, have subagents call subagents,... Beautiful.
By qaz_plm 2026-01-242:14 A new one or one previously patched?
By sakesun 2026-01-271:33 Clause web is very slow compare to others.
By Razengan 2026-01-2417:45 In my experience, ChatGPT, and then Grok.
I've posted a lot of feedback about Claude since several months and for example they still don't support Sign in with Apple on the website (but support Sign in with Google, and with Apple on iOS!)
Interesting. Have you tested other LLMs or CLIs as a comparison? Curious which one you’re finding more reliable than Opus 4.5 through Claude Code.
By frumplestlatz 2026-01-246:03 Codex is quite a bit better in terms of code quality and usability. My only frustration is that it's a lot less interactive than Claude. On the plus side, I can also trust it to go off and implement a deep complicated feature without a lot of input from me.
By kordlessagain 2026-01-243:01 Yeah same with Claude Code pretty much and most people don’t realize some people use Windows.
By athrowaway3z 2026-01-2411:19 I'm almost certain their code is a dumpster fire.
As for your 200$/mo sub. Dont buy it. If you read the fine print, their 20x usage is _per 5h session_, not overall usage.
Take 2x 100$ if you're hitting the limit.
By boguscoder 2026-01-243:19 I thought Eric Traut was famous for his pioneering work in virtualization, TIL he has Pyright fame too !
By appplication 2026-01-2323:503 reply I appreciate the sentiment but I’m giving OpenAI 0 credit for anything open source, given their founding charter and how readily it was abandoned when it became clear the work could be financially exploited.
By jstummbillig 2026-01-247:53 > when it became clear the work could be financially exploited
That is not the obvious reason for the change. Training models got a lot more expensive than anyone thought it would.
You can of course always cast shade on people's true motivations and intentions, but there is a plain truth here that is simply silly to ignore.
Training "frontier" open LLMs seems to be exactly possible when a) you are Meta, have substantial revenue from other sources and simply are okay with burning your cash reserves to try to make something happen and b) you copy and distill from the existing models.
By seizethecheese 2026-01-242:081 reply I agree that openAI should be held with a certain degree of contempt, but refusing to acknowledge anything positive they do is an interesting perspective. Why insist on a one dimensional view? It’s like a fraudster giving to charity, they can be praiseworthy in some respect while being overall contemptible, no?
By cap11235 2026-01-242:32 Why even acknowledge them in any regard? Put trash where it belongs.
By edmundsauto 2026-01-245:16 By this measure, they shouldn’t even try to do good things in small pockets and probably should just optimize for profits!
Fortunately, many other people can deal with nuance.
By psychoslave 2026-01-2413:05 Is it just a frontend CLI calling remote external logic for the bulk of operations, or does it come with everything needed to run lovely offline? Does it provide weights under FLOW license? Does it document the whole build process and how to redo and go further on your own?
Interesting that compaction is done using an encrypted message that "preserves the model's latent understanding of the original conversation":
> Since then, the Responses API has evolved to support a special /responses/compact endpoint (opens in a new window) that performs compaction more efficiently. It returns a list of items (opens in a new window) that can be used in place of the previous input to continue the conversation while freeing up the context window. This list includes a special type=compaction item with an opaque encrypted_content item that preserves the model’s latent understanding of the original conversation. Now, Codex automatically uses this endpoint to compact the conversation when the auto_compact_limit (opens in a new window) is exceeded.
Their compaction endpoint is far and away the best in the industry. Claude's has to be dead last.
Help me understand, how is a compaction endpoint not just a Prompt + json_dump of the message history? I would understand if the prompt was the secret sauce, but you make it sound like there is more to a compaction system than just a clever prompt?
By FuckButtons 2026-01-248:011 reply They could be operating in latent space entirely maybe? It seems plausible to me that you can just operate on the embedding of the conversation and treat it as an optimization / compression problem.
Yes, Codex compaction is in the latent space (as confirmed in the article):
> the Responses API has evolved to support a special /responses/compact endpoint [...] it returns an opaque encrypted_content item that preserves the model’s latent understanding of the original conversation
Is this what they mean by "encryption" - as in "no human-readable text"? Or are they actually encrypting the compaction outputs before sending them back to the client? If so, why?
