
The recent release of a tranche of files by the US Department of Justice (DoJ) under the “Epstein Files Transparency Act (H.R.4405)” has once again prompted many people to closely examine redacted and…
The recent release of a tranche of files by the US Department of Justice (DoJ) under the “Epstein Files Transparency Act (H.R.4405)” has once again prompted many people to closely examine redacted and sanitized PDF documents. Our previous articles on the Manafort papers and the Mueller report, as well as a study by Adhatarao, S. and Lauradoux, C. (2021) “Exploitation and Sanitization of Hidden Data in PDF Files: Do Security Agencies Sanitize Their PDF files?,” in Proceedings of the 2021 ACM Workshop on Information Hiding and Multimedia Security, illustrate the importance of robust sanitization and redaction workflows when handling sensitive documents prior to release.
This article examines a small random selection of the Epstein PDF files from a purely digital forensic perspective, focusing on the PDF syntax and idioms they contain, any malformations or unusual constructs, and other technical aspects.
PDFs are more challenging to analyze than many other formats because they are binary files that require specialized knowledge, expertise, and software. Please note that we did not analyze the contents of the PDF documents. Not every PDF was examined. Any mention of products (or appearance in screen-shots) does not imply any endorsement or support of any information, products, or providers whatsoever. We are not lawyers; this article does not constitute legal advice
We offer this information, in part, as some of the Epstein PDFs released by DoJ are beginning to appear on malware analysis sites (such as Hybrid-Analysis) with various kinds of incorrect analysis and misinformation.
After we'd completed our analysis the DoJ released a new dataset, DataSet 8.zip. This new ZIP file is 9.95 GB compressed and contains over 11,000 files, including 10,593 new PDFs totaling 1.8 GB and 29,343 pages (the longest document has 1,060 pages). DataSet 8 also contains many large MP4 movies, Excel spreadsheets, and various other files. The first PDF in the set of 10,593 PDFs is VOL00008\IMAGES\0001\EFTA00009676.pdf, and the last file is VOL00008\IMAGES\0011\EFTA00039023.pdf. A cursory analysis shows pdfinfo properties similar to those from the earlier datasets, but we have not otherwise analyzed this new dataset.
Since our original post, various social media and news platforms have also been announcing “recoverable redactions” from the “Epstein Files”. We stand by our analysis; DoJ has correctly redacted the EFTA PDFs in Datasets 01-07, and they do not contain recoverable text as alleged. As our article states, we did not analyze any other DoJ or Epstein-related documents.
For example, the featured image in this Guardian news article (which was also picked up by the New York Times) corresponds to VOL00004\IMAGES\0001EFTA00005855.pdf, as can be easily determined by searching for the Bates Numbers in the EFTA “.OPT” data files. The information in this EFTA PDF is fully and correctly redacted; there is no hidden information. The only extractable text is some garbled text from the poor-quality OCR and, as expected, the Bates Numbers on each page.
In the few reports we investigated (including from Forbes and Ed Krassenstein on both X (formerly Twitter) and Instagram), these stories misrepresent other DoJ files that were not part of the major DataSets 01-07 release on December 19 under the EFTA. All PDFs released under EFTA have a Bates Number on every page starting "EFTA". These include “Case 1:22-cv-10904-JSR Document 1-1, Exhibit 1 to Government’s Complaint against JPMorgan Chase Bank, N.A.” (see page 41) and “Case No: ST-20-CV-14 Government Exhibit 1” (see page 19). These PDFs, previously released by the DoJ, do contain incorrect and ineffective redactions, with black boxes that simply obscure text, making “copy & paste” easy to recover the text that's otherwise hidden. Clearly, DoJ processes and systems in the past have inadequately redacted information!
The files we examined
The tranche released by DoJ on Friday, December 19 is available as seven “data sets”, most easily downloaded as seven ZIP archives totaling just under 2.97 GB. Each ZIP file contains a similar folder structure, with DataSet 6 being the odd one out with an extra top-level folder. Once unzipped, the total size is 2.99 GB. The tranche contains 4,085 PDF files, a single AVI (movie) file (located in the folder VOL00002\NATIVES\0001), and 2 data files (.DAT and .OPT) for each ZIP archive. The “.OPT” files appear to be CSV (Comma-Separated Values) but lack a heading row, while the “.DAT” files contain information about the Bates numbering. The analysis we provide here is limited to the PDF files.
The PDF files are named and ordered sequentially within the folder structure, starting with “EFTA00000001.pdf” in VOL00001 and ending with “EFTA00009664.pdf” in VOL00007, indicating that at least 5,879 PDF files remain unreleased.
A random sampling of the PDFs for visual review suggests that they are a mix of single and multi-page full-page photos and scanned content. OCR (Optical Character Recognition) was used to provide some searchable and extractable text in at least some files. “Black box” style redactions (without text reasons) are apparent. When done correctly, this is the appropriate way to redact, far more robust than pixelating text. The PDFs we sampled did not include any obviously “born digital” documents. Various news sites are reporting very heavily redacted documents within this tranche.
File validity
A precursor to most forensic examinations is to establish whether the PDF files are technically valid (that is, conform to the rules of the PDF format), since analyzing malformed files can easily lead to incorrect results or wrong conclusions. Combining tools that use different methods provides the broadest possible information while ensuring that tooling limitations are fully understood. However, if the basic file structure or cross-reference information is incorrect, various software might then draw different conclusions and/or construct different Document Object Models (DOMs).
In addition to basic file structure, incremental updates (if any), and cross-reference information, PDF validity assessments include the objects that comprise the PDF’sDOM as well as the file structure, incremental updates, and cross-reference information. To assess relationships between objects in the PDF DOM, some forensic analysis tools leverage our Arlington PDF Data Model, while others use their own internal methods.
Our analysis of file validity, using a multitude of PDF forensic tools, identified only one minor defect (invalidity); 109 PDFs had a positive FontDescriptor Descent value rather than a negative one. This is a relatively common (but minor) error, typically associated with font substitution and font matching, that does not affect the validity of the files overall. One specific forensic tool reported a PDF version issue with some files, related to the document catalog Version entry, which prevented the tool from further verifying those specific PDFs.
PDF versions
I’ve previously written about the unreliability of PDF version numbers. Still, for forensic purposes, they may provide insight into the DoJ’s software, and whether improved software could have performed better.
I used two different but commonly used PDF command-line pdfinfo utilities on different platforms (Windows and Ubuntu Linux) to summarize information about these PDF files. When run against the full tranche of PDFs, I got two very different sets of answers! Immediately, my spidey senses started to tingle, and I was once again reminded of a key lesson in digital document forensics – you should never trust a single tool!
| Reported PDF Version | Count Tool A | Count Tool B |
| 1.3 | 209 | 3,817 |
| 1.4 | 1 | 1 |
| 1.5 | 3,875 | 267 |
| TOTAL (should be 4,085) | 4,085 | 4,085 |
The PDF version in the file header, “%PDF-x.y”, is nominally the first line in every PDF file (based on the not-unreasonable assumption that the PDF files have no “junk bytes” before this PDF file identifier). Using the Linux command line, you can run in Linux “head -n 1 file.pdf” to extract the first header line from each PDF and compare it with the reported results from each tool. Or run in Linux “grep -P --text --byte-offset "%PDF-\d\.\d" *.pdf” to confirm that there are no junk bytes prior to the PDF header line.
The reason for the difference reported in the table above is that Tool B is not accounting for the Version entry in the document catalog of PDFs with incremental updates. We’ll next investigate whether this is due to malformed files or a programming error. When properly accounting for incremental updates, however, Tool A is correct.
Using the same pdfinfo output (and again comparing results from both tools), we can also quickly establish the following facts:
- No PDF is tagged
- No PDF is encrypted
- No PDF is “optimized” (technically, Linearized PDF)
- No PDF has any annotations
- No PDF has any outlines (bookmarks)
- No PDF contains any embedded files
- None of the PDFs are forms
- None of the PDFs contains JavaScript
Page counts range from 1 (in 3,818 PDFs) to 119 pages (in two PDFs), totaling 9,659 pages across all 4,085 PDFs.
