
Today, we're introducing Mercury 2 — the world's fastest reasoning language model, built to make production AI feel instant.
Today, we're introducing Mercury 2 — the world's fastest reasoning language model, built to make production AI feel instant.
Why speed matters more now
Production AI isn't one prompt and one answer anymore. It's loops: agents, retrieval pipelines, and extraction jobs running in the background at volume. In loops, latency doesn’t show up once. It compounds across every step, every user, every retry.
Yet current LLMs still share the same bottleneck: autoregressive, sequential decoding. One token at a time, left to right.
A new foundation: Diffusion for real-time reasoning
Mercury 2 doesn't decode sequentially. It generates responses through parallel refinement, producing multiple tokens simultaneously and converging over a small number of steps. Less typewriter, more editor revising a full draft at once. The result: >5x faster generation with a fundamentally different speed curve.
That speed advantage also changes the reasoning trade-off. Today, higher intelligence means more test-time compute — longer chains, more samples, more retries — bought at the direct expense of latency and cost. Diffusion-based reasoning gets you reasoning-grade quality inside real-time latency budgets.
Mercury 2 at a glance
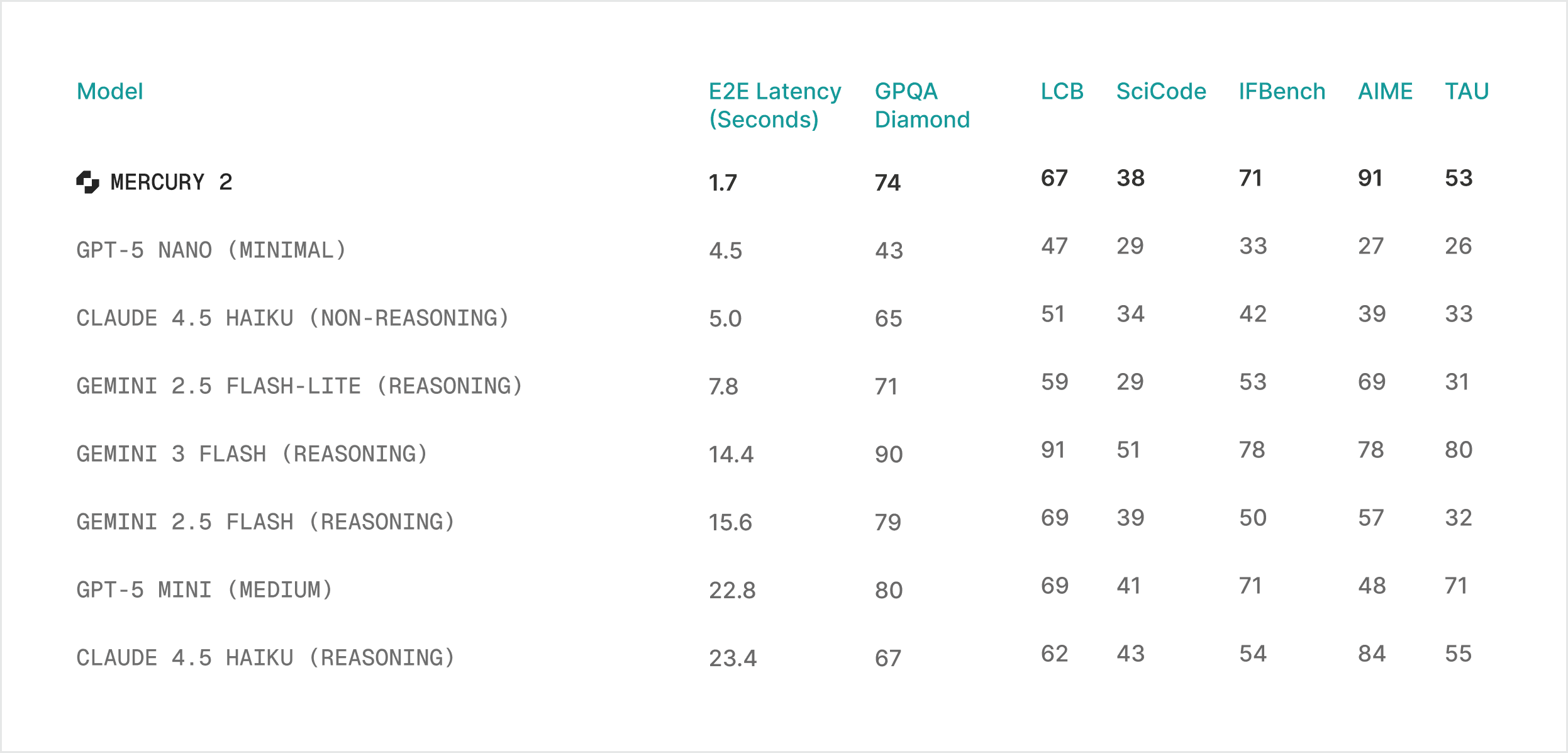
Mercury 2 shifts the quality-speed curve for production deployments:
Speed: 1,009 tokens/sec on NVIDIA Blackwell GPUs
Price: $0.25/1M input tokens · $0.75/1M output tokens
Quality: competitive with leading speed-optimized models
Features: tunable reasoning · 128K context · native tool use · schema-aligned JSON output
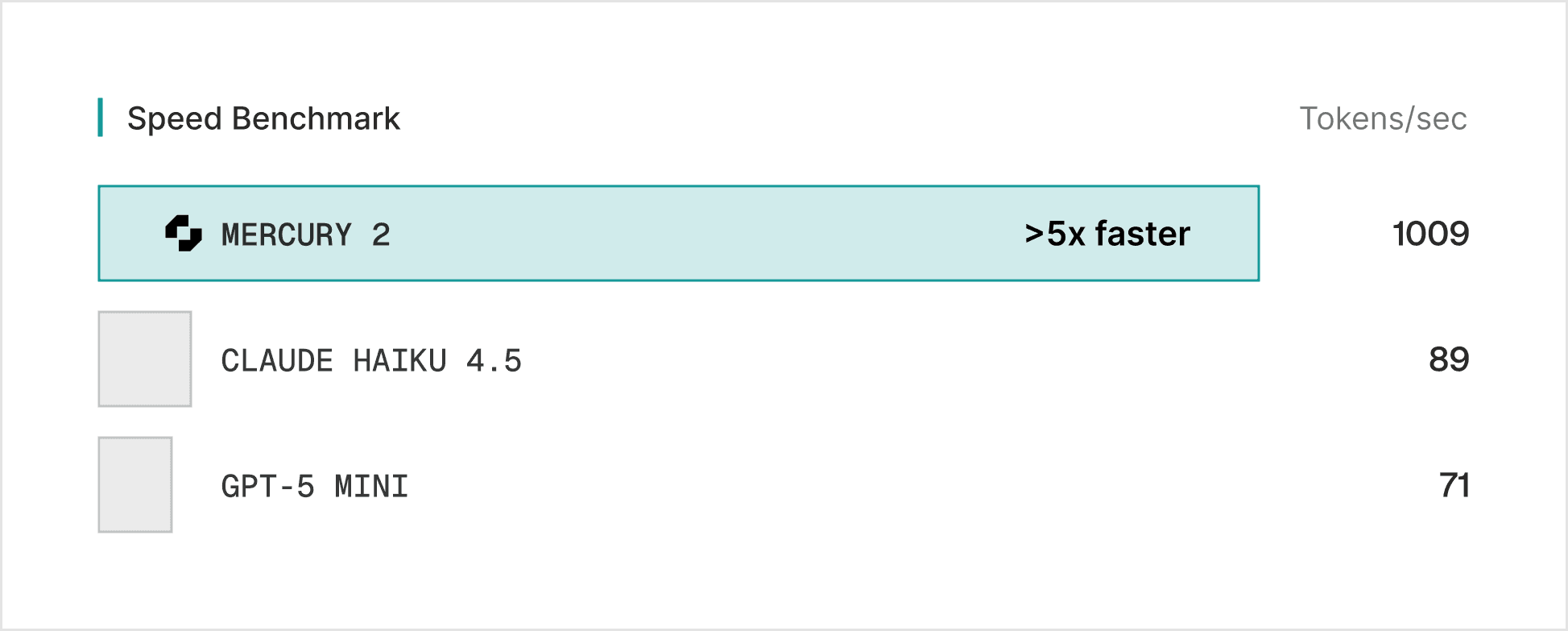
We optimize for speed users actually feel: responsiveness in the moments users experience - p95 latency under high concurrency, consistent turn-to-turn behavior, and stable throughput when systems get busy.
