
2025-09-0814:36217429www.techpowerup.com

During the IFA 2025 in Berlin, AMD hosted a media discussion, where one of the topics was the ongoing x86 vs. Arm debate. AMD has argued that x86 processors, both their own and Intel's SKUs, can offer…
- Upcoming Hardware Launches 2025 (Updated Aug 2025)
- Zotac GeForce RTX 5070 Solid Review
- ASUS ROG Ally X Review
- Battlefield 6 Open Beta Performance Benchmark Review - 17 GPUs Tested
- Seagate FireCuda 540 2 TB Review
- MSI MPG CORELIQUID P13 360 Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Metal Gear Solid Δ: Snake Eater Performance Benchmark Review - 30+ GPUs Tested
- Redragon K1NG Ultra Review
- AMD Ryzen 9 9950X3D Review - Great for Gaming and Productivity
Read the original article
Comments
By exmadscientist 2025-09-0815:1211 reply This is an entirely uncontroversial take among experts in the space. x86 is an old CISC-y hot mess. RISC-V is a new-school hyper-academic hot mess. Recent ARM is actually pretty good. And none of it matters, because the uncore and the fabrication details (in particular, whether things have been tuned to run full speed demon or full power sipper) completely dominate the ISA.
In the past x86 didn't dominate in low power because Intel had the resources to care but never did, and AMD never had the resources to try. Other companies stepped in to full that niche, and had to use other ISAs. (If they could have used x86 legally, they might well have done so. Oops?) That may well be changing. Or perhaps AMD will let x86 fade away.
I remember reading this Jim Keller interview:
https://web.archive.org/web/20210622080634/https://www.anand...
Basically the gist of it is that the difference between ARM/x86 mostly boils down to instruction decode, and:
- Most instructions end up being simple load/store/conditional branch etc. on both architectures, where there's literally no difference in encoding efficiency
- Variable length instruction has pretty much been figured out on x86 that it's no longer a bottleneck
Also my personal addendum is that today's Intel efficiency cores are have more transistors and better perf than the big Intel cores of a decade ago
Nice followup to your link: https://chipsandcheese.com/p/arm-or-x86-isa-doesnt-matter.
Personally I do not entirely buy it. Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. The PC Snapdragon chips AFAIK also offer better performance-per-watt than AMD or Intel, with laptops offering them often having 10-30% longer battery life at similar performance.
The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope: https://images.macrumors.com/t/xuN87vnxzdp_FJWcAwqFhl4IOXs=/...
By ben-schaaf 2025-09-095:545 reply > Personally I do not entirely buy it. Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. The PC Snapdragon chips AFAIK also offer better performance-per-watt than AMD or Intel, with laptops offering them often having 10-30% longer battery life at similar performance.
Do not conflate battery life with core efficiency. If you want to measure how efficient a CPU core is you do so under full load. The latest AMD under full load uses the same power as M1 and is faster, thus it has better performance per watt. Snapdragon Elite eats 50W under load, significantly worse than AMD. Yet both M1 and Snapdragon beat AMD on battery life tests, because battery life is mainly measured using activities where the CPU is idle the vast majority of the time. And of course the ISA is entirely irrelevant when the CPU isn't being used to begin with.
> The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope
That chart is Apple propaganda. In Geekbench 5 the RTX 3090 is 2.5x faster, in blender 3.1 it is 5x faster. See https://9to5mac.com/2022/03/31/m1-ultra-gpu-comparison-with-... and https://techjourneyman.com/blog/m1-ultra-vs-nvidia-rtx-3090/
By devnullbrain 2025-09-0911:341 reply I want to measure the device how I use it. Race-to-sleep and power states are integral to CPU design.
By ben-schaaf 2025-09-0911:532 reply Yes they are, but only one of those is at all affected by the choice of ISA. If modern AMD chips are better at race-to-sleep than an Apple M1 and still get worse battery life then the problem is clearly not x86-64.
Right, so as I understand it people see that x86-64 designs score poorly on a set of benchmarks and infer that it is because they are x86-64.
In fact it’s because that manufacturer has made architectural choices that are not inherent to the x86-64 ISA.
And that’s just hardware. MacOS gets roughly 30% better battery life on M series hardware than Asahi Linux. I’m not blaming the Asahi team, they do amazing work, they don’t even work on many of the Linux features relevant to power management, and Apple has had years of head start on preparing for and optimising for the M architecture. It’s just that software matters, a lot.
So if I’m reading this right, ISA can make a difference, but it’s incremental compared to the many architectural decisions and trade offs that go into a particular design.
By bee_rider 2025-09-0918:09 > So if I’m reading this right, ISA can make a difference, but it’s incremental compared to the many architectural decisions and trade offs that go into a particular design.
This is true, but only in the sense that is very rarely correct to say “Factor Y can’t possibly make a difference.”
Does anyone care about blaming / lauding an ISA without any connection to the actual devices that people use?
Performance and battery life are lived experiences. There’s probably some theoretical hyper optimization where 6502 ISA is just as good as ARM, but does it matter?
By jijijijij 2025-09-0914:23 In this thread, it does. You are moving the goalpost by making this about "actual devices", when the topic is ISA efficiency.
> If you want to measure how efficient a CPU core is you do so under full load.
Higher wattage gives diminishing returns. Chips will run higher wattage under full load just to eke out a marginal improvement in performance. Therefore efficiency improves if the manufacturer chooses to limit the chip rather than pushing it harder.
Test efficiency using whatever task the chip will be used for. For most ultralight laptops, that will be web browsing etc. so the m1 MacBook/snapdragon results are valid for typical users. Maybe your workload hammers the CPU but that doesn't make it the one true benchmark.
By ben-schaaf 2025-09-0915:051 reply No, and that's exactly the point I'm making. If you try to measure ISA efficiency using a workload where the CPU is idle the vast majority of the time, then your power usage will be dominated by things unrelated to the ISA.
To further hammer the point home, let me reduce do a reductio ad absurdum: The chip is still "in use" when its asleep. Sleeping your laptop is a typical usecase. Therefore how much power is used while sleeping is a good measure of ISA efficiency. This is of course absurd because the CPU cores are entirely turned off when sleeping, they could draw 1kW with potato performance and nothing in this measurement would change.
You're not taking into account dynamic clock speeds, just "idle" and "load." Most CPUs have configurable TDP, and if you give them more power they will run more cores at a higher frequency. Suppose I measured the same laptop CPU under "full load" in two different computers at full load, but one is configured for a 30w TDP and the other is configured for a 40w TDP. The first PC will be more efficient, because you get diminishing returns for increased power. But it's the same CPU.
To go back to your original argument, you're claiming that x86 ISA is more efficient than ARM because a certain AMD chip beat certain M1/snapdragon chips at 50w. You can't draw that conclusion because the two chips may be designed to have peak efficiency at different power levels, even if the maximum power draw is the same. Likely the Snapdragon/M1 have better efficiency at 10W with reduced clock speed even if the CPU is not idling.
Hence my response: it doesn't make sense to talk about performance per watt, without also specifying the workload. Not only will different workloads use different amounts of power, they will also rely on different instructions which may give different ISAs or CPUs the edge.
Not to mention -- who even cares about ISA efficiency? What matters is the result for the product I can buy. If M1/snapdragon are able to match AMD on performance but beat it in battery life for my workloads, I don't care if AMD has better "performance per watt" according to your metric.
By ben-schaaf 2025-09-1110:591 reply > You're not taking into account dynamic clock speeds, just "idle" and "load." Most CPUs have configurable TDP, and if you give them more power they will run more cores at a higher frequency. Suppose I measured the same laptop CPU under "full load" in two different computers at full load, but one is configured for a 30w TDP and the other is configured for a 40w TDP. The first PC will be more efficient, because you get diminishing returns for increased power. But it's the same CPU.
Dynamic clock speeds are exactly why you need to do this testing under full load. No you're probably not getting the same power draw on each chip, but at least you're eliminating the frequency scaling algorithms from the equation. This is why it's so hard to evaluate core efficiency (let alone what effect the ISA has).
What you can do however is compare chips with wildly different performance and power characteristics. A chip that is using significantly more power to do significantly less work is less efficient than a chip using less power to do more.
> To go back to your original argument, you're claiming that x86 ISA is more efficient than ARM because a certain AMD chip beat certain M1/snapdragon chips at 50w.
I never claimed x86 is more efficient than ARM. I did claim the latest AMD cores are more efficient than M1 and snapdragon elite X, while still having worse battery life.
> You can't draw that conclusion because the two chips may be designed to have peak efficiency at different power levels, even if the maximum power draw is the same. Likely the Snapdragon/M1 have better efficiency at 10W with reduced clock speed even if the CPU is not idling.
Firstly this is pretty silly: All chips get more efficient at lower clock speed. Maximum efficiency is at at whatever the lowest clockspeed you can go, which is primarily determined by how the chip is manufactured. Which brings me to my second point: What does any of this have to do with the ISA?
> Not to mention -- who even cares about ISA efficiency? What matters is the result for the product I can buy.
If you don't care about ISA efficiency why are you here‽ That's what this discussion is about! If you don't care about this just leave.
And to answer your question: We care about ISA efficiency because we care about the efficiency of our chips. If ARM was twice as efficient then we should be pushing to kill x86, backwards compatibility be damned. In actuality the reason ARM-based laptops have better efficiency has nothing/little to do with the ISA, so instead of asking AMD/intel to release an ARM-based chips we should be pushing them to optimize battery usage.
By fwipsy 2025-09-1114:48 You didn't understand what I said before responding. Please don't waste my time like that.
He said "per watt", that's still true. You just talked about max throughput, which no one is discussing.
> The latest AMD under full load uses the same power as M1 and is faster, thus it has better performance per watt.