PDF’s incremental updates feature allows multiple revisions of a document to be stored in a PDF file. As the name implies, each set of deltas is appended to the original document, forming a chain of edits. When read by conforming PDF software, a PDF is always processed from the end of the file, effectively applying the deltas to the original document and to any previous incremental updates. Both the original document and each incremental update can be recognized by their respective “xref” and “%%EOF” markers (assuming that the PDF files are structured correctly).
For this investigation, we started by examining the very first PDF in the tranche: VOL00001\IMAGES\0001\EFTA00000001.pdf. This PDF had different PDF versions reported by different versions of pdfinfo. A simple trick to check if a PDF contains incremental updates is to search for these special markers while treating the PDF as a text file (which it isn’t!):
$ grep -P --text -–byte-offset "(xref)|(%%EOF)" EFTA00000001.pdf
371340:xref
371758:startxref
371775:%%EOF
372977:startxref
372994:%%EOF
373961:startxref
373978:%%EOF
These results (sorted by byte offset) indicate that EFTA00000001.pdf contains two incremental updates after the original file. The lack of an “xref” marker before the last two “startxref” markers indicate that neither incremental updates uses conventional cross-reference data, but may use cross-reference streams (if any objects are changed).
Bates numbering
As referenced above, Bates numbering is the process by which every page is assigned a unique identifier. For this tranche of Epstein PDF files, Bates numbers were added to each page via a separate incremental update, as shown below in Visual Studio Code with my pdf-cos-syntax extension. Note that DoJ’s PDFs are primarily text-based internally, making forensic analysis a lot easier - and the files a lot bigger.
Observations:
- Line 2984 is the end-of-file marker for the file version, and line 2985 starts a new incremental update section.
- Lines 2985-2987 define object 26, the unembedded Helvetica font resource used by the Bates number.
- Lines 2997-3020 are the modified page object (object 3), replacing the page object in previous revisions of the file.
- Line 2999 is the page Contents array, comprising five separate content streams, with the 3rd stream (object 29) being the Bates numbering added in this incremental update. Object 30 is an empty content stream that could have been removed by an optimization process.
- Line 3034 sets the Helvetica font to 12 point.
- Line 3037 uses a hexadecimal string to paint the Bates number onto the page.
The idiom for this final incremental update, which adds the Bates number to every page, appears in all the PDF files we selected at random for investigation. This specific incremental update always uses a cross-reference stream (/Type /XRef) and relies on the previous incremental update, in which the document catalog Version entry is set to PDF 1.5.
The VSCode pdf-cos-syntax extension also indicates (correctly!) that the original PDF is missing the required (when the PDF contains binary data, which most do) comment as the second line of the file that indicates to software that the PDF file needs to be treated as binary data (ISO 32000-2:2020, §7.5.2). Although the missing comment does not make the PDF invalid per se, without such a marker close to the top of each PDF, software may think the PDF is a text file, and thus potentially corrupt the PDF by changing line endings, which would break the byte offsets in the cross-reference data. In this PDF, the first incremental update adds this marker comment after a lot of binary data, which is pointless.
As mentioned above, the first incremental update changed the document catalog Version entry to PDF 1.5, as we see in this next screenshot:
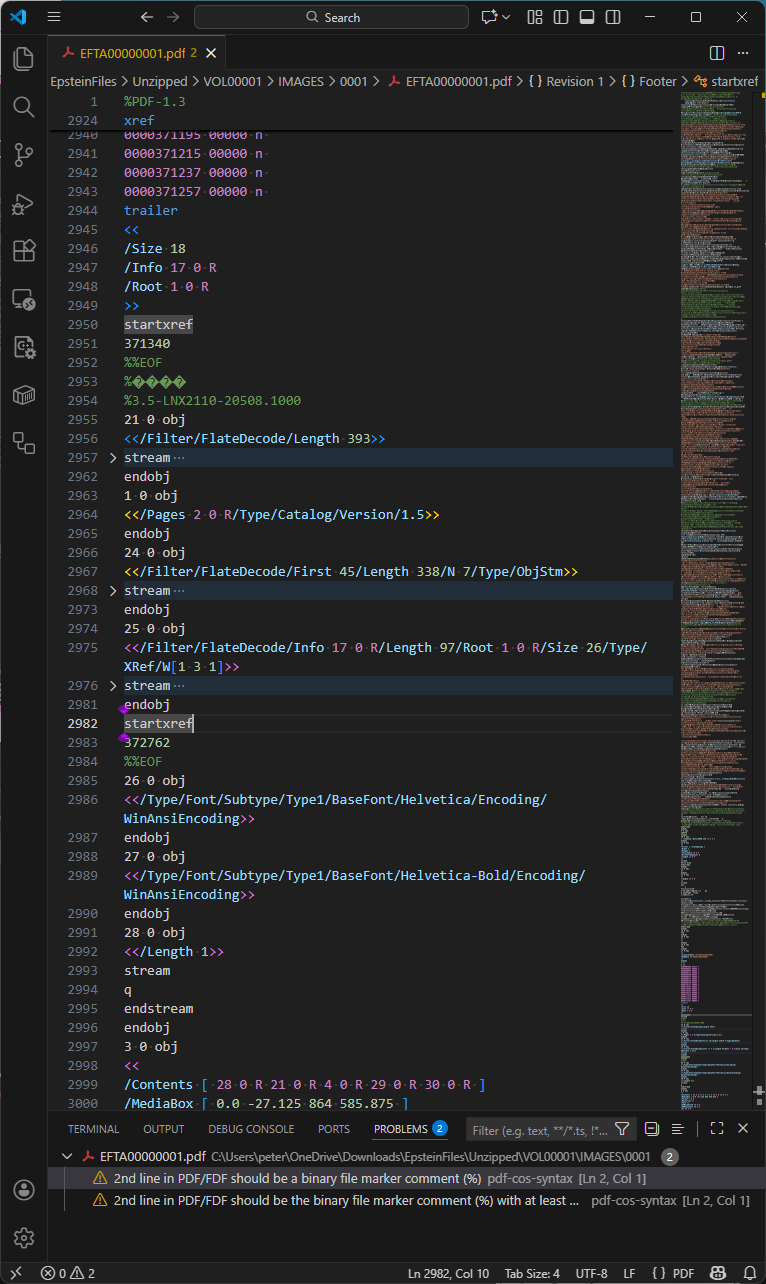
Observations:
- Lines 2953-2984 are the incremental update section.
- Line 2954 is a PDF comment. PDF comments always start with a PERCENT SIGN (
%) and may occur in many places in PDF files. Effective sanitization and redaction workflows typically remove all comments from PDFs because they may inadvertently disclose information, but this exact comment appears in 3,608 other PDF files. The origin or meaning of this comment was not further investigated. - Line 2964 upgrades the PDF version to 1.5. At first glance, this may appear to be perfectly valid PDF, but it is technically incorrect because the file header is
%PDF-1.3yet the Version key was only added in PDF 1.4 - this is what the strict file validation tool mentioned above had noticed. As object 24 is a compressed object stream (lines 2966-2973) and object 25 is a compressed cross-reference stream (lines 2974-2981), the indicated version should be PDF 1.5. As a practical matter, however, this level of technical detail does not impact operation or behavior of PDFs. - Line 2984 is the end-of-section “
%%EOF” marker for this incremental update section.
As this section of the PDF uses compressed object streams, specialized PDF forensic tools must be used… simple search methodologies, such as those mentioned above, may not identify everything!