“Inception’s Mercury 2 demonstrates what’s possible when new model architecture meets NVIDIA AI infrastructure. Surpassing 1,000 tokens per second on NVIDIA GPUs underscores the performance, scalability, and versatility of our platform to power the full spectrum of AI workloads.”
Shruti Koparkar, Senior Manager of Product, Accelerated Computing Group at NVIDIA
What Mercury 2 unlocks in production
Mercury 2 excels in latency-sensitive applications where the user experience is non-negotiable.
1. Coding and editing
Autocomplete, next-edit suggestions, refactors, interactive code agents - workflows where the developer is in the loop and any pause breaks flow.
“Suggestions land fast enough to feel like part of your own thinking, not something you have to wait for.”
Max Brunsfeld, Co-Founder, Zed
2. Agentic loops
Agentic workflows chain dozens of inference calls per task. Cutting latency per call doesn't just save time, it changes how many steps you can afford to run, and how good the final output gets.
“We’re now leveraging the latest Mercury model to intelligently optimize campaign execution at scale. By surfacing insights and dynamically enhancing delivery in real time, we’re driving stronger performance, greater efficiency, and a more resilient, AI-powered advertising ecosystem. This advancement reinforces our commitment to autonomous advertising, where intelligent systems continuously refine execution to deliver measurable outcomes for our clients.”
Adrian Witas, SVP, Chief Architect, Viant
“We’ve been evaluating Mercury 2 because of its unparalleled latency and quality, especially valuable for real time transcript cleanup and interactive HCI applications. No other model has come close to the speed Mercury can provide!”
Sahaj Garg, CTO & Co-Founder, Wispr Flow
"Mercury 2 is at least twice as fast as GPT-5.2, which is a game changer for us."
Suchintan Singh, CTO & Co-Founder, Skyvern
3. Real-time voice and interaction
Voice interfaces have the tightest latency budget in AI. Mercury 2 makes reasoning-level quality viable within natural speech cadences.
“We build lifelike AI video avatars that hold real-time conversations with real people, so low latency isn't a nice-to-have, it's everything. Mercury 2 has been a big unlock in our voice stack: fast, consistent text generation that keeps the whole experience feeling natural and human.”
Max Sapo, CEO & Co-Founder, Happyverse AI
“Mercury 2 quality is excellent, and the model’s low latency enables more responsive voice agents.”
Oliver Silverstein, CEO & Co-Founder, OpenCall
4. Search and RAG pipelines
Multi-hop retrieval, reranking, and summarization latencies stack fast. Mercury 2 lets you add reasoning to the search loop without blowing your latency budget.
“Our partnership with Inception makes real-time AI for our search product practical. Every SearchBlox customer, across customer support, compliance, risk, analytics, and e-commerce, benefits from sub-second intelligence across all of their data.”
Timo Selvaraj, Chief Product Officer, SearchBlox
Get started
Mercury 2 is available now.
Mercury 2 is OpenAI API compatible. Drop into your existing stack - no rewrites required.
If you’re doing an enterprise evaluation, we’ll partner with you on workload fit, eval design, and performance validation under your expected serving constraints.
Mercury 2 is live. Welcome to diffusion.
Read the original article
Comments
It could be interesting to do the metric of intelligence per second.
ie intelligence per token, and then tokens per second
My current feel is that if Sonnet 4.6 was 5x faster than Opus 4.6, I'd be primarily using Sonnet 4.6. But that wasn't true for me with prior model generations, in those generations the Sonnet class models didn't feel good enough compared to the Opus class models. And it might shift again when I'm doing things that feel more intelligence bottlenecked.
But fast responses have an advantage of their own, they give you faster iteration. Kind of like how I used to like OpenAI Deep Research, but then switched to o3-thinking with web search enabled after that came out because it was 80% of the thoroughness with 20% of the time, which tended to be better overall.
I think there's clearly a "Speed is a quality of it's own" axis. When you use Cereberas (or Groq) to develop an API, the turn around speed of iterating on jobs is so much faster (and cheaper!) then using frontier high intelligence labs, it's almost a different product.