He also said per watt. An AMD CPU running at full power and then stopping will use less battery than an M1 with the same task; that's comparing power efficiency.
By boxed 2025-09-0911:54 https://techjourneyman.com/blog/m1-ultra-vs-nvidia-rtx-3090/
Look at their updated graph which has less BS. It's never close in perf/watt.
The BS part about apples graph was that they cut the graph short for the nvidia card (and bending the graph a bit at the end). The full graph still shows apple being way better per watt.
By ohdeargodno 2025-09-098:482 reply It's not, because Apple purposefully lied on their marketing material. Letting a 3090 go on full blast brings it pretty much in line in perf/watt. Your 3090 will not massively thermal throttle after 30 minutes either, but the M1 Ultra will.
So, yes, if you want to look good on pointless benchmarks, a M1 ultra ran for 1 minute is more efficient than a downclocked 3090.
How do you think Nvidia got Samsung’s 8nm process to be just as power efficient as TSMC’s 5nm node?
By ohdeargodno 2025-09-0913:41 [dead]
https://techjourneyman.com/blog/m1-ultra-vs-nvidia-rtx-3090/
Look at that updated graph which has less BS. It's never close in perf/watt.
The BS part about apples graph was that they cut the graph short for the nvidia card (and bending the graph a bit at the end). The full graph still shows apple being way better per watt.
By ohdeargodno 2025-09-0913:36 [dead]
By petrichorko 2025-09-0910:102 reply To me it's not as simple as comparing the efficiency under full load. I imagine the efficiency on x86 as some kind of log curve, which translates to higher power consumption even on lighter loads. Apple's ARM implementation tends to eat a lot less power on tasks that happen most of the time, hence greatly improving the battery life.
I've tried a Ryzen 7 that had a similar efficiency to an M1 according to some tests, and that thing ran hot like crazy. Its just marketing bullshit to me now..
The OS matters, and I would guess you were using two different OSes? I have no doubt macOS running on an m1 is more optimized than whatever you were using on the ryzen.
I recently had to remove Windows completely from a few years old laptop with an 12th gen cpu and a Intel Iris / GeForce RTX 3060 Mobile combo because it was running very hot (90c+) and the fans were constantly running. Running Linux, I have no issues. I just double checked since I had not for several months, and temperature is 40c lower on my lap than it was propped up on a book for maximum airflow. Full disclaimer, I would have done this anyways, but the process was sped up because my wife was extremely annoyed with the noise my new-to-me computer was making, and it was cooking the components.
I have learned to start with the OS when things are tangibly off, and only eventually come back to point the finger at my hardware.
By ashirviskas 2025-09-0912:051 reply OS does matter, with Linux my M1 macbook gets kinda hot and it cannot do more than 1.5-2h of google meetings with cameras on. IIRC google meetings on macos were at least a bit more efficient.
Though it has definitely been getting better in the last 1.5 years using Asahi Linux and in some areas it is a better experience than most laptops running Linux (sound, cameras, etc.). The developers even wrote a full fledged physical speaker simulator just so it could be efficiently driven over its "naive" limits.
By sgc 2025-09-0914:53 That is more a "who is controlling access to hardware drivers matters" problem. I wouldn't be surprised if macOS was still a tiny bit more efficient with a level playing field, but we will never know.
By petrichorko 2025-09-0911:07 Linux can definitely help with this, I had the same experience with it on Z1 (SteamOS). But even running Windows 11 in a VM on M1 does not make the machine run hot
By ben-schaaf 2025-09-0915:35 If we're comparing entire systems as products you're absolutely right. That's not what this discussion is about. We're trying to compare the efficiency of the ISA. What do you think would happen if AMD replaced the x86-64 decoders with ARM64 ones, and changed nothing about how the CPU idles, how high it clocks or how fast it boosts?
My guess is ARM64 is a few percent more efficient, something AMD has claimed in the past. They're now saying it would be identical, which is probably not far from the truth.
The simple fact of the matter is that the ISA is only a small part of how long your battery lasts. If you're gaming or rendering or compiling it's going to matter a lot, and Apple battery life is pretty comparable in these scenarios. If you're reading, writing, browsing or watching then your cores are going to be mostly idle, so the only thing the ISA influences won't even have a current running through it.
By exmadscientist 2025-09-094:516 reply Yes, Intel/AMD cannot match Apple in efficiency.
But Apple cannot beat Intel/AMD in single-thread performance. (Apple marketing works very hard to convince people otherwise, but don't fall for it.) Apple gets very, very close, but they just don't get there. (As well, you might say they get close enough for practical matters; that might be true, but it's not the question here.)
That gap, however small it might be for the end user, is absolutely massive on the chip design level. x86 chips are tuned from the doping profiles of the silicon all the way through to their heatsinks to be single-thread fast. That last 1%? 2%? 5%? of performance is expensive, and is far far far past the point of diminishing returns in turns of efficiency cost paid. That last 20% of performance burns 80% of the power. Apple has chosen not to do things this way.
So x86 chips are not particularly well tuned to be efficient. They never have been; it's, on some level, a cultural problem. Could they be? Of course! But then the customers who want what x86 is right now would be sad. There are a lot of customers who like the current models, from hyperscalers to gamers. But they're increasingly bad fits for modern "personal computing", a use case which Apple owns. So why not have two models? When I said "doping profiles of the silicon" above, that wasn't hyperbole, that's literally true. It is a big deal to maintain a max-performance design and a max-efficiency design. They might have the same RTL but everything else will be different. Intel at their peak could have done it (but was too hubristic to try); no one else manufacturing x86 has had the resources. (You'll note that all non-Apple ARM vendor chips are pure efficiency designs, and don't even get close to Apple or Intel/AMD. This is not an accident. They don't have the resources to really optimize for either one of these goals. It is hard to do.)
Thus, the current situation: Apple has a max-efficiency design that's excellent for personal computing. Intel/AMD have aging max-performance designs that do beat Apple at absolute peak... which looks less and less like the right choice with every passing month. Will they continue on that path? Who knows! But many of their customers have historically liked this choice. And everyone else... isn't great at either.
> Apple has a max-efficiency design that's excellent for personal computing. Intel/AMD have aging max-performance designs that do beat Apple at absolute peak...
Can you explain then, how come switching from Intel MBP to Apple Silicon MBP feels like literally everything is 3x faster, the laptop barely heats up at peak load, and you never hear the fans? Going back to my Intel MBP is like going back to stone age computing.
In other words if Intel is so good, why is it... so bad? I genuinely don't understand. Keep in mind though, I'm not comparing an Intel gaming computer to a laptop, let's compare oranges to oranges.
By fxtentacle 2025-09-098:351 reply If you take a peak-performance-optimized design (the Intel CPU) and throttle it down to low power levels, it will be slower than a design optimized for low power (the Apple CPU).
"let's compare oranges to oranges"
That's impossible because Apple has bought up most of TSMC's 3nm production capacity. You could try to approximate by comparing Apple M4 Max against NVIDIA B300 but that'll be a very one-sided win for NVIDIA.
By wtallis 2025-09-0915:02 > That's impossible because Apple has bought up most of TSMC's 3nm production capacity. You could try to approximate by comparing Apple M4 Max against NVIDIA B300 but that'll be a very one-sided win for NVIDIA.
Have you not heard that Intel's Lunar Lake is made on the same TSMC 3nm process as Apple's M3? It's not at all "impossible" to make a fair and relevant comparison here.
By VHRanger 2025-09-0914:14 > Can you explain then, how come switching from Intel MBP to Apple Silicon MBP feels like literally everything is 3x faster, the laptop barely heats up at peak load, and you never hear the fans? Going back to my Intel MBP is like going back to stone age computing.
My understanding of it is that Apple Silicon's very very long instruction pipeline plays well with how the software stack in MacOS is written and compiled first and foremost.
Similarly that the same applications take less RAM in MacOS than even in Linux often even because at the OS level stuff like garbage collection are better integrated.
By exmadscientist 2025-09-0923:46 I did not say "Intel is so good". I said "x86 peak single-thread performance is just a hair better than Apple M-series peak".
Pretty much everything else about the M-series parts is better. In particular, Apple's uncore is amazing (partly because it's a lot newer design) and you really notice that in terms of power management.
By bee_rider 2025-09-0918:29 Is the Intel MacBook very old?
Is it possible that your workloads are bound by something other than single-threaded compute performance? Memory? Drive speed?
Is it possible that Apple did a better job tuning their OS for their hardware, than for Intel’s?
By bpavuk 2025-09-098:35 it all comes down to thermal budget of something as thin as MBP.
By aurareturn 2025-09-0911:48
AMD, Intel, Qualcomm have all reference Geekbench ST numbers. In Geekbench, Apple is significantly ahead of AMD and Intel in ST performance. So no need Apple marketing to convince us. The industry has benchmarks to do so.But Apple cannot beat Intel/AMD in single-thread performance.By steveBK123 2025-09-0912:231 reply > looks less and less like the right choice with every passing month
It does seem like for at least the last 3-5 years it's been pretty clear that Intel x86 was optimizing for the wrong target / a shrinking market.
HPC increasingly doesn't care about single core/thread performance and is increasingly GPU centric.
Anything that cares about efficiency/heat (basically all consumer now - mobile, tablet, laptop, even small desktop) has gone ARM/RISC.
Datacenter market is increasingly run by hyperscalers doing their own chip designs or using AMD for cost reasons.
By bee_rider 2025-09-0918:35 It seems impossible that CPUs could ever catch up to GPUs, for the things that GPUs are really good at.
I dunno. I sort of like all the vector extensions we’ve gotten on the CPU side as they chase that dream. But I do wonder if Intel would have been better off just monomaniacally focusing on single-threaded performance, with the expectation that their chips should double down on their strength, rather than trying to attack where Nvidia is strong.