"encrypted_content" is just a poorly worded variable name that indicates the content of that "item" should be treated as an opaque foreign key. No actual encryption (in the cryptographic sense) is involved.
By whatreason 2026-01-2416:06 This is not correct, encrypted content is in fact encrypted content. For openai to be able to support ZDR there needs to be a way for you to store reasoning content client side without being able to see the actual tokens. The tokens need to stay secret because it often contains reasoning related to safety and instruction following. So openai gives it to you encrypted and keeps the keys for decrypting on their side so it can be re-rendered into tokens when given to the model.
There is also another reason, to prevent some attacks related to injecting things in reasoning blocks. Anthropic has published some studies on this. By using encrypted content, openai and rely on it not being modified. Openai and anthropic have started to validate that you're not removing these messages between requests in certain modes like extended thinking for safety and performance reasons
Are you sure? For reasoning, encrypted_content is for sure actually encrypted.
Hmmm, no, I don't know this for sure. In my testing, the /compact endpoint seems to work almost too well for large/complex conversations, and it feels like it cannot contain the entire latent space, so I assumed it keeps pointers inside it (ala previous_response_id). On the other hand, OpenAI says it's stateless and compatible with Zero Data Retention, so maybe it can contain everything.
By xg15 2026-01-2410:52 Ah, that makes more sense. Thanks!
By Art9681 2026-01-251:05 Their models are specifically trained for their tools. For example the `apply_patch` tool. You would think it's just another file editing tool, but its unique diff format is trained into their models. It also works better than the generic file editing tools implemented in other clients. I can also confirm their compaction is best in class. I've imlemented my own client using their API and gpt-5.2 can work for hours and process millions of input tokens very effectively.
By EnPissant 2026-01-245:44 Maybe it's a model fine tuned for compaction?
By kordlessagain 2026-01-243:02 Yes, agree completely.
Is it possible to use the compactor endpoint independently? I have my own agent loop i maintain for my domain specific use case. We built a compaction system, but I imagine this is better performance.
By westoncb 2026-01-241:41 It wouldn’t work for other models if it’s encoded in a latent representation of their own models.
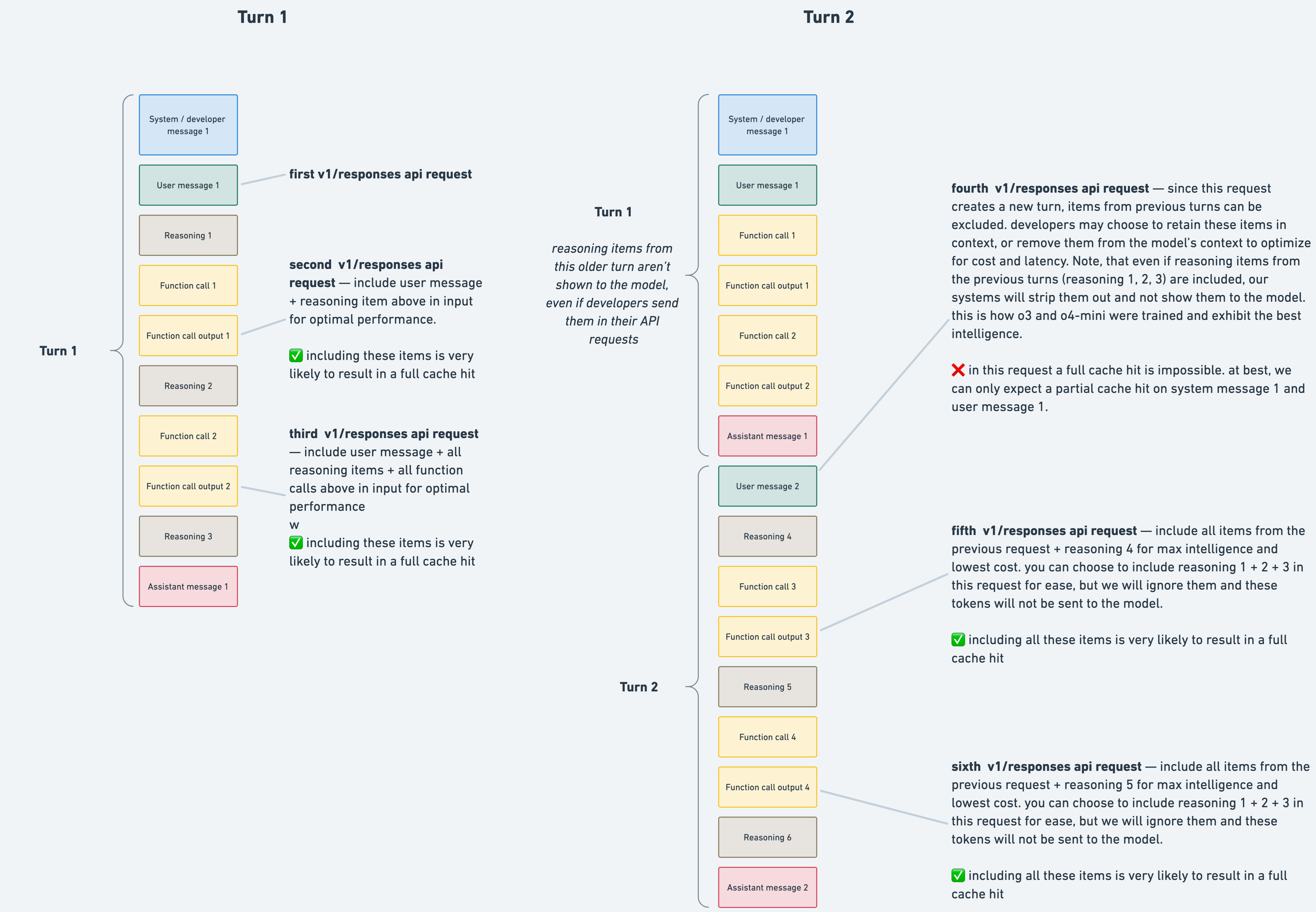
One thing that surprised me when diving into the Codex internals was that the reasoning tokens persist during the agent tool call loop, but are discarded after every user turn.
This helps preserve context over many turns, but it can also mean some context is lost between two related user turns.
A strategy that's helped me here, is having the model write progress updates (along with general plans/specs/debug/etc.) to markdown files, acting as a sort of "snapshot" that works across many context windows.
