Anthropic's AI Fluency Index measures 11 observable behaviors across thousands of Claude.ai conversations to understand how people develop AI collaboration skills.
People are integrating AI tools into their daily routines at a pace that would have been difficult to predict even a year ago. But adoption alone doesn’t tell us much about the impact of these tools. A further, equally important question is: as AI becomes part of everyday life, are individuals developing the skills to use it well?
Previous Anthropic Education Reports have studied how university students and educators use Claude. We found that students use it to create reports and analyze lab results; educators use it to build lesson materials and automate routine work. But we know that any person who uses AI is likely to improve at what they do. We wanted to explore this further, and to understand how people using AI develop “fluency” with this technology over time.
In this report, we begin answering that question. We track the presence or absence of a taxonomy of behaviors that we take to represent AI fluency across a large sample of anonymized conversations.
In line with our recent Economic Index, we find that the most common expression of AI fluency is augmentative—treating AI as a thought partner, rather than delegating work entirely. In fact, these conversations exhibit more than double the number of AI fluency behaviors than quick, back-and-forth chats.
But we also find that when AI produces artifacts—including apps, code, documents, or interactive tools—users are less likely to question its reasoning (-3.1 percentage points) or identify missing context (-5.2pp). This aligns with related patterns we observed in our recent study on coding skills.
These initial findings present us with a baseline that we can use to study the development of AI fluency over time.
Measuring AI fluency
To quantify AI fluency, we use the 4D AI Fluency Framework, developed by Professors Rick Dakan and Joseph Feller in collaboration with Anthropic. This framework helps us define 24 specific behaviors that we take to exemplify safe and effective human-AI collaboration.
Of these 24 behaviors, 11 (listed in the graph below) are directly observable when humans interact with Claude on Claude.ai or Claude Code. The other 13 (including things like being honest about AI’s role in work, or considering the consequences of sharing AI-generated output), happen outside Claude.ai’s chat interface, so they’re much harder for us to track. These unobservable behaviors are arguably some of the most consequential dimensions of AI fluency, so in future work we plan to use qualitative methods to assess them.
For this study, we focused on the 11 directly observable behaviors. We used our privacy-preserving analysis tool to study 9,830 conversations that included several back-and-forths with Claude on Claude.ai during a 7-day window in January 2026.1 We then measured the presence or absence of the 11 behaviors; each conversation could display evidence of multiple behaviors. We assessed the reliability of our sample by checking whether our results were consistent across each day of the week, and across the different languages in our sample (we found that they were).2 This, finally, gave us the AI Fluency Index: a baseline measurement of how people collaborate with AI today, and a foundation for tracking how those behaviors evolve over time as models change.