By whizzter 2025-09-099:25 It's the gaming/HPC focus, sure you can achieve some stunning benchmark numbers with nice vectorized straightforward code.
In the real world we have our computers running JIT'ed JS, Java or similar code taking up our cpu time, tons of small branches (mostly taken the same way and easily remembered by the branch predictor) and scattering reads/writes all over memory.
Transistors not spent on larger branch prediction caches or L1 caches are badly spent, doesn't matter if the CPU can issue a few less instructions per clock to ace an benchmark if it's waiting for branch mispredictions or cache misses most of the time.
There's no coincidence that the Apple teams iirc are partly the same people that built Pentium-M (that begun the Core era by delivering very good perf on mobile chips when P4 was supposed to be the flagship).
> But Apple cannot beat Intel/AMD in single-thread performance
It's literally one of the main Apple M chips advantage over Intel/AMD. At the time when M chip came out, it was the only chip that managed to consume ~100GB/s of MBW with just a single thread.
https://web.archive.org/web/20240902200818/https://www.anand...
> From a single core perspective, meaning from a single software thread, things are quite impressive for the chip, as it’s able to stress the memory fabric to up to 102GB/s. This is extremely impressive and outperforms any other design in the industry by multiple factors, we had already noted that the M1 chip was able to fully saturate its memory bandwidth with a single core and that the bottleneck had been on the DRAM itself.
By exmadscientist 2025-09-0923:521 reply Memory bandwidth is an uncore thing, not a core thing. Apple's uncore is amazing. But that means they can feed their cores well, not that their cores are actually the absolute best performers when all the stops are pulled out.
By menaerus 2025-09-107:23 Yes, it is core and uncore, which we call a CPU, and you said "But Apple cannot beat Intel/AMD in single-thread performance." which is incorrect for the reasons above.
By privatelypublic 2025-09-096:24 Let's not forget- there shouldn't be anything preventing you from setting PL1 and PL2 power levels in linux or windows, AMD or Intel. Sometimes you can even set them in the Bios.
Letting you limit just how much of that extra 20% power hogging perf you want.
There are just so many confounding factors that it's almost entirely impossible to pin down what's going on.
- M-series chips have closely integrated RAM right next to the CPU, while AMD makes do with standard DDR5 far away from the CPU, which leads to a huge latency increase
- I wouldn't be surprised if Apple CPUs (which have a mobile legacy) are much more efficient/faster at 'bursty' workloads - waking up, doing some work and going back to sleep
- M series chips are often designed for a lower clock frequency, and power consumption increases quadratically (due to capactive charge/dischargelosses on FETs) Here's a diagram that shows this on a GPU:
So while it's entirely possible that AArch64 is more efficient (the decode HW is simpler most likely, and encoding efficiency seems identical):
https://portal.mozz.us/gemini/arcanesciences.com/gemlog/22-0...?
It's hard to tell how much that contributes to the end result.
By magicalhippo 2025-09-0910:561 reply Zen 5 also seems to have a bit of a underperforming memory subsystem, from what I can gather.
Hardware Unboxed just did an interesting video[1] comparing gaming performance of 7600X Zen 4 and 9700X Zen 5 processors, and also the 9800X3D for reference. In some games the 9700X Zen 5 had a decent lead over the Zen 4, but in others it had exactly the same performance. But the 9800X3D would then have a massive lead over the 9700X.
For example, in Horizon Zero Dawn benchmark, the 7600X had 182 FPS while the 9700X had 185 FPS, yet the 9800X3D had a massive 266 FPS.
I mean, huge software with a ton of quirks like a AAA video game are arguably not a good benchmark to understand hardware.
They're still good benchmarks IMO because they represent a "real workload" but to understand why the 9800X3D performs this much better you'd want some metrics on CPU cache misses in the processors tested.
It's often similar to hyperthreading -- on very efficient sofware you actually want to turn SMT off sometimes because it causes too many cache evictions as two threads fight for the same L2 cache space which is efficiently utilized.
So software having a huge speedup from a X3D model with a ton of cache might indicate the sofware has a bad data layout and needs the huge cache because it keeps doing RAM round trips. You'd presumably also see large speedups in this case from faster RAM on the same processor.
By magicalhippo 2025-09-0917:20 > but to understand why the 9800X3D performs this much better you'd want some metrics on CPU cache misses in the processors tested.
But as far as I can tell the 9600X and the 9800X3D are the same except for the 3D cache and a higher TDP. However they have similar peak extended power (~140W) and I don't see how the different TDP numbers explain the differences between 9600X and 7600X where the is sometimes ahead and other times identical, while the 9800X3D beats both massively regardless.
What other factors could it be besides fewer L3 cache misses that lead to 40+% better performance of the 9800X3D?
> You'd presumably also see large speedups in this case from faster RAM on the same processor.
That was precisely my point. The Zen 5 seems to have a relatively slow memory path. If the M-series has a much better memory path, then the Zen 5 is at a serious disadvantage for memory-bound workloads. Consider local CPU-run LLMs as a prime example. The M-s crushes AMD there.
I found the gaming benchmark interesting because it represented workloads that had workloads that just straddled the cache sizes, and thus showed how good the Zen 5 could be had it had a much better memory subsystem.
I'm happy to be corrected though.
By formerly_proven 2025-09-097:241 reply > M-series chips have closely integrated RAM right next to the CPU, while AMD makes do with standard DDR5 far away from the CPU, which leads to a huge latency increase
2/3rds the speed of light must be very slow over there
I mean at 2GHz, and 2/3c, the signal travels about 10cm in 1 clock cycle. So it's not negligible, but I suspect it has much more to do with signal integrity and the transmission line characteristics of the data bus.
I think since on mobile CPUs, the RAM sits right on top of the SoC, very likely the CPUs are designed with a low RAM latency in mind.
By formerly_proven 2025-09-107:47 > I mean at 2GHz, and 2/3c, the signal travels about 10cm in 1 clock cycle. So it's not negligible
That's 0.5ns - if you look at end-to-end memory latencies, which are usually around 100ns for mobile systems, that actually is negligible, and M series chips do not have particularly low memory latency (they trend higher in comparison).
I think the m chips have much wider databus so bandwith is much higher as well as lower latency?
huh, it seems like the M4 pro can hit >400GB/s of RAM bandwidth whereas even a 9950x hits only 100GB/s.
I'm curious how that is; in practice it "feels" like my 9950x is much more efficient at "move tons of RAM" tasks like a duckDB workload above a M4.
But then again a 9950x has other advantages going on like AVX512 I guess?
By hnuser123456 2025-09-0915:071 reply Yes, the M-series chips effectively use several "channels" of RAM (depending on the tier/size of chip) while most desktop parts, including the 9950x, are dual-channel. You get 51.2 GB/s of bandwidth per channel of DDR5-6400.
You can get 8-RAM-channel motherboards and CPUs and have 400 GB/s of DDR5 too, but you pay a price for the modularity and capacity over it all being integrated and soldered. DIMMs will also have worse latency than soldered chips and have a max clock speed penalty due to signal degradation at the copper contacts. A Threadripper Pro 9955WX is $1649, a WRX90 motherboard is around $1200, and 8x16GB sticks of DDR5 RDIMMS is around $1200, $2300 for 8x32GB, $3700 for 8x64GB sticks, $6000 for 8x96GB.
Or you can get a strix halo 395+ that has 8 memory channels with a max of 128gb of ram. I think it does around 400 GB/s
By hnuser123456 2025-09-1016:091 reply From what I see Strix Halo has a 256 bit memory bus, which would be like quad channel ddr5, but it's soldered so can run at 8000mt/s, which comes out to 256 GB/s.
By christkv 2025-09-115:44 Yeah you are right still up from the other consumer platforms
By michaelmrose 2025-09-095:361 reply RTX3090 is a desktop part optimized for maximum performance with a high-end desktop power supply. It isn't meaningful to compare its performance per watt with a laptop part.
Saying it offers a certain wattage worth of the desktop part means even less because it measures essentially nothing.
You would probably want to compare it to a mobile 3050 or 4050 although this still risks being a description of the different nodes more so than the actual parts.
By KingOfCoders 2025-09-096:051 reply It's no comparison at all, the person who bought a 3090 in the 30xx days wanted max gaming performance, someone with an Apple laptop wants longer battery usage.
It's like comparing an F150 with an Ferrari, a decision that no buyer needs to make.
By thechao 2025-09-0912:21 > It's like comparing an F150 with a Ferrari, a decision that no buyer needs to make.
... maybe a Prius? Bruh.
I mean the M1 is nice but pretending that it can do in 110w what the 3090 does with 320w is Apple marketing nonsense. Like if your use case is playing games like cp2077, the 3090 will do 100fps in ultra ray tracing and an M4 Max will only do 30fps. Not to mention it’s trivial to undervolt nvidia cards and get 100% performance at 80% power. So 1/3 the power for 1/3 the performance? How is that smoking anything?
By pjmlp 2025-09-0911:31 Indeed, like talking as if Apple mattered at all in server space, or digital workstations (studio is not a replacement for people willing to buy Mac Pros, which still keep being built with Intel Xeons).
>Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency.
Why would they spend billions to "catch up" to an ecological niche that is already occupied, when the best they could do - if the argument here is right that x86 and ARM are equivalent - is getting the same result?
They would only invest this much money and time if they had some expectation of being better, but "sharing the first place" is not good enough.
The problem is that they are slowly losing the mobile markets, while their usual markets are not growing as they used to. AMD is less vulnerable to the issues that arise from that because they are fabless, and they could pivot entirely to GPU or non-x86 markets if they really wanted to. But Intel has fabs (very expensive in terms of R&D and capex) dedicated to products for desktop and server markets that must continue to generate revenue.