We know that there are 7 objects (because we find /N 7) inside the object stream:
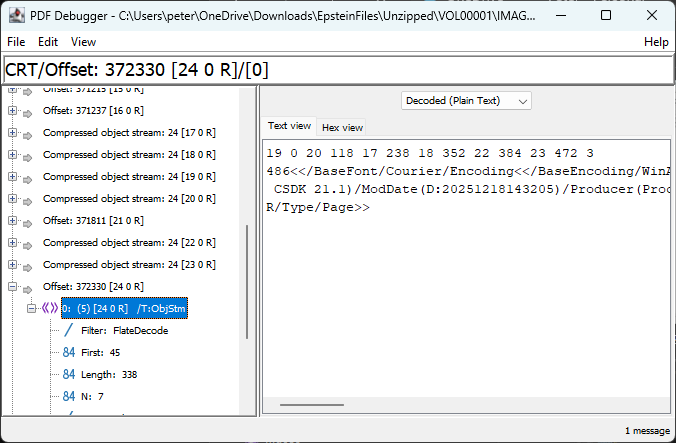
As per PDF’s specification, ISO 32000-2:2020, §7.5.7, the first line of integers is interpreted as N pairs, where the first integer is the object number and the second integer is the byte offset relative to the first object in the object stream.
| N | 1st integer (object number) | 2nd integer (start offset) | Explanation | Content |
| 1 | 19 | 0 | Type1 Font object for OPBaseFont0 (Courier) | <</BaseFont/Courier/Encoding<</BaseEncoding/WinAnsiEncoding/Type/Encoding>>/Name/OPBaseFont0/Subtype/Type1/Type/Font>> |
| 2 | 20 | 118 | Type1 Font object for OPBaseFont1 (Helvetica) | <</BaseFont/Helvetica/Encoding<</BaseEncoding/WinAnsiEncoding/Type/Encoding>>/Name/OPBaseFont1/Subtype/Type1/Type/Font>> |
| 3 | 17 | 238 | Document information (Info) dictionary | <</CreationDate(D:20251218143205)/Creator(OmniPage CSDK 21.1)/ModDate(D:20251218143205)/Producer(Processing-CLI)>> |
| 4 | 18 | 352 | ProcSet resources array | [/PDF/Text/ImageB/ImageC/ImageI] |
| 5 | 22 | 384 | Resources dictionary for the page | <</Font<</OPBaseFont0 19 0 R/OPBaseFont1 20 0 R>>/ProcSet 18 0 R/XObject<</Im0 8 0 R>>>> |
| 6 | 23 | 472 | Array of 2 indirect references (to content streams) | [21 0 R 4 0 R] |
| 7 | 3 | 486 | Updated Page object | <</Contents 23 0 R/MediaBox[0 0 864 576.75]/Parent 2 0 R/Resources 22 0 R/Thumb 11 0 R/Type/Page>> |
What is very interesting here – from a PDF forensics perspective – is the fact of a hidden document information dictionary that is not referenced from the last (final) incremental update trailer (i.e., there is no Info entry in object 31, lines 3050-3063 below). As such, this orphaned dictionary is invisible to PDF software! This oddity occurs in all other PDFs we’d randomly selected for investigation.
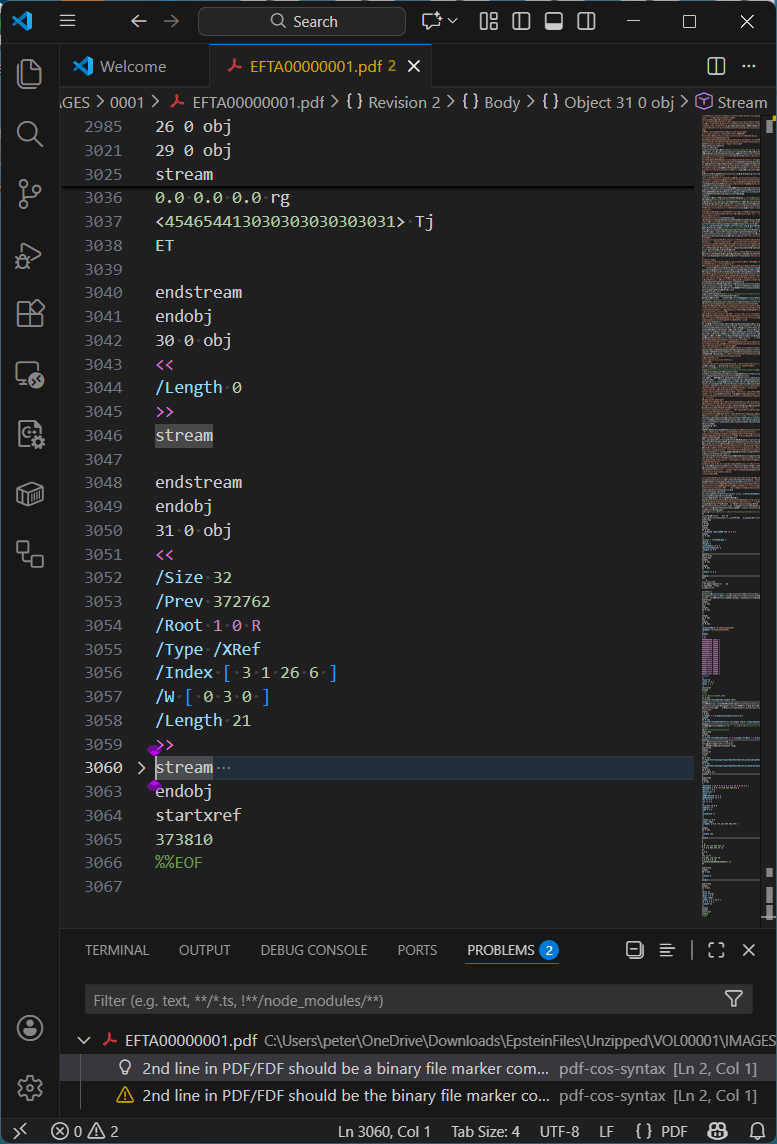
Formatted nicely as an uncompressed object, this hidden document information dictionary inside the compressed object stream contains the following information (the CreationDate and ModDate appear to change in other randomly examined PDFs):
17 0 obj
<<
/CreationDate (D:20251218143205)
/ModDate (D:20251218143205)
/Creator (OmniPage CSDK 21.1)
/Producer (Processing-CLI)
>>
endobj
This metadata clearly indicates the software DoJ used to manipulate these PDF files. Although not relevant to the content, this forensic discovery clearly shows that extra care is required when sanitizing PDFs.
Another randomly selected PDF, VOL00003\IMAGES\0001\EFTA00003939.pdf contains 3 full-page images, and just a single incremental update that applies the Bates numbering. However, in this case the file header is %PDF-1.5 yet both the original PDF and incremental update use conventional cross-reference tables! This isn’t problematic, but is certainly unexpected and inefficient since PDF 1.5 introduced compressed cross-reference streams.
By comparing the objects in the incremental cross-reference table to the original cross-reference table we can see that objects 66 to 69 – the 3 Page objects for the 3 page document – were redefined. This is just what is expected in order to add the Bates number to each page’s Contents stream as in the previous example.
Our initial examination using pdfinfo utilities did not identify any metadata in any of the PDFs in the tranche, either in the document information dictionary (PDF file trailer Info entry) or as an XMP metadata stream (Metadata entry).
However, since we know that (a) the tranche includes PDFs with incremental updates, and (b) that an orphaned document information dictionary exists, all revisions of a document should be thoroughly examined. Incremental updates may have marked other document information dictionaries or XMP metadata streams as free but not deleted the actual data.
XMP metadata is always encoded in PDF as a stream object, and since stream objects cannot be in compressed object streams, using forensic tools to search for keys “/XML” or “/Metadata” should always locate them. All modern office suites and PDF creation applications will generate XMP metadata when exporting to PDF. As XMP is usually uncompressed, searching for XML fragments may also be helpful (see below for an example XMP object fragment).
3 0 obj
<</Length 36996/Subtype/XML/Type/Metadata>>
stream
<?xpacket begin="" id="W5M0MpCe … zNTczkc9d"?>
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk=" … ">
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xmp="http://ns.adobe.com/xap/1.0/"
...
Not unsurprisingly for properly-redacted files, we did not find any XMP metadata streams or XML in any PDF. As a consequence, none of the PDFs can declare conformance to either PDF/A (ISO 19005 for long-term archiving) or PDF/UA (ISO 14289 for accessibility). Of course, as untagged PDFs, the files cannot conform to accessibility specifications such as PDF/UA or WCAG in any event. Additionally, none of the PDFs appear to include device-independent color spaces.
The presence of an Info entry in the trailer dictionary or (in PDFs with cross-reference streams) in the cross-reference stream dictionary indicates the presence of document information dictionaries. “/Info” does indeed occur in many of the PDFs, including multiple times in some PDFs, indicating potential changes via incremental updates. However, as discovered above, in some cases the final incremental update does not include an Info entry, thus “orphaning” any existing document information dictionaries.
