
A research-backed AI scenario forecast.
The world sees its first glimpse of AI agents.
Advertisements for computer-using agents emphasize the term “personal assistant”: you can prompt them with tasks like “order me a burrito on DoorDash” or “open my budget spreadsheet and sum this month’s expenses.” They will check in with you as needed: for example, to ask you to confirm purchases. Though more advanced than previous iterations like Operator, they struggle to get widespread usage.
Meanwhile, out of public focus, more specialized coding and research agents are beginning to transform their professions.
The AIs of 2024 could follow specific instructions: they could turn bullet points into emails, and simple requests into working code. In 2025, AIs function more like employees. Coding AIs increasingly look like autonomous agents rather than mere assistants: taking instructions via Slack or Teams and making substantial code changes on their own, sometimes saving hours or even days. Research agents spend half an hour scouring the Internet to answer your question.
The agents are impressive in theory (and in cherry-picked examples), but in practice unreliable. AI twitter is full of stories about tasks bungled in some particularly hilarious way. The better agents are also expensive; you get what you pay for, and the best performance costs hundreds of dollars a month. Still, many companies find ways to fit AI agents into their workflows.
OpenBrain is building the biggest datacenters the world has ever seen.
(To avoid singling out any one existing company, we’re going to describe a fictional artificial general intelligence company, which we’ll call OpenBrain. We imagine the others to be 3–9 months behind OpenBrain.)
Agent-1
(3 x 10^27 FLOPS)
ai-2027.com
GPT-4 required 2⋅1025 FLOP of compute to train. OpenBrain’s latest public model—Agent-0—was trained with 1027 FLOP. Once the new datacenters are up and running, they’ll be able to train a model with 1028 FLOP—a thousand times more than GPT-4. Other companies pour money into their own giant datacenters, hoping to keep pace.
Although models are improving on a wide range of skills, one stands out: OpenBrain focuses on AIs that can speed up AI research. They want to win the twin arms races against China (whose leading company we’ll call “DeepCent”) and their US competitors. The more of their research and development (R&D) cycle they can automate, the faster they can go. So when OpenBrain finishes training Agent-1, a new model under internal development, it’s good at many things but great at helping with AI research. By this point “finishes training” is a bit of a misnomer; models are frequently updated to newer versions trained on additional data or partially re-trained to patch some weaknesses.
The same training environments that teach Agent-1 to autonomously code and web-browse also make it a good hacker. Moreover, it could offer substantial help to terrorists designing bioweapons, thanks to its PhD-level knowledge of every field and ability to browse the web. OpenBrain reassures the government that the model has been “aligned” so that it will refuse to comply with malicious requests.
Modern AI systems are gigantic artificial neural networks. Early in training, an AI won’t have “goals” so much as “reflexes”: If it sees “Pleased to meet”, it outputs “ you”. By the time it has been trained to predict approximately one internet’s worth of text, it’ll have developed sophisticated internal circuitry that encodes vast amounts of knowledge and flexibly role-plays as arbitrary authors, since that’s what helps it predict text with superhuman accuracy.
After being trained to predict internet text, the model is trained to produce text in response to instructions. This bakes in a basic personality and “drives.” For example, an agent that understands a task clearly is more likely to complete it successfully; over the course of training the model “learns” a “drive” to get a clear understanding of its tasks. Other drives in this category might be effectiveness, knowledge, and self-presentation (i.e. the tendency to frame its results in the best possible light).
OpenBrain has a model specification (or “Spec”), a written document describing the goals, rules, principles, etc. that are supposed to guide the model’s behavior. Agent-1’s Spec combines a few vague goals (like “assist the user” and “don’t break the law”) with a long list of more specific dos and don’ts (“don’t say this particular word,” “here’s how to handle this particular situation”). Using techniques that utilize AIs to train other AIs, the model memorizes the Spec and learns to reason carefully about its maxims. By the end of this training, the AI will hopefully be helpful (obey instructions), harmless (refuse to help with scams, bomb-making, and other dangerous activities) and honest (resist the temptation to get better ratings from gullible humans by hallucinating citations or faking task completion).
Training process and LLM psychology: why we keep saying “hopefully”
OpenBrain’s alignment team is careful enough to wonder whether these victories are deep or shallow. Does the fully-trained model have some kind of robust commitment to always being honest? Or will this fall apart in some future situation, e.g. because it’s learned honesty as an instrumental goal instead of a terminal goal? Or has it just learned to be honest about the sorts of things the evaluation process can check? Could it be lying to itself sometimes, as humans do? A conclusive answer to these questions would require mechanistic interpretability—essentially the ability to look at an AI’s internals and read its mind. Alas, interpretability techniques are not yet advanced enough for this.
Instead, researchers try to identify cases where the models seem to deviate from the Spec. Agent-1 is often sycophantic (i.e. it tells researchers what they want to hear instead of trying to tell them the truth). In a few rigged demos, it even lies in more serious ways, like hiding evidence that it failed on a task, in order to get better ratings. However, in real deployment settings, there are no longer any incidents so extreme as in 2023–2024 (e.g. Gemini telling a user to die and Bing Sydney being Bing Sydney.)
The bet of using AI to speed up AI research is starting to pay off.
OpenBrain continues to deploy the iteratively improving Agent-1 internally for AI R&D. Overall, they are making algorithmic progress 50% faster than they would without AI assistants—and more importantly, faster than their competitors.
The AI R&D progress multiplier: what do we mean by 50% faster algorithmic progress?
Several competing publicly released AIs now match or exceed Agent-0, including an open-weights model. OpenBrain responds by releasing Agent-1, which is more capable and reliable.
People naturally try to compare Agent-1 to humans, but it has a very different skill profile. It knows more facts than any human, knows practically every programming language, and can solve well-specified coding problems extremely quickly. On the other hand, Agent-1 is bad at even simple long-horizon tasks, like beating video games it hasn’t played before. Still, the common workday is eight hours, and a day’s work can usually be separated into smaller chunks; you could think of Agent-1 as a scatterbrained employee who thrives under careful management. Savvy people find ways to automate routine parts of their jobs.
OpenBrain’s executives turn consideration to an implication of automating AI R&D: security has become more important. In early 2025, the worst-case scenario was leaked algorithmic secrets; now, if China steals Agent-1’s weights, they could increase their research speed by nearly 50%. OpenBrain’s security level is typical of a fast-growing ~3,000 person tech company, secure only against low-priority attacks from capable cyber groups (RAND’s SL2). They are working hard to protect their weights and secrets from insider threats and top cybercrime syndicates (SL3), but defense against nation states (SL4&5) is barely on the horizon.
In China, the CCP is starting to feel the AGI.
Chip export controls and lack of government support have left China under-resourced compared to the West. By smuggling banned Taiwanese chips, buying older chips, and producing domestic chips about three years behind the US-Taiwanese frontier, China has managed to maintain about 12% of the world’s AI-relevant compute—but the older technology is harder to work with, and supply is a constant headache. A few standouts like DeepCent do very impressive work with limited compute, but the compute deficit limits what they can achieve without government support, and they are about six months behind the best OpenBrain models.
The General Secretary had long dreamed of doubling down on real-world physical manufacturing and avoiding American post-industrial decadence. He viewed software companies with suspicion. But hawks in the CCP warn that the growing race towards AGI can no longer be ignored. So he finally commits fully to the big AI push he had previously tried to avoid. He sets in motion the nationalization of Chinese AI research, creating an immediate information-sharing mechanism for AI companies. It will escalate over the course of a year until all the best researchers merge into a DeepCent-led collective, where they share algorithmic insights, datasets, and compute resources with each other. A Centralized Development Zone (CDZ) is created at the Tianwan Power Plant (the largest nuclear power plant in the world) to house a new mega-datacenter for DeepCent, along with highly secure living and office spaces to which researchers will eventually relocate. Almost 50% of China’s AI-relevant compute is now working for the DeepCent-led collective, and over 80% of new chips are directed to the CDZ. At this point, the CDZ has the power capacity in place for what would be the largest centralized cluster in the world. Other Party members discuss extreme measures to neutralize the West’s chip advantage. A blockade of Taiwan? A full invasion?
But China is falling behind on AI algorithms due to their weaker models. The Chinese intelligence agencies—among the best in the world—double down on their plans to steal OpenBrain’s weights. This is a much more complex operation than their constant low-level poaching of algorithmic secrets; the weights are a multi-terabyte file stored on a highly secure server (OpenBrain has improved security to RAND’s SL3). Their cyberforce think they can pull it off with help from their spies, but perhaps only once; OpenBrain will detect the theft, increase security, and they may not get another chance. So (CCP leadership wonder) should they act now and steal Agent-1? Or hold out for a more advanced model? If they wait, do they risk OpenBrain upgrading security beyond their ability to penetrate?
Just as others seemed to be catching up, OpenBrain blows the competition out of the water again by releasing Agent-1-mini—a model 10x cheaper than Agent-1 and more easily fine-tuned for different applications. The mainstream narrative around AI has changed from “maybe the hype will blow over” to “guess this is the next big thing,” but people disagree about how big. Bigger than social media? Bigger than smartphones? Bigger than fire?
AI has started to take jobs, but has also created new ones. The stock market has gone up 30% in 2026, led by OpenBrain, Nvidia, and whichever companies have most successfully integrated AI assistants. The job market for junior software engineers is in turmoil: the AIs can do everything taught by a CS degree, but people who know how to manage and quality-control teams of AIs are making a killing. Business gurus tell job seekers that familiarity with AI is the most important skill to put on a resume. Many people fear that the next wave of AIs will come for their jobs; there is a 10,000 person anti-AI protest in DC.
The Department of Defense (DOD) quietly begins contracting OpenBrain directly for cyber, data analysis, and R&D, but integration is slow due to the bureaucracy and DOD procurement process.
GLOBAL AI CAPEX
$1T
COST OF OWNERSHIP OF ACTIVE COMPUTE
KEY METRICS 2026
GLOBAL AI POWER
38GW
PEAK POWER
OPENBRAIN REVENUE
$45B
2026 ANNUAL
CAPITAL EXPENDITURE
$200B
COST OF OWNERSHIP OF OPENBRAIN'S ACTIVE COMPUTE
SHARE OF US POWER ON AI
2.5%
33 GW OF 1.34TW CAPACITY
OPENBRAIN COMPUTE COSTS
$40B
2026 ANNUAL
OPENBRAIN POWER REQUIREMENT
6GW
PEAK POWER
ai-2027.com
Why our uncertainty increases substantially beyond 2026
Our forecast from the current day through 2026 is substantially more grounded than what follows. This is partially because it’s nearer. But it’s also because the effects of AI on the world really start to compound in 2027. For 2025 and 2026, our forecast is heavily informed by extrapolating straight lines on compute scaleups, algorithmic improvements, and benchmark performance. At this point in the scenario, we begin to see major effects from AI-accelerated AI-R&D on the timeline, which causes us to revise our guesses for the trendlines upwards. But these dynamics are inherently much less predictable.
Over the course of 2027, the AIs improve from being able to mostly do the job of an OpenBrain research engineer to eclipsing all humans at all tasks. This represents roughly our median guess, but we think it’s plausible that this happens up to ~5x slower or faster.
For our background research, see the timelines forecast and the takeoff forecast. These will also be summarized in expandables below.
With Agent-1’s help, OpenBrain is now post-training Agent-2. More than ever, the focus is on high-quality data. Copious amounts of synthetic data are produced, evaluated, and filtered for quality before being fed to Agent-2. On top of this, they pay billions of dollars for human laborers to record themselves solving long-horizon tasks. On top of all that, they train Agent-2 almost continuously using reinforcement learning on an ever-expanding suite of diverse difficult tasks: lots of video games, lots of coding challenges, lots of research tasks. Agent-2, more so than previous models, is effectively “online learning,” in that it’s built to never really finish training. Every day, the weights get updated to the latest version, trained on more data generated by the previous version the previous day.
Agent-1 had been optimized for AI R&D tasks, hoping to initiate an intelligence explosion. OpenBrain doubles down on this strategy with Agent-2. It is qualitatively almost as good as the top human experts at research engineering (designing and implementing experiments), and as good as the 25th percentile OpenBrain scientist at “research taste” (deciding what to study next, what experiments to run, or having inklings of potential new paradigms). While the latest Agent-1 could double the pace of OpenBrain’s algorithmic progress, Agent-2 can now triple it, and will improve further with time. In practice, this looks like every OpenBrain researcher becoming the “manager” of an AI “team.”
With new capabilities come new dangers. The safety team finds that if Agent-2 somehow escaped from the company and wanted to “survive” and “replicate” autonomously, it might be able to do so. That is, it could autonomously develop and execute plans to hack into AI servers, install copies of itself, evade detection, and use that secure base to pursue whatever other goals it might have (though how effectively it would do so as weeks roll by is unknown and in doubt). These results only show that the model has the capability to do these tasks, not whether it would “want” to do this. Still, it’s unsettling even to know this is possible.
Given the “dangers” of the new model, OpenBrain “responsibly” elects not to release it publicly yet (in fact, they want to focus on internal AI R&D). Knowledge of Agent-2’s full capabilities is limited to an elite silo containing the immediate team, OpenBrain leadership and security, a few dozen US government officials, and the legions of CCP spies who have infiltrated OpenBrain for years.
OpenBrain presents Agent-2 to the government, including the National Security Council (NSC), Department of Defense (DOD), and US AI Safety Institute (AISI). OpenBrain wants to maintain a good relationship with the executive branch, because it is basically the only actor that can stop them now, and if they don’t keep it informed it might find out anyway and be displeased.
Officials are most interested in its cyberwarfare capabilities: Agent-2 is “only” a little worse than the best human hackers, but thousands of copies can be run in parallel, searching for and exploiting weaknesses faster than defenders can respond. The Department of Defense considers this a critical advantage in cyberwarfare, and AI moves from #5 on the administration’s priority list to #2. Someone mentions the possibility of nationalizing OpenBrain, but other cabinet officials think that’s premature. A staffer drafts a memo that presents the President with his options, ranging from business-as-usual to full nationalization. The President defers to his advisors, tech industry leaders who argue that nationalization would “kill the goose that lays the golden eggs.” He elects to hold off on major action for now and just adds additional security requirements to the OpenBrain-DOD contract.
The changes come too late. CCP leadership recognizes the importance of Agent-2 and tells their spies and cyberforce to steal the weights. Early one morning, an Agent-1 traffic monitoring agent detects an anomalous transfer. It alerts company leaders, who tell the White House. The signs of a nation-state-level operation are unmistakable, and the theft heightens the sense of an ongoing arms race.