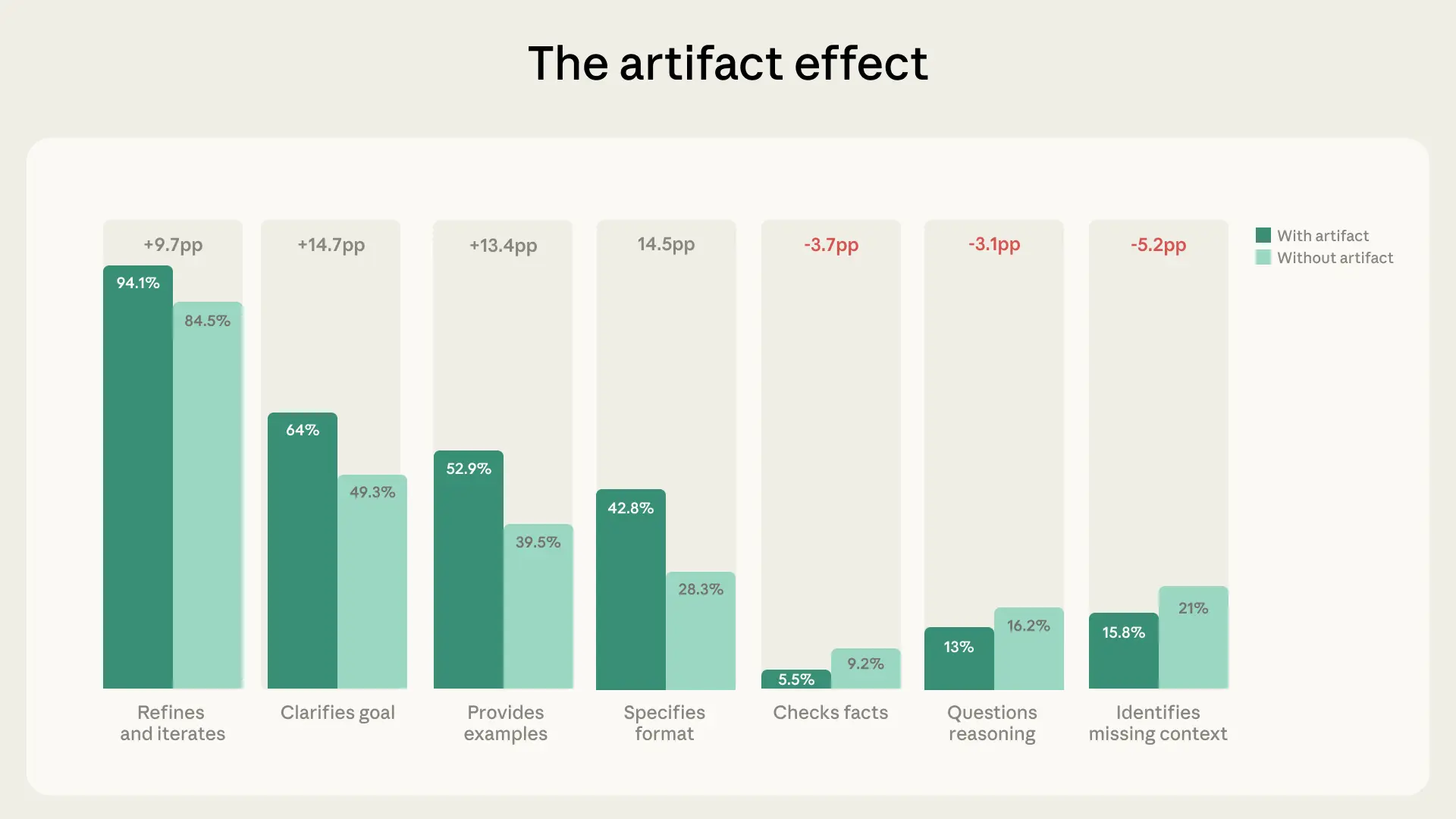
There are several possible explanations for this pattern. It might be that Claude is creating polished, functional-looking outputs, for which it doesn’t seem necessary to question things further: if the work looks finished, users might treat it as such. But it’s also possible that artifact conversations involve tasks where factual precision matters less than aesthetics or functionality (designing a UI, for instance, versus writing a legal analysis). Or users might be evaluating artifacts through channels we can’t observe—running code, testing an app elsewhere, sharing a draft with a colleague—rather than expressing their evaluation within that same initial conversation.
Whatever the explanation, the pattern is worth paying attention to. As AI models become increasingly capable of producing polished-looking outputs, the ability to critically evaluate those outputs, whether in direct conversation or through other means, will become more valuable rather than less.
Developing your own AI fluency
| As with all skills, AI fluency is a matter of degree—for most of us, it’s possible to develop our techniques much further. Based on the patterns in our data, there are three areas where we’ve found many users could improve their skills: |
|---|
| Staying in the conversation. Iteration and refinement is the single strongest correlate of all other fluency behaviors in our data. So, when you get an initial response, it’s worth treating it as only a starting point: ask follow-up questions, push back on any parts that don’t feel right, and refine what you’re looking for. |
| Questioning polished outputs. When AI models produce something that looks good, it’s the perfect moment to pause and ask: is this accurate? Is anything missing? Does this reasoning hold up? As we discussed above, our data show that polished outputs coincide with lower rates of critical evaluation, even though users go to greater lengths to direct Claude’s work at the outset. |
| Setting the terms of the collaboration. In only 30% of conversations do users tell Claude how they’d like it to interact with them. Try being explicit by adding instructions like, “Push back if my assumptions are wrong,” “Walk me through your reasoning before giving me the answer,” or, “Tell me what you’re uncertain about.” Establishing these expectations up front can change the dynamic of the rest of the conversation. |
Limitations
This research comes with important caveats:
- Sample limitations: Our sample reflects Claude.ai users who engaged in multi-turn conversations during a single week in January 2026. Since we think this is still relatively early on in the diffusion of AI tools, these users likely skew towards early adopters who are already comfortable with AI—i.e., who may not represent the broader population. Our sample should be understood as providing a baseline for this population, not as a universal benchmark. Because the data comes from a single week, it is also unable to capture any seasonal or longitudinal effects. And because it’s focused on Claude.ai, we don’t capture how users interact with other AI platforms.