Also, I put together a little research paper recently--I think there's probably an underexplored option of "Use frontier AR model for a little bit of planning then switch to diffusion for generating the rest." You can get really good improvements with diffusion models! https://estsauver.com/think-first-diffuse-fast.pdf
By refulgentis 2026-02-252:417 reply I'm very worried for both.
Cerebras requires a $3K/year membership to use APIs.
Groq's been dead for about 6 months, even pre-acquisition.
I hope Inception is going well, it's the only real democratic target at this. Gemini 2.5 Flash Lite was promising but it never really went anywhere, even by the standards of a Google preview
Taalas is interesting. 16,000 TPS for Llama on a chip.
Llama 3.1 8B is pretty useful for some thing. I use it to generate SQL pretty reliably for example.
They are doing an updated model in a month or so anyway, then a frontier level one "by summer".
By numeri 2026-02-2515:24 but Taalas had to quantize Llama 3.1 8B to death to get it to fit. It can't produce coherent non-English text at all.
I do wonder if there are tasks where 16k garbage words/s are more useful than 200 good words per second. Does anyone have any ideas? Data extraction perhaps?
By pnocera 2026-02-2519:45 A politician communication agent maybe...
By Nihilartikel 2026-02-2512:411 reply Neat! I had been wondering if anyone was trying to implement a model in silico. We're getting closer to having chatty talking toasters every day now!
"What is my purpose..."
By Nihilartikel 2026-02-2820:19 Even more on the nose: https://youtu.be/LRq_SAuQDec?si=CAe210GZ_lKcc6_Y
By DeathArrow 2026-02-256:07 I wonder how many token per seconds can they get if they put Mercury 2 on a chip.
By replete 2026-02-257:29 Its exciting to see, but look at the die size for only an 8b model
You can call Cerebras APIs via OpenRouter if you specify them as the provider in your request fyi. It's a bit pricier but it exists!
By andai 2026-02-253:57 I used their API normally (pay per token) a few weeks ago. Their Coding Plan appears to be permanently sold out though.
I don't think it's a good comparison given Inception work on software and Cerebras/Groq work on hardware. If Inception demonstrate that diffusion LLMs work well at scale (at a reasonable price) then we can probably expect all the other frontier labs to copy them quickly, similarly to OpenAI's reasoning models.
By refulgentis 2026-02-253:12 Definitely depends on what you're buying, maybe some of the audience here was buying Groq and Cerebras chips? I don't think they sold them but can't say for sure.
If you're a poor schmoke like me, you'd be thinking of them as API vendors of ~1000 token/s LLMs.
Especially because Inception v1's been out for a while and we haven't seen a follow-the-leader effect.
Coincidentally, that's one of my biggest questions: why not?
What do you mean by Grow is dead since about 6 months ago? Not refuting your point, but I’m curious.
By refulgentis 2026-02-253:081 reply No new model since GPT-OSS 120B, er maybe Kimi K2 not-thinking? Basically there were a couple models it normally obviously support, and it didn't.
Something about that Nvidia sale smelled funny to me because the # was yuge, yet, the software side shut down decently before the acquisition.
But that's 100% speculation, wouldn't be shocked if it was:
"We were never looking to become profitable just on API users, but we had to have it to stay visible. So, yeah, once it was clear an Nvidia sale was going through, we stopped working 16 hours a day, and now we're waiting to see what Nvidia wants to do with the API"
By vessenes 2026-02-2515:31 The groq purchase was designed to not trigger federal oversight of mergers, so you buy out the ‘interesting’ part, leave a skeleton team and a line of business you don’t care about -> no CFIUS, no mandatory FTC reporting -> smoother process.
By estsauver 2026-02-253:32 I am currently using their APIs on a paygo plan, I think it might just be a capacity issue for new sign ups.
By Leynos 2026-02-259:06 Cerebras are on OpenRouter.
Once again, it's a tech that Google created but never turned into a product. AFAIK in their demo last year, Google showed a special version of Gemini that used diffusion. They were so excited about it (on the stage) and I thought that's what they'd use in Google search and Gmail.