By 9rx 2025-09-0913:02 The question remains: Why would they spend billions only to "catch up"? That means, even after the investment is made and they have a product that is just as good, there is still no compelling technical reason for the customer to buy Intel/AMD over the other alternatives that are just as good, so their only possible avenue to attract customers is to drive the price into the ground which is a losing proposition.
By BoredPositron 2025-09-0913:001 reply The markets didn't really budge. Apple only grew 1% in the traditional PC market (desktop/notebook) over the last 5 years and that's despite a wave of new products. The snapdragons are below 1%...
By samus 2025-09-1021:13 And that's fine for them since they have also have their mobile platform, which is arguably more important at this point.
By ChoGGi 2025-09-0913:08 > The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope: https://images.macrumors.com/t/xuN87vnxzdp_FJWcAwqFhl4IOXs=/...
I see it's measuring full system wattage with a 12900k which tended to use quite a bit of juice compared to AMD offerings.
https://gamersnexus.net/u/styles/large_responsive_no_waterma...
By robotnikman 2025-09-0919:18 > Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency
A big reason for this, at least for AMD, is because Apple buys all of TSMC's latest and greatest nodes for massive sums of money, so there is simply none left for others like AMD who are stuck a generation behind. And Intel is continually stuck trying to catch up. I would not say its due to x86 itself.
By whatagreatboy 2025-09-099:21 Even Jim Keller says that instruction decode is the difference, and that saves a lot of battery for ARM even if it doesn't change the core efficiency at full lot.
By KingOfCoders 2025-09-096:011 reply Why would they? They are dominated by gaming benchmarks in a way Apple isn't. For decades it was not efficiency but raw performance, 50% more power usage for 10% more performance was ok.
"The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt"
Gamers are not interested in performance-per-watt but fps-per-$.
If some behavior looks strange to you, most probably you don't understand the underlying drivers.
> Gamers are not interested in performance-per-watt but fps-per-$.
I game a decent amount on handheld mode for the switch. Like tens of millions of others.
By pjmlp 2025-09-0911:33 While others run PlayStation and XBox.
The demographics aren't the same, nor the games.
By KingOfCoders 2025-09-0912:56 I game a decent amount on table top games. Like tens of millions of others.
By ohdeargodno 2025-09-098:46 [dead]
By codedokode 2025-09-0821:548 reply x86 decoding must be a pain - I vaguely remember that they have trace caches (a cache of decoded micro-operations) to skip decoding in some cases. You probably don't make such caches when decoding is easy.
Also, more complicated decoding and extra caches means longer pipeline, which means more price to pay when a branch is mispredicted (binary search is a festival of branch misprediction for example, and I got 3x acceleration of linear search on small arrays when I switched to the branchless algorithm).
Also I am not a CPU designer, but branch prediction with wide decoder also must be a pain - imagine that while you are loading 16 or 32 bytes from instruction cache, you need to predict the address of next loaded chunk in the same cycle, before you even see what you got from cache.
As for encoding efficiency, I played with little algorithms (like binary search or slab allocator) on godbolt, and RISC-V with compressed instruction generates similar amount of code as x86 - in rare cases, even slightly smaller. So x86 has a complex decoding that doesn't give any noticeable advantages.
x86 also has flags, which add implicit dependencies between instructions, and must make designer's life harder.
By wallopinski 2025-09-091:131 reply I was an instruction fetch unit (IFU) architect on P6 from 1992-1995. And yes, it was a pain, and we had close to 100x the test vectors of all the other units, going back to the mid 1980's. Once we started going bonkers with the prefixes, we just left the pre-Pentium decoder alone and added new functional blocks to handle those. And it wasn't just branch prediction that sucked, like you called out! Filling the instruction cache was a nightmare, keeping track of head and tail markers, coalescing, rebuilding, ... lots of parallel decoding to deal with cache and branch-prediction improvements to meet timing as the P6 core evolved was the typical solution. We were the only block (well, minus IO) that had to deal with legacy compatibility. Fortunately I moved on after the launch of Pentium II and thankfully did not have to deal with Pentium4/Northwood.
By nerpderp82 2025-09-092:551 reply https://en.wikipedia.org/wiki/P6_(microarchitecture)
The P6 is arguably the most important x86 microarch ever, it put Intel on top over the RISC workstations.
What was your favorite subsystem in the P6 arch?
Was it designed in Verilog? What languages and tools were used to design P6 and the PPro?
By wallopinski 2025-09-094:55 Well duh, the IFU. :) No, I was fond of the FPU because the math was just so bonkers. The way division was performed with complete disregard to the rules taught to gradeschoolers always fascinated me. Bob Colwell told us that P6 was the last architecture one person could understand completely.
Tooling & Languages: IHDL, a templating layer on top of HDL that had a preprocessor for intel-specific macros. DART test template generator for validation coverage vectors. The entire system was stitched together with PERL, TCL, and shellscripts, and it all ran on three OSes: AIX, HPUX and SunOS. (I had a B&W sparcstation and was jealous of the 8514/a 1024x768 monitors on AIX.) We didn't go full Linux until Itanic and by then we were using remote computing via Exceed and gave up our workstations for generic PCs. When I left in the mid 2000's, not much had changed in the glue/automation languages, except a little less Tcl. I'm blanking on the specific formal verification tool, I think it was something by Cadence. Synthesis and timing was ... design compiler and primetime? Man. Cobwebs. When I left we were 100% Cadence and Synopsys and Verilog (minus a few custom analog tools based on SPICE for creating our SSAs). That migration happened during Bonnell, but gahd it was painful. Especially migrating all the Pentium/486/386/286/8088 test vectors.
I have no idea what it is like ~20 years later (gasp), but I bet the test vectors live on, like Henrietta Lacks' cells. I'd be interested to hear from any Intelfolk reading this?
> x86 decoding must be a pain
So one of the projects I've been working on and off again is the World's Worst x86 Decoder, which takes a principled approach to x86 decoding by throwing out most of the manual and instead reverse-engineering semantics based on running the instructions themselves to figure out what they do. It's still far from finished, but I've gotten it to the point that I can spit out decoder rules.
As a result, I feel pretty confident in saying that x86 decoding isn't that insane. For example, here's the bitset for the first two opcode maps on whether or not opcodes have a ModR/M operand: ModRM=1111000011110000111100001111000011110000111100001111000011110000000000000000000000000000000000000011000001010000000000000000000011111111111111110000000000000000000000000000000000000000000000001100111100000000111100001111111100000000000000000000001100000011111100000000010011111111111111110000000011111111000000000000000011111111111111111111111111111111111111111111111111111110000011110000000000000000111111111111111100011100000111111111011110111111111111110000000011111111111111111111111111111111111111111111111
I haven't done a k-map on that, but... you can see that a boolean circuit isn't that complicated. Also, it turns out that this isn't dependent on presence or absence of any prefixes. While I'm not a hardware designer, my gut says that you can probably do x86 instruction length-decoding in one cycle, which means the main limitation on the parallelism in the decoder is how wide you can build those muxes (which, to be fair, does have a cost).
That said, there is one instruction where I want to go back in time and beat up the x86 ISA designers. f6/0, f6/1, f7/0, and f7/1 [1] take in an extra immediate operand whereas f6/2 and et al do not. It's the sole case in the entire ISA where this happens.
[1] My notation for when x86 does its trick of using one of the register selector fields as extra bits for opcodes.
By Dylan16807 2025-09-0823:341 reply > While I'm not a hardware designer, my gut says that you can probably do x86 instruction length-decoding in one cycle
That's some very faint praise there. Especially when you're trying to chop up several instructions every cycle. Meanwhile RISC-V is "count leading 1s. 0-1:16bit 2-4:32bit 5:48bit 6:64bit"
The chopping up can happen the next cycle, in parallel across all the instructions in the cache line(s) that were fetched, and it can be pipelined so there's no loss in throughput. Since x86 instructions can be as small as one byte, in principle the throughput-per-cache-line can be higher on x86 than on RISC-V (e.g. a single 32-byte x86 cache line could have up to 32 instructions where the original RISC-V ISA might only have 8). And in any case, there are RISC-V extensions that allow variable-length instructions now, so they have to deal with the problem too.
By codedokode 2025-09-096:54 As for program size, I played with small algorithms (like binary search) on godbolt, and my x86 programs had similar size to RISC-V with compressed instructions. I rarely saw 1-byte instructions, there almost always was at least one prefix.
> e.g. a single 32-byte x86 cache line could have up to 32 instructions where the original RISC-V ISA might only have 8
With compressed instructions the theoretical maximum is 16.
> so they have to deal with the problem too.
Luckily you can determine the length from first bits of an instruction, and you can have either 2 bytes left from previous line, or 0.
By Dylan16807 2025-09-091:31 > The chopping up can happen the next cycle
It still causes issues.
> Since x86 instructions can be as small as one byte, in principle the throughput-per-cache-line can be higher on x86 than on RISC-V (e.g. a single 32-byte x86 cache line could have up to 32 instructions where the original RISC-V ISA might only have 8).
RISC-V has better code density. The handful of one byte instructions don't make up for other longer instructions.
> And in any case, there are RISC-V extensions that allow variable-length instructions now, so they have to deal with the problem too.
Now? Have to deal with the problem too?
It feels like you didn't read my previous post. I was explaining how it's much much simpler to decode length. And the variable length has been there since the original version.
By monocasa 2025-09-093:03 > While I'm not a hardware designer, my gut says that you can probably do x86 instruction length-decoding in one cycle
That's been my understanding as well. X86 style length decoding is about one pipeline stage if done dynamically.
The simpler riscv length decoding ends up being about a half pipeline stage on the wider decoders.