- Partial framework coverage: In this study, we only assessed the 11 of the 24 behavioral indicators that are directly observable in conversations on Claude.ai. All behaviors related to the responsible and ethical use of AI outputs occur outside of these conversations, and are not captured.
- Binary classification: For each conversation in our sample, we classify each behavior as either present or absent. But this likely misses significant nuance—like arguable or partial demonstrations of behaviors, or overlapping signals between them.
- Implicit behaviors: Users might demonstrate fluency behaviors mentally (such as fact-checking Claude’s claims against their own knowledge) without expressing these behaviors in conversation. This seems especially relevant for our data on artifacts—users might be evaluating Claude’s outputs through testing and practical use, rather than through conversation-visible behaviors.
- Correlational findings: The relationships we identify are correlational. We don’t know whether one behavior causes another, or whether they both reflect some common underlying factor, like task complexity or user preferences.
This study offers us a baseline that we can use to assess how AI fluency is changing over time. As AI capabilities evolve and adoption increases, we’re aiming to learn whether users are developing more sophisticated behaviors, which skills are emerging naturally with experience, and which will require more intentional development.
In future work, we plan to extend our analysis in several directions. First, we plan to conduct “cohort analyses,” comparing new users to experienced ones in order to understand how familiarity with AI is correlated with fluency development. Second, we plan to use qualitative research methods to assess the behaviors that aren’t directly observable in Claude.ai conversations. And third, we aim to explore the causal questions that this work raises—like whether encouraging iterative conversations leads to greater critical evaluation, or whether there are other interventions that could encourage this more effectively.
In addition, we’d like to explore AI fluency behaviors in Claude Code, a platform mostly used by software developers. In preparation for this study, we conducted some initial analysis that found consistency between Claude Code conversations and ones in Claude.ai. But this is still preliminary, and Claude Code’s very different user base and functionality implies that more substantial research is necessary.
We expect that the nature of AI fluency will develop and evolve substantially over time. With this and future research, we’re aiming to make that development visible, measurable, and actionable.
Bibtex
If you’d like to cite this post, you can use the following Bibtex key:
@online{swanson2026aifluency,
author = {Kristen Swanson, Drew Bent, Saffron Huang and Zoe Ludwig and Rick Dakan and Joe Feller},
title = {Anthropic Education Report: The AI Fluency Index},
date = {2026-02-16},
year = {2026},
url = {https://www.anthropic.com/news/anthropic-education-report-the-ai-fluency-index},
}Acknowledgements
Kristen Swanson designed the research, led the analysis, and wrote this report. Zoe Ludwig, Saffron Huang, and Drew Bent contributed to framework alignment, messaging, and review. The 4D Framework for AI Fluency was developed by Rick Dakan and Joe Feller. Zack Lee provided technical support. Hanah Ho helped visualize the data. Keir Bradwell, Rebecca Hiscott, Ryan Donegan and Sarah Pollack provided communications review and guidance.
Read the original article
Comments
> But we know that any person who uses AI is likely to improve at what they do.
Do we?
I could have sworn there was research that stated the more you use these tools the quicker your skills degrade, which honestly feels accurate to me and why I've started reading more technical books again.
By rkomorn 2026-02-2320:01 > I've started reading more technical books again
How's that working out for you in the context of working with AI tools? Do you feel like it's helping you make better use of them? Or keeping your mind sharp?
I've been considering getting some books on core topics I haven't (re)visited in a long time to see if not having to write as much code anymore instead gives me time to (re)learn more and accelerate.
By fatherwavelet 2026-02-2323:21 I just don't understand how someone can have these models at their disposal not learn anything?
The general lack of intellectual curiosity is just mind blowing to me.