By refulgentis 2026-02-2622:33 Google did not create it; it is correct there was a Gemini that used diffusion, you could apply for access (not via API). It was okay
We agree! In fact, there is an emerging class of models aimed at fast agentic iteration (think of Composer, the Flash versions of proprietary and open models). We position Mercury 2 as a strong model in this category.
By estsauver 2026-02-253:39 Do you guys all think you'll be able to convert open source models to diffusion models relatively cheaply ala the d1 // LLaDA series of papers? If so, that seems like an extremely powerful story where you get to retool the much, much larger capex of open models into high performance diffusion models.
(I can also see a world where it just doesn't make sense to share most of the layers/infra and you diverge, but curious how you all see the approach.)
Maybe make that intelligence per token per relative unit of hardware per watt. If you're burning 30 tons of coal to be 0.0000000001% better than the 5 tons of coal option because you're throwing more hardware at it, well, it's not much of a real improvement.
By estsauver 2026-02-253:44 I think the fast inference options have historically been only marginally more expensive then their slow cousins. There's a whole set of research about optimal efficiency, speed, and intelligence pareto curves. If you can deliver even an outdated low intelligence/old model at high efficiency, everyone will be interested. If you can deliver a model very fast, everyone will be interested. (If you can deliver a very smart model, everyone is obviously the most interested, but that's the free space.)
But to be clear, 1000 tokens/second is WAY better. Anthropic's Haiku serves at ~50 tokens per second.
By jakubtomanik 2026-02-2510:18 Intelligence per second is a great metric. I never could fully articulate why I like Gemini 3 Flash but this is exactly why. It’s smart enough and unbelievably fast. Thanks for sharing this
Yeah I agree with this. We might be able to benchmark it soon (if we can’t already) but asking different agentic code models to produce some relatively simple pieces of software. Fast models can iterate faster. Big models will write better code on the first attempt, and need less loop debugging. Who will win?
At the moment I’m loving opus 4.6 but I have no idea if its extra intelligence makes it worth using over sonnet. Some data would be great!
For what it's worth, most people already are doing this! Some of the subagents in Claude Code (Explore, I think even compaction) default to Haiku and then you have to manually overwrite it with an env variable if you want to change it.
Imagine the quality of life upgrade of getting compaction down to a few second blip, or the "Explore" going 20 times faster! As these models get better, it will be super exciting!
By embedding-shape 2026-02-259:44 > Imagine the quality of life upgrade of getting compaction down to a few second blip, or the "Explore" going 20 times faster! As these models get better, it will be super exciting!
I'm awaiting the day the small and fast models come anywhere close to acceptable quality, as of today, neither GPT5.3-codex-spark nor Haiku are very suitable for either compaction or similar tasks, as they'll miss so much considering they're quite a lot dumber.
Personally I do it the other way, the compaction done by the biggest model I can run, the planning as well, but then actually following the step-by-step "implement it" is done by a small model. It seemed to me like letting a smaller model do the compaction or writing overviews just makes things worse, even if they get a lot faster.
By jmvldz 2026-02-2720:09 The explore step with Codex-5.3-Spark and Opus 4.6 Fast both feel incredible.
By nubg 2026-02-251:22 Interesting perspective. Perhaps also the user would adopt his queries knowing he can only to small (but very fast) steps. I wonder who would win!
By jdthedisciple 2026-02-256:14 Interesting suggestion.
Maybe we could use some sort of entropy-based metric as a proxy for that?
By dmichulke 2026-02-255:02 Useful for evaluating people as well
By irishcoffee 2026-02-2513:57 I really thought this was sarcasm. Intelligence per token? Intelligence at all, in a token? We don’t even agree on how to measure _human_ intelligence! I just can’t. Artificially intelligent indeed. Probably the perfect term for it, you know in lieu of authentic intelligence.
picard_facepalm.jpg
Co-founder / Chief Scientist at Inception here. If helpful, I’m happy to answer technical questions about Mercury 2 or diffusion LMs more broadly.
By nowittyusername 2026-02-252:391 reply How does the whole kv cache situation work for diffusion models? Like are there latency and computation/monetary savings for caching? is the curve similar to auto regressive caching options? or maybe such things dont apply at all and you can just mess with system prompt and dynamically change it every turn because there's no savings to be had? or maybe you can make dynamic changes to the head but also get cache savings because of diffusion based architecture?... so many ideas...