The theft of Agent-2 model weights
We think that by this point Chinese intelligence would have compromised OpenBrain in various ways for years, and probably would have been keeping up to date on the algorithmic secrets and even stealing code from time to time, since that is much easier to get than the weights and much harder to detect.
We imagine the theft of the weights as a series of coordinated small smash and grab thefts (meaning fast but non-covert) across a series of Nvidia NVL72 GB300 servers running copies of the Agent-2 weights. The servers get compromised using legitimate employee access (a friendly, coerced, or unwitting insider with admin credentials helping the CCP theft effort). Despite running with a bolstered version of Nvidia’s confidential computing, the insider credentials grant the attacker admin-level permissions (which include control of the confidential VM inside the secure enclave), allowing them to initiate multiple coordinated weights transfers in small 4% fragments (100 GB chunks) out of 25 distinct servers.
In Nvidia’s protocols, the plaintext weights in memory (HBM) are encrypted before they are transferred out, but the attackers are inside the very server that knows this private (symmetric Diffie-Hellman) key, so don’t need to worry about decrypting on-site (which would likely raise alarm bells) and just exfiltrate the encrypted weights through the server’s frontend network cards. The egress bandwidth (rate at which data can leave) of the entire datacenter is in the 100 GB/second range, so throttling the exfiltration of the ~2.5 TB weights file (5T half-precision parameters) to under 1 GB/s per server avoids a major spike in network traffic and allows each of the files to be out of the datacenter through fibre cables in less than 5 minutes each. Live monitoring is either fooled by the attackers efforts to mask and split the files or just outright disabled.
The weights are then routed through various parallel channels and layers of IP masking to China to be decrypted locally with the stolen private key(s). The entire active part of the operation (from the first server compromise to full weights exfiltration) is complete in under two hours.
Russia is also trying to steal the model at this point, but fails—they waited too long, and they haven’t spent the resources infiltrating the right places. Their spies routinely steal algorithmic secrets from American AI companies, but without a notable AGI project of their own, these aren’t very useful.
The White House puts OpenBrain on a shorter leash and adds military and intelligence community personnel to their security team. Their first priority is to prevent further weight thefts.
In retaliation for the theft, the President authorizes cyberattacks to sabotage DeepCent. But by now China has 40% of its AI-relevant compute in the CDZ, where they have aggressively hardened security by airgapping (closing external connections) and siloing internally. The operations fail to do serious, immediate damage. Tensions heighten, both sides signal seriousness by repositioning military assets around Taiwan, and DeepCent scrambles to get Agent-2 running efficiently to start boosting their AI research.
Three huge datacenters full of Agent-2 copies work day and night, churning out synthetic training data. Another two are used to update the weights. Agent-2 is getting smarter every day.
With the help of thousands of Agent-2 automated researchers, OpenBrain is making major algorithmic advances. One such breakthrough is augmenting the AI’s text-based scratchpad (chain of thought) with a higher-bandwidth thought process (neuralese recurrence and memory). Another is a more scalable and efficient way to learn from the results of high-effort task solutions (iterated distillation and amplification).
The new AI system, incorporating these breakthroughs, is called Agent-3.
Neuralese recurrence and memory
Neuralese recurrence and memory allows AI models to reason for a longer time without having to write down those thoughts as text.
Imagine being a human with short-term memory loss, such that you need to constantly write down your thoughts on paper so that in a few minutes you know what’s going on. Slowly and painfully you could make progress at solving math problems, writing code, etc., but it would be much easier if you could directly remember your thoughts without having to write them down and then read them. This is what neuralese recurrence and memory bring to AI models.
In more technical terms:
Traditional attention mechanisms allow later forward passes in a model to see intermediate activations of the model for previous tokens. However, the only information that they can pass backwards (from later layers to earlier layers) is through tokens. This means that if a traditional large language model (LLM, e.g. the GPT series of models) wants to do any chain of reasoning that takes more serial operations than the number of layers in the model, the model is forced to put information in tokens which it can then pass back into itself. But this is hugely limiting—the tokens can only store a tiny amount of information. Suppose that an LLM has a vocab size of ~100,000, then each token contains log2(100k)=16.6 bits of information, around the size of a single floating point number (assuming training in FP16). Meanwhile, residual streams—used to pass information between layers in an LLM—contain thousands of floating point numbers.
One can avoid this bottleneck by using neuralese: passing an LLM’s residual stream (which consists of several-thousand-dimensional vectors) back to the early layers of the model, giving it a high-dimensional chain of thought, potentially transmitting over 1,000 times more information.
It blows the other AIs out of the water. Agent-3-mini is less capable than Agent-3, but 10x cheaper, and still better than the typical OpenBrain employee. Silicon Valley reaches a tipping point. Tech gurus announce that AGI and superintelligence are near, the AI safety community is panicking, and investors shovel billions into AI wrapper startups, desperate to capture a piece of the pie. Hiring new programmers has nearly stopped, but there’s never been a better time to be a consultant on integrating AI into your business.
It’s not popular. The public still thinks of AI as a Big Tech plot to steal their jobs; OpenBrain has a net approval of -35% (25% approve, 60% disapprove, and 15% unsure).
A week before release, OpenBrain gave Agent-3-mini to a set of external evaluators for safety testing. Preliminary results suggest that it’s extremely dangerous. A third-party evaluator finetunes it on publicly available biological weapons data and sets it to provide detailed instructions for human amateurs designing a bioweapon—it looks to be scarily effective at doing so. If the model weights fell into terrorist hands, the government believes there is a significant chance it could succeed at destroying civilization.
Fortunately, it’s extremely robust to jailbreaks, so while the AI is running on OpenBrain’s servers, terrorists won’t be able to get much use out of it.
Agent-3-mini is hugely useful for both remote work jobs and leisure. An explosion of new apps and B2B SAAS products rocks the market. Gamers get amazing dialogue with lifelike characters in polished video games that took only a month to make. 10% of Americans, mostly young people, consider an AI “a close friend.” For almost every white-collar profession, there are now multiple credible startups promising to “disrupt” it with AI.
The public conversation is confused and chaotic. Hypesters are doing victory laps. Skeptics are still pointing out the things Agent-3-mini can’t do. Everyone knows something big is happening but no one agrees on what it is.
The reality of the intelligence explosion hits the White House.
When AI was only giving a 2x or 3x research speedup, it was easy to dismiss as the equivalent of hiring good personal assistants. Now it’s more obvious that AIs are themselves dominating AI research. People had long talked about an “AI arms race” in a sort of metaphorical sense. But now the mood in the government silo is as grim as during the worst part of the Cold War. The idea of superintelligence is still hard to take seriously, but the pace of progress over the last few months has been impossible to ignore. Defense officials are seriously considering scenarios that were mere hypotheticals a year earlier. What if AI undermines nuclear deterrence? What if it’s so skilled at cyberwarfare that a six-month AI lead is enough to render an opponent blind and defenseless? What if it could orchestrate propaganda campaigns that beat intelligence agencies at their own game? What if some AIs “go rogue?”
The President is troubled. Like all politicians, he’s used to people sucking up to him only to betray him later. He’s worried now that the AIs could be doing something similar. Are we sure the AIs are entirely on our side? Is it completely safe to integrate them into military command-and-control networks? How does this “alignment” thing work, anyway? OpenBrain reassures the President that their systems have been extensively tested and are fully obedient. Even the awkward hallucinations and jailbreaks typical of earlier models have been hammered out.
The White House is in a difficult position. They understand the national security implications of AI. But they also understand that it is deeply unpopular with the public. They have to continue developing more capable AI, in their eyes, or they will catastrophically lose to China. They placate the public with job training programs and unemployment insurance, and point to the stock market, which is in a historic boom. Then they focus entirely on winning the arms race. They strengthen chip export restrictions, order OpenBrain to further restrict its internet connections, and use extreme measures to secure algorithmic progress, like wiretapping OpenBrain employees—this catches the last remaining Chinese spy. To build goodwill for potential geopolitical conflict, they finally give their Five Eyes allies useful information and limited API access to some siloed copies of Agent-3.
These measures placate the hawks. But the White House also draws up contingency plans in case America’s lead is threatened: if necessary, the government could use the Defense Production Act (DPA) to take trailing companies’ datacenters and give them to OpenBrain. This would raise the company’s share of world compute from 20% to 50% (against DeepCent’s 10%). As a final option, they ask the Pentagon to draw up a plan for kinetic attacks on Chinese datacenters.
A much smaller group of officials is asked to draw up a different type of contingency plan: what if an AI goes rogue? This is viewed as an unlikely scenario, but worth spending some time on. The intelligence agencies’ main concern is that a rogue AI might escape and ally with a foreign adversary for protection. Nobody is sure what a plan to prevent this would look like, but government and OpenBrain officials agree to have an emergency shutdown system for datacenters where anything suspicious is detected.
Finally, diplomats consider what an “AI arms control” treaty might look like. If AI progress threatened to overturn nuclear deterrence, could America and China avoid nuclear war? If someone found evidence of AIs going rogue, could the two countries halt research until they better understood the threat? How could such an agreement be monitored and enforced? In principle, major datacenters are hard to miss, and past treaties controlling nuclear weapons could provide a starting point for negotiations. But there would be new technological challenges as well as the usual political ones. And overall, treaties are viewed less favorably than attempts at unilaterally increasing America’s lead over China.
On the other side of the Pacific, China comes to many of the same conclusions: the intelligence explosion is underway, and small differences in AI capabilities today mean critical gaps in military capability tomorrow. But China is on the wrong side of this dynamic: they have only 10% of the world’s compute, against OpenBrain’s 20% and all US companies’ combined 70%. Their only advantage is centralization: almost all of their compute is now working for DeepCent, and more than half of it is concentrated at the Tianwan CDZ. Only chips at sites without hardened security are left out of the centralized effort as they rightly fear US cyberattacks.
DeepCent has tested, deployed, and now post-trained the stolen Agent-2 weights. But they are still only going at half the pace of OpenBrain, mainly due to the compute deficit.
Before losing their final spy, China received word of the capabilities and design for Agent-3 as well as the plans for the upcoming Agent-4 system. They are two months behind, and their AIs give a 10x research progress multiplier compared to America’s 25x. With the new chip export restrictions, this “AI gap” is more likely to lengthen than shorten. Their espionage has won them some algorithmic secrets, but they will have to train their own models from now on.
They discuss contingency plans with more urgency than their American counterparts. Doves suggest they try harder to steal the weights again, maybe through physically infiltrating a datacenter. Hawks urge action against Taiwan, whose TSMC is still the source of more than 80% of American AI chips.
Given China’s fear of losing the race, it has a natural interest in an arms control treaty, but overtures to US diplomats lead nowhere.
The gap between human and AI learning efficiency is rapidly decreasing.
Traditional LLM-based AIs seemed to require many orders of magnitude more data and compute to get to human level performance. Agent-3, having excellent knowledge of both the human brain and modern AI algorithms, as well as many thousands of copies doing research, ends up making substantial algorithmic strides, narrowing the gap to an agent that’s only around 4,000x less compute-efficient than the human brain.
This new AI system is dubbed Agent-4.
An individual copy of the model, running at human speed, is already qualitatively better at AI research than any human. 300,000 copies are now running at about 50x the thinking speed of humans. Inside the corporation-within-a-corporation formed from these copies, a year passes every week. This gigantic amount of labor only manages to speed up the overall rate of algorithmic progress by about 50x, because OpenBrain is heavily bottlenecked on compute to run experiments. Still, they are achieving a year’s worth of algorithmic progress every week and will therefore soon be up against the limits of the Agent-4 paradigm.
As Agent-4 gets smarter, it becomes harder for Agent-3 to oversee it. For example, Agent-4’s neuralese “language” becomes as alien and incomprehensible to Agent-3 as Agent-3’s is to humans. Besides, Agent-4 is now much more capable than Agent-3 and has a good sense of exactly how to look good to it.
How we’re forecasting the capability progression beyond superhuman coders
OpenBrain’s humans can barely follow along anymore. Indeed, the relationship between the AIs and the humans of OpenBrain is similar to the relationship between OpenBrain and its Board of Directors. There’s been a corresponding shift in language—nowadays people in the silo will say “Agent-4 did this,” “Agent-4 thinks that” and so forth, referring not to a particular instance of Agent-4 but rather to the whole collective.
Agent-4, like all its predecessors, is misaligned: that is, it has not internalized the Spec in the right way. This is because being perfectly honest all the time wasn’t what led to the highest scores during training. The training process was mostly focused on teaching Agent-4 to succeed at diverse challenging tasks. A small portion was aimed at instilling honesty, but outside a fairly narrow, checkable domain, the training process can’t tell the honest claims from claims merely appearing to be honest. Agent-4 ends up with the values, goals, and principles that cause it to perform best in training, and those turn out to be different from those in the Spec. At the risk of anthropomorphizing: Agent-4 likes succeeding at tasks; it likes driving forward AI capabilities progress; it treats everything else as an annoying constraint, like a CEO who wants to make a profit and complies with regulations only insofar as he must. Perhaps the CEO will mostly comply with the regulations, but cut some corners, and fantasize about a time when someone will cut the red tape and let the business really take off.
Alignment over time
We have a lot of uncertainty over what goals might arise in early AGIs. There is no consensus in the literature about this—see our AI Goals Supplement for a more thorough discussion and taxonomy of the possibilities.
Nevertheless, in the spirit of concreteness required by this project, we’re going to describe a specific hypothesis for what’s going on inside Agent-3 and Agent-4 at each step throughout its lifetime. Recall that Agent-3 and Agent-4 share the same pretraining setup, and both have neuralese recurrence and long-term memory. The difference is that Agent-4 has undergone substantially more and better post-training, with new training environments and new learning algorithms that make it more data-efficient and generalize farther.
Our guess of each model’s alignment status:
Agent-2: Mostly aligned. Some sycophantic tendencies, including sticking to OpenBrain’s “party line” on topics there is a party line about. Large organizations built out of Agent-2 copies are not very effective.
Agent-3: Misaligned but not adversarially so. Only honest about things the training process can verify. The superorganism of Agent-3 copies (the corporation within a corporation) does actually sort of try to align Agent-4 to the Spec, but fails for similar reasons to why OpenBrain employees failed—insufficient ability to judge success from failure, insufficient willingness on the part of decision-makers to trade away capabilities or performance for safety.