ISO 32000-2:2020, Table 349 lists the defined entries in PDF’s document information dictionary (Title, Author, Subject, etc). Any vendor may add additional entries (such as Apple does with its /AAPL:Keywords entry), so redaction and sanitization software should be aware of extra entries.
From our random sampling, we identified one PDF with a non-trivial document information dictionary still present: VOL00002\IMAGES\0001\EFTA00003212.pdf. This is shown below in Visual Studio Code with my pdf-cos-syntax extension:
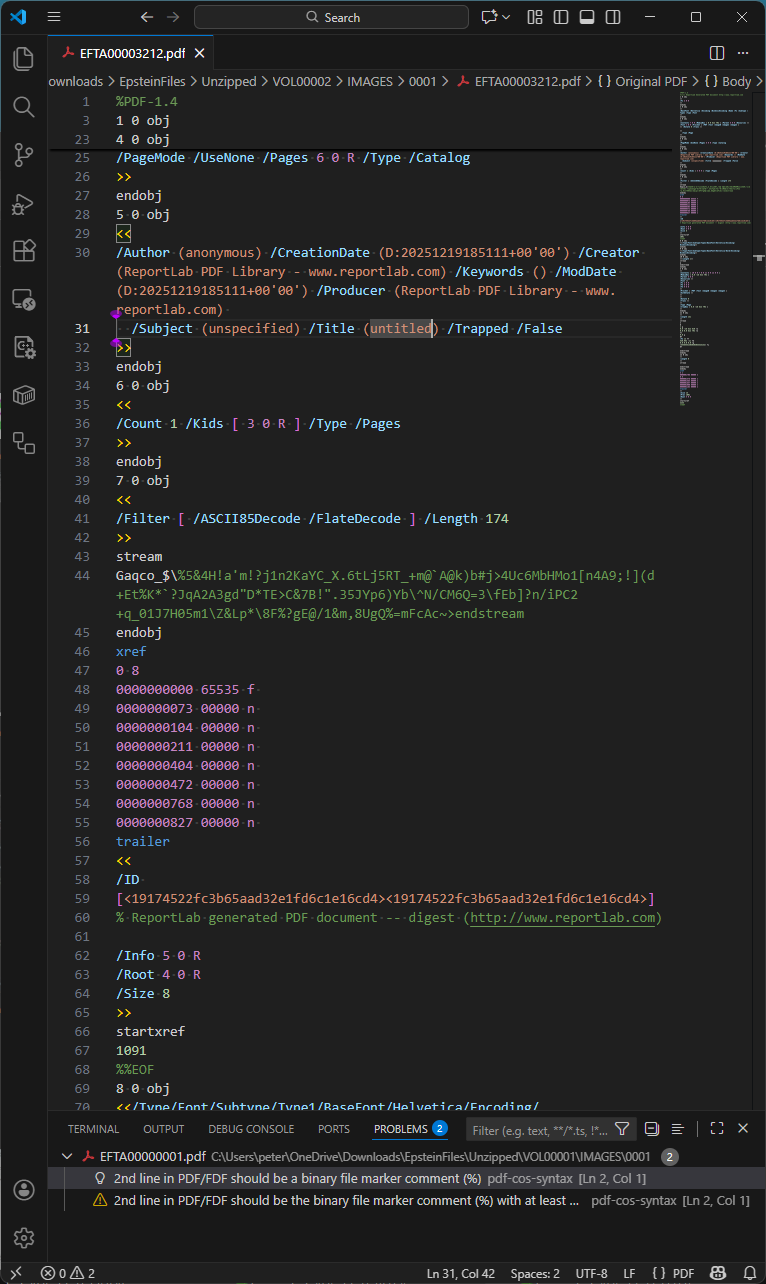
Of additional interest in this specific PDF is that the comment at line 60 has survived DoJ’s sanitization and redaction workflow! Other PDF comments may therefore also be present in other files.
EFTA00003212.pdf appears to be a redacted image or an error from the DoJ workflow, as it is a single page with the text “No Images Produced”.
Simple searching of the standardized PDF document information dictionary entries gives the following (note that the technique used will not locate information in compressed object streams, as mentioned above):
| Key name | Number of PDFs (max. = 4,085) | Comment |
| Info | 3,823 | Some PDFs have empty Info dictionaries with no entries |
| Title | 1 | Only EFTA00003212.pdf |
| Author | 1 | Only EFTA00003212.pdf |
| Subject | 1 | Only EFTA00003212.pdf |
| Keywords | 1 | Only EFTA00003212.pdf |
| Creator | 1 | Only EFTA00003212.pdf |
| Producer | 215 | Always “pypdf” (denotes https://pypi.org/project/pypdf/) |
| CreationDate | 3,609 | Same PDFs that have ModDate with an identical value |
| ModDate | 3,609 | Same PDFs that have CreationDate with an identical value |
| Trapped | 1 | Only EFTA00003212.pdf |
| APPL:Keywords | 0 |
Detailed date analysis is a common task in the forensic analysis of potentially fraudulent or modified documents. However, in the case of redacted or sanitized documents, where the document is known to have been modified, this can be less useful.
The creation and modification dates for the 3,609 PDFs range from December 18, 2025, 14:32:05 (2:32 pm) to December 19, 2025, 23:26:13 (almost midnight). For all files, the creation and modification dates are always the same. This may also imply that the DoJ batch processing to prepare this tranche of PDFs took at least 36 hours!
What’s also interesting is that the CreationDate and ModDate fields in the hidden document information dictionary (inside the object stream of the first increment update – see above) appear to always be an exact match to both the CreationDate and ModDate of the original document. This implies that all dates across all incremental updates were updated in a single processing pass that applied the Bates numbering.
Photographs
There are no JPEG images (DCTDecode filter) in any PDF in the tranche, including the full-page photographs. Randomly viewing the photographic images at high magnification (zoom) in PDF viewers clearly shows JPEG “jaggy” compression artifacts. All photographic images appear to have been downscaled to 96 DPI (769 x 1152 or 1152 x 769 pixels), making text on random objects in the photos much harder to discern (see the OCR discussion below).
DoJ explicitly avoids JPEG images in the PDFs probably because they appreciate that JPEGs often contain identifiable information, such as EXIF, IPTC, or XMP metadata, as well as COM (comment) tags in the JPEG bitstream. This information may disclose the camera model and serial number, GPS location, camera operator details, date/time of the photo, etc., and is more difficult to redact while retaining the JPEG data. The DoJ processing pipeline has therefore explicitly converted all lossy JPEG images to low DPI, FLATE-encoded bitmaps in the PDFs using an indexed device-dependent color space with a palette of 256 unique colors (which reduces the color fidelity compared to the original high-quality digital color photograph).
Scanned documents – or are they?
Randomly inspecting the tranche discovers many documents that appear to have been created by a scanning process. On closer inspection, there are documents that have tell-tale artifacts from a physical scanning process, such as visible physical paper edges, punched holes, staple marks, spiral binding, stamps, paper scuff marks, color blotches and inconsistencies, handwritten notes or marginalia, varying paper skew, and platen marks from the physical paper scanning processes. For example, VOL00007\IMAGES\0001\EFTA00009440.pdf shows many of these aspects
There are also other documents that appear to simulate a scanned document but completely lack the “real-world noise” expected with physical paper-based workflows. The much crisper images appear almost perfect without random artifacts or background noise, and with the exact same amount of image skew across multiple pages. Thanks to the borders around each page of text, page skew can easily be measured, such as with VOL00007\IMAGES\0001\EFTA00009229.pdf. It is highly likely these PDFs were created by rendering original content (from a digital document) to an image (e.g., via print to image or save to image functionality) and then applying image processing such as skew, downscaling, and color reduction.
The use of the timeless monospaced (also known as fixed-width) “Courier” typeface means that the number of characters redacted can be easily determined by vertical alignment with text lines above and below each redaction. In some instances, this may reduce the possible number of options that represent the redacted content, allowing it to be more easily guessed. Although redaction of variable-width typefaces is far more complex, Bland, M., Iyer, A., and Levchenko, K. 2022 paper “Story Beyond the Eye: Glyph Positions Break PDF Text Redaction” showed that this is still possible with sufficient computing power and determination.