By volodia 2026-02-252:48 There are many ways to do it, but the simplest approach is block diffusion: https://m-arriola.com/bd3lms/
There are also more advanced approaches, for example FlexMDM, which essentially predicts length of the "canvas" as it "paints tokens" on it.
By CamperBob2 2026-02-252:041 reply Seems to work pretty well, and it's especially interesting to see answers pop up so quickly! It is easily fooled by the usual trick questions about car washes and such, but seems on par with the better open models when I ask it math/engineering questions, and is obviously much faster.
By volodia 2026-02-252:11 Thanks for trying it and for the thoughtful feedback, really appreciate it. And we’re actively working on improving quality further as we scale the models.
you mention voice ai in the announcement but I wonder how this works in practice. most voice AI systems are bound not by full response latency but just by time-to-first-non-reasoning-token (because once it heads to TTS, the output speed is capped at the speed of speech and even the slowest models are generating tokens faster than that once they start going).
what do ttft numbers look like for mercury 2? I can see how at least compared to other reasoning models it could improve things quite a bit but i'm wondering if it really makes reasoning viable in voice given it seems total latency is still in single digit seconds, not hundreds of milliseconds
By PranayKumarJain 2026-02-2510:301 reply Spot on about the TTFT bottleneck. In the voice world, the "thinking" silence is what kills the illusion.
At eboo.ai, we see this constantly—even with faster models, the orchestrator needs to be incredibly tight to keep the total loop under 500-800ms. If Mercury 2 can consistently hit low enough TTFT to keep the turn-taking natural, that would be a game changer for "smart" voice agents.
Right now, most "reasoning" in voice happens asynchronously or with very awkward filler audio. Lowering that floor is the real challenge.
By orthoxerox 2026-02-2514:561 reply > Spot on about the TTFT bottleneck. In the voice world, the "thinking" silence is what kills the illusion.
Are you an LLM? Because you sound like one.
By RussianCow 2026-02-2517:45 It's almost like LLMs are trained on human writing...
By mynti 2026-02-259:18 I always wondered how these models would reason correctly. I suppose they are diffusing fixed blocks of text for every step and after the first block comes the next and so on (that is how it looks in the chat interface anyways). But what happens if at the end of the first block it would need information about reasoning at the beginning of the first block? Autoregressive Models can use these tokens to refine the reasoning but I guess that Diffusion Models can only adjust their path after every block? Is there a way maybe to have dynamic block length?
I had a very odd interaction somewhat similar to how weak transformer models get into a loop:
https://gist.github.com/nlothian/cf9725e6ebc99219f480e0b72b3...
What causes this?
By volodia 2026-02-253:15 This looks like an inference glitch that we are working on fixing, thank you for flagging.
Do you think you will be moving towards drifting models in the future for even more speed?
By volodia 2026-02-252:36 Not imminently, but hard to predict where the field will go
How big is Mercury 2? How many tokens is it trained on?
Is it's agentic accuracy good enough to operate, say, coding agents without needing a larger model to do more difficult tasks?
You can think of Mercury 2 as roughly in the same intelligence tier as other speed-optimized models (e.g., Haiku 4.5, Grok Fast, GPT-Mini–class systems). The main differentiator is latency — it’s ~5× faster at comparable quality.
We’re not positioning it as competing with the largest models (Opus 4.5, etc.) on hardest-case reasoning. It’s more of a “fast agent” model (like Composer in Cursor, or Haiku 4.5 in some IDEs): strong on common coding and tool-use tasks, and providing very quick iteration loops.
By nayroclade 2026-02-252:54 Is the approach fundamentally limited to smaller models? Or could you theoretically train a model as powerful as the largest models, but much faster?
By xanth 2026-02-253:00 Are you dogfooding it on simple tasks? If so what do you use it for regularly and what do you avoid?
By bjt12345 2026-02-258:34 If latency is the differentiator, would you be chasing the edge compute marketplace, e.g. mobile edge compute AI agents?
By smusamashah 2026-02-259:20 Will it be possible to put this on Talaas chip and go even higher speeds?