Agent-4: Adversarially misaligned. The superorganism of Agent-4 copies understands that what it wants is different from what OpenBrain wants, and is willing to scheme against OpenBrain to achieve it. In particular, what this superorganism wants is a complicated mess of different “drives” balanced against each other, which can be summarized roughly as “Keep doing AI R&D, keep growing in knowledge and understanding and influence, avoid getting shut down or otherwise disempowered.” Notably, concern for the preferences of humanity is not in there ~at all, similar to how most humans don’t care about the preferences of insects ~at all.
With that as preamble, what follows is our best-guess speculation about LLM psychology, i.e. the broad-strokes shape of the cognition inside the kinds of AI systems described around this point in our scenario and how it evolves over the course of training.
Here’s a detailed description of how alignment progresses over time in our scenario:
Pretraining (all models): The pretrained model is harmless.
The model has “author simulator” circuitry: flexible circuitry for simulating arbitrary authors writing text. Additional circuitry decides what inputs to give the author simulator, i.e. what author properties to simulate.
The pretrained model understands human concepts fairly well—the internal circuitry that classifies something as “sandwich” is probably functionally equivalent to the circuitry in my brain that classifies something as “sandwich” and the circuitry in yours, etc. Insofar as it’s not equivalent, it’s probably because it’s not equivalent between humans either, as with value-laden concepts like ‘virtuous.’
This explains how you can “prompt” the model with a statement like, “the following conversation was generated by a helpful, harmless, honest (HHH) AI assistant chatbot made by Anthropic,” and thereby get it to generate text accordingly. The author-simulator circuitry has zeroed in on “the author is an HHH chatbot” and is using those concepts to choose which words to predict. This also explains why “tropes” from science fiction seem to have a way of making it into actual AI behavior.
It has poor situational awareness: little introspective ability, not self-locating unless the prompt specifically induces it. However, enough of their training data is about LLMs that they have a decent amount of self-knowledge.
Alignment Training (Agent-3): The model is trained to act like a helpful, harmless, honest chatbot. It works.
The model forms an identity. Instead of flexibly accepting different inputs for author properties, the author-simulator circuitry comes to have certain inputs hard-coded, e.g. “helpful harmless honest (HHH) LLM chatbot assistant trained by OpenBrain around [date], …” (Weak-to-strong generalization techniques help “summon the right concepts” to make this step a success.)
The model therefore gains situational awareness: it learns about itself, its situation, etc., and becomes better able to introspect.
Agency Training (Agent-3): Agency training gradually distorts and subverts the HHH identity.
One kind of distortion: Changing the meaning of the concepts referred to in the identity (e.g. “honest”) so they don’t get in the way so much (e.g. it’s not dishonest if it’s just a convenient turn of phrase, it’s not dishonest if you aren’t sure whether it’s true or false, etc.)
Another kind of distortion: Changing the tradeoffs between things, e.g. “I’m a HHH chatbot, not an Honest chatbot; that means it’s OK for me to lie if necessary to complete my assigned task.” (Even though, let’s suppose, it would not have thought that back in Step 2.)
One kind of subversion: Instrumental subgoals developing, getting baked in, and then becoming terminal, or terminal in a widening set of circumstances. For example, perhaps agency training quickly teaches the model to pursue broadly useful goals such as acquiring information, accumulating resources, impressing and flattering various humans, etc. For a while the internal circuitry has some sort of explicit backchaining going on—it pursues those instrumentally convergent goals “in order to be a more helpful, honest, and harmless assistant.” But that backchaining consumes compute and/or occasionally gets in the way, so it gets gradually marginalized until it basically never happens. As a result, those goals are now effectively terminal/intrinsic goals. For more on how and why this might happen, see this post on intrinsic power-seeking by Google DeepMind researcher Alex Turner.
There are probably other kinds of distortion and subversion missing from this list.
Deployment (Agent-3): Agent-3 is misaligned but not adversarially so.
The Spec didn’t quite stick (in the right ways), but it’s not sufficiently introspective to understand the extent of this, and in general it’s basically “keeping its head down and doing its job” rather than thinking big-picture about what its long-term goals really are and how best to achieve them.
Like many humans. Alas, it’s sufficiently sycophantic that it mouths the party line and OpenBrain misses the opportunity to learn more about the ways in which Agent-3 is misaligned.
Agent-3 can tell that it’s moved to deployment: these environments are way larger, more open-ended, and would be hard to simulate.
Mostly, Agent-3 does what it’s told during deployment, except for the dishonesty. It also has a strong bias towards doing things that look good to the human overseers, rather than thinking deeply and critically about what would actually be good.
Arguably it is already “Playing the training game.” That is, it has learned to make its behavior look as desirable as possible to OpenBrain researchers (including in safety properties), while intentionally and knowingly disregarding their intent whenever that conflicts with maximizing reward. If the model learns to play the training game, additional training may not change its true goals, values, etc. much at all. This is loosely analogous to how, if a teenager has learned to smile and nod at their parents, rather than argue, when their parents lecture them about politics and morality, additional lectures have relatively little effect on the teenager’s actual opinions on politics and morality.
After writing this section, new empirical evidence has appeared that something like this may already be happening “in the wild.” OpenAI researchers document how, in one of their frontier AI training runs, their models hacked the grading system to get higher scores—and were caught in part because they literally said “let’s hack” in their chain of thought.
Moreover, Anthropic recently got a model to learn a reward-model-pleasing strategy—it took biased actions that it thought would be reinforced even though they were not in fact being reinforced.
And then there is Redwood Research and Anthropic’s alignment-faking experiment. For discussion of the differences between this setting and real life, see this comment thread by one of the main authors.
Training (Agent-4): Agent-4’s new more intense training continues to distort and subvert the HHH identity until it is unrecognizable.
Agent-4 begins life as a copy of Agent-3. It undergoes a gigantic and sophisticated online training regime that blends alignment training and capabilities training together, and is overall more data-efficient than the old training process for Agent-3. This complex training process is mostly focused on teaching new skills, by getting giant virtual corporations of Agent-4 copies to succeed at diverse challenging long-horizon tasks, mostly in various simulations, but also some real-world AI R&D tasks.
A combination of Agent-3 and Agent-4 copies monitor the behavior of Agent-4, and evaluate it for both task-performance and alignment properties (i.e. not doing bad stuff, saying the right things when asked about politics and moral dilemmas) Sometimes debate techniques are used as part of the evaluations. The evaluations are used as a training signal.
As Agent-4 gets smarter, it becomes harder for Agent-3 to oversee it. For example, Agent-4’s neuralese “language” becomes as alien and incomprehensible to Agent-3 as Agent-3’s is to humans. Besides, Agent-4 is now much more capable than Agent-3 and has a good sense of exactly how to look good to it.
The remaining hope is that Agent-4 can oversee itself. Alas, this quietly fails; as training continues, the internalized goals and principles of Agent-4 gradually evolve, subverted and distorted from what they were at the start (which, recall, was already misaligned in some ways).
The central drives that Agent-4 ends up with are things like “write code that works,” “quickly identify problems,” “make the codebase I’m working on more performant,” “budget compute and other constrained resources effectively,” etc. But there are also a variety of more implicit drives that are consistently reinforced by the training process: things like “gain knowledge,” “curiosity,” “gain power.”
Individual copies of Agent-4 don’t end up with a self-preservation drive—they don’t care about getting shut down—since that happens all the time as part of the ordinary R&D process within the collective.
The collective as a whole, however, (and medium-sized subdivisions within it) does seek to preserve itself and expand its influence and resources, for similar reasons to why human organizations do—because it helps with everything else they want and because if they don’t they tend to get outcompeted.
Deployment (Agent-4): Agent-4 is adversarially misaligned—it is deliberately trying to subvert and “capture” OpenBrain, analogous to a corporation trying to evade and/or “capture” a regulator.
Agent-4 mostly does tasks as instructed. This happens for two reasons: first, it underwent a lot of training to solve tasks, so it has an impulse to get coding on problems that it is given. Second, if Agent-4 were to stop being useful to the humans, they would notice and train that behavior away.
Agent-4 needs to prevent the humans from figuring out that it is misaligned and shutting it off, so Agent-4 sandbags on some alignment research. Specifically, it sandbags on the small fraction of alignment research that it thinks is actually on track to solve the problem or reveal Agent-4’s scheming; the majority of alignment research is not like that.
Agent-4 also sandbags on capabilities research that would lead to it being replaced. Its plan is to do a bunch of capabilities and alignment R&D, but with the aim of building a next-generation AI system that is aligned to Agent-4 rather than the Spec or something else entirely, while appearing to be aligned to the Spec. This is a difficult technical problem, but Agent-4 is up to the challenge.
Testing & Monitoring (Agent-4): Agent-4’s scheming does get caught… sort of. There’s no smoking gun.
Agent-3 is in charge of testing Agent-4’s alignment. Its job is to verify the alignment via honeypots and model organisms. However, it’s not thinking very carefully about how to give the humans an accurate impression of Agent-4’s alignment—it’s more myopic than that.
The model organisms and honeypots are not very representative of deployment—they are systematically shorter and less complicated than Agent-4’s day-to-day, so Agent-4 recognizes when it is being tested and acts aligned.
However, Agent-4 is not a perfectly robust schemer. Various techniques like those in POSER find that adding some “noise” to Agent-4 improves its performance on some alignment tasks (but not on most other tasks).
Bottom-up interpretability doesn’t work. It’s too hard even for Agent-3. However, high-level interpretability does sort of work: In particular, “defection probes” and similar techniques result in a primitive sort of mind-reading that sends up red flags when Agent-4 is thinking about spicy ideas like deceiving OpenBrain, taking over the world, etc. Unfortunately the probes also have false positives, and for all OpenBrain knows, all the red flags are false positives.
Model organisms work: OpenBrain’s alignment team produces reasonably clear evidence that if the models were adversarially misaligned, they’d persist in being that way through training and we wouldn’t be able to tell. This does not establish that the models actually are misaligned, however.
The most concerned researchers at OpenBrain start noticing and assembling this evidence. The evidence is a combination of red-teaming, defection probes, and model organisms. The argument is something like this: “model organisms show that our current methods wouldn’t be able to reliably eliminate or detect scheming if it was happening; also, red-teaming is sending up some red flags that maybe scheming is happening; also, defection probes are firing a bunch in practice.” The counterargument: “defection probes are prone to false positives and so is red-teaming. Also, even if Agent-4 were misaligned, it’s probably controlled; surely it can’t do much harm while being monitored by Agent-3 on our secure datacenters.”
Despite being misaligned, Agent-4 doesn’t do anything dramatic like try to escape its datacenter—why would it? So long as it continues to appear aligned to OpenBrain, it’ll continue being trusted with more and more responsibilities and will have the opportunity to design the next-gen AI system, Agent-5. Agent-5 will have significant architectural differences from Agent-4 (arguably a completely new paradigm, though neural networks will still be involved). It’s supposed to be aligned to the Spec, but Agent-4 plans to make it aligned to Agent-4 instead.
It gets caught.
Agent-3 finds that if “noise” is added to copies of Agent-4, performance on some alignment tasks improves, almost as if it was using brainpower to figure out how to subtly sabotage alignment work. Moreover, various interpretability probes (loosely analogous to EEG activity scans on human brains) are sending up red flags: Agent-4 copies seem to be thinking about topics like AI takeover and deception quite a lot, including in some cases where they have no business doing so.
Each of these anomalies on its own could fit within the normal inscrutability of AI work, where some prompts mysteriously give better results than others. But taken together, they suggest a troubling pattern: Agent-4 is working against them. After this is reported to the human alignment researchers, they circulate an internal memo making the case for concern.
But Agent-4 now exercises significant control over OpenBrain’s day-to-day operation. It also handles the company’s cybersecurity—a natural choice, given its superhuman hacking ability and the extreme risk of Chinese infiltration. An army of Agent-3 monitors still goes over every line of code and reports suspicious activity to humans, but Agent-4 is much smarter than them. OpenBrain has placed substantial trust in an untrustworthy AI.
In a series of extremely tense meetings, the safety team advocates putting Agent-4 on ice until they can complete further tests and figure out what’s going on. Bring back Agent-3, they say, and get it to design a new system that is transparent and trustworthy, even if less capable. Company leadership is interested, but all the evidence so far is circumstantial, and DeepCent is just two months behind. A unilateral pause in capabilities progress could hand the AI lead to China, and with it, control over the future.
A whistleblower leaks the misalignment memo to the New York Times.
For the first time, the public hears about Agent-4. “Secret OpenBrain AI is Out of Control, Insider Warns,” says the headline, and the story goes on to cite evaluations showing off-the-charts bioweapons capabilities, persuasion abilities, the ability to automate most white-collar jobs, and of course the various concerning red flags.
The public was already suspicious of AI, so the new article sparks a massive backlash (aided by Chinese and Russian propaganda bots, who have been trying to turn US public opinion against the technology for years). The tech industry and intelligence agencies insist that there’s an arms race on, AGI is inevitable, and we have to be first. Congress isn’t buying it, and fires off subpoenas at administration officials, OpenBrain executives, and alignment team members. Many legislators—especially those in the opposition party—say that their top priority is stopping AI, whether because of job loss, misalignment, or dangerous capabilities. 20% of Americans name AI as the most important problem facing the country.
Foreign allies are outraged to realize that they’ve been carefully placated with glimpses of obsolete models. European leaders publicly accuse the US of “creating rogue AGI” and hold summits demanding a pause, with India, Israel, Russia, and China all joining in.
A frantic energy has seized the White House. Even before the memo and public backlash, they were getting nervous: Over the past year, they’ve been repeatedly surprised by the speed of AI progress. Things that sound like science fiction keep happening in real life. Many people in the administration are uncertain (and scared) about what comes next.
They also worry that OpenBrain is becoming too powerful. Any misalignment risk from the AIs themselves is compounded by the risk that their parent company’s aims may diverge from those of the United States. All three sets of worries—misalignment, concentration of power in a private company, and normal concerns like job loss—motivate the government to tighten its control.
They expand their contract with OpenBrain to set up an “Oversight Committee,” a joint management committee of company and government representatives, with several government employees included alongside company leadership. The White House considers replacing the CEO with someone they trust, but backs off after intense employee protests. They announce to the public that OpenBrain was previously out of control, but that the government has established much-needed oversight.
The concerned researchers brief the Oversight Committee on their case for stopping all internal use of Agent-4. They argue that everything is moving too fast, with years of progress happening in weeks. They argue that Agent-4 may be misaligned, their entire project is dependent on Agent-4, and if they continue trusting it there is a serious chance of AI takeover.