Optical Character Recognition (OCR)
OCR is complex image processing that attempts to identify text in bitmap images. In PDF files, OCR-identified text is commonly placed on top of the image using the invisible text render mode. This enables users to then extract the text from the image.
Returning to the very first PDF file in the tranche, VOL00001\IMAGES\0001\EFTA00000001.pdf - this is a full-page photo of a hand-written sign where part of the hand-written information is explicitly redacted. The PDF contains largely inaccurate OCR-ed text, indicating that natural language processing (NLP), machine learning (ML), or even language aware dictionary-based algorithms were not used. This means that there will be more errors in the extracted text than is necessary.
With cloud platforms readily accessible and supporting advanced OCR at low cost, anyone is capable of re-processing the entire tranche of PDFs and comparing the OCR results to those provided by DoJ. Even though the page images are low-resolution (96 DPI), rerunning OCR may bring to light additional or corrected information hidden by the original OCR that failed to recognize everything correctly.
The “black box” redactions we investigated were all correctly applied directly into the image pixel data. They are not separate PDF rectangle objects simply floating above sensitive information that was still present in the image and easily discoverable. Yes, sometimes it is that easy…!
Conclusion
We did not set out to comprehensively analyze every corner of every PDF file in the Epstein PDFs, but to present a basic walk-through of some of the challenges and tricks used to conduct a PDF forensic assessment. Our results above were from a small random sample of documents - there may well be outlier PDFs in the data sets that we did not encounter.
The DoJ has clearly created internal processes, systems, and workflows that can sanitize and redact information prior to publishing as PDF. This includes converting JPEG images to low-resolution pixel-only bitmaps, largely removing metadata, and rendering page images to bitmaps. OCR appears to have been widely applied, but is of variable quality.
Their PDF technology could be improved to vastly reduce file size by removing unnecessary objects (e.g., empty content streams, ProcSets, empty thumbnail references, etc.), simplifying and reducing content streams, applying all incremental updates (i.e., removing all incremental update sections), and always using compressed object streams and compressed cross-reference streams. Information leakage may also be occurring via PDF comments or orphaned objects inside compressed object streams, as I discovered above.
PDF forensics is a highly complex field, where variations in files and tool assumptions can easily yield false results. The PDF Association hosts a PDF Forensic Liaison Working Group to develop industry guidance on forensic examination of PDF files and to educate document examiners and other specialists about many of these aspects.
Read the original article
Comments
I found this part interesting:
There are also other documents that appear to simulate a scanned document but completely lack the “real-world noise” expected with physical paper-based workflows. The much crisper images appear almost perfect without random artifacts or background noise, and with the exact same amount of image skew across multiple pages. Thanks to the borders around each page of text, page skew can easily be measured, such as with VOL00007\IMAGES\0001\EFTA00009229.pdf. It is highly likely these PDFs were created by rendering original content (from a digital document) to an image (e.g., via print to image or save to image functionality) and then applying image processing such as skew, downscaling, and color reduction.
By tombrossman 2026-02-0419:325 reply GNOME Desktop users can put this in a Bash script in ~/.local/share/nautilus/ for more convincing looking fake PDF scans, accessible from your right-click menu. I do not recall where I copied it from originally to give credit so thanks, random internet person (probably on Stack Exchange). It works perfectly.
ROTATION=$(shuf -n 1 -e '-' '')$(shuf -n 1 -e $(seq 0.05 .5)) for pdf in "$@"; do magick -density 150 $pdf \ -linear-stretch '1.5%x2%' \ -rotate 0.4 \ -attenuate '0.01' \ +noise Multiplicative \ -colorspace 'gray' \ "${pdf%.*}-fakescan.${pdf##*.}" doneBy barrkel 2026-02-0421:11 That seq is probably supposed to be $(seq 0.05 0.05 0.5). Right now it's always 0.05.
Note that you can get random numbers straight from bash with $RANDOM. It's 15 bit (0 to 32767) but good enough here; this would get between 0.05 and 0.5: $(printf "0.%.4d\n" $((500 + RANDOM % 4501)))
By streetfighter64 2026-02-0420:311 reply Shouldn't $ROTATION be set inside the loop and actually used in the magick command?
By tombrossman 2026-02-0420:58 You know, now that you point it out that seems obvious. I think maybe I was experimenting with rotation and left that in, unused. I did this years ago. The loop works OK though. Thanks for the feedback (and now I have to finish editing that script ...)
By lordgrenville 2026-02-057:461 reply Nothing about this is specific to GNOME, right? Imagemagick is cross-platform
By turboponyy 2026-02-059:152 reply I guess the Gnome-specific part is that Gnome comes with the Nautilus file browser, and the instructions add a script for Nautilus.
But yea, this will work as long as you have imagemagick and Nautilus installed.
By lordgrenville 2026-02-059:50 Oh I missed that part, was just looking at the script
By landdate 2026-02-0515:46 or just run script and input pdf as argument...
By mimischi 2026-02-0515:17 I like https://lookscanned.io/
By taskforcegemini 2026-02-0520:34 you sound as grumpy as my cat looks. there's no need for this language
By landdate 2026-02-0516:02 [flagged]
The real question is: Which of the documents are the ones that are "simulating" scanned documents, and what political narrative do they reinforce?
The only reason I can think of for why someone would want to do this is to pass off fraudulent or AI generated images as real.
By boromisp 2026-02-0512:22 A simpler explanation could be wanting to skip the print->sign->scan ceremony required by some institutions.
By reactordev 2026-02-0510:25 This. Slip in a few thousand “fakes” with the trove of goods to be able to fabricate a narrative.
By lucideer 2026-02-0615:20 Another explanation is that it's simply one form of lazy ineffective obfuscation performed by inexperienced relative luddites in an attempt to walk the fine line between complying with the supreme court directive & not releasing anything useful.
Other investigations into the files have found oddities like redaction of the word "don't" indicating a haphazard find-&-replace approach to redaction, possibly LLM-aided.
The DOJ/Akamai online hosted search feature is also incomplete - potentially due to some of these "digitally scanned" files not being subject to OCR.
By lucideer 2026-02-0615:23 > to pass off fraudulent or AI generated images as real.
Possibly but I don't find it compelling, if only because a significant portion of the media reportage on the files has made claims that are entirely baseless - if there were a narrative to be sold one would expect such reportage to be actively leveraging such fraudulent images.
By streetfighter64 2026-02-0418:413 reply Very interesting. That document in particular seems to be an interview of A. Acosta by the DoJ from 2019. But what reason would the FBI have for pretending it's a scanned document, if it is genuine? Perhaps there's some aspect of Epstein's deal with Acosta that they'd rather not reveal to the public?
https://www.justice.gov/epstein/files/DataSet%207/EFTA000092...
Not that I can speak from personal experience or anything... But somebody on an email chain may have requested a scanned version of the document to ensure there is no metadata and the employee might have found it easier to just flatten the pdf and apply a graphical filter to make the document appear like a scanned document. There might even be a webtool available somewhere to do so, I wouldn't know...
By ThePowerOfFuet 2026-02-0421:27 Straight to the signup page? A bit blatant, no?
By mikkupikku 2026-02-0419:319 reply > the employee might have found it easier to just flatten the pdf and apply a graphical filter to make the document appear like a scanned document
Is that remotely plausible? I can't imaging faking a scan being easier than just walking down the hall to the copier room.
If I look at my personal work situation, working from home would mean I can't do it immediately, but would have to remember to do it the next day. Or just do it digitally right now in a few minutes and have it off my to-do list
Don't attribute to malice what can be attributed to laziness, these are government workers
By streetfighter64 2026-02-059:591 reply I think maybe the old "don't attribute to malice" adage goes out the window when we're talking about a coverup of a giant child sex trafficking ring run by high-up people in the government.
By sporkland 2026-02-0517:03 While I don't disagree with your point about Epstein case being a massive cya for a ton of people in power, the fact is that if they deeply wanted to cover up something the right way to do it would to be to actually print it and scan it, this does look like someone shortcutted some broad order to print and scan all digital media.
It's thousands of pages, surely investing some time in a script is faster. They were in a rush as well.
If they were faking the documents rather than the delivery method they definitely could have invested some time in flawless looks.