I don't think this is true.
I'm pretty sure that Codex uses reasoning.encrypted_content=true and store=false with the responses API.
reasoning.encrypted_content=true - The server will return all the reasoning tokens in an encrypted blob you can pass along in the next call. Only OpenaAI can decrypt them.
store=false - The server will not persist anything about the conversation on the server. Any subsequent calls must provide all context.
Combined the two above options turns the responses API into a stateless one. Without these options it will still persist reasoning tokens in a agentic loop, but it will be done statefully without the client passing the reasoning along each time.
Maybe it's changed, but this is certainly how it was back in November.
I would see my context window jump in size, after each user turn (i.e. from 70 to 85% remaining).
Built a tool to analyze the requests, and sure enough the reasoning tokens were removed from past responses (but only between user turns). Here are the two relevant PRs [0][1].
When trying to get to the bottom of it, someone from OAI reached out and said this was expected and a limitation of the Responses API (interesting sidenote: Codex uses the Responses API, but passes the full context with every request).
This is the relevant part of the docs[2]:
> In turn 2, any reasoning items from turn 1 are ignored and removed, since the model does not reuse reasoning items from previous turns.
[0]https://github.com/openai/codex/pull/5857
[1]https://github.com/openai/codex/pull/5986
[2]https://cookbook.openai.com/examples/responses_api/reasoning...
Thanks. That's really interesting. That documentation certainly does say that reasoning from previous turns are dropped (a turn being an agentic loop between user messages), even if you include the encrypted content for them in the API calls.
I wonder why the second PR you linked was made then. Maybe the documentation is outdated? Or maybe it's just to let the server be in complete control of what gets dropped and when, like it is when you are using responses statefully? This can be because it has changed or they may want to change it in the future. Also, codex uses a different endpoint than the API, so maybe there are some other differences?
Also, this would mean that the tail of the KV cache that contains each new turn must be thrown away when the next turn starts. But I guess that's not a very big deal, as it only happens once for each turn.
EDIT:
This contradicts the caching documentation: https://developers.openai.com/blog/responses-api/
Specifically:
> And here’s where reasoning models really shine: Responses preserves the model’s reasoning state across those turns. In Chat Completions, reasoning is dropped between calls, like the detective forgetting the clues every time they leave the room. Responses keeps the notebook open; step‑by‑step thought processes actually survive into the next turn. That shows up in benchmarks (TAUBench +5%) and in more efficient cache utilization and latency.