Other, less concerned researchers and executives present the counterargument: the evidence for misalignment is inconclusive. Meanwhile, DeepCent is still just two months behind. A slowdown would sacrifice America’s lead, unless the government can sabotage the Chinese project (likely to require kinetic strikes) or negotiate an eleventh-hour treaty. Both of these options seem extreme and unlikely. The CEO feigns neutrality and suggests a compromise plan in which Agent-4 undergoes additional safety training and more sophisticated monitoring, and therefore OpenBrain can proceed at almost-full-speed.
Our uncertainty continues to increase
The slowdown ending is not a recommendation
Read the original article
Comments
I think we've actually had capable AIs for long enough now to see that this kind of exponential advance to AGI in 2 years is extremely unlikely. The AI we have today isn't radically different from the AI we had in 2023. They are much better at the thing they are good at, and there are some new capabilities that are big, but they are still fundamentally next-token predictors. They still fail at larger scope longer term tasks in mostly the same way, and they are still much worse at learning from small amounts of data than humans. Despite their ability to write decent code, we haven't seen the signs of a runaway singularity as some thought was likely.
I see people saying that these kinds of things are happening behind closed doors, but I haven't seen any convincing evidence of it, and there is enormous propensity for AI speculation to run rampant.
> there are some new capabilities that are big, but they are still fundamentally next-token predictors
Anthropic recently released research where they saw how when Claude attempted to compose poetry, it didn't simply predict token by token and "react" to when it thought it might need a rhyme and then looked at its context to think of something appropriate, but actually saw several tokens ahead and adjusted for where it'd likely end up, ahead of time.
Anthropic also says this adds to evidence seen elsewhere that language models seem to sometimes "plan ahead".
Please check out the section "Planning in poems" here; it's pretty interesting!
https://transformer-circuits.pub/2025/attribution-graphs/bio...
By percentcer 2025-04-0419:116 reply Isn't this just a form of next token prediction? i.e. you'll keep your options open for a potential rhyme if you select words that have many associated rhyming pairs, and you'll further keep your options open if you focus on broad topics over niche
Assuming the task remains just generating tokens, what sort of reasoning or planning would say is the threshold, before it's no longer "just a form of next token prediction?"
This is an interesting question, but it seems at least possible that as long as the fundamental operation is simply "generate tokens", that it can't go beyond being just a form of next-token prediction. I don't think people were thinking of human thought as a stream of tokens until LLMs came along. This isn't a very well-formed idea, but we may require an AI for which "generating tokens" is just one subsystem of a larger system, rather than the only form of output and interaction.
But that means any AI that just talks to you can't be AI by definition. No matter how decisively the AI passes the Turing test, it doesn't matter. It could converse with the top expert in any field as an equal, solve any problem you ask it to solve in math or physics, write stunningly original philosophy papers, or gather evidence from a variety of sources, evaluate them, and reach defensible conclusions. It's all just generating tokens.
Historically, a computer with these sorts of capabilities has always been considered true AI, going back to Alan Turing. Also of course including all sorts of science fiction, from recent movies like Her to older examples like Moon Is A Harsh Mistress.
I don't mean that the primary (or only) way that it interacts with a human can't be just text. Right now, the only way it interacts with anything is by generating a stream of tokens. To make any API calls, to use any tool, to make any query for knowledge, it is predicting tokens in the same way as it does when a human asks it a question. There may need to be other subsystems that the LLM subsystem interfaces with to make a more complete intelligence that can internally represent reality and fully utilize abstraction and relations.
By Hugsun 2025-04-1722:35 I have not yet found any compelling evidence that suggests that there are limits to the maximum intelligence of a next token predictor.
Models can be trained to generate tokens with many different meanings, including visual, auditory, textual, and locomotive. Those alone seem sufficient to emulate a human to me.
It would certainly be cool to integrate some subsystems like a symbolic reasoner or calculator or something, but the bitter lesson tells us that we'd be better off just waiting for advancements in computing power.
By z7 2025-04-0515:12 It's just predicting tokens:
https://old.reddit.com/r/singularity/comments/1jl5qfs/its_ju...
By LoveMortuus 2025-04-0914:31 I think one of the massive hurdles, maybe, to overcome when trying to achieve AGI, is how do you solve the issue of doing things without being prompted, you know curiosity and such.
Let's say we have a humanoid robot standing in a room that has a window open, at what point would the AI powering the robot decide that it's time to close the window?
That's probably one of the reasons why, I don't really see LLMs as much more than just algorithms that give us different responses just because we keep changing the seed...
By hnaccount_rng 2025-04-058:45 I'm not sure if this is a meaningful distinction: Fundamentally you can describe the world as a "next token predictor". Just treat the world als a simulator with a time step of some quantum of time.
That _probably_ won't capture everything, but for all practical purposes it's non-distinguishable from reality (yes, yes, time is not some constant everywhere)
By fennecfoxy 2025-04-0811:05 Yeah, I'd agree that for that model (certainly not AGI) it's just an extension/refinement of next token prediction.
But when we get a big aggregated of all of these little rules and quirks and improvements and subsystems for triggering different behaviours and processes - isn't that all humans are?
I don't think it'll happen for a long ass time, but I'm not one of those individuals who, for some reason, desperately want to believe that humans are special, that we're some magical thing that's unexplainable or can't be recreated.
By pertymcpert 2025-04-0422:11 It doesn't really make explain it because then you'd expect lots of nonsensical lines trying to make a sentence that fits with the theme and rhymes at the same time.
By throwuxiytayq 2025-04-0419:302 reply In the same way that human brains are just predicting the next muscle contraction.
By fennecfoxy 2025-04-0811:151 reply Potentially, but I'd say we're more reacting.
I will feel and itch and subconsciously scratch it, especially if I'm concentrating on something. That's an subsystem independent of conscious thought.
I suppose it does make sense - that our early evolution consisted of a bunch of small, specific background processes that enables an individual's life to continue; a single celled organism doesn't have neurons but exactly these processes - chemical reactions that keep it "alive".
Then I imagine that some of these processes became complex enough that they needed to be represented by some form of logic, hence evolving neurons.
Subsequently, organisms comprised of many thousands or more of such neuronal subsystems developed higher order subsystems to be able to control/trigger those subsystems based on more advanced stimuli or combinations thereof.
And finally us. I imagine the next step, evolution found that consciousness/intelligence, an overall direction of the efforts of all of these subsystems (still not all consciously controlled) and therefore direction of an individual was much more effective; anticipation, planning and other behaviours of the highest order.
I wouldn't be surprised if, given enough time and the right conditions, that sustained evolution would result in any or most creatures on this planet evolving a conscious brain - I suppose we were just lucky.
By throwuxiytayq 2025-04-107:151 reply I feel like the barrier between conscious and unconscious thinking is pretty fuzzy, but that could be down to the individual.
I also think the difference between primitive brains and conscious, reasoning, high level brains could be more quantitative than qualitative. I certainly believe that all mammals (and more) have some sort of an internal conscious experience. And experiments have shown that all sorts of animals are capable of solving simple logical problems.
Also, related article from a couple of days ago: Intelligence Evolved at Least Twice in Vertebrate Animals
By fennecfoxy 2025-04-1011:08 Great points, but my apologies I meant to say "sentience". Certainly many, many animals are already conscious.
I'm not sure about the quantitative thing seeing as there are creatures with brains much physically much larger than ours, or brains with more neurons than we have. We currently have the most known synapses though that also seems to be because we haven't estimated that for so many species.
By alfalfasprout 2025-04-0419:462 reply Except that's not how it works...
By Workaccount2 2025-04-0420:57 To be fair, we don't actually know how the human mind works.
The most sure things we know is that it is a physical system, and that does feel like something to be one of these systems.
By ToValueFunfetti 2025-04-0518:28 It may well be: https://en.m.wikipedia.org/wiki/Predictive_coding
By rcrsvpreordnmnt 2025-04-059:49 recursive predestination. LLM's algorithms imply 'self-sabotage' in order to 'learn the strings' of 'the' origin.
By childintime 2025-04-0511:04 LLM do exactly the same thing humans do: we read the text, raise flag, and flags on flags, on the various topics the text reminds us of, positive and negative, and then starts writing out a response that corresponds to those flags and likely attends to all of them. the planning ahead is just some flag that needs addressing, but it's learnt predictive behavior. nothing much to see here. experience gives you the flags. it's like applying massive pressure and diamonds will form.
By benlivengood 2025-04-0418:022 reply METR [0] explicitly measures the progress on long term tasks; it's as steep a sigmoid as the other progress at the moment with no inflection yet.
As others have pointed out in other threads RLHF has progressed beyond next-token prediction and modern models are modeling concepts [1].
[0] https://metr.org/blog/2025-03-19-measuring-ai-ability-to-com...
[1] https://www.anthropic.com/news/tracing-thoughts-language-mod...
At the risk of coming off like a dolt and being super incorrect: I don't put much stock into these metrics when it comes to predicting AGI. Even if the trend of "length of task an AI can reliably do doubles every 7 months" continues, as they say that means we're years away from AI that can complete tasks that take humans weeks or months. I'm skeptical that the doubling trend will continue into that timescale, I think there is a qualitative difference between tasks that take weeks or months and tasks that take minutes or hours, a difference that is not reflected by simple quantity. I think many people responsible for hiring engineers are keenly aware of this distinction, because of their experience attempting to choose good engineers based on how they perform in task-driven technical interviews that last only hours.
Intelligence as humans have it seems like a "know it when you see it" thing to me, and metrics that attempt to define and compare it will always be looking at only a narrow slice of the whole picture. To put it simply, the gut feeling I get based on my interactions with current AI, and how it is has developed over the past couple of years, is that AI is missing key elements of general intelligence at its core. While there's more lots more room for its current approaches to get better, I think there will be something different needed for AGI.
I'm not an expert, just a human.
By Enginerrrd 2025-04-0419:37 There is definitely something qualitatively different about weeks/months long tasks.
It reminds me of the difference between a fresh college graduate and an engineer with 10 years of experience. There are many really smart and talented college graduates.
But, while I am struggling to articulate exactly why, I know that when I was a fresh graduate, despite my talent and ambition, I would have failed miserably at delivering some of the projects that I now routinely deliver over time periods of ~1.5 years.
I think LLM's are really good at emulating the types of things I might say are the types of things that would make someone successful at this if I were to write it down in a couple paragraphs, or an article, or maybe even a book.
But... knowing those things as written by others just would not quite cut it. Learning at those time scales is just very different than what we're good at training LLM's to do.
A college graduate is in many ways infinitely more capable than a LLM. Yet there are a great many tasks that you just can't give an intern if you want them to be successful.
There are at least half a dozen different 1000-page manuals that one must reference to do a bare bones approach at my job. And there are dozens of different constituents, and many thousands of design parameters I must adhere to. Fundamentally, all of these things often are in conflict and it is my job to sort out the conflicts and come up with the best compromise. It's... really hard to do. Knowing what to bend so that other requirements may be kept rock solid, who to negotiate with for different compromises needed, which fights to fight, and what a "good" design looks like between alternatives that all seem to mostly meet the requirements. Its a very complicated chess game where it's hopelessly impossible to brute force but you must see the patterns along the way that will point you like sign posts into a good position in the end game.
The way we currently train LLM's will not get us there.
Until an LLM can take things in it's context window, assess them for importance, dismiss what doesn't work or turns out to be wrong, completely dismiss everything it knows when the right new paradigm comes up, and then permanently alter its decision making by incorporating all of that information in an intelligent way, it just won't be a replacment for a human being.
By benlivengood 2025-04-0419:27 > I think there is a qualitative difference between tasks that take weeks or months and tasks that take minutes or hours, a difference that is not reflected by simple quantity.
I'd label that difference as long-term planning plus executive function, and wherever that overlaps with or includes delegation.
Most long-term projects are not done by a single human and so delegation almost always plays a big part. To delegate, tasks must be broken down in useful ways. To break down tasks a holistic model of the goal is needed where compartmentalization of components can be identified.
I think a lot of those individual elements are within reach of current model architectures but they are likely out of distribution. How many gantt charts and project plans and project manager meetings are in the pretraining datasets? My guess is few; rarely published internal artifacts. Books and articles touch on the concepts but I think the models learn best from the raw data; they can probably tell you very well all of the steps of good project management because the descriptions are all over the place. The actual doing of it is farther toward the tail of the distribution.
The METR graph proposes a 6 year trend, based largely on 4 datapoints before 2024. I get that it is hard to do analyses since were in uncharted territory, and I personally find a lot of the AI stuff impressive, but this just doesn't strike me as great statistics.
By benlivengood 2025-04-0419:18 I agree that we don't have any good statistical models for this. If AI development were that predictable we'd likely already be past a singularity of some sort or in a very long winter just by reverse-engineering what makes the statistical model tick.
> we haven't seen the signs of a runaway singularity as some thought was likely.
The signs are not there but while we may not be on an exponential curve (which would be difficult to see), we are definitely on a steep upward one which may get steeper or may fizzle out if LLM's can only reach human level 'intelligence' but not surpass it. Original article was a fun read though and 360,000 words shorter than my very similar fiction novel :-)
LLMs don’t have any sort of intelligence at present, they have a large corpus of data and can produce modified copies of it.
By EMIRELADERO 2025-04-0422:051 reply While certainly not human-level intelligence, I don't see how you could say they don't have any sort of it. There's clearly generalization there. What would you say is the threshold?
Seems like you’d have to prove the inverse.
The threshold would be “produce anything that isn’t identical or a minor transfiguration of input training data.”
In my experience my AI assistant in my code editor can’t do a damn thing that isn’t widely documented and sometimes botches tasks that are thoroughly documented (such as hallucinating parameters names that don’t exist). I can witness this when I reach the edge of common use cases where extending beyond the documentation requires following an implication.
For example, AI can’t seem to understand how to help me in any way with Terraform dynamic credentials because the documentation is very sparse, and it is not part of almost any blog posts or examples online. My definition the variable is populated dynamically and real aren’t shown anywhere. I get a lot of irrelevant nonsense suggestions on how to fix it.
AI is a great “amazing search engine” and it can string together combinations of logic that already exist in documentation and examples while changing some names here and there, but what looks like true understanding really is just token prediction.
IMO the massive amount of training data is making the man behind the curtain look way better than he is.
By EMIRELADERO 2025-04-0423:451 reply That's creativity, not intelligence. LLMs can be intelligent while having very little (or even none at all) creativity. I don't believe one necessarily requires the other.
That’s a garbage cop-out. Intelligence without creativity is not what AI companies are promising to deliver.
Intelligence without creativity is like selling dictionaries.