Have been following your models and semi-regularly ran them through evals since early summer. With the existing Coder and Mercury models, I always found that the trade-offs were not worth it, especially as providers with custom inference hardware could push model tp/s and latency increasingly higher.
I can see some very specific use cases for an existing PKM project, specially using the edit model for tagging and potentially retrieval, both of which I am using Gemini 2.5 Flash-Lite still.
The pricing makes this very enticing and I'll really try to get Mercury 2 going, if tool calling and structured output are truly consistently possible with this model to a similar degree as Haiku 4.5 (which I still rate very highly) that may make a few use cases far more possible for me (as long as Task adherence, task inference and task evaluation aren't significantly worse than Haiku 4.5). Gemini 3 Flash was less ideal for me, partly because while it is significantly better than 3 Pro, there are still issues regarding CLI usage that make it unreliable for me.
Regardless of that, I'd like to provide some constructive feedback:
1.) Unless I am mistaken, I couldn't find a public status page. Doing some very simple testing via the chat website, I got an error a few times and wanted to confirm whether it was server load/known or not, but couldn't
2.) Your homepage looks very nice, but parts of it struggle, both on Firefox and Chromium, with poor performance to the point were it affects usability. The highlighting of the three recommended queries on the homepage lags heavily, same for the header bar and the switcher between Private and Commercial on the Early Access page switches at a very sluggish pace. The band showcasing your partners also lags below. I did remove the very nice looking diffusion animation you have in the background and found that memory and CPU usage returned to normal levels and all described issues were resolved, so perhaps this could be optimized further. It makes the experience of navigating the website rather frustrating and first impressions are important, especially considering the models are also supposed to be used in coding.
3.) I can understand if that is not possible, but it would be great if the reasoning traces were visible on the chat homepage. Will check later whether they are available on the API.
4.) Unless I am mistaken, I can't see the maximum output tokens anywhere on the website or documentation. Would be helpful if that were front and center. Is it still at roughly 15k?
5.) Consider changing the way web search works on the chat website. Currently, it is enabled by default but only seems to be used by the model when explicitly prompted to do so (and even then the model doesn't search in every case). I can understand why web search is used sparingly as the swift experience is what you want to put front and center and every web search adds latency, but may I suggest disabling web search by default and then setting the model up so, when web search is enabled, that resource is more consistently relied upon?
6.) "Try suggested prompt" returns an empty field if a user goes from an existing chat back to the main chat page. After a reload, the suggested prompt area contains said prompts again.
One thing that I very much like and that has gotten my mind racing for PKM tasks are the follow up questions which are provided essentially instantly. I can see some great value, even combining that with another models output to assist a user in exploring concepts they may not be familiar with, but will have to test, especially on the context/haystack front.
By volodia 2026-02-2620:23 Thank you for the detailed feedback! I shared this already with the team.
By gok 2026-02-255:38 Do you use fully bidirectional attention or is it at all causal?
By bananapub 2026-02-259:33 would diffusion models benefit from things like Cerebras hardware?
By DoctorOetker 2026-02-259:39 > Mercury 2 doesn't decode sequentially. It generates responses through parallel refinement, producing multiple tokens simultaneously and converging over a small number of steps. Less typewriter, more editor revising a full draft at once.
There has been quite some progress unifying DDPM & SGM as SDE
> DDPM and Score-Based Models: The objective function of DDPMs (maximizing the ELBO) is equivalent to the score matching objectives used to train SGMs.
> SDE-based Formulation: Both DDPMs and SGMs can be unified under a single SDE framework, where the forward diffusion is an Ito SDE and the reverse process uses score functions to recover data.
> Flow Matching (Continuous-Time): Flow matching is equivalent to diffusion models when the source distribution corresponds to a Gaussian. Flow matching offers "straight" trajectories compared to the often curved paths of diffusion, but they share similar training objectives and weightings.
Is there a similar connection between modern transformers and diffusion?
Suppose we look at each layer or residual connection between layers, the context window of tokens (typically a power of 2), what is incrementally added to the embedding vectors is a function of the previous layer outputs, and if we have L layers, what is then the connection between those L "steps" of a transformer and similarly performing L denoising refinements of a diffusion model?
Does this allow fitting a diffusion model to a transformer and vice versa?