By dsr_ 2026-02-2318:31 Not until large-N research is done without sponsorship, support, or veiled threats from AI companies.
At which point, if the evidence turns out to be negative, it will be considered invalid because no model less recent than November 2027 is worth using for anything. If the evidence turns out to be slightly positive, it will be hailed as the next educational paradigm shift and AI training will be part of unemployment settlements.
By poszlem 2026-02-2319:00 I would even say it's likely the opposite. My output as a programmer is now much higher than before, but I am losing my programming skills with each use of claude code.
Let me add a single data point.
> is likely to improve at what they do
personally, my skills are not improving.
professionally, my output is increased
By mobattah 2026-02-2318:52 My software development skillset has improved. I’m learning and stress testing new patterns that would have taken far longer pre-AI. I’m also working in new domains and tech stacks that would have taken me much longer to get up to speed on.
People who use AI mindfully and actively can possibly improve.
The olden days of buidling skills and competencies are largely dying or dead when the skills and competencies are changing faster than skills and competency training ever intended to.
If things change fast, learning becomes even more important. And learning about the principles that don't change becomes most important of all.
By j45 2026-02-240:32 Yup, continuous learning, the principles that don't change are in part identified and part still coming to the forefront.
By selridge 2026-02-2319:32 We DEEPLY do not.
That's not, IMO, a "skills go down" position. It's respecting that this is a bigger maybe than anyone in living memory has encountered.
Clearly this means Anthropic believes this but would be nice to have a footnote pointing to research backing this claim.
By amelius 2026-02-2321:25 It is also not very convincing considering that while the UI of Claude is not bad it is also not exactly stellar.
By rishabhaiover 2026-02-2318:363 reply As a student, I constantly worry about this. But everyone in my class is producing output at a pace I can't compete with without AI assistance.
what class are you in that "producing output at a [rapid] pace" is relevant to the grade?
By rishabhaiover 2026-02-2318:533 reply pick any cs class
By Avshalom 2026-02-2318:55 I have a minor in CS and no -producing the assignment by the deadline is important- grades are not based on quantity of code vs classmates.
I mean, maybe things have changed (I finished college about 20 years ago), but I don't remember producing large volumes of stuff as being a particularly important part of a CS degree.
By rishabhaiover 2026-02-2319:251 reply Between a challenging job market, increasing new frontiers of learning (AI, MLops, parallel hardware) and an average mind like mine, a tool that increases throughput is likely to be adopted by masses, whether you like it or not and quality is not a concern for most, passing and getting an A is (most of my professors actively encourage to use LLMs for reports/code generation/presentations)
By plastic-enjoyer 2026-02-2319:583 reply It will be a very interesting experiment when your generation of computer science graduates enters the job market, to put it mildly.
By rishabhaiover 2026-02-2321:291 reply Individuals believe they act freely, but they are constrained and directed by historical forces beyond their awareness - Leo Tolstoy
Historical forces beyond your awareness cannot force you to submit mountains of slop.
By rishabhaiover 2026-02-2418:552 reply slop is not a thing anymore, stop living in a fantasy world
By andai 2026-02-2413:00 The last one already killed unique web designs, killed flash, gave us us soulless flat design and electron bloat.
They'll have to work pretty hard to outdo that!
By lawn 2026-02-2319:02 That was never a worry in any of my CS classes.
By theappsecguy 2026-02-2319:301 reply Copying AI slop isn’t producing output! It’s also not conducive to learning
By fatherwavelet 2026-02-2323:252 reply As if you are just a such a genius the models are of no use to you.
How can you not think that makes you sound like a complete moron?
By theappsecguy 2026-02-2618:51 I would urge you to leverage some critical thinking, re-read what I stated, and identify where I said that the models are of no use to me. If the ability to think for yourself without AI assistance hasn't fully atrophied on your end you may be able to see that you are the moron in this thread.
By SubmarineClub 2026-02-2417:25 I guess I really am just that much smarter than you.
By co_king_5 2026-02-2319:52 [dead]
By Insanity 2026-02-2318:24 Yah and this seems to be supported by preliminary evidence on the impact of AI on things like retention and cognitive ability.
By wasmainiac 2026-02-2322:52 Not even just skills, motivation too.