By smcnally 2026-02-0422:35 Or more-realistic flawed looks as the case is here.
By meinersbur 2026-02-0422:241 reply The time advantage of faking a scan becomes better the more pages you have to scan.
Nice. But 5 years seems unrealistic. Who stays on the same job using same processes 5 years these days? Even if the task might remain the same, input formats might change, requiring extra maintenance to the tool. Should recalculate that for 3 years before using it in my automation decisions.
By luplex 2026-02-058:12 you do not work in the public sector, where processes change rarely, slowly, and partially
By salynchnew 2026-02-0420:46 If it's already scanned, then you don't have to leave your desk.
By normie3000 2026-02-059:141 reply Working from home and no scanner in the house?
By ongy 2026-02-0511:37 No printer.
By juujian 2026-02-060:25 Look, what I'm saying is that I don't have a scanner at home or at work and I've find this.
By Spooky23 2026-02-0512:13 You’re talking about 1,000 FBI agents locked in a building. There’s no printer.
Depending on their technical capability, yes.
I mean even in this thread you got what are essentially one-liners to do it.
Definitely less hassle then doing it irl
By streetfighter64 2026-02-0420:491 reply Hoe big a percentage of FBI / DoJ employees are running linux (with imagemagick) as their work computer? I'd be surprised to see a similar oneliner for a stock windows installation.
Yeah they might have used some web converter, but that on the other hand would have been extremely incompetent handling of the secret data.
By 1718627440 2026-02-0516:23 Installing MSYS2 is a matter of a few minutes. There is also WSL and macOS features a POSIX shell, imagemagick is likely already installed as a dependency somewhere, like ffmpeg often also is.
By mikkupikku 2026-02-0421:583 reply I know I'm not the brightest bulb by any measure, but do some people really take less than at least a few minutes to come up with one-liners for problems as novel as graphical transformations to PDFs? Maybe if the presumed techie hacker / federal worker took it as an amusing challenge I could see this being done, but genuinely out of pure laziness? That's incredible if true.
By naniwaduni 2026-02-0422:52 It's not a novel problem. But yes, I don't think people quite appreciate how quick and easy it is for people who are in the habit of brewing up one-liners to solve simple problems to do that. I've done it here on HN for jq toy problems before, and I don't really doubt there are people similarly familiar with imagemagick.
By vlovich123 2026-02-056:50 It’s a mix of “they’ve done it many times before” and these days AI. But remember the “they’ve done it many times before” just means that in a technical and popular forum you’re likely to find the handful of people who have done so regularly enough to remember the one liner. Also this is probably easily searchable as well so even prior to AI not super hard.
By jeltz 2026-02-0514:26 There is nothing novel about it. I saw at least one person say that they have done exactly the same thing out of laziness.
By breppp 2026-02-0514:45 I am only guessing that they had to remove the document from a classified network in a way where data won't possibly leak
By draw_down 2026-02-0419:08 [dead]
Such a weird way to do it when it would be a vastly easier to just blow the document out to paper and re-scan it.
Vastly easier when you do it to one or a handful of documents.
But if you want to do it to 2000 documents...
By fc417fc802 2026-02-0516:27 But at that point why bother with the fakery? Why does it matter if it's obviously of digital origin? As long as it's rendered down to an image problem solved.
Was the motivation for this benign (an employee skirting regulations) or malicious?
By pbhjpbhj 2026-02-0512:20 4 reems (4×500) is hardly a lot for commercial equipment to handle - paper trays will take a reem at a time. Document analysis would still show some shenanigans were in play, but you'd get a bit of variation at least.
By userinexperienc 2026-02-0513:48 [dead]
By hiccuphippo 2026-02-0421:431 reply I mean, I do that all the time when they ask me to print something, sign it, and then scan it.
Sign a blank paper, scan it, paste the original doc on it. Then keep the scan for future docs.
By foxglacier 2026-02-056:52 An easier trick I've used is just sign directly on the computer screen over the displayed document with a whiteboard marker and take a photo with my phone.
Has anyone analysed JE's writing style and looked for matches in archived 4chan posts or content from similar platforms? Same with Ghislaine, there should be enough data to identify them atp right? I don't buy the MaxwellHill claims for various reasons but it doesn't mean there's nothing to find.
There was a post on here about a project in stylometry that analyzed HN users comment history. The tool helped find accounts that had an extremely similar writing style to a given account. The site was soon removed due to privacy concerns but many users with multiple account attested to its accuracy
https://news.ycombinator.com/item?id=33755016
It turns out stylometry is actually a pretty well-developed field. It makes me wanna write an AI browser assistant that can take my comments and stylize them randomly to make it harder to use these sorts of forensics against me
By DavidPeiffer 2026-02-054:431 reply >It makes me wanna write an AI browser assistant that can take my comments and stylize them randomly to make it harder to use these sorts of forensics against me
The old trick years ago was to translate from English to different language and back (possibly repeating). I'd be curious how helpful it is against stylometry detection?
By userbinator 2026-02-057:111 reply The old trick years ago was to translate from English to different language and back (possibly repeating). I'd be curious how helpful it is against stylometry detection?
If you want to be grouped with foreigners who don't know English, it might work well, although word choices may still be distinctive enough to differentiate even when translated.
Assuming the source language is English, going to a romance language and back wouldn't be too hard grammar wise, but could easily wipe out a lot of non-Latin-descended words if you use the right approach to translation.
By ted_bunny 2026-02-0614:16 "We are pretty sure the target is an Anglishman, which definitely narrows our field but maybe a bit too much."
By Cthulhu_ 2026-02-068:39 On the one side it's a shame this tool was removed because it's very interesting, but on the other hand, the main use case would likely abuse and (cyber)stalking.
That said, best to assume that the various government agencies have tools like this, and better - if you're trying to hide your identity online, don't just change users or go through VPNS/proxies/TOR but change your writing style too.
(Also I'm convinced most VPNs/ proxies / TOR nodes / public access points are honeypots)
By andai 2026-02-059:38 A while back the government claimed it had used stylometry to identify Satoshi Nakamoto.
By JoelMcCracken 2026-02-0513:50 I remember using one of these tools and it falsely identified some other account as being mine. Of course, I only have just this account.
By Der_Einzige 2026-02-0417:094 reply Stylometry is extremely sophisticated even with simple n-gram analysis. There's a demo of this that can easily pick out who you are on HN just based on a few paragraphs of your own writing, based on N-gram analysis.
https://news.ycombinator.com/item?id=33755016
You can also unironically spot most types of AI writing this way. The approaches based on training another transformer to spot "AI generated" content are wrong.
> You can also unironically spot most types of AI writing this way.
I have no idea if specialized tools can reliably detect AI writing but, as someone whose writing on forums like HN has been accused a couple of times of being AI, I can say that humans aren't very good at it. So far, my limited experience with being falsely accused is it seems to partly just be a bias against being a decent writer with a good vocabulary who sometimes writes longer posts.
As for the reliability of specialized tools in detecting AI writing, I'm skeptical at a conceptual level because an LLM can be reinforcement trained with feedback from such a tool (RLTF instead of RLHF). While they may be somewhat reliable at the moment, it seems unlikely they'll stay that way.
Unfortunately, since there are already companies marketing 'AI detectors' to academic institutions, they won't stop marketing them as their reliability continues to get worse. Which will probably result in an increasing shit show of false accusations against students.
By pcthrowaway 2026-02-051:391 reply > I can say that humans aren't very good at it
You're assuming the people making accusations of posts being written by AI are from humans (which I agree are not good at making this determination). However, computers analyzing massive datasets are likely to be much better at it , and this can also be a Werewolf/Mafia/Killers-type situation where AI frequently accuses posters it believes are human, of being AI, to diminish the severity of accusations and blend in better.
By ted_bunny 2026-02-0614:32 Are you impugning intent on the LLM's part?
By streetfighter64 2026-02-0420:39 Well, humans might be great at detecting AI (few false negatives) but might falsely accuse humans more often (higher false positive rate). You might be among a set of humans being falsely accused a lot, but that's just proof that "heuristic stylometry" is consistent, it doesn't really say anything about the size of that set.