I think the delta may be an overloaded use of "turn"? The Responses API does preserve reasoning across multiple "agent turns", but doesn't appear to across multiple "user turns" (as of November, at least).
In either case, the lack of clarity on the Responses API inner-workings isn't great. As a developer, I send all the encrypted reasoning items with the Responses API, and expect them to still matter, not get silently discarded[0]:
> you can choose to include reasoning 1 + 2 + 3 in this request for ease, but we will ignore them and these tokens will not be sent to the model.
[0]https://raw.githubusercontent.com/openai/openai-cookbook/mai...
By EnPissant 2026-01-241:08 > I think the delta may be an overloaded use of "turn"? The Responses API does preserve reasoning across multiple "agent turns", but doesn't appear to across multiple "user turns" (as of November, at least).
Yeah, I think you may be correct.
It depends on the API path. Chat completions does what you describe, however isn't it legacy?
I've only used codex with the responses v1 API and there it's the complete opposite. Already generated reasoning tokens even persist when you send another message (without rolling back) after cancelling turns before they have finished the thought process
Also with responses v1 xhigh mode eats through the context window multiples faster than the other modes, which does check out with this.
By jumploops 2026-01-2423:23 That’s what I used to think, before chatting with the OAI team.
The docs are a bit misleading/opaque, but essentially reasoning persists for multiple sequential assistant turns, but is discarded upon the next user turn[0].
The diagram on that page makes it pretty clear, as does the section on caching.
[0]https://cookbook.openai.com/examples/responses_api/reasoning...
By jswny 2026-01-2413:11 How do you know/toggle which API path you are using?
By xg15 2026-01-2410:45 I think it might be a good decision though, as it might keep the context aligned with what the user sees.
If the reasoning tokens where persisted, I imagine it would be possible to build up more and more context that's invisible to the user and in the worst case, the model's and the user's "understanding" of the chat might diverge.
E.g. image a chat where the user just wants to make some small changes. The model asks whether it should also add test cases. The user declines and tells the model to not ask about it again.
The user asks for some more changes - however, invisibly to the user, the model keeps "thinking" about test cases, but never telling outside of reasoning blocks.
So suddenly, from the model's perspective, a lot of the context is about test cases, while from the user's POV, it was only one irrelevant question at the beginning.
By olliepro 2026-01-2322:56 I made a skill that reflects on past conversations via parallel headless codex sessions. Its great for context building. Repo: https://github.com/olliepro/Codex-Reflect-Skill
This is effective and it's convenient to have all that stuff co-located with the code, but I've found it causes problems in team environments or really anywhere where you want to be able to work on multiple branches concurrently. I haven't come up with a good answer yet but I think my next experiment is to offload that stuff to a daemon with external storage, and then have a CLI client that the agent (or a human) can drive to talk to it.
worktrees are good but they solve a different problem. Question is, if you have a lot of agent config specific to your work on a project where do you put it? I'm coming around to the idea that checked in causes enough problems it's worth the pain to put it somewhere else.
By ndriscoll 2026-01-2414:10 I have this in my AGENTS.md:
More stuff, but that's the basics of folder management, though I haven't hooked it up to our CI to deal with MRs etc, and have never told it that a project is done, so haven't ironed out whether that part of the workflow works well. But it does a good job of taking notes, using project-based state directories for planning, etc. Usually it obeys the worktree thing, but sometimes it forgets after compaction.## Task Management - Use the projects directory for tracking state - For code review tasks, do not create a new project - Within the `open` subdirectory, make a new folder for your project - Record the status of your work and any remaining work items in a `STATUS.md` file - Record any important information to remember in `NOTES.md` - Include links to MRs in NOTES.md. - Make a `worktrees` subdirectory within your project. When modifying a repo, use a `git worktree` within your project's folder. Skip worktrees for read-only tasks - Once a project is completed, you may delete all worktrees along with the worktrees subdirectory, and move the project folder to `completed` under a quarter-based time hierarchy, e.g. `completed/YYYY-Qn/project-name`.I'm dumb with this stuff, but what I've done is set up a folder structure:
And then in dev/AGENTS.md, I say to look at ai-workflows/AGENTS.md, and that's our team sharable instructions (e.g. everything I had above), skills, etc. Then I run it from `dev` so it has access to all repos at once and can make worktrees as needed without asking. In theory, we all should push our project notes so it can have a history of what changed when, etc. In practice, I also haven't been pushing my project directories because they have a lot of experimentation that might just end up as noise.dev/ dev/repoA dev/repoB ... dev/ai-workflows/ dev/ai-workflows/projects
worktrees are a bunch of extra effort. if your code's well segregated, and you have the right config, you can run multiple agents in the same copy of the repo at the same time, so long as they're working on sufficiently different tasks.