So I guess the key takeaway is basically that the better Claude gets at producing polished output, the less users bother questioning it. They found that artifact conversations have lower rates of fact-checking and reasoning challenges across the board. That's kind of an uncomfortable loop for a company selling increasingly capable models.
> the less users bother questioning it
This makes me think of checklists. We have decades of experience in uncountable areas showing that checklists reminding users to question the universe improve outcomes: Is the chemical mixture at the temperature indicated by the chart? Did you get confirmation from Air Traffic Control? Are you about to amputate the correct limb? Is this really the file you want to permanently erase?
Yet our human brains are usually primed to skip steps, take shortcuts, and see what we expect rather than what's really there. It's surprisingly hard to keep doing the work both consistently and to notice deviations.
> lower rates of fact-checking and reasoning challenges
Now here we are with LLMs, geared to produce a flood of superficially-plausible output which strikes at our weak-point, the ability to do intentional review in a deep and sustained way. We've automated the stuff that wasn't as-hard and putting an even greater amount of pressure on the remaining bottleneck.
Rather than the old definition involving customer interaction and ads, I fear the new "attention economy" is going to be managing the scarce resource of human inspection and validation.
By jimbokun 2026-02-2319:59 Sounds like having a strong checklist of steps to take for every pull request will be crucial for creating reliable and correct software when AIs write most of the code.
But the temptation to short change this step when it becomes the bottleneck for shipping code will become immense.
By boplicity 2026-02-2319:35 > So I guess the key takeaway is basically that the better Claude gets at producing polished output, the less users bother questioning it.
This is exactly what I worry about when I use AI tools to generate code. Even if I check it, and it seems to work, it's easy to think, "oh, I'm done." However, I'll (often) later find obvious logical errors that make all of the code suspect. I don't bother, most of the time though.
I'm starting to group code in my head by code I've thoroughly thought about, and "suspect" code that, while it seems to work, is inherently not trustworthy.
By Florin_Andrei 2026-02-2318:093 reply I think we're still at the stage where model performance largely depends on:
- how many data sources it has access to
- the quality of your prompts
So, if prompting quality decreases, so does model performance.
By dmk 2026-02-2318:15 Sure, but the study is saying something slightly different, it's not that people write bad prompts for artifacts, they actually write better ones (more specific, more examples, clearer goals,...). They just stop evaluating the result. So the input quality goes up but the quality control goes down.
Seems like it’s impossible for output to be good if the prompt is bad. Unless the AI is ignoring the literal instructions and just guessing “what you really want” which would be bad in a different way.
By AnIrishDuck 2026-02-2320:34 > On two occasions I have been asked, — "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" In one case a member of the Upper, and in the other a member of the Lower, House put this question. I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question.
- Charles Babbage, https://archive.org/details/passagesfromlife03char/page/67/m...
EDIT: This is a new iteration of an old problem. Even GIGO [1] arguably predates computers and describes a lot of systemic problems. It does seem a lot more difficult to distinguish between a "garbage" or "good" prompt though. Perhaps this problem is just going to keep getting harder.
By candiddevmike 2026-02-2318:321 reply What does prompting quality even mean, empirically? I feel like the LLM providers could/should provide prompt scoring as some kind of metric and provide hints to users on ways they can improve (possibly including ways the LLM is specifically trained to act for a given prompt).
By dsr_ 2026-02-2318:33 That would be a quality metric, and right now they are focused on quantity metrics.
By lukev 2026-02-2320:22 This is a highly circular method of evaluation. It correlates "fluency behaviors" with longer conversations and more back and forth.
What it notably does not correlate any of these these behaviors with is external value or utility.
It is entirely possible that those people who are getting the most value out of LLMs are the ones with shorter interactions, and that those who engage in lengthier interactions are distracting themselves, wasting time, or chasing rabbit trails (the equivalent of falling in a wiki-hole, at the most charitable.)
I can't prove that either -- but this data doesn't weigh in one way or the other. It only confirms that people who are chatty with their LLMs are chatty with their LLMs.
In my own case, I find the longer I "chat" with the LLM the more likely I am to end up with a false belief, a bad strategy, or some other rabbit hole. 90% of the value (in my personal experience) is in the initial prompt, perhaps with 1-2 clarifying follow-ups.