By eigenform 2025-09-094:06 Don't know this for certain, but I always assumed that x86 implementations get away with this by predecoding cachelines. If you're going to do prefetching in parallel and decoupled from everything else, might as well move part of the work there too? (obviously not without cost - plus, you can identify branches early!)
By matja 2025-09-098:39 Missing a 0 at the end
By monocasa 2025-09-092:57 > x86 decoding must be a pain - I vaguely remember that they have trace caches (a cache of decoded micro-operations) to skip decoding in some cases. You probably don't make such caches when decoding is easy.
To be fair, a lot of modern ARM cores also have uop caches. There's a lot to decide even without the variable length component, to the point that keeping a cache of uops and temporarily turning pieces of the IFU off can be a win.
By jabl 2025-09-097:32 > I vaguely remember that they have trace caches (a cache of decoded micro-operations) to skip decoding in some cases. You probably don't make such caches when decoding is easy.
The P4 microarch had trace caches, but I believe that approach has since been avoided. What practically all contemporary x86 processors do have, though is u-op caches, which contain decoded micro-ops. Note this is not the same as a trace cache.
For that matter, many ARM cores also have u-op caches, so it's not something that is uniquely useful only on x86. The Apple M* cores AFAIU do not have u-op caches, FWIW.
> trace caches
They don't anymore they have uop caches, but trace caches are great and apple uses them [1].
They allow you to collapse taken branches into a single fetch.
Which is extreamly important, because the average instructions/taken-branch is about 10-15 [2]. With a 10 wide frontend, every second fetch would only be half utilized or worse.
> extra caches
This is one thing I don't understand, why not replace the L1I with the uop-cache entirely?
I quite like what Ventana does with the Veyron V2/V3. [3,4] They replaced the L1I with a macro-op trace cache, which can collapse taken branches, do basic instruction fusion and more advanced fusion for hot code paths.
[1] https://www.realworldtech.com/forum/?threadid=223220
[2] https://lists.riscv.org/g/tech-profiles/attachment/353/0/RIS... (page 10)
By adgjlsfhk1 2025-09-0919:51 you need both. Branches don't tell you "jump to this micro-op", they're "jump to this address" so you need the address numbering of a normal L1i.
Intel’s E cores decode x86 without a trace cache (μop cache), and are very efficient. The latest (Skymont) can decode 9 x86 instructions per cycle, more than the P core (which can only decode 8)
AMD isn’t saying that decoding x86 is easy. They are just saying that decoding x86 doesn’t have a notable power impact.
Does that really say anything about efficiency? Why can't they decode 100 instructions per cycle?
> Why can't they decode 100 instructions per cycle?
Well, obviously because there aren't 100 individual parallel execution units to which those instructions could be issued. And lower down the stack because a 3000 bit[1] wide cache would be extremely difficult to manage. An instruction fetch would be six (!) cache lines wide, causing clear latency and bottleneck problems (or conversely would demand your icache be 6x wider, causing locality/granularity problems as many leaf functions are smaller than that).
But also because real world code just isn't that parallel. Even assuming perfect branch prediction the number of instructions between unpredictable things like function pointer calls or computed jumps is much less than 100 in most performance-sensitive algorithms.
And even if you could, the circuit complexity of decoding variable length instructions is superlinear. In x86, every byte can be an instruction boundary, but most aren't, and your decoder needs to be able to handle that.
[1] I have in my head somewhere that "the average x86_64 instruction is 3.75 bytes long", but that may be off by a bit. Somewhere around that range, anyway.
Wasn't the point of SMT that a single instruction decoder had difficulty keeping the core's existing execution units busy?
By ajross 2025-09-092:44 No, it's about instruction latency. Some instructions (cache misses that need to hit DRAM) will stall the pipeline and prevent execution of following instructions that depend on the result. So the idea is to keep two streams going at all times so that the other side can continue to fill the units. SMT can be (and was, on some Atom variants) a win even with an in-order architecture with only one pipeline.
By imtringued 2025-09-098:02 That's a gross misrepresentation of what SMT is to the point where nothing you said is correct.
First of all. In SMT there is only one instruction decoder. SMT merely adds a second set of registers, which is why it is considered a "free lunch". The cost is small in comparison to the theoretical benefit (up to 2x performance).
Secondly. The effectiveness of SMT is workload dependent, which is a property of the software and not the hardware.
If you have a properly optimized workload that makes use of the execution units, e.g. a video game or simulation, the benefit is not that big or even negative, because you are already keeping the execution units busy and two threads end up sharing limited resources. Meanwhile if you have a web server written in python, then SMT is basically doubling your performance.
So, it is in fact the opposite. For SMT to be effective, the instruction decoder has to be faster than your execution units, because there are a lot of instructions that don't even touch them.
By BobbyTables2 2025-09-092:07 I vaguely thought it was to provide another source of potentially “ready” instructions when the main thread was blocked on I/O to main memory (such as when register renaming can’t proceed because of dependencies).
But I could be way off…
By fulafel 2025-09-095:29 No, it's about the same bottleneck that also explains the tapering off of single core performance. We can't extract more parallelism from the single flow-of-control of programs, because operations (and esp control flow transfers) are dependent on results of previous operations.
SMT is about addressing the underutilization of execution resources where your 6-wide superscalar processor gets 2.0 ILP.
By eigenform 2025-09-094:08 I think part of the argument is that doing a micro-op cache is not exactly cutting down on your power/area budget.
(But then again, do the AMD e-cores have uop caches?)
> x86 also has flags, which add implicit dependencies between instructions, and must make designer's life harder.
Fortunately flags (or even individual flag bits) can be renamed just like other registers, removing that bottleneck. And some architectures that use flag registers, like aarch64, have additional arithmetic instructions which don't update the flag register.
Using flag registers brings benefits as well. E.g. conditional jump distances can be much larger (e.g. 1 MB in aarch64 vs. 4K in RISC-V).
By adgjlsfhk1 2025-09-0919:58 How big a difference is that? 1MB is still too small to jump to an arbitrary function, and 4K is big enough to almost always jump within a function.
By eigenform 2025-09-093:57 > [...] imagine that while you are loading 16 or 32 bytes from instruction cache, you need to predict the address of next loaded chunk in the same cycle, before you even see what you got from cache.
Yeah, you [ideally] want to predict the existence of taken branches or jumps in a cache line! Otherwise you have cycles where you're inserting bubbles into the pipeline (if you aren't correctly predicting that the next-fetched line is just the next sequential one ..)
Variable length decoding is more or less figured out, but it takes more design effort, transistors and energy. They cost, but not a lot, relatively, in a current state of the art super wide out-of-order CPU.
By wallopinski 2025-09-091:142 reply "Transistors are free."
That was pretty much the uArch/design mantra at intel.
By nerpderp82 2025-09-092:591 reply Isn't that still true for high perf chips? We don't have ways to use all those transistors so we make larger and larger caches.
By exmadscientist 2025-09-095:121 reply Max-performance chips even introduce dead dummy transistors ("dark silicon") to provide a bit of heat sinking capability. Having transistors that are sometimes-but-rarely useful is no problem whatsoever for modern processes.
AFAIK the dark silicon term is specifically those transistors not always powered on. Doping the Si substrate to turn it into transistors is not going to change the heat profile, so I don't think dummy transistors are added on purpose for heat management. Happy to be proven wrong though.
By exmadscientist 2025-09-0923:50 My understanding is that pretty much every possible combination of these things is found somewhere in a modern chip. There are dummy transistors, dark transistors, slow transistors... everything. Somewhere.
By drob518 2025-09-094:17 It has turned out to be a pretty good rule of thumb over the decades.
Not a lot is not how I would describe it. Take a 64bit piece of fetched data. On ARM64 you will just push that into two decoder blocks and be done with it. On x86 you got what, 1 to 15 bytes range per instruction? I dont even want to think about possible permutations, its in the 10 ^ some two digit number order.
You don't need all the permutations. If there are 32 bytes in a cache line then each instruction can only start at one of 32 possible positions. Then if you want to decode N instructions per cycle you need N 32-to-1 muxes. You can reduce the number of inputs to the later muxes since instructions can't be zero size.
By monocasa 2025-09-093:05 It was even simpler until very recently where the decode stage would only look at a max 16 byte floating window.
By saagarjha 2025-09-091:05 Yes, but you're not describing it from the right position. Is instruction decode hard? Yes, if you think about it in isolation (also, fwiw, it's not a permutation problem as you suggest). But the core has a bunch of other stuff it needs to do that is far harder. Even your lowliest Pentium from 2000 can do instruction decode.
By ahartmetz 2025-09-0821:46 It's a lot for a decoder, but not for a whole core. Citation needed, but I remember that the decoder is about 10% of a Ryzen core's power budget, and of course that is with a few techniques better than complete brute force.
By topspin 2025-09-096:02 I've listened Keller's views on CPU design and the biggest takeaway I found is that performance is overwhelmingly dominated by predictors. Good predictors mitigate memory latency and keep pipelines full. Bad predictors stall everything while cores spin on useless cache lines. The rest, including ISA minutiae, rank well below predictors on the list of things that matter.
At one time, ISA had a significant impact on predictors: variable length instructions complicated predictor design. The consensus is that this is no longer the case: decoders have grown to overcome this and now the difference is negligible.
Yeah I'm not sure I buy it either.
It doesn't matter if most instructions have simple encodings. You still need to design your front end to handle the crazy encodings.
I doubt it makes a big difference, so until recently he would have been correct - why change your ISA when you can just wait a couple of months to get the same performance improvement. But Moore's law is dead now so small performance differences matter way more now.
By imtringued 2025-09-098:141 reply The core argument in RISC vs CISC has never been that you can't add RISC style instructions to a CISC. If anything, the opposite is true, because CISC architectures just keep adding more and more instructions.