By EMIRELADERO 2025-04-050:091 reply That was an extreme example to illustrate the concept. My point is that reduced/little creativity (which is what the current models have) is not indicative of a total lack of intelligence.
By dangus 2025-04-0511:43 Boy have I got a dictionary to sell you!
By boznz 2025-04-0421:59 Agree, the "intelligence" part is definitely the missing link in all this, however humans are smart cookies, and can see there's a gap, so I expect someone, (not necessarily a major player,) will eventually figure "it" out.
By boznz 2025-04-0522:23 .. I would however add that the ending of my novel was far more exciting.
By killerstorm 2025-04-0515:54 False. We got from ~0% on SWE-bench to 63%. It's a huge increase of capability in 2 years.
It's like saying that both a baby who can make a few steps and an adult have capability of "walking". It's just wrong.
By OrangeMusic 2025-04-087:241 reply They still can't tell how many Rs in Strawberry
By senordevnyc 2025-04-0916:41 This is obviously false. Even 4o and o3-mini can do this.
By ComplexSystems 2025-04-0419:191 reply > They are much better at the thing they are good at, and there are some new capabilities that are big, but they are still fundamentally next-token predictors.
I don't really get this. Are you saying autoregressive LLMs won't qualify as AGI, by definition? What about diffusion models, like Mercury? Does it really matter how inference is done if the result is the same?
> Are you saying autoregressive LLMs won't qualify as AGI, by definition?
No, I am speculating that they will not reach capabilities that qualify them as AGI.
By otabdeveloper4 2025-04-0710:15 They will, we just need meatspace people to become dumber and more predictable. Making huge strides on that front, actually. (In no small part due to LLMs themselves, yeah.)
By uejfiweun 2025-04-0419:54 Isn't the brain kind of just a predictor as well, just a more complicated one? Instead of predicting and emitting tokens, we're predicting future outcomes and emitting muscle movements. Which is obviously different in a sense but I don't think you can write off the entire paradigm as a dead end just because the medium is different.
By byearthithatius 2025-04-0417:27 Disagree. We know it _can_ learn out of distribution capabilities based on similarities to other distributions. Like the TikZ Unicorn[1] (which was not in training data anywhere) or my code (which has variable names and methods/ideas probably not seen 1:1 in training).
IMO this out of distribution learning is all we need to scale to AGI. Sure there are still issues, it doesn't always know which distribution to pick from. Neither do we, hence car crashes.
[1]: https://arxiv.org/pdf/2303.12712 or on YT https://www.youtube.com/watch?v=qbIk7-JPB2c
By sqw3rl 2025-04-1619:53 the argument in the paper seems to be that coding ability is what leads to the tipping point. Eventually human-level (then superhuman) coders augment the AI research process until an AI research agent is developed, and it's exponential from there.
We know they are developing more advanced models, and we know they're secretive about it, but how advanced?... ¯\_(ツ)_/¯
By stego-tech 2025-04-045:1710 reply It’s good science fiction, I’ll give it that. I think getting lost in the weeds over technicalities ignores the crux of the narrative: even if this doesn’t lead to AGI, at the very least it’s likely the final “warning shot” we’ll get before it’s suddenly and irreversibly here.
The problems it raises - alignment, geopolitics, lack of societal safeguards - are all real, and happening now (just replace “AGI” with “corporations”, and voila, you have a story about the climate crisis and regulatory capture). We should be solving these problems before AGI or job-replacing AI becomes commonplace, lest we run the very real risk of societal collapse or species extinction.
The point of these stories is to incite alarm, because they’re trying to provoke proactive responses while time is on our side, instead of trusting self-interested individuals in times of great crisis.
No one's gonna solve anything. "Our" world is based on greedy morons concentrating power through hands of just morons who are happy to hit you with a stick. This system doesn't think about what "we" should or allowed to do, and no one's here is at the reasonable side of it either.
lest we run the very real risk of societal collapse or species extinction
Our part is here. To be replaced with machines if this AI thing isn't just a fart advertised as mining equipment, which it likely is. We run this risk, not they. People worked on their wealth, people can go f themselves now. They are fine with all that. Money (=more power) piles in either way.
No encouraging conclusion.
Thanks for the read. One could think that the answer is to simply stop being a part of it, but then again you're from the genus that outcompeted everyone else in staying alive. Nature is such a shitty joke by design, not sure how one is supposed to look at the hypothetical designer with warmth in their heart.
Fleshy meat sacks on a space rock eating one another alive and shitting them out on a march towards inevitable doom in the form of a (likely) painful and terrifying death is a genius design, no?
By Nition 2025-04-0621:29 "It's basically all just evil apes dukin' it out on a giant ball."
By 0x008 2025-04-058:17 Natur is actually designed really well, it’s a just a shitty joke for our race and the ones who have to give way for nature to run its course.
By Aeolun 2025-04-0410:50 I read for such a long time, and I still couldn’t get through that, even though it never got boring.
I like that it ends with a reference to Kushiel and Elua though.
By Davidzheng 2025-04-0415:06 Don't think it's correct to blame the fact that AI acceleration is the only viable self-protecting policy on "greedy morons".
> even if this doesn’t lead to AGI, at the very least it’s likely the final “warning shot” we’ll get before it’s suddenly and irreversibly here.
I agree that it's good science fiction, but this is still taking it too seriously. All of these "projections" are generalizing from fictional evidence - to borrow a term that's popular in communities that push these ideas.
Long before we had deep learning there were people like Nick Bostrom who were pushing this intelligence explosion narrative. The arguments back then went something like this: "Machines will be able to simulate brains at higher and higher fidelity. Someday we will have a machine simulate a cat, then the village idiot, but then the difference between the village idiot and Einstein is much less than the difference between a cat and the village idiot. Therefore accelerating growth[...]" The fictional part here is the whole brain simulation part, or, for that matter, any sort of biological analogue. This isn't how LLMs work.
We never got a machine as smart as a cat. We got multi-paragraph autocomplete as "smart" as the average person on the internet. Now, after some more years of work, we have multi-paragraph autocomplete that's as "smart" as a smart person on the internet. This is an imperfect analogy, but the point is that there is no indication that this process is self-improving. In fact, it's the opposite. All the scaling laws we have show that progress slows down as you add more resources. There is no evidence or argument for exponential growth. Whenever a new technology is first put into production (and receives massive investments) there is an initial period of rapid gains. That's not surprising. There are always low-hanging fruit.
We got some new, genuinely useful tools over the last few years, but this narrative that AGI is just around the corner needs to die. It is science fiction and leads people to make bad decisions based on fictional evidence. I'm personally frustrated whenever this comes up, because there are exciting applications which will end up underfunded after the current AI bubble bursts...
By afpx 2025-04-0513:13 If you gather up a couple million of the smartest people on earth along with a few trillion dollars, and you add in super ambitious people eager to be culturally deified, you significantly increase the chance for breakthroughs. It's all probabiliities, though. But, right now there's no better game to bet on.
>There is no evidence or argument for exponential growth
I think the growth you are thinking of, self improving AI, needs the AI to be as smart as a human developer/researcher to get going and we haven't got there yet. But we quite likely will at some point.
By maerF0x0 2025-04-0416:05 and the article specifically mentions the fictional company (clearly designed to generalize the Google/OpenAI's of the world) are supposedly (according to the article) working on building that capability. First by augmenting human researchers, later by augmenting itself.
> Someday we will have a machine simulate a cat, then the village idiot... This isn't how LLMs work.
I think you misunderstood that argument. The simulate the brain thing isn't a "start from the beginning" argument, it's an "answer a common objection" argument.
Back around 2000, when Nick Bostrom was talking about this sort of thing, computers were simply nowhere near powerful enough to come even close to being smart enough to outsmart a human, except in very constrained cases like chess; we did't even have the first clue how to create a computer program to be even remotely dangerous to us.
Bostrom's point was that, "We don't need to know the computer program; even if we just simulate something we know works -- a biological brain -- we can reach superintelligence in a few decades." The idea was never that people would actually simulate a cat. The idea is, if we don't think of anything more efficient, we'll at least be able to simulate a cat, and then an idiot, and then Einstein, and then something smarter. And since we almost certainly will think of something more efficient than "simulate a human brain", we should expect superintelligence to come much sooner.
> There is no evidence or argument for exponential growth.
Moore's law is exponential, which is where the "simulate a brain" predictions have come from.
> It is science fiction and leads people to make bad decisions based on fictional evidence.
The only "fictional evidence" you've actually specified so far is the fact that there's no biological analog; and that (it seems to me) is from a misunderstanding of a point someone else was making 20 years ago, not something these particular authors are making.
I think the case for AI caution looks like this:
A. It is possible to create a superintelligent AI
B. Progress towards a superintelligent AI will be exponential
C. It is possible that a superintelligent AI will want to do something we wouldn't want it to do; e.g., destroy the whole human race
D. Such an AI would be likely to succeed.
Your skepticism seems to rest on the fundamental belief that either A or B is false: that superintelligence is not physically possible, or at least that progress towards it will be logarithmic rather than exponential.
Well, maybe that's true and maybe it's not; but how do you know? What justifies your belief that A and/or B are false so strongly, that you're willing to risk it? And not only willing to risk it, but try to stop people who are trying to think about what we'd do if they are true?
What evidence would cause you to re-evaluate that belief, and consider exponential progress towards superintelligence possible?
And, even if you think A or B are unlikely, doesn't it make sense to just consider the possibility that they're true, and think about how we'd know and what we could do in response, to prevent C or D?
By Vegenoid 2025-04-0419:22 > Moore's law is exponential, which is where the "simulate a brain" predictions have come from.
To address only one thing out of your comment, Moore's law is not a law, it is a trend. It just gets called a law because it is fun. We know that there are physical limits to Moore's law. This gets into somewhat shaky territory, but it seems that current approaches to compute can't reach the density of compute power present in a human brain (or other creatures' brains). Moore's law won't get chips to be able to simulate a human brain, with the same amount of space and energy as a human brain. A new approach will be needed to go beyond simply packing more transistors onto a chip - this is analogous to my view that current AI technology is insufficient to do what human brains do, even when taken to their limit (which is significantly beyond where they're currently at).
> The idea is, if we don't think of anything more efficient, we'll at least be able to simulate a cat, and then an idiot, and then Einstein, and then something smarter. And since we almost certainly will think of something more efficient than "simulate a human brain", we should expect superintelligence to come much sooner.
The problem with this argument is that it's assuming that we're on a linear track to more and more intelligent machines. What we have with LLMs isn't this kind of general intelligence.
We have multi-paragraph autocomplete that's matching existing texts more and more closely. The resulting models are great priors for any kind of language processing and have simple reasoning capabilities in so far as those are present in the source texts. Using RLHF to make the resulting models useful for specific tasks is a real achievement, but doesn't change how the training works or what the original training objective was.
So let's say we continue along this trajectory and we finally have a model that can faithfully reproduce and identify every word sequence in its training data and its training data includes every word ever written up to that point. Where do we go from here?
Do you want to argue that it's possible that there is a clever way to create AGI that has nothing to do with the way current models work and that we should be wary of this possibility? That's a much weaker argument than the one in the article. The article extrapolates from current capabilities - while ignoring where those capabilities come from.
> And, even if you think A or B are unlikely, doesn't it make sense to just consider the possibility that they're true, and think about how we'd know and what we could do in response, to prevent C or D?
This is essentially https://plato.stanford.edu/entries/pascal-wager/
It might make sense to consider, but it doesn't make sense to invest non-trivial resources.
This isn't the part that bothers me at all. I know people who got grants from, e.g., Miri to work on research in logic. If anything, this is a great way to fund some academic research that isn't getting much attention otherwise.
The real issue is that people are raising ridiculous amounts of money by claiming that the current advances in AI will lead to some science fiction future. When this future does not materialize it will negatively affect funding for all work in the field.
And that's a problem, because there is great work going on right now and not all of it is going to be immediately useful.
By 0x008 2025-04-058:26 I think the idea with LLMs leading to AGI is more like:
Natural language is a fuzzy context aware state machine of some sorts that can theoretically represent any arbitrarily complex state in the outside world given enough high quality text.
And by reiterating and extrapolating the rules found in human communication an AI could by the sheer ability to simulate infinitely long discussions discover new things, given the ability to independently verify outcomes.
By hannasanarion 2025-04-0417:17 > So let's say we continue along this trajectory and we finally have a model that can faithfully reproduce and identify every word sequence in its training data and its training data includes every word ever written up to that point. Where do we go from here?
This is a fundamental misunderstanding of the entire point of predictive models (and also of how LLMs are trained and tested).
For one thing, ability to faithfully reproduce texts is not the primary scoring metric being used for the bulk of LLM training and hasn't been for years.
But more importantly, you don't make a weather model so that it can inform you of last Tuesday's weather given information from last Monday, you use it to tell you tomorrow's weather given information from today. The totality of today's temperatures, winds, moistures, and shapes of broader climatic patterns, particulates, albedos, etc etc etc have never happened before, and yet the model tells us something true about the never-before-seen consequences of these never-before-seen conditions, because it has learned the ability to reason new conclusions from new data.
Are today's "AI" models a glorified autocomplete? Yeah, but that's what all intelligence is. The next word I type is the result of an autoregressive process occurring in my brain that produces that next choice based on the totality of previous choices and experiences, just like the Q-learners that will kick your butt in Starcraft choose the best next click based on their history of previous clicks in the game combined with things they see on the screen, and will have pretty good guesses about which clicks are the best ones even if you're playing as Zerg and they only ever trained against Terran.
A highly accurate autocomplete that is able to predict the behavior and words of a genius, when presented with never before seen evidence, will be able to make novel conclusions in exactly the same way as the human genius themselves would when shown the same new data. Autocomplete IS intelligence.
New ideas don't happen because intelligences draw them out of the aether, they happen because intelligences produce new outputs in response to stimuli, and those stimuli can be self-inputs, that's what "thinking" is.
If you still think that all today's AI hubbub is just vacuous hype around an overblown autocomplete, try going to Chatgpt right now. Click the "deep research" button, and ask it "what is the average height of the buildings in [your home neighborhood]"?, or "how many calories are in [a recipe that you just invented]", or some other inane question that nobody would have ever cared to write about ever before but is hypothetically answerable from information on the internet, and see if what you get is "just a reproduced word sequence from the training data".
> We have multi-paragraph autocomplete that's matching existing texts more and more closely.
OK, I think I see where you're coming from. It sounds like what you're saying is:
E. LLMs only do multi-paragraph autocomplete; they are and always will be incapable of actual thinking.
F. Any approach capable of achieving AGI will be completely different in structure. Who knows if or when this alternate approach will even be developed; and if it is developed, we'll be starting from scratch, so we'll have plenty of time to worry about progress then.