By Cthulhu_ 2026-02-068:46 Thing is, people are on the lookout for obvious AI and I'm sure they have been successful a few times. But this is like confirmation bias, they will never know whether they saw / read something AI generated if they didn't clock it in the first place.
I'm on Reddit too much and a few times there were memes or whatever that were later on pointed out to be AI. And that's the ones that had tells, more and more (and as price goes down / effort/expenditure increases) it will become harder to impossible to tell.
And I have mixed feelings. I don't mind so much for memes, there's little difference between low-effort image editing and low-effort image generation IMO. There's the "advice" / "story" posts which for a long time now have been more of a creative writing effort than true stories, it's a race to the bottom already and AI will only try and accellerate it. But sometimes it's entertaining.
But "fake news" is the dangerous one, and I'm disappointed that combating this seemed to be a passing fad now that the big tech companies and their leaders / shareholders have bent the knee to regimes that are very interested in spreading disinformation/propaganda to push their agenda under people's skins subtly. I'm surprised it's not more egregious tbh, but maybe it's because my internet bubbles are aligned with my own opinions/morals/etc at the moment.
By queuebert 2026-02-0519:41 Another possibility is that you are actually an AI and don't know it.
By mikkupikku 2026-02-0419:33 Hacker News is one of the best places for this, because people write relatively long posts and generally try to have novel ideas. On 4chan, most posts are very short memey quips, so everybody's style is closer to each others than it is to their normal writing style.
By digiown 2026-02-0418:24 Funnily this also implies that laundering your writing through an AI is a good way to defeat stylometry. You add in a strong enough signal, and hopefully smooth out the rest.
By diamondage 2026-02-0417:21 Why are they wrong? Surely it depends on how you train it?
People always claimed this as a data leak vector but I've always been sceptical. Like just writing style and vocabulary is probably extremely shared among too many people to narrow it down much. (How people that you know could have written this reply?) The counter argument is that he had a very specific style in his mail so maybe this is a special case.
By Eisenstein 2026-02-0419:302 reply If you have a large enough set to test against and a specific person you are looking for, this is totally doable currently.
By fluoridation 2026-02-0420:143 reply Of course it's doable. The question is how reliable the results are.
By andai 2026-02-059:39 I wonder if it works on zoomers too. I have noticed a slight mode collapse among this population ;)
By Cthulhu_ 2026-02-068:40 Not to mention, I'd argue that most people have a (subtly?) different writing style depending on where they post and to who they talk to.
By ted_bunny 2026-02-0422:45 It just needs to find the needles in the haystack. Humans can better verify if they're truly needles.
By hansvm 2026-02-0423:01 Not just a test set, but enough of a set to search through and compare against. Several pages of in-depth writing isn't anywhere near sufficient, even when limiting the search space to ~10k people.
this is a well-studied field (stylometry). when combining writing styles, vocabulary, posting times, etc. you absolutely can narrow it down to specific people.
even when people deliberately try to feign some aspects (e.g. switching writing styles for different pseudonyms), they will almost always slip up and revert to their most comfortable style over time. which is great, because if they aren't also regularly changing pseudonyms (which are also subject to limited stylometry, so pseudonym creation should be somewhat randomized in name, location, etc.), you only need to catch them slipping once to get the whole history of that pseudonym (and potentially others, once that one is confirmed).
By scythe 2026-02-0423:04 Stylometry is okay if you're trying to deanonymize a large enough sample text. A reddit account would be doable. But individual 4chan posts? You barely have enough content within the text limit.
People do change over time, I used to write "ha" after every sentence for some reason
By wholinator2 2026-02-0421:271 reply You know, i had a particularly cringy period in which i put "la" at the end of sentences.
Don't throw the baby out with the bathwater. "Ooh, la" sounds really unnatural.
But on a serious note, what did "la" mean in your context? I've never seen this.
It’s a common thing for speakers of Singaporean English to end sentences with la/leh. But no idea if that’s what’s going on here.
By mchaver 2026-02-0511:33 In one use case, it is kind of a verbal exclamation point, but it has more meanings and uses than just that. Likely originates from Hokkien, but it has evolved into it is own thing. If you are curious, more details here https://en.wikipedia.org/wiki/Singlish
By nurettin 2026-02-056:48 In Turkish la at the end disrespectfully refers to a male person.
By Exoristos 2026-02-0421:08 You left off something.
By zxcvasd 2026-02-0421:23 sure, not denying that. my writing style is fairly different now in my 40s than it was in my late teens/early twenties.
but, those changes are usually pretty gradual and relatively small. thats why when attempting to identify someone via writing, you look at several aspects of the writing and not just word choice (grammar, use of specific slang, sentence length, paragraph structure, punctuation, etc.). it is highly unlikely that all aspects of someones writing changes at the same time. simply removing "ha" is inconsequential to identification if not much else changed.
additionally, this data is typically combined with other data/patterns (posting times, username (themes, length, etc.), writing that displays certain types of expertise, and more) to increase the confidence level of correct identification.
The writing style is rather interesting. Epstein seems borderline dyslexic, but almost none of the emails I've seen are written in a coherent way, regardless of the sender.
Either people on that level rarely write anything on their own and have completely forgotten how to construct proper sentences or maybe that just how they communicate. Sort of language internal to the group.
By ted_bunny 2026-02-0614:30 I had a boss who was too impatient to hear a full sentence most of the time, and respected absolutely no one. She typed like this.
I haven't looked at the files, nor followed the technical analysis much, but in case you missed it, some of that incoherency may be a processing glitch discussed a couple of days ago.
By mrweasel 2026-02-0517:33 Yeah, I saw that and no, that's not what I mean. Some of the conversations reads like incoherent ramblings, completely devoid of context, answers that seems unrelated. Even when we have a "full" thread of conversation, it's really hard to parse the messages and make sense of them. It sometimes read like maybe they have their own language.
Some people postes conversations, and comments, but I don't feel like they actually grasp what's being discused and they just latches on to key words.
> I don't buy the MaxwellHill claims for various reasons
Why not? Clear motive, matching timeline, mentions of that reddit account in the released FBI documents of her case
I was there for the original thread making the connection so I got a very fresh look at the profile. The user was consistently referring to being in dental school. A lot of posting, and not in ways that would influence opinions. Maybe a cover for more secretive mod actions, but it'd be a wastefully excessive cover.
Other mods knew them personally and were still in contact. The user claims they heard of the rumor and decided not to reactivate for the lulz.
I am not familiar with the mod side of reddit - couldn't fellow mods audit her mod action logs to find more juicy details we would have heard about by now?
If Maxwell is indeed a spy and doing what she is claimed to do, it is highly unlikely that she'd put her last name and a reference to her specific family's property in her username. This would be a glaringly arrogant choice for someone who had been groomed from an early age for spycraft, and who had any degree of oversight.
If she were part of a spy network, they would be highly remiss not to commandeer the account at the time of her arrest to avoid suspicion unless they were completely incompetent.
I am mostly familiar with cold war espionage so it just doesn't sound like the general MO to me. Unless Opsec or whatever has badly decayed since then. That's not impossible.
The mentions of the account in the files are from anonymous tips, some of which are highly absurd. They vetted a lot of tips, and I saw no information in the new releases indicating they thought it held water. We've seen the subpoena and IP tracking for the Epstein prison guard whistleblower, but no such thing on this topic.
By ted_bunny 2026-02-0711:26
I'm pretty sure Epstein tried to meet with moot at least once: https://www.jmail.world/search?q=chris+poole
He met with moot ("he is sensitive, be gentile", search on jmail), and within a few days the /pol/ board got created, starting a culture war in the US, leading to Trump getting elected president. Absolutely nuts.
Few thoughts: in context it's not nuts at all:
- moot was fundraising for his VC backed startup during the years the emails are in, and he was likely connected via mutuals in USV or other firms. These meetings were clearly around him trying to solicit investment in his canv.as project.
- /pol/ was /new/ being returned; the ethos of the board had already existed for a long time and the decision to undo the deletion of /new/ was entirely unsurprising for denizens at the time, and was consistent with a concerted push moot was making for more transparency in the enforcement of rules on the site and fairness towards users who followed the rules. /pol/ didn't start a culture war at this time any more than /new/ had previously - it just existed as a relatively content-unmoderated platform for people to discuss earnestly what would get them banned elsewhere.