The argument has been that even if you have a CISC ISA that also happens to have a subset of instructions following the RISC philosophy, that the bloat and legacy instructions will hold CISC back. In other words, the weakness of CISC is that you can add, but never remove.
Jim Keller disagrees with this assessment and it is blatantly obvious.
You build a decoder that predicts that the instructions are going to have simple encodings and if they don't, then you have a slow fallback.
Now you might say that this makes the code slow under the assumption that you make heavy use of the complex instructions, but compilers have a strong incentive to only emit fast instructions.
If you can just add RISC style instructions to CISC ISAs, the entire argument collapses into irrelevance.
It's not just the complex encodings though, there's also the variable instruction length, and the instruction semantics that mean you need microcode.
Obviously they've done an amazing job of working around it, but that adds a ton of complexity. At the very least it's going to mean you spend engineering resources on something that ARM & RISC-V don't even have to worry about.
This seems a little like a Java programmer saying "garbage collection is solved". Like, yeah you've made an amazingly complicated concurrent compacting garbage collector that is really fast and certainly fast enough almost all of the time. But it's still not as fast as not doing garbage collection. If you didn't have the "we really want people to use x86 because my job depends on it" factor then why would you use CISC?
By exmadscientist 2025-09-0923:49 > RISC-V don't even have to worry about
Except that RISC-V had to bolt on a variable-length extension, giving the worst of all possible worlds....
Apple’s ARM cores have wider decode than x86
M1 - 8 wide
M4 - 10 wide
Zen 4 - 4 wide
Zen 5 - 8 wide
By adgjlsfhk1 2025-09-0821:584 reply pure decoder width isn't enough to tell you everything. X86 has some commonly used ridiculously compact instructions (e.g. lea) that would turn into 2-3 instructions on most other architectures.
By ajross 2025-09-0823:03 The whole ModRM addressing encoding (to which LEA is basically a front end) is actually really compact, and compilers have gotten frightently good at exploiting it. Just look at the disassembly for some non-trivial code sometime and see what it's doing.
By monocasa 2025-09-093:01 Additionally, stuff llike rmw instructions are really like at least three, maybe four or five risc instructions.
By ack_complete 2025-09-0914:39 Yes, but so does ARM. ld1 {v0.16b,v1.16b,v2.16b,v3.16b},x0,#64 loads 4 x 128-bit vector registers and post-increments a pointer register.
By kimixa 2025-09-0822:07 Also the op cache - if it hits that the decoder is completely skipped.
By ryuuchin 2025-09-091:54 Is Zen 5 more like a 4x2 than a true 8 since it has dual decode clusters and one thread on a core can't use more than one?
By wmf 2025-09-0819:21 Skymont - 9 wide
By mort96 2025-09-0822:36 Wow, I had no idea we were up to 8 wide decoders in amd64 CPUs.
By devnullbrain 2025-09-0912:281 reply > fixed-length instructions seem really nice when you're building little baby computers, but if you're building a really big computer, to predict or to figure out where all the instructions are, it isn't dominating the die. So it doesn't matter that much.
The notebooks of TFA aren't really big computers.
By adgjlsfhk1 2025-09-0920:01 they are. By "small" here, we're referring to the Core size, not the machine size. i.e. an in order, dual issue cpu is small, but a M1 chip is massive.
By AnotherGoodName 2025-09-0820:331 reply For variable vs fixed width i have heard that fixed width is part of apple silicons performance. There’s literally gains to be had here for sure imho.
By astrange 2025-09-0823:28 It's easier but it's not that important. It's more important for security - you can reinterpret variable length instructions by jumping inside them.
This matches my understanding as well, as someone who has a great deal of interest in the field but never worked in it professionally. CPUs all have a microarchitecture that doesn't look like the ISA at all, and they have an instruction decoder that translates ISA one or more ISA instructions into zero or more microarchitectural instructions. There are some advantages to having a more regular ISA, such as the ability to more easily decode multiple instructions in parallel if they're all the same size or having to spend fewer transistors on the instruction decoder, but for the big superscalar chips we all have in our desktops and laptops and phones, the drawbacks are tiny.
I imagine that the difference is much greater for the tiny in-order CPUs we find in MCUs though, just because an amd64 decoder would be a comparatively much larger fraction of the transistor budget
By themafia 2025-09-0821:08 Then there's mainframes. Where you want code compiled in 1960 to run unmodified today. There was quite of original advantage as well as IBM was able to implement the same ISA with three different types and costs of computers.
By astrange 2025-09-0823:32 uOps are kind of oversold in the CPU design mythos. They are not that different from the original ISA, and some x86 instructions (like lea) are both complex and natural fits for hardware so don't get microcoded.
>RISC-V is a new-school hyper-academic hot mess.
Yeah... Previously I was a big fan of RISC-V, but after I had to dig slightly deeper into it as a software developer my enthusiasm for it has cooled down significantly.
It's still great that we got a mainstream open ISA, but now I view it as a Linux of the hardware world, i.e. a great achievement, with a big number of questionable choices baked in, which unfortunately stifles other open alternatives by the virtue of being "good enough".
By chithanh 2025-09-096:32 > which unfortunately stifles other open alternatives by the virtue of being "good enough".
In China at least, the hardware companies are smart enough to not put all eggs in the RISC-V basket, and are pursuing other open/non-encumbered ISAs.
They have LoongArch which is a post-MIPS architecture with elements from RISC-V. Also they have ShenWei/SunWay which is post-Alpha.
And they of course have Phytium (ARM), HeXin (OpenPower), and Zhaoxin (x86).
By codedokode 2025-09-0821:571 reply What choices? The main thing that comes to mind is lack of exceptions on integer overflow but you are unlikely meaning this.
- Handling of misaligned loads/stores: RISC-V got itself into a weird middle ground, ops on misaligned pointers may work fine, may work "extremely slow", or cause fatal exceptions (yes, I know about Zicclsm, it's extremely new and only helps with the latter, also see https://github.com/llvm/llvm-project/issues/110454). Other platforms either guarantee "reasonable" performance for such operations, or forbid misaligned access with "aligned" loads/stores and provide separate misaligned instructions. Arguably, RISC-V should've done the latter (with misaligned instructions defined in a separate higher-end extension), since passing unaligned pointer into an aligned instruction signals correctness problems in software.
- The hardcoded page size. 4 KiB is a good default for RV32, but arguably a huge missed opportunity for RV64.
- The weird restriction in the forward progress guarantees for LR/SC sequences, which forces compilers to compile `compare_exchange` and `compare_exchange_weak` in the absolutely same way. See this issue for more information: https://github.com/riscv/riscv-isa-manual/issues/2047
- The `seed` CSR: it does not provide a good quality entropy (i.e. after you accumulated 256 bits of output, it may contain only 128 bits of randomness). You have to use a CSPRNG on top of it for any sensitive applications. Doing so may be inefficient and will bloat binary size (remember, the relaxed requirement was introduced for "low-powered" devices). Also, software developers may make mistake in this area (not everyone is a security expert). Similar alternatives like RDRAND (x86) and RNDR (ARM) guarantee proper randomness and we can use their output directly for cryptographic keys with very small code footprint.
- Extensions do not form hierarchies: it looks like the AVX-512 situation once again, but worse. Profiles help, but it's not a hierarchy, but a "packet". Also, there are annoyances like Zbkb not being a proper subset of Zbb.
- Detection of available extensions: we usually have to rely on OS to query available extensions since the `misa` register is accessible only in machine mode. This makes detection quite annoying for "universal" libraries which intend to support various OSes and embedded targets. The CPUID instruction (x86) is ideal in this regard. I totally disagree with the virtualization argument against it, nothing prevents VM from intercepting the read, no one excepts huge performance from such reads.
And this list is compiled after a pretty surface-level dive into the RISC-V spec. I heard about other issues (e.g. being unable to port tricky SIMD code to the V extension or underspecification around memory coherence important for writing drivers), but I can not confidently talk about those, so it's not part of my list.
P.S.: I would be interested to hear about other people gripes with RISC-V.
By brandmeyer 2025-09-0913:202 reply Nothing major, just some oddball decisions here and there.
Fused compare-and-branch only extends to the base integer instructions. Anything else needs to generate a value that feeds into a compare-and-branch. Since all branches are compare-and-branch, they all need two register operands, which impairs their reach to a mere +/- 4 kB.
The reach for position-independent code instructions (AUIPC + any load or store) is not quite +/- 2 GB. There is a hole on either end of the reach that is a consequence of using a sign-extended 12-bit offset for loads and stores, and a sign-extended high 20-bit offset for AIUPC. ARM's adrp (address of page) + unsigned offsets is more uniform.
RV32 isn't a proper subset of RV64, which isn't a proper subset of RV128. If they were proper subsets, then RV64 programs could run unmodified on RV128 hardware. Not that its going to ever happen, but if it did, the processor would have to mode-switch, not unlike the x86-64 transition of yore.
Floating point arithmetic spends three bits in the instruction encoding to support static rounding modes. I can count on zero hands the number of times I've needed that.
The integer ISA design goes to great lengths to avoid any instructions with three source operands, in order to simplify the datapaths on tiny machines. But... the floating point extension correctly includes fused multiply-add. So big chunks of any high-end processor will need three-operand datapaths anyway.
The base ISA is entirely too basic, and a classic failure of 90% design. Just because most code doesn't need all those other instructions doesn't mean that most systems don't. RISC-V is gathering extensions like a Katamari to fill in all those holes (B, Zfa, etc).
None of those things make it bad, I just don't think its nearly as shiny as the hype. ARM64+SVE and x86-64+AVX512 are just better.
By adgjlsfhk1 2025-09-0919:341 reply > Floating point arithmetic spends three bits in the instruction encoding to support static rounding modes.