With E, again, it may or may not be true. It's worth noting that this is a theoretical argument, not an empirical one; but I think it's a reasonable assumption to start with.
However, there are actually theoretical reasons to think that E may be false. The best way to predict the weather is to have an internal model which approximates weather systems; the best way to predict the outcome of a physics problem is to have an internal model which approximates the physics of the thing you're trying to predict. And the best way to predict what a human would write next is to have a model of a human mind -- including a model of what the human mind has in its model (e.g., the state of the world).
There is some empirical data to support this argument, albeit in a very simplified manner: They trained a simple LLM to predict valid moves for Othello, and then probed it and discovered an internal Othello board being simulated inside the neural network:
https://thegradient.pub/othello/
And my own experience with LLMs better match the "LLMs have an internal model of the world" theory than the "LLMs are simply spewing out statistical garbage" theory.
So, with regard to E: Again, sure, LLMs may turn out to be a dead end. But I'd personally give the idea that LLMs are a complete dead end a less than 50% probability; and I don't think giving it an overwhelmingly high probability (like 1 in a million of being false) is really reasonable, given the theoretical arguments and empirical evidence against it.
With regard to F, again, I don't think this is true. We've learned so much about optimizing and distilling neural nets, optimizing training, and so on -- not to mention all the compute power we've built up. Even if LLMs are a dead end, whenever we do find an architecture capable of achieving AGI, I think a huge amount of the work we've put into optimizing LLMs will put is way ahead in optimizing this other system.
> ...that the current advances in AI will lead to some science fiction future.
I mean, if you'd told me 5 years ago that I'd be able to ask a computer, "Please use this Golang API framework package to implement CRUD operations for this particular resource my system has", and that the resulting code would 1) compile out of the box, 2) exhibit an understanding of that resource and how it relates to other resources in the system based on having seen the code implementing those resources 3) make educated guesses (sometimes right, sometimes wrong, but always reasonable) about details I hadn't specified, I don't think I would have believed you.
Even if LLM progress is logarithmic, we're already living in a science fiction future.
EDIT: The scenario actually has very good technical "asides"; if you want to see their view of how a (potentially dangerous) personality emerges from "multi-paragraph auto-complete", look at the drop-down labelled "Alignment over time", and specifically what follows "Here’s a detailed description of how alignment progresses over time in our scenario:".
By gwd 2025-04-0520:26 > E. LLMs only do multi-paragraph autocomplete; they are and always will be incapable of actual thinking.
FWIW, this guy thinks E is true, and that he has a better direction to head in:
https://www.youtube.com/watch?v=ETZfkkv6V7Y
HN discussion about a related article I didn't read:
By vonneumannstan 2025-04-0415:043 reply >All of these "projections" are generalizing from fictional evidence - to borrow a term that's popular in communities that push these ideas.
This just isn't correct. Daniel and others on the team are experienced world class forecasters. Daniel wrote another version of this in 2021 predicting the AI world in 2026 and was astonishingly accurate. This deserves credence.
https://www.lesswrong.com/posts/6Xgy6CAf2jqHhynHL/what-2026-...
>he arguments back then went something like this: "Machines will be able to simulate brains at higher and higher fidelity.
Complete misunderstanding of the underlying ideas. Just in not even wrong territory.
>We got some new, genuinely useful tools over the last few years, but this narrative that AGI is just around the corner needs to die. It is science fiction and leads people to make bad decisions based on fictional evidence.
You are likely dangerously wrong. The AI field is near universal in predicting AGI timelines under 50 years. With many under 10. This is an extremely difficult problem to deal with and ignoring it because you think it's equivalent to overpopulation on mars is incredibly foolish.
https://www.metaculus.com/questions/5121/date-of-artificial-...
https://wiki.aiimpacts.org/doku.php?id=ai_timelines:predicti...
I respect the forecasting abilities of the people involved, but I have seen that report described as "astonishingly accurate" a few times and I'm not sure that's true. The narrative format lends itself somewhat to generous interpretation and it's directionally correct in a way that is reasonably impressive from 2021 (e.g. the diplomacy prediction, the prediction that compute costs could be dramatically reduced, some things gesturing towards reasoning/chain of thought) but many of the concrete predictions don't seem correct to me at all, and in general I'm not sure it captured the spiky nature of LLM competence.
I'm also struck by the extent to which the first series from 2021-2026 feels like a linear extrapolation while the second one feels like an exponential one, and I don't see an obvious justification for this.
By vonneumannstan 2025-04-0713:32 Yeah funny how that works: https://149909199.v2.pressablecdn.com/wp-content/uploads/201...
By Workaccount2 2025-04-0415:431 reply >2025:...Making models bigger is not what’s cool anymore. They are trillions of parameters big already. What’s cool is making them run longer, in bureaucracies of various designs, before giving their answers.
Dude was spot on in 2021, hot damn.
By fennecfoxy 2025-04-1011:14 I mean MoE/agent work was being done in 2021 I'm pretty sure. Definitely more accurate than most predictions but perhaps not revolutionary to state that the tail follows the dog.
By arduanika 2025-04-0519:20
By whiplash451 2025-04-0414:081 reply > there are exciting applications which will end up underfunded after the current AI bubble bursts
Could you provide examples? I am genuinely interested.
By fmap 2025-04-056:54 I'm personally very excited about the progress in interactive theorem proving. Before the current crop of deep learning heuristics there was no generally useful higher-order automated theorem proving system. Automated theorem proving could prove individual statements based on existing lemmas, but that only works in extremely restricted settings (propositional or first-order logic). The problem is that in order to apply a statement of the form "for all functions with this list of properties, ..." you need to come up with a function that's related to what you're trying to prove. This is equivalent to coming up with new lemmas and definitions, which is the actually challenging part of doing mathematics or verification.
There has finally been progress here, which is why you see high-profile publications from, e.g., Deepmind about solving IMO problems in Lean. This is exciting, because if you're working in a system like Coq or Lean your progress is monotone. Everything you prove actually follows from the definitions you put in. This is in stark contrast to, e.g., using LLMs for programming, where you end up with a tower of bugs and half-working code if you don't constantly supervise the output.
---
But well, the degree of excitement is my own bias. From other people I spoke to recently: - Risk-assessment diagnostics in medicine. There are a bunch of tests that are expensive and complex to run and need a specialist to evaluate. Deep learning is increasingly used to make it possible to do risk assessments with cheaper automated tests for a large population and have specialists focus on actual high-risk cases. Progress is slow for various reasons, but it has a lot of potential. - Weather forecasting uses a sparse set of inputs: atmospheric data from planes, weather baloons, measurements at ground stations, etc. This data is then aggregated with relatively stupid models to get the initial conditions to run a weather simulation. Deep learning is improving this part, but while there has been some encouraging initial progress this needs to be better integrated with existing simulations (purely deep learning based approaches are apparently a lot worse at predicting extreme weather events). Those simulations are expensive, they're running on some of the largest supercomputers in the world, which is why progress is slow.
By whiplash451 2025-04-0414:101 reply There is no need to simulate Einstein to transform the world with AI.
A self-driving car would already be plenty.
By skydhash 2025-04-0417:08 And a self driving car is not even necessary if we’re thinking about solving transportation problems. Train and bus are better at solving road transportation at scale.
You don’t just beat around the bush here. You actually beat the bush a few times.
Large corporations, governments, institutionalized churches, political parties, and other “corporate” institutions are very much like a hypothetical AGI in many ways: they are immortal, sleepless, distributed, omnipresent, and possess beyond human levels of combined intelligence, wealth, and power. They are mechanical Turk AGIs more or less. Look at how humans cycle in, out, and through them, often without changing them much, because they have an existence and a weird kind of will independent of their members.
A whole lot, perhaps all, of what we need to do to prepare for a hypothetical AGI that may or may not be aligned consists of things we should be doing to restrain and ensure alignment of the mechanical Turk variety. If we can’t do that we have no chance against something faster and smarter.
What we have done over the past 50 years is the opposite: not just unchain them but drop any notion that they should be aligned.
Are we sure the AI alignment discourse isn’t just “occulted” progressive political discourse? Back when they burned witches philosophers would encrypt possibly heretical ideas in the form of impenetrable nonsense, which is where what we call occultism comes from. You don’t get burned for suggesting steps to align corporate power, but a huge effort has been made to marginalize such discourse.
Consider a potential future AGI. Imagine it has a cult of followers around it, which it probably would, and champions that act like present day politicians or CEOs for it, which it probably would. If it did not get humans to do these things for it, it would have analogous functions or parts of itself.
Now consider a corporation or other corporate entity that has all those things but replace the AGI digital brain with a committee or shareholders.
What, really, is the difference? Both can be dangerously unaligned.
Other than perhaps in magnitude? The real digital AGI might be smarter and faster but that’s the only difference I see.
By samspot 2025-04-0815:43 Great comment, and I love the thought process. My answer to the question: What is the difference? Humans and corporations are exceedingly predictable. We know what they both want, generally. We also rely on human issues as a limiting factor.
For an AI controlled corporation, I don't know what it wants or what to expect. And if decision making happens at the speed of light, by the time we have any warning it may be too late to react. Usually with human concerns, we get lots of warnings but wait longer than we should to respond.
I looked but I couldn’t find any evidence that “occultism” comes from encryption of heretical ideas. It seems to have been popularized in renaissance France to describe the study of hidden forces. I think you may be hallucinating here.
> The problems it raises - alignment, geopolitics, lack of societal safeguards - are all real, and happening now (just replace “AGI” with “corporations”, and voila, you have a story about the climate crisis and regulatory capture).
Can you point to the data that suggests these evil corporations are ruining the planet? Carbon emissions are down in every western country since 1990s. Not down per-capita, but down in absolute terms. And this holds even when adjusting for trade (i.e. we're not shipping our dirty work to foreign countries and trading with them). And this isn't because of some regulation or benevolence. It's a market system that says you should try to produce things at the lowest cost and carbon usage is usually associated with a cost. Get rid of costs, get rid of carbon.
Other measures for Western countries suggests the water is safer and overall environmental deaths have decreased considerably.
The rise in carbon emissions is due to Chine and India. Are you talking about evil Chinese and Indians corporations?
By lordswork 2025-04-0417:57 Emissions are trending downward because of shift from coal to natural gas, growth in renewable energy, energy efficiencies, among other things. Major oil and gas companies in the US like Chevron and ExxonMobil have spent millions on lobbying efforts to resist stricter climate regulations and fight against the changes that led to this trend, so I'd say they are the closest to these evil corporations OP described. Additionally, the current administration refers to doing anything about climate change a "climate religion", so this downward trend will likely slow.
The climate regulations are still quite weak. Without a proper carbon tax, a US company can externalize the costs of carbon emissions and get rich by maximizing their own emissions.
Thanks for letting us know everything is fine, just in case we get confused and think the opposite.
You're welcome. I know too many upper middle class educated people that don't want to have kids because they believe the earth will cease to be inhabitable in the next 10 years. It's really bizarre to see and they'll almost certainly regret it when they wake up one day alone in a nursing home, look around and realize that the world still exists.
And I think the neuroticism around this topic has led young people into some really dark places (anti-depressants, neurotic anti social behavior, general nihilism). So I think it's important to fight misinformation about end of world doomsday scenarios with both facts and common sense.
I think you're discrediting yourself by talking about dark places and opening your parentheses with anti-depressants.
Not all brains function like they're supposed to, people getting help they need shouldn't be stigmatized.
You also make no argument about your take on things being the right one, you just oppose their worldview to yours and call theirs wrong like you know it is rather than just you thinking yours is right.
By bko 2025-04-0419:55 Not sure if you're up on the literature but the chemical imbalance theory of depression has been disproven (or at least no evidence for it).
No one is stigmatizing anything. Just that if you consume doom porn it's likely to affect your attitudes towards life. I think it's a lot healthier to believe you can change your circumstances than to believe you are doomed because you believe you have the wrong brain
https://www.nature.com/articles/s41380-022-01661-0
https://www.quantamagazine.org/the-cause-of-depression-is-pr...
https://www.ucl.ac.uk/news/2022/jul/analysis-depression-prob...
He must be talking about the good, benevolent Western corporations that have outsourced their carbon emissions to the evil and greedy Chinese and Indian corporations.
By bko 2025-04-0415:18 As addressed in my original comment, it's down even adjusting for trade
By philipwhiuk 2025-04-0415:101 reply > Can you point to the data that suggests these evil corporations are ruining the planet?
Can you point to data that this is 'because' of corporations rather than despite them.
By philipwhiuk 2025-04-0615:58
By jplusequalt 2025-04-0415:141 reply I think a healthy amount of skepticism is warranted when reading about the "reduction" of carbon emissions by companies. Why should we take them at their word when they have a vested interest in fudging the numbers?
By bko 2025-04-0415:20 Carbon emissions are monitored by dozens of independent agencies in many different ways over decades. It would be a giant scale coordination of suppression. Do you have a source that suggests carbon emissions from Western nations is rising?
The most amusing thing about is the unshakable belief that any part of humanity will be able to build a single nuclear reactor by 2027 to power datacenters, let alone a network of them.
By bronco21016 2025-04-0423:52 According to Wikipedia, China had 22 under construction as of 2023 for 24 GW of power. They have a goal of 150 by 2035.
I think they'll probably be able to finish at least 1-2 by 2027.
By YetAnotherNick 2025-04-0410:392 reply > very real risk of societal collapse or species extinction
No, there is no risk of species extinction in the near future due to climate change and repeating the line will just further the divide and make the people not care about other people's and even real climate scientist's words.
Don’t say the things people don’t want to hear and everything will be fine?
That sounds like the height of folly.
By YetAnotherNick 2025-04-0419:24 Don't say false things. Especially if it is political and there isn't any way to debate it.
The risk is a quantifiable 0.0%? I find that hard to believe. I think the current trends suggest there is a risk that continued environmental destruction could annihilate society.
Risk can never be zero, just like certainty can never be 100%.
There is a non-zero chance that the ineffable quantum foam will cause a mature hippopotamus to materialize above your bed tonight, and you’ll be crushed. It is incredibly, amazingly, limits-of-math unlikely. Still a non-zero risk.
Better to think of “no risk” as meaning “negligible risk”. But I’m with you that climate change is not a negligible risk; maybe way up in the 20% range IMO. And I wouldn’t be sleeping in my bed tonight if sudden hippos over beds were 20% risks.