By mikkupikku 2026-02-0419:35 Besides /new/ there was also /n/ (not at that time about transportation.) Moot's war with people being racist on 4chan had many back and forths before /pol/ was created.
Given the "nature" of 4chan (only a few hundred posts and a few thousand comments at a time, the vast majority of it shitposts and spam), it just can't do that. The imageboard format and limits basically prevent any scaling and mainstream success. If you follow any of the general threads in pol or sp for a while, you'll spot the same few people all the time, it's a tiny community of active users.
By thatguy0900 2026-02-0417:511 reply I think the logic is Pol didn't need to reach the masses, the masses only consume content they don't create it. You only need to radicalize the few people who then go on to be the 1% of people commenting and posting.
There's an old joke that 9gag* only reposts stuff from Reddit and Reddit only reposts stuff from 4chan and 4chan is the origin of all meme culture. This joke was widespread enough to reach myself and my friend group back in the day, even though none of used 4chan or Reddit.
If you radicalise the 0.01% of people who are prolific meme creators, you radicalise the masses.
* I did say old...
By direwolf20 2026-02-0422:04 And Facebook repeats stuff from 9gag
By acessoproibido 2026-02-0417:093 reply I always wondered how much of a cultural etc influence 4Chan actually had (has?) - so much of the mindset and vernacular that was popular there 10+ years ago is now completely mainstream.
By jazzyjackson 2026-02-0417:321 reply Ah, a rare opportunity to share a blog post that had a big effect on my political outlook back in 2016, Meme Magic Is Real, You Guys
Who can say what effect it had on the world, but a presidential candidate reposting himself personified as Pepe the frog was still weird back then, and at least a nod to the trolls doing so much work on his behalf
https://medium.com/tryangle-magazine/meme-magic-is-real-you-... (dismissable login wall)
By streetfighter64 2026-02-0420:44 Counterpoint: https://youtube.com/watch?v=r8Y-P0v2Hh0
Summary: Trump used memes not in the sense of pepes but in the original (Dawkins') sense of "earworm" soundbites, along with a torrent of scandals, each making the previous seem like old news, to exploit a public tired of the "status quo" into voting for a zany wildcard pushing for reactionary policy
By PlatoIsADisease 2026-02-0423:07 I remember in high school finding the whole nazi thing funny. They were literal losers in ww2. It was like drawing a communist hammer and sickle.
Looking back on it, I wonder if this was priming.
I didn't fall for it. They are still losers, but the encyclopedia dramatica with swastikas looks way way way less funny in 2026 than it did in 2008.
By thinkingemote 2026-02-058:45 Internet trolls want attention. When the internet gives trolls attention and said that the trolls are culturally and politically important and dangerous it is exactly what was desired.
That many serious commentators didn't see this was itself very funny as anything with lots of attention on the internet does become influential! It is funny to a troll to see people pay serious attention to them "I am just a clown and they think I'm serious!". But don't think that they were actual comedians, lol, they are as serious as HN users.
In the dawkins sense of the word: the "meme" wants to spread and grow and the mechanism for it's virality was the immune response to it.
On another angle, the responses also gave the target an identity. Groups get defined as groups from outside more than from within. And it's always a wrong characterisation which also helps define the in group in relation. "You guys are all toxic Linux dude bros" inside: "but some of us love macs and windows, and some of us are girls, they sure dont understand our ways"
/pol/ in no way started the American culture war. It was brewing for a while.
By _--__--__ 2026-02-0417:16 pol was made to contain all posting on the American culture war so it could be banned from the other (more active) boards
By actionfromafar 2026-02-0417:561 reply Well, broke the levee if you will. Otherwise, explain Pepe.
I hardly think an internet image of a cartoon frog heavily influenced American elections, despite a surface-level co-option by various Republican politicians.
By actionfromafar 2026-02-0418:09 I agree completely.
I'm just saying, it's a symptom. The crazy found critical mass, broke containment. From there it was laundered in millions of Facebook groups and here we are.
By WetMinister 2026-02-0418:501 reply You’re acting as if https://doge.gov does not exist. Ask yourself under which presidency, administration and kind of politics such is allowed to even exist with a straight face.
It would've existed regardless of internet memes, just under a different and similarly obnoxious name.
By whattheheckheck 2026-02-054:281 reply You actually think if we replayed society and magically shut off internet memes it would have played out the exact same but under a different name?
By GaryBluto 2026-02-0514:59 More or less, but it depends on what is classed as an internet meme.
By jahsome 2026-02-0417:16 In no way?
Just to substantiate this a bit: I remember a gleeful consensus in certain circles being that /pol/ and /r/the_donald had "memed Trump into the White House". It's much more complicated than that, but there's certainly an element of truth there.
By ZunarJ5 2026-02-0514:11 https://www.wired.com/story/dale-beran-it-came-from-somethin...
This is a good book about it.
Then Reddit and almost all of social media went on to purge trump and pro trump content. The Donald was banned. Trump deplatformed across social media.
That's true, but not really relevant to this discussion. You can't really deplatform a president; yes he was no longer on Twitter, but roughly 8 billion people listen any time he speaks.
By wiredpancake 2026-02-0423:44 [dead]
By plagiarist 2026-02-053:05 That subreddit was banned far too late. They had been urging for violence and hatred for quite some time. But action was taken only after the clowns inside of it were declaring they'd murder police officers executing a warrant (regarding legislators staying home to block quorum or whatever it was).
Of course in 2026 it is apparently fine to break into homes without a warrant and execute protesters. The same people are able to "believe" two literally opposite concepts.
By dashundchen 2026-02-054:49 2015 - 2016 reddit was exploited to hell by the_donald and other associated reddits. Things like coordinated up voting of a pinned post to get it to shoot up the front page, private chats to manipulate voting in a page.
There would be times when you would go to the r/all and half the page would be posts from them.
Not to mention a lot of the organized harassment a lot of the mods/power users of that sub caused in the years after. It was a mess.
Hey quick question, around January 2021, what would happened that caused Trump to be deplatformed? Anything stick out in your mind?
By agumonkey 2026-02-0515:06 As I see it, Trump was a symptom of something older.. no matter what effort were made to slow / avoid the issues, the mania was still growing.
I don’t agree with this analysis.
The reason I don’t agree is that moot banned any Gamergate discussion and those people then went to 8chan, a site which moot had no control over.
And it was Gamergate that put some fuel on the fire which (IMHO) increased support for Trump. The 8chan site grew a great deal from it, then continued from that first initial “win”.
By kmeisthax 2026-02-0418:42 From moot's perspective, it can be as simple as being convinced by some rich guy you've never heard of to bring back the politics board. He doesn't need to have an intent to start a fascist coup, that's Epstein's job. GamerGate is just the point at which moot realized he'd fucked up and destroyed 4chan imageboard culture by letting /pol/ fester.
Which meeting are you seeing? That search doesn't seem to work for me, I'm only seeing the one Jan 2012.
It doesn't show up in JMail for some reason, but it's this email: https://www.justice.gov/epstein/files/DataSet%2010/EFTA01852...
By kipchak 2026-02-0418:27 Thanks, trying to figure out the timeline relative to the board's creation given how close they are. The first email I can find related to a meeting is this one from Boris Nikolic on Oct 20th, with /pol/ on the 23rd.
https://www.justice.gov/epstein/files/DataSet%2010/EFTA01992...
By agumonkey 2026-02-0514:50 What is the theory here ? that Epstein suggested the idea of breeding extreme counter culture on 4chan ?
By acessoproibido 2026-02-0417:07 That is a crazy amount of emails from/about moot...
By whattheheckheck 2026-02-054:25 Created /pol/ for epstein himself https://bsky.app/profile/kaiserbeamz.bsky.social/post/3mdou7...
By yonatan8070 2026-02-0417:343 reply A bit off-topic, but I find it kinda funny that the "Decline" button on the cookie popup on this page is labled "Continue without consent".
By Paracompact 2026-02-0422:00 They're really trying to guilt trip you.
By marcd35 2026-02-0514:47 Proceed, but unwillingly
By direwolf20 2026-02-0422:04 Damn, so the website about the Epstein is Epstein too

{kind=link}