IMO this is way better than the alternative in x86 and ARM. The reason no one deals with rounding modes is because changing the mode is really slow and you always need to change it back or else everything breaks. Being able to do it in the instruction allows you to do operations with non-standard modes much more simply. For example, round-to-nearest-ties-to-odd can be incredibly useful to prevent double rounding.
By brandmeyer 2025-09-1315:141 reply You can't even express static rounding in C. You can't even express them in the LLVM language-independent IR. Any attempt to use the static rounding modes will necessarily involve intrinsics and/or assembly.
By adgjlsfhk1 2025-09-154:18 There's a chicken and egg problem here. C can't express this, and there's no LLVM IR for this because up till now, everyone has had global registers for configuring fpus which make them slow and useless.
C probably won't support this for decades (ISO tends to be pretty conservative), but other languages (e.g Rust/Julia) might support this soonish (especially if LLVM adds support)
By adgjlsfhk1 2025-09-0919:39 > The base ISA is entirely too basic
IMO this is very wrong. The base ISA is excellent for micro-controllers and teaching, but the ~90% of real implementations can add the extra 20 extensions to make a modern, fully featured CPU.
By ack_complete 2025-09-092:021 reply > Detection of available extensions: we usually have to rely on OS to query available extensions since the `misa` register is accessible only in machine mode.
Not a RISC-V programmer, but this drives me crazy on ARM. Dozens of optional features, but the FEAT_ bits are all readable only from EL1, and it's unspecified what API the OS exposes to query it and which feature bits are exposed. I don't care if it'd be slow, just give us the equivalent of a dedicated CPUID instruction, even if it just a reserved opcode that traps to kernel mode and is handled in software.
By cesarb 2025-09-093:31 > but the FEAT_ bits are all readable only from EL1, [...] I don't care if it'd be slow, just give us the equivalent of a dedicated CPUID instruction, even if it just a reserved opcode that traps to kernel mode and is handled in software.
I like the way the Linux kernel solves this: these FEAT_ bits are also readable from EL0, since trying to read them traps to kernel mode and the read is emulated by the kernel. See https://docs.kernel.org/arch/arm64/cpu-feature-registers.htm... for details. Unfortunately, it's a Linux-only feature, and didn't exist originally (so old enough Linux kernel versions won't have the emulation).
By dzaima 2025-09-0910:14 Another bad choice (perhaps more accurately called a bug, but they chose to not do anything about it): vmv1.r & co (aka whole-vector-register move instructions) depend on valid vtype being set, despite not using any part of it (outside of the extreme edge-case of an interrupt happening in the middle of it, and the hardware wanting to chop the operation in half instead of finishing it (entirely pointless for application-class CPUs where VLEN isn't massive enough for that to in any way be useful; never mind moves being O(1) with register renaming))
So to move one vector register to another, you need to have a preceding vsetvl; worse, with the standard calling convention you may get illegal vtype after a function call! Even worse, the behavior is actually left reserved for for move with illegal vtype, so hardware can (and some does) just allow it, thereby making it impossible to even test for on some hardware.
Oh, and that thing about being able to stop a vector instruction midway through? You might think that's to allow guaranteeing fast interrupts while keeping easy forwards progress; but no, vector reductions cannot be restarted.. And there's the extremely horrific vfredosum[1], which is an ordered float sum reduction, i.e. a linear chain of N float adds, i.e. a (fp add latency) * (element count in vector) -cycle op that must be started completely over again if interrupted.
[1]: https://dzaima.github.io/intrinsics-viewer/#0q1YqVbJSKsosTtY...
By mixmastamyk 2025-09-0823:31 Sounds like a job for RISC-6, or VI.
By adgjlsfhk1 2025-09-090:231 reply > - The hardcoded page size.
I'm pretty confident that this will get removed. It's an extension that made it's way into RVA23, but once anyone has a design big enough for it to be a burden, it can be dropped.
By monocasa 2025-09-093:09 That's really hard to drop.
Fancier unix programs tend to make all kinds of assumptions about page size to do things like the double mapped ring buffer trick.
https://en.wikipedia.org/wiki/Circular_buffer#Optimization
In fact it looks like apple silicon maintains support for 4kb pages just for running Rosetta. It's one of those things like TSO that was enough of a pain to work around the assumptions that they just included hardware support for it that isn't enabled when running in regular arm software mode.
> Handling of misaligned loads/stores
Agreed, I think the problem is that RVI doesn't want to/can't mandate implementation details.
I hope that the first few RVA23 cores will have proper misaligned load/store support and we can tell toolchains RVA23 or Zicclsm means fast misaligned load/store and future hardware that is stupid enough to not implement it, will just have to suffer.
There is some silver lining, because you can transform N misaligned loads into N+1 aligned ones + a few instructions to stich together the result. Currently this needs to be done manually, but hopefully it will be an optimization in future compiler versions: https://github.com/llvm/llvm-project/issues/150263 (Edit: oh, I should've recognised your username, xd)
> The hardcoded page size.
There is Svnapot, which is supposes to allow other page sizes, but I don't know enough about it to be sure it actually solves the problem properly.
> You have to use a CSPRNG on top of it for any sensitive applications
Shouldn't you have to do that reguardless and also mix in other kind of state on OS level?
> Extensions do not form hierarchies
The mandatory extensions in the RVA profiles are a hierarchy.
> Detection of available extensions
I think this is being worked on with unified disvover, whch should also cover other microarchitectural details.
There also is a neat toolchain solution with: https://github.com/riscv-non-isa/riscv-c-api-doc/blob/main/s...
> being unable to port tricky SIMD code to the V extension
Anything NEON code is trivially ported to RVV, as is AVX-512 code that doesn't use GFNI which is pretty much the only extension that doesn't have a RVV equivalent yet (neither does NEON or SVE though).
Where the complaints come from is if you want to take full advantage of the native vector length in VLA code, which can sometimes be tricky, especially in existing projects which are sometimes build arround the assumption of fixed vector lengths. But you can always fall back to using RVV as a fixed vector length ISA with a much faster way of querrying vector length then CPUID.
> P.S.: I would be interested to hear about other people gripes with RISC-V
I feel like encoding scalar fmacc with three sources and seperate destinations and rounding modes was a huge waste of encoding space, I would trade that for a vpternlog equivalent, which also is a encoding hog, any day.
The vl=0 special case was a bad idea, now you have to know/predict vl!=0 to get rid of the vector destination as a read dependency, or have some mechanism to kill an instuction if vl=0.
There should've been restricted vrgather variants earlier, but I'm now (slowly) working on proposing them and a handfull of other new vector instructions (mask add/sub, pext/pdep, bmatflip).
Overall though, I think RVV came out suprizingly good, everything works thogether very nicely.
By zozbot234 2025-09-098:19 > I feel like encoding scalar fmacc with three sources and seperate destinations and rounding modes was a huge waste of encoding space
This might be easily solved by defining new lighter varieties of the F/D/Q extensions (under new "Z" names) that just don't include the fmacc insn blocks and reserve them for extension. (Of course, these new extensions would themselves be incompatible with the full F/D/Q extensions, effectively deprecating them for general use and relegating them to special-purpose uses where the FMACC encodings are genuinely useful.) Something to think about if the 32-bit insn encoding space becomes excessively scarce.
By camdroidw 2025-09-0917:53 Reading this and child comments it would seem to me that we need a RISC Vim
By whynotminot 2025-09-0815:495 reply An annoying thing people have done since Apple Silicon is claim that its advantages were due to Arm.
No, not really. The advantage is Apple prioritizing efficiency, something Intel never cared enough about.
In most cases, efficiency and performance are pretty synonymous for CPUs. The faster you can get work done (and turn off the silicon, which is admittedly a higher design priority for mobile CPUs) the more efficient you are.
The level of talent Apple has cannot be understated, they have some true CPU design wizards. This level of efficiency cannot be achieved without making every aspect of the CPU as fast as possible; their implementation of the ARM ISA is incredible. Lots of companies make ARM chips, but none of them are Apple level performance.
As a gross simplification, where the energy/performance tradeoff actually happens is after the design is basically baked. You crank up the voltage and clock speed to get more perf at the cost of efficiency.
By toast0 2025-09-0823:45 > In most cases, efficiency and performance are pretty synonymous for CPUs. The faster you can get work done (and turn off the silicon, which is admittedly a higher design priority for mobile CPUs) the more efficient you are.
Somewhat yes, hurry up and wait can be more efficient than running slow the whole time. But at the top end of Intel/AMD performance, you pay a lot of watts to get a little performance. Apple doesn't offer that on their processors, and when they were using Intel processors, they didn't provide thermal support to run in that mode for very long either.
The M series bakes in a lower clockspeed cap than contemperary intel/amd chips; you can't run in the clock regime where you spend a lot of watts and get a little bit more performance.
By MindSpunk 2025-09-092:27 Apple also buys out basically all of TSMC's initial capacity for their leading edge node so generally every time a new Apple Silicon thing comes out it's a process node ahead of every other chip they're comparing to.
By prioritizing efficiency, Apple also prioritizes integration. The PC ecosystem prefers less integration (separate RAM, GPU, OS, etc) even at the cost of efficiency.
By AnthonyMouse 2025-09-090:051 reply > By prioritizing efficiency, Apple also prioritizes integration. The PC ecosystem prefers less integration (separate RAM, GPU, OS, etc) even at the cost of efficiency.
People always say this but "integration" has almost nothing to do with it.
How do you lower the power consumption of your wireless radio? You have a network stack that queues non-latency sensitive transmissions to minimize radio wake-ups. But that's true for radios in general, not something that requires integration with any particular wireless chip.
How do you lower the power consumption of your CPU? Remediate poorly written code that unnecessarily keeps the CPU in a high power state. Again not something that depends on a specific CPU.