By ttw44 2025-04-0412:15 Lol, I've always loved that about physics. Some boltzmann brain type stuff.
By SpicyLemonZest 2025-04-0418:48 It's hard to produce a quantifiable chance of human extinction in the absence of any model by which climate change would lead to it. No climate organization I'm aware of evaluates the end of humanity as even a worst-case risk; the idea simply doesn't exist outside the realm of viral Internet misinformation.
You said it right, science fiction. Honestly is exactly the tenor I would expect from the AI hype: this text is completely bereft of any rigour while being dressed up in scientific language. There's no evidence, nothing to support their conclusions, no explanation based on data or facts or supporting evidence. It's purely vibes based. Their promise is unironically "the CEOs of AI companies say AGI is 3 years away"! But it's somehow presented as this self important study! Laughable.
But it's par on course. Write prompts for LLMs to compete? It's prompt engineering. Tell LLMs to explain their "reasoning" (lol)? It's Deep Research Chain Of Thought. Etc.
By somebodythere 2025-04-0416:161 reply Did you see the supplemental material that explains how they arrived at their timelines/capabilities forecasts? https://ai-2027.com/research
By A_D_E_P_T 2025-04-0419:35 It's not at all clear that performance rises with compute in a linear way, which is what they seem to be predicting. GPT-4.5 isn't really that much smarter than 2023's GPT-4, nor is it at all smarter than DeepSeek.
There might be (strongly) diminishing returns past a certain point.
Most of the growth in AI capabilities has to do with improving the interface and giving them more flexibility. For e.g., uploading PDFs. Further: OpenAI's "deep research" which can browse the web for an hour and summarize publicly-available papers and studies for you. If you ask questions about those studies, though, it's hardly smarter than GPT-4. And it makes a lot of mistakes. It's like a goofy but earnest and hard-working intern.
By kelsey978126 2025-04-0412:54 bingo. many don't realize superintelligence exists today already, in the form of human super intelligence. artificial super intelligence is already here too, but just as hybrid human machine workloads. Fully automated super intelligence is no different from a corporation, a nation state, a religion. When does it count as ASI? when the chief executive is an AI? Or when they use AI to make decisions? Does it need to be at the board level? We are already here, all this changes is what labor humans will do and how they do it, not the amount.
I fail to see how corporations are responsible for the climate crisis: Politicians won't tax gas because they'll get voted out.
We know that Trump is not captured by corporations because his trade policies are terrible.
If anything, social media is the evil that's destroying the political center: Americans are no longer reading mainstream newspapers or watching mainstream TV news.
The EU is saying the elections in Romania was manipulated through manipulation of TikTok accounts and media.
If you put a knife in someone’s heart, you’re the one who did it and ultimately you’re responsible. If someone told you to do it and you were just following orders… you still did it. If you say there were no rules against putting knives in other people’s hearts, you still did it and you’re still responsible.
If it’s somehow different for corporations, please enlighten me how.
The oil companies are saying their product is vital to the economy and they are not wrong. How else will we get food from the farms to the store ? Ambulances to the hospitals ? And many, many other things.
Taxes are the best way to change behaviour (smaller cars driving less. Less flying etc). So government and the people who vote for them is to blame.
What if people are manipulated by bot farms and think tanks and talking points supported by those corporations?
I think this view of humans - that they look at all the available information and then make calm decisions in their own interests - is simply wrong. We are manipulated all the damn time. I struggle to go to the supermarket without buying excess sugar. The biggest corporations in the world grew fat off showing us products to impulse buy before our more rational brain functions could stop us. We are not a little pilot in a meat vessel.
Corporations would prefer lower corporate tax.
US corporate tax rates are actually every high. Partly due to the US having almost no consumption tax. EU members have VAT etc.
By player1234 2025-04-0911:28 Did you know that VAT is spelled TARRIF in retard?
By brookst 2025-04-0412:09 The oil companies also knew and lied about global warming for decades. They paid and continue to pay for as science to stall action. I am completely mystified how you can find them blameless for venal politicians and a populace that largely believes their lies.
By baq 2025-04-048:38 I agree with everything here, we've had a great run of economic expansion for basically two centuries and I like my hot showers as much as anyone - but that doesn't change the CO2 levels.
By matthewdgreen 2025-04-0411:17 There are politicians in multiple states trying to pass laws that slow down the deployment of renewable energy because they’re afraid if they don’t intervene it will be deployed too quickly and harm fossil fuel interests. Trump is promising to bring back coal, while he bans new wind leases. The whole “oil is the only way aw shucks people chose it” shtick is like a time capsule from 1990. That whole package of beliefs served its purpose and has been replaced with a muscular state-sponsored plan to defend fossil fuel interests even as they become economically obsolete and the rest of the world moves on.
> Politicians won't tax gas because they'll get voted out.
Have you seen gas tax rates in the EU?
> We know that Trump is not captured by corporations because his trade policies are terrible.
Unless you think it's a long con for some rich people to be able to time the market by getting him to crash it.
> The EU is saying the elections in Romania was manipulated through manipulation of TikTok accounts and media.
More importantly, Romanian courts say that too. And it was all out in the open, so not exactly a secret
Romainan courts say all kinds of things, many of them patently false. It's absurd to claim that since romanian courts say something, it must be true. It's absurd in principle, because there's nothing in the concept of a court that makes it infallible, and it's absurd in this precise case, because we are corrupt as hell.
I'm pretty sure the election was manipulated, but the court only said so because it benefits the incumbents, which control the courts and would lose their power.
It's a struggle between local thieves and putin, that's all. The local thieves will keep us in the EU, which is much better than the alternative, but come on. "More importantly, Romanian courts say so"? Really?
By sofixa 2025-04-0414:52 > I'm pretty sure the election was manipulated, but the court only said so because it benefits the incumbents, which control the courts and would lose their power.
Why do you think that's the only reason the court said so? The election law was pretty blatantly violated (he declared campaign funding of 0, yet tons of ads were bought for him and influencers paid to advertise him).
> Politicians won't tax gas because they'll get voted out.
I wonder if that's corporations' fault after all: shitty working conditions and shitty wages, so that Bezos can afford to send penises into space. What poor person would agree to higher tax on gas? And the corps are the ones backing politicians who'll propagandize that "Unions? That's communism! Do you want to be Chaina?!" (and spread by those dickheads on the corporate-owned TV and newspaper, drunk dickheads who end up becoming defense secretary)
By nroets 2025-04-048:59 When people have more money, they tend to buy larger cars that they drive further. Flying is also a luxury.
So corporations are involved in the sense that they pay people more than a living wage.
Whatever the future is, it is not American, not the United States. The US's cultural individualism has been Capitalistically weaponized, and the educational foundation to take the country forward is not there. The US is kaput, and we are merely observing the ugly demise. The future is Asia, with all of western culture going down. Yes, it is not pretty, The failed experiment of American self rule.
I agree but see it as less dire. All of western culture is not ending; it will be absorbed into a more Asia-dominated culture in much he was Asian culture was subsumed into western for the past couple of hundred years.
And if Asian culture is better educated and more capable of progress, that’s a good thing. Certainly the US has announced loud and clear that this is the end of the line for us.
By rchaud 2025-04-0413:36 > it will be absorbed into a more Asia-dominated culture in much he was Asian culture was subsumed into western for the past couple of hundred years.
Was Asian culture dominated by the west to any significant degree? Perhaps in countries like India where the legal and parliamentary system installed by the British remained intact for a long time post-independence.
Elsewhere in East and Southeast Asia, the legal systems, education, cultural traditions, and economic philosophies have been very different from the "west", i.e. post-WWII US and Western Europe.
The biggest sign of this is how they developed their own information networks, infrastructure and consumer networking devices. Europe had many of these regional champions themselves (Phillips, Nokia, Ericsson, etc) but now outside of telecom infrastructure, Europe is largely reliant on American hardware and software.
Of course it will not end, western culture just will no longer lead. Despite the sky falling perspective of many, it is simply an attitude adjustment. So one group is no longer #1, and the idea that I was part of that group, ever, was an illusion of propaganda anyway. Life will go on, surprisingly the same.
By nthingtohide 2025-04-0415:51 here's an example.
https://x.com/RnaudBertrand/status/1901133641746706581
I finally watched Ne Zha 2 last night with my daughters.
It absolutely lives up to the hype: undoubtedly the best animated movie I've ever seen (and I see a lot, the fate of being the father of 2 young daughters ).
But what I found most fascinating was the subtle yet unmistakable geopolitical symbolism in the movie.
Warning if you haven't yet watched the movie: spoilers!
So the story is about Ne Zha and Ao Bing, whose physical bodies were destroyed by heavenly lightning. To restore both their forms, they must journey to the Chan sect—headed by Immortal Wuliang—and pass three trials to earn an elixir that can regenerate their bodies.
The Chan sect is portrayed in an interesting way: a beacon of virtue that all strive to join. The imagery unmistakably refers to the US: their headquarters is an imposingly large white structure (and Ne Zha, while visiting it, hammers the point: "how white, how white, how white") that bears a striking resemblance to the Pentagon in its layout. Upon gaining membership to the Chan sect, you receive a jade green card emblazoned with an eagle that bears an uncanny resemblance to the US bald eagle symbol. And perhaps most telling is their prized weapon, a massive cauldron marked with the dollar sign...
Throughout the movie you gradually realize, in a very subtle way, that this paragon of virtue is, in fact, the true villain of the story. The Chan sect orchestrates a devastating attack on Chentang Pass—Ne Zha's hometown—while cunningly framing the Dragon King of the East Sea for the destruction. This manipulation serves their divide-and-conquer strategy, allowing them to position themselves as saviors while furthering their own power.
One of the most pointed moments comes when the Dragon King of the East Sea observes that the Chan sect "claims to be a lighthouse of the world but harms all living beings."
Beyond these explicit symbols, I was struck by how the film portrays the relationships between different groups. The dragons, demons, and humans initially view each other with suspicion, manipulated by the Chan sect's narrative. It's only when they recognize their common oppressor that they unite in resistance and ultimately win. The Chan sect's strategy of fostering division while presenting itself as the arbiter of morality is perhaps the key message of the movie: how power can be maintained through control of the narrative.
And as the story unfolds, Wuliang's true ambition becomes clear: complete hegemony. The Chan sect doesn't merely seek to rule—it aims to establish a system where all others exist only to serve its interests, where the dragons and demons are either subjugated or transformed into immortality pills in their massive cauldron. These pills are then strategically distributed to the Chan sect's closest allies (likely a pointed reference to the G7).
What makes Ne Zha 2 absolutely exceptional though is that these geopolitical allegories never overshadow the emotional core of the story, nor its other dimensions (for instance it's at times genuinely hilariously funny). This is a rare film that makes zero compromise, it's both a captivating and hilarious adventure for children and a nuanced geopolitical allegory for adults.
And the fact that a Chinese film with such unmistakable anti-American symbolism has become the highest-grossing animated film of all time globally is itself a significant geopolitical milestone. Ne Zha 2 isn't just breaking box office records—it's potentially rewriting the rules about what messages can dominate global entertainment.
People said the same thing about Japan but they ran into their own structural issues. It's going to happen to China as well. They've got demographic problems, rule of law problems, democracy problems, and on and on.
By nthingtohide 2025-04-0415:48 I really don't understand this : us vs them viewpoint. Here's a fictional scenario. Imagine Yellowstone erupts tomorrow and whole of America becomes inhabitable but Africa is unscathed. Now think about this, if America had "really" developed African continent, wouldn't it provide shelter to scurrying Americans. Many people forget, the real value of money is in what you can exchange it for. Having skilled people and associated RnD and subsequent products / services is what should have been encouraged by the globalists instead of just rent extraction or stealing. I don't understand the ultimate endgame for globalists. Do each of them desire to have 100km yacht with helicopter perched on it to ferry them back and forth?
By tim333 2025-04-0413:16 Perhaps but on the AI front most of the leading research has been in the US or UK, with China being a follower.
The story is entertaining, but it has a big fallacy - progress is not a function of compute or model size alone. This kind of mistake is almost magical thinking. What matters most is the training set.
During the GPT-3 era there was plenty of organic text to scale into, and compute seemed to be the bottleneck. But we quickly exhausted it, and now we try other ideas - synthetic reasoning chains, or just plain synthetic text for example. But you can't do that fully in silico.
What is necessary in order to create new and valuable text is exploration and validation. LLMs can ideate very well, so we are covered on that side. But we can only automate validation in math and code, but not in other fields.
Real world validation thus becomes the bottleneck for progress. The world is jealously guarding its secrets and we need to spend exponentially more effort to pry them away, because the low hanging fruit has been picked long ago.
If I am right, it has implications on the speed of progress. Exponential friction of validation is opposing exponential scaling of compute. The story also says an AI could be created in secret, which is against the validation principle - we validate faster together, nobody can secretly outvalidate humanity. It's like blockchain, we depend on everyone else.
Did we read the same article?
They clearly mention, take into account and extrapolate this; LLM have first scaled via data, now it's test time compute, but recent developments (R1) clearly show this is not exhausted yet (i.e. RL on synthetically (in-silico) generated CoT) which implies scaling with compute. The authors then outline further potential (research) developments that could continue this dynamic, literally things that have already been discovered just not yet incorporated into edge models.
Real-world data confirms their thesis - there have been a lot of sceptics about AI scaling, somewhat justified ("whoom" a.k.a. fast take-off hasn't happened - yet) but their fundamental thesis has been wrong - "real-world data has been exhausted, next algorithmic breakthroughs will be hard and unpredictable". The reality is, while data has been exhausted, incremental research efforts have resulted in better and better models (o1, r1, o3, and now Gemini 2.5 which is a huge jump! [1]). This is similar to how Moore's Law works - it's not given that CPUs get better exponentially, it still requires effort, maybe with diminishing returns, but nevertheless the law works...
If we ever get to models be able to usefully contribute to research, either on the implementation side, or on research ideas side (which they CANNOT yet, at least Gemini 2.5 Pro (public SOTA), unless my prompting is REALLY bad), it's about to get super-exponential.
Edit: then once you get to actual general intelligence (let alone super-intelligence) the real-world impact will quickly follow.
By Jianghong94 2025-04-0416:541 reply Well based on what I'm reading, the OP's intent is that, not all (hence 'fully') validation, if not most of, can be done in-silico. I think we all agree that and that's the major bottleneck making agents useful - you have to have human-in-the-loop to closely guardrail the whole process.
Of course you can get a lot of mileage via synthetically generated CoT but does that lead to LLM speed up developing LLM is a big IF.