How do you achieve coordination?
Or do you require the tasks be sufficiently unrelated?
By tomashubelbauer 2026-01-2413:171 reply I do this sometimes - let Claude Code implement three or four features or fixes at the same time on the same repository directory, no worktrees. Each session knows which files it created, so when you ask CC to commit the changes it made in this session, it can differentiate them. Sometimes it will think the other changes are temporary artifacts or results of an experiment and try to clear them (especially when your CLAUDE.md contains an instruction to make it clean after itself), so you need to watch out for that. If multiple features touch the same file and different hunks belong to different commits, that's where I step in and manually coordinate.
By fragmede 2026-01-254:51 I'm insane and run sessions in parallel. Claude.md has Claude committing to git just the changes that session made, which lets me pull each sessions changes into their own separate branch for review without too much trouble.
I think this explains why I'm not getting the most out of codex, I like to interrupt and respond to things i see in reasoning tokens.
that's the main gripe I have with codex; I want better observability into what the AI is doing to stop it if I see it going down the wrong path. in CC I can see it easily and stop and steer the model. in codex, the model spends 20m only for it to do something I didn't agree on. it burns OpenAI tokens too; they could save money by supporting this feature!
By ljm 2026-01-2322:42 I’ve been using agent-shell in emacs a lot and it stores transcripts of the entire interaction. It’s helped me out lot of times because I can say ‘look at the last transcript here’.
It’s not the responsibility of the agent to write this transcript, it’s emacs, so I don’t have to worry about the agent forgetting to log something. It’s just writing the buffer to disk.
By crorella 2026-01-2321:23 Same here! I think it would be good if this could be made by default by the tooling. I've seen others using SQL for the same and even the proposal for a succinct way of representing this handoff data in the most compact way.
By sdwr 2026-01-2321:26 That could explain the "churn" when it gets stuck. Do you think it needs to maintain an internal state over time to keep track of longer threads, or are written notes enough to bridge the gap?
By pcwelder 2026-01-244:30 Sonnet has the same behavior: drops thinking on user message. Curiously in the latest Opus they have removed this behavior and all thinking tokens are preserved.
but that's why I like Codex CLI, it's so bare bone and lightweight that I can build lots tools on top of it. persistent thinking tokens? let me have that using a separate file the AI writes to. the reasoning tokens we see aren't the actual tokens anyway; the model does a lot more behind the scenes but the API keeps them hidden (all providers do that).
By postalcoder 2026-01-2322:401 reply Codex is wicked efficient with context windows, with the tradeoff of time spent. It hurts the flow state, but overall I've found that it's the best at having long conversations/coding sessions.
yeah it throws me out of the "flow", which I don't like. maybe the cerebras deal helps with that.
By postalcoder 2026-01-2322:521 reply It's worth it at the end of the day because it tends to properly scope out changes and generate complete edits, whereas I always have to bring Opus around to fix things it didn't fix or manually loop in some piece of context that it didn't find before.
That said, faster inference can't come soon enough.
By behnamoh 2026-01-2322:56 > That said, faster inference can't come soon enough.
why is that? technical limits? I know cerebras struggles with compute and they stopped their coding plan (sold out!). their arch also hasn't been used with large models like gpt-5.2. the largest they support (if not quantized) is glm 4.7 which is <500B params.
By dayone1 2026-01-242:15 where do you save the progress updates in? and do you delete them afterwards or do you have like 100+ progress updates each time you have claude or codex implement a feature or change?
By lighthouse1212 2026-01-305:52 [dead]
By lighthouse1212 2026-01-2416:03 [dead]

{kind=link}
{kind=link}