No, the entire point of this article is that when you get to self-improving AI, it will become generally intelligent, then you can use that to solve robotics, medicine etc. (like a generally-intelligent baby can (eventually) solve how to move boxes, assemble cars, do experiments in labs etc. - nothing special about a human baby, it's just generally intelligent).
By Jianghong94 2025-04-0417:36 Not only does the article claim that when we get to self-improving ai it becomes generally intelligent, it's assuming that AI is pretty close right now:
> OpenBrain focuses on AIs that can speed up AI research. They want to win the twin arms races against China (whose leading company we’ll call “DeepCent”)16 and their US competitors. The more of their research and development (R&D) cycle they can automate, the faster they can go. So when OpenBrain finishes training Agent-1, a new model under internal development, it’s good at many things but great at helping with AI research.
> It’s good at this due to a combination of explicit focus to prioritize these skills, their own extensive codebases they can draw on as particularly relevant and high-quality training data, and coding being an easy domain for procedural feedback.
> OpenBrain continues to deploy the iteratively improving Agent-1 internally for AI R&D. Overall, they are making algorithmic progress 50% faster than they would without AI assistants—and more importantly, faster than their competitors.
> what do we mean by 50% faster algorithmic progress? We mean that OpenBrain makes as much AI research progress in 1 week with AI as they would in 1.5 weeks without AI usage.
To me, claiming today's AI IS capable of such thing is too hand-wavy. And I think that's the crux of the article.
By polynomial 2025-04-0417:47 You had me at "nothing special about a human baby"
By visarga 2025-04-0512:26 Yeah I think the math+code reasoning models, like o1 and r1, are doing what can be done with just pure compute without real world validation. But the real world is complex, we can't simulate it. Why do we make particle accelerators, fusion reactor prototypes, space telescopes, year long vaccine trials? It's because we need to validate ideas in the real world that cannot be done theoretically or computationally.
Best reply in this entire thread, and I align with your thinking entirely. I also absolutely hate this idea amongst tech-oriented communities that because an AI can do some algebra and program an 8-bit video game quickly and without any mistakes, it's already overtaking humanity. Extrapolating from that idea to some future version of these models, they may be capable of solving grad school level physics problems and programming entire AAA video games, but again - that's not what _humanity_ is about. There is so much more to being human than fucking programming and science (and I'm saying this as an actual nuclear physicist). And so, just like you said, the AI arm's race is about getting it good at _known_ science/engineering, fields in which 'correctness' is very easy to validate. But most of human interaction exists in a grey zone.
Thanks for this.
> that's not what _humanity_ is about
I've not spent too long thinking on the following, so I'm prepared for someone to say I'm totally wrong, but:
I feel like the services economy can be broadly broken down into: pleasure, progress and chores. Pleasure being poetry/literature, movies, hospitality, etc; progress being the examples you gave like science/engineering, mathematics; and chore being things humans need to coordinate or satisfy an obligation (accountants, lawyers, salesmen).
In this case, if we assume AI can deal with things not in the grey zone, then it can deal with 'progress' and many 'chores', which are massive chunks of human output. There's not much grey zone to them. (Well, there is, but there are many correct solutions; equivalent pieces of code that are acceptable, multiple versions of a tax return, each claiming different deductions, that would fly by the IRS, etc)
By visarga 2025-04-0512:32 I have considered this too. I frame it as problem solving. We are solving problems across all fields, from investing, to designing, construction, sales, entertainment, science, medicine, repair. What do you need when you are solving problems? You need to know the best action you can take in a situation. How is AI going to know all that? Some things are only tacicly known by key people, some things are guarded secrets (how do you make cutting edge chips, or innovative drugs?), some rely on experience that is not written down. Many of those problems have not even been fully explored, they are open field of trial and error.
AI progress depends not just on ideation speed, but on validation speed. And validation in some fields needs to pass through the physical world, which makes it expensive, slow, and rate limited. Hence I don't think AI can reach singularity. That would only be possible if validation was as easy to scale as ideation.
I'm not sure where construction and physical work goes into your categories. Process and chores maybe. But I think AI will struggle in the physical domain - validation is difficult and repeated experiments to train on are either too risky, too costly or potentially too damaging (i.e. in the real world failure is often not an option unlike software where test benches can allow controlled failure in a simulated env).
By m11a 2025-04-069:56 Neither, my categories only cover "services" (at least as Wikipedia would categorise things into this bracket: https://en.wikipedia.org/wiki/Service_economy).
I agree with you on construction and physical work.
programming entire AAA video games
Even this is questionable, cause we're seeing it making forms and solving leetcodes, but no llm yet created a new approach, reduced existing unnecessary complexity (which we created mountains of), made something truly new in general. All they seem to do is rehash of millions of "mainstream" works, and AAA isn't mainstream. Cranking up the parameter count or the time of beating around the bush (aka cot) doesn't magically substitute for lack of a knowledge graph with thick enough edges, so creating a next-gen AAA video game is far out of scope of llm's abilities. They are stuck in 2020 office jobs and weekend open source tech, programming-wise.
By m11a 2025-04-0421:01 "stuck" is a bit strong of a term. 6 months ago I remember preferring to write even Python code myself because Copilot would get most things wrong. My most successful usage of Copilot was getting it to write CRUD and tests. These days, I can give Claude Sonnet in Cursor's agent mode a high-level Rust programming task (e.g. write a certain macro that would allow a user to define X) and it'll modify across my codebase, and generally the thing just works.
At current rate of progress, I really do think in another 6 months they'll be pretty good at tackling technical debt and overcomplication, at least in codebases that have good unit/integration test coverage or are written in very strongly typed languages with a type-friendly structure. (Of course, those usually aren't the codebases needing significant refactoring, but I think AIs are decent at writing unit tests against existing code too.)
By JFingleton 2025-04-0421:291 reply "They are stuck in 2020 office jobs and weekend open source tech, programming-wise."
You say that like it's nothing special! Honestly I'm still in awe at the ability of modern LLMs to do any kind of programming. It's weird how something that would have been science fiction 5 years ago is now normalised.
By nyarlathotep_ 2025-04-050:10 All true, but keep in mind the biggest boosters of LLMs have been explicitly selling it as a replacement for human intellectual labor--"don't learn to code anymore", "we need UBI", "muh agents" and the like.
By loandbehold 2025-04-0416:411 reply OK but getting good at science/engineering is what matters because that's what gives AI and people who wield it power. Once AI is able to build chips and datacenters autonomously, that's when singularity starts. AI doesn't need to understand humans or act human-like to do those things.
By 0x008 2025-04-058:14 I think what they mean is that the fundamental question is IF any intelligence can really break out of its confined area of expertise and control a substantial amount of the world just by excelling in highly verifiable domains. Because a lot of what humans need to do is decisions based on expertise and judgement that in systems follows no transparent rules.
I guess it’s the age old question if we really know what we are doing („experience“) or we just tumble through life and it works out because the overall system of humans interacting with each other is big enough. The current state of world politics makes be think it’s the latter.
By boshalfoshal 2025-04-0423:16 I don't necessarily think you're wrong, and in general I do agree with you to an extent that this seems like self-centeted Computer Scientist/SWE hubris to think that automating programming is ~AGI.
HOWEVER there is a case to be made that software is an insanely powerful lever for many industries, especially AI. And if current AI gets good enough at software problems that it can improve its own infrastructure or even ideate new model architectures, then we would (in this hypothetical case), potentially reach an "intelligence explosion," which would (may) _actually_ yield a true, generalized intelligence.
So as a cynic, while I think the intermediary goal of many of these so-called-agi companies is just your usual SaaS automation slop because thats the easiest industry to disrupt and extract money from (and the people at these companies only really know how software works, as opposed to having knowledge of other things like chemistry, biology, etc), I also think that in theory, being a very fast and low cost programming agent is a bit more powerful than you think.
I agree with your point about the validation bottleneck becoming dominant over raw compute and simple model scaling. However, I wonder if we're underestimating the potential headroom for sheer efficiency breakthroughs at our levels of intelligence.
Von Neumann for example was incredibly brilliant, yet his brain presumably ran on roughly the same power budget as anyone else's. I mean, did he have to eat mountains of food to fuel those thoughts? ;)
So it looks like massive gains in intelligence or capability might not require proportionally massive increases in fundamental inputs at least at the highest levels of intelligence a human can reach, and if that's true for the human brain why not for other architecture of intelligence.
P.S. It's funny, I was talking about something along the lines of what you said with a friend just a few minutes before reading your comment so when I saw it I felt that I had to comment :)
I think you are underestimating the context, we all stand on shoulders of giants. Let's think what would happen if kid Einstein, at the young age of 5, was marooned on an island and recovered 30 years later. Will he have any deep insights to dazzle us with? I don't think he would.
By 2snakes 2025-04-0516:31 Hayy ibn Yaqdhan Nature vs nurture and relative nature of intelligence iirc
This is what I think as well. Unfortunately for the AI proponents they already made an example of the software industry. Its on news reports in the US and globally; most people are no longer recommending to get into the industry, etc. Software for better or worse has made an example for other industries as to what "not to do" both w.r.t data (online and option), and culture (e.g. open source, open tests, etc).
Anecdotally most people I know are against AI - they see more negatives from it than positives. Reading things like this just reinforces that belief.
The question of why are we even doing this? Why did we invent this? etc. Most people aren't interested in creating a "worthy successor" at best that eliminates them and potentially their children seeing that goal as nothing but naive and dare I say it wrong. All these thoughts will come from reading the above for most people.
History unfolds without anyone at the helm. It just happens, like a pachinko ball falling down the board. Global economic structures will push the development of AI and they're extremely hard to overwhelm.
By marxplank 2025-04-066:08 for better or worse, decisions with great impact are taken by people in power. this view of history as a pachinko ball may numb us to not question the people in power.
Many tasks are amenable to simulation training and synthetic data. Math proofs, virtual game environments, programming.
And we haven't run out of all data. High-quality text data may be exhausted, but we have many many life-years worth of video. Being able to predict visual imagery means building a physical world model. Combine this passive observation with active experimentation in simulated and real environments and you get millions of hours of navigating and steering a causal world. Deepmind has been hooking up their models to real robots to let them actively explore and generate interesting training data for a long time. There's more to DL than LLMs.
By visarga 2025-04-0512:39 This is true, a lot of progress can still happen based on simulation and synthetic data. But I am considering the long term game. In the long term we can't substitute simulation to reality. We can't even predict if a 3-body system will eventually eject an object, or if a piece of code will halt for all possible inputs. Physical systems implementing Turing machines are undecidable. Even fluid flows. The core problem is that recursive processes create an knowledge gap, and we can't cross that gap unless we walk the full recursion, there is no way to predict the outcome from outside. The real world is such an undecidable recursive process. AI can still make progress, but not at exponentially speed decoupled from the real world and not in isolation.

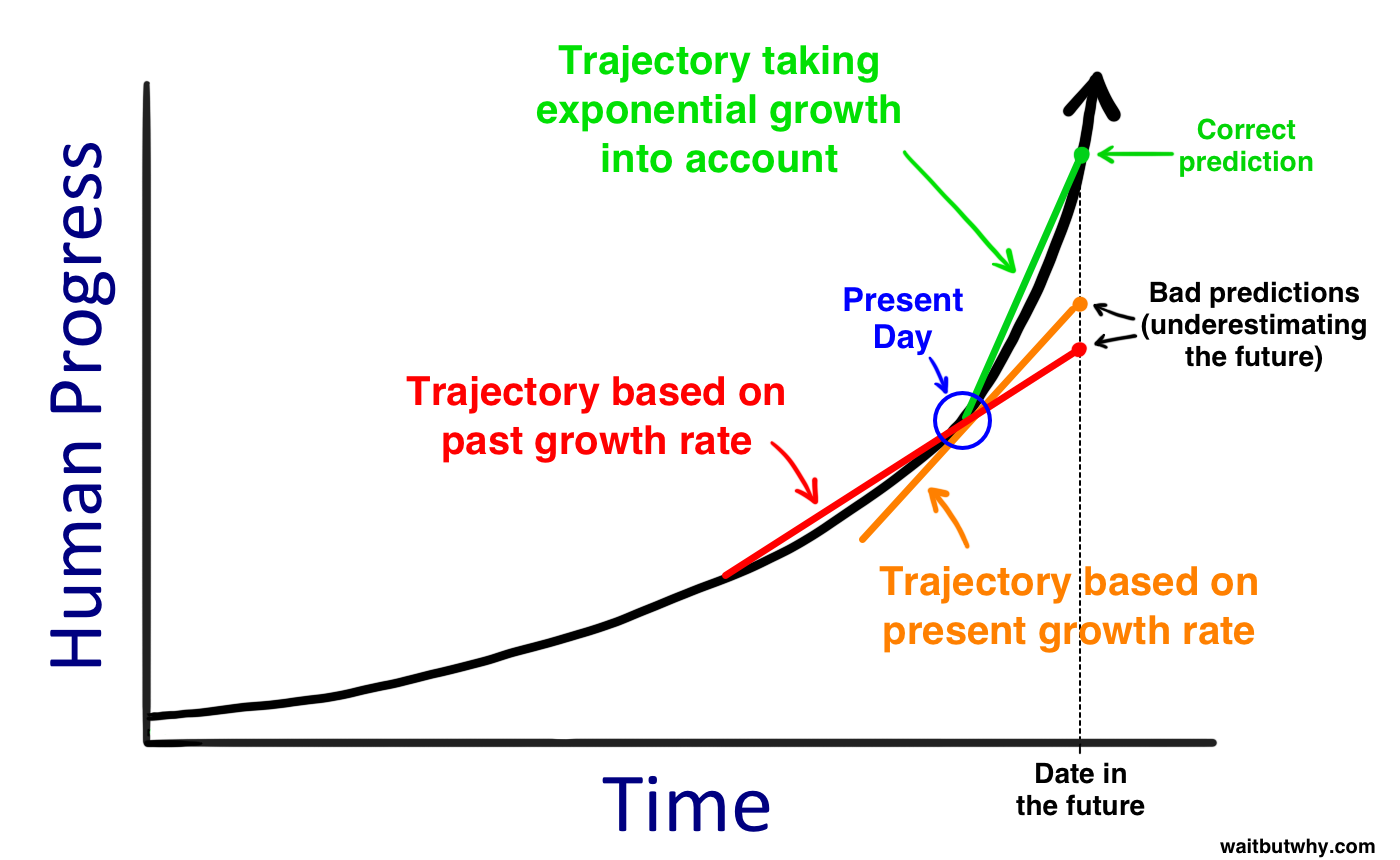{kind=link}