How much power is saved by soldering the memory or CPU instead of using a socket? A negligible amount if any; the socket itself has no significant power draw.
What Apple does well isn't integration, it's choosing (or designing) components that are each independently power efficient, so that then the entire device is. Which you can perfectly well do in a market of fungible components simply by choosing the ones with high efficiency.
In fact, a major problem in the Android and PC laptop market is that the devices are insufficiently fungible. You find a laptop you like where all the components are efficient except that it uses an Intel processor instead of the more efficient ones from AMD, but those components are all soldered to a system board that only takes Intel processors. Another model has the AMD APU but the OEM there chose poorly for the screen.
It's a mess not because the integration is poor but because the integration exists instead of allowing you to easily swap out the part you don't like for a better one.
By adgjlsfhk1 2025-09-090:301 reply > How much power is saved by soldering the memory or CPU instead of using a socket? A negligible amount if any; the socket itself has no significant power draw.
This isn't quite true. When the whole chip is idling at 1-2W, 0.1W of socket power is 10%. Some of Apple's integration almost certainly save power (e.g. putting storage controllers for the SSD on the SOC, having tightly integrated display controllers, etc).
By AnthonyMouse 2025-09-091:26 > When the whole chip is idling at 1-2W, 0.1W of socket power is 10%.
But how are you losing 10% of power to the socket at idle? Having a socket might require traces to be slightly longer but the losses to that are proportional to overall power consumption, not very large, and both CPU sockets and the new CAMM memory standard are specifically designed to avoid that anyway (primarily for latency rather than power reasons because the power difference is so trivial).
> Some of Apple's integration almost certainly save power (e.g. putting storage controllers for the SSD on the SOC, having tightly integrated display controllers, etc).
This isn't really integration and it's very nearly the opposite: The primary advantage here in terms of hardware is that the SoC is being fabbed on 3nm and then the storage controller would be too, which would be the same advantage if you would make an independent storage controller on the same process.
Which is the problem with PCs again: The SSDs are too integrated. Instead of giving the OS raw access to the flash chips, they adhere a separate controller just to do error correction and block remapping, which could better be handled by the OS on the main CPU which is fabbed on a newer process or, in larger devices with a storage array, a RAID controller that performs the task for multiple drives at once.
And which would you rather have, a dual-core ARM thing integrated with your SSD, or the same silicon going to two more E-cores on the main CPU which can do the storage work when there is any but can also run general purpose code when there isn't?
There's a critical instruction for Objective C handling (I forget exactly what it is) but it's faster than intel's chips even in Rosetta 2's x86 emulation.
Eh, probably the biggest difference is in the OS. The amount of time Linux or Windows will spend using a processor while completely idle can be a bit offensive.
It’s all of the above. One thing Apple excels at is actually using their hardware and software together whereas the PC world has a long history of one of the companies like Intel, Microsoft, or the actual manufacturer trying to make things better but failing to get the others on-board. You can in 2025 find people who disable power management because they were burned (hopefully not literally) by some combination of vendors slacking on QA!
One good example of this is RAM. Apple Silicon got some huge wins from lower latency and massive bandwidth, but that came at the cost of making RAM fixed and more expensive. A lot of PC users scoffed at the default RAM sizes until they actually used one and realized it was great at ~8GB less than the equivalent PC. That’s not magic or because Apple has some super elite programmers, it’s because they all work at the same company and nobody wants to go into Tim Cook’s office and say they blew the RAM budget and the new Macs need to cost $100 more. The hardware has compression support and the OS and app teams worked together to actually use it well, whereas it’s very easy to imagine Intel adding the feature but skimping on speed / driver stability, or Microsoft trying to implement it but delaying release for a couple years, or not working with third-party developers to optimize usage, etc. – nobody acting in bad faith but just what inevitably happens when everyone has different incentives.
Windows 10 introduced memory compression. Here's a discussion from 2015 [0]. And one on Linux by IBM from 2013 [1]. But the history goes way back [2].
I don't know why that '8GiB is great!' -- no, no it isn't. Your memory usage just spills over to swap faster. It isn't more efficient (not with those 16KiB pages).
[0] https://learn.microsoft.com/en-us/shows/Seth-Juarez/Memory-C...
[1] https://events.static.linuxfound.org/sites/events/files/slid...
[2] https://en.wikipedia.org/wiki/Virtual_memory_compression#Ori...
Yes, I'm aware that Windows has memory compression, so let's think about why it's less successful and Windows systems need more memory than Macs.
The Apple version has a very high-performance hardware implementation versus Microsoft's software implementation (not a slam on Microsoft, they just have to support more hardware).
The Apple designers can assume a higher performance baseline memory subsystem because, again, they're working with hardware designers at the same company who are equally committed to making the product succeed.
The core Mac frameworks are optimized to reduce VM pressure and more Mac apps use the system frameworks, which means that you're paying the overhead tax less.
Many Mac users use Safari instead of Chrome so they're saving multiple GB for an app which most people have open constantly as well as all of the apps which embed a WebKit view.
Again, this is not magic, it's aligned incentives. Microsoft doesn't control Intel, AMD, and Qualcomm's product design, they can't force Google to make Chrome better, and they can't force every PC vendor not to skimp on hardware. They can and do work with those companies but it takes longer and in some cases the cost incentives are wrong – e.g. a PC vendor knows 99% of their buyers will blame Windows if they use slower RAM to save a few bucks or get paid to preload of McAfee which keeps the memory subsystem busy constantly so they take the deal which adds to their bottom line now.
Neither macOS nor Windows use a hardware-based accelerator for memory compression. It's all done in software. Linux zram uses Intel QAT but that's only available on a limited number of processors.
You seem to be under the mistaken impression that Microsoft cannot gear Windows to act differently based on the installed hardware (or processor). That's quite untrue.
It was software on Intel but they presumably added instructions with the intention of using them:
https://asahilinux.org/docs/hw/cpu/apple-instructions/
> You seem to be under the mistaken impression that Microsoft cannot gear Windows to act differently based on the installed hardware (or processor).
Definitely not - my point is simply that all of these things are harder and take longer if they have to support multiple implementations and get other companies to ship quality implementations.
> Definitely not - my point is simply that all of these things are harder and take longer if they have to support multiple implementations and get other companies to ship quality implementations.
What's your source for it is "harder" or "takes longer"? #ifdef is a quite well known processor directive to developers and easy to use.
By acdha 2025-09-0922:20 > What's your source for it is "harder" or "takes longer"?
Windows devices’ power management and battery life has been behind Apple since the previous century? If you think hardware support is a simple #ifdef, ask yourself how a compile-time flag can detect firmware updates, driver versions, or flakey hardware. It’s not that Apple’s hardware is perfect but that those are made by the same company so you don’t get Dell telling you to call Broadcom who are telling you to call Microsoft.
By astrange 2025-09-0918:18 > Neither macOS nor Windows use a hardware-based accelerator for memory compression.
Not true.
By achandlerwhite 2025-09-093:38 He didn’t say 8 gigs is great but that you can get by with about 8 gigs less than equivalent on Windows.
By tguvot 2025-09-096:16 i think i had 20+ years ago servers with this https://www.eetimes.com/serverworks-rolls-out-chip-set-based...
By astrange 2025-09-0918:20 > Apple Silicon got some huge wins from lower latency and massive bandwidth, but that came at the cost of making RAM fixed and more expensive.
The memory latency actually isn't good, only bandwidth is good really. But there is a lot of cache to hide that. (The latency from fetching between CPU clusters is actually kind of bad too, so it's important not to contend on those cache lines.)
> A lot of PC users scoffed at the default RAM sizes until they actually used one and realized it was great at ~8GB less than the equivalent PC.
Less than that. Unified memory means that the SSD controller, display, etc subtract from that 8GB, whereas on a PC they have some of their own RAM on the side.
By wvenable 2025-09-095:27 I don't buy it. Software is not magically using less RAM because it was compiled for MacOS. The actual RAM use by the OS itself is relatively small for both operating systems.
Is this meant to be contradicting what I said?
It's all in the OS. There's absolutely no reason RAM can't be managed similarly effectively on a non-integrated product.
Android is just Linux with full attention paid to power saving measures. These OS can get very long battery life, but in my experience the typical experience is something or other keeps the processor active and halves your expected battery life.
By acdha 2025-09-0913:09 My point is that it's not just the OS for Apple, because every part of the device is made by people with the same incentives. Android is slower and has worse battery efficiency than iOS not because Google are a bunch of idiots (quite the contrary) but because they have to support a wider range of hardware and work with the vendors who are going to use slower, less capable components to save $3 per device. Apple had a decade lead on basic things like storage security because when they decided to do that, the hardware team committed to putting high-quality encryption into the SoC and that meant that iOS could just assume that feature existed and was fast starting on the 3GS whereas Google had to spend years and years haranguing the actual phone manufacturers into implementing what was at the time seen as a costly optional feature.
By mschuster91 2025-09-098:261 reply Apple can get away with less RAM because the flash storage is blazing fast and attached directly to the CPU, making swap much more painless than on most Windows machines that get bottom-of-the-barrel storage and controllers.
By acdha 2025-09-0913:12 Yes, that's exactly what I'm talking about: Apple can do that because everyone involved works at the same place and owns the success or failure of the product. Google or Microsoft have to be a lot more conservative because they have limited ability to force the hardware vendors to do something and they'll probably get blamed more if it doesn't work well: people are primed to say “Windows <version + 1> sucks!” even if the real answer is that their PC was marginally-specced when they bought it 5 years ago.
By cheema33 2025-09-095:43 > The advantage is Apple prioritizing efficiency, something Intel never cared enough about.
Intel cared plenty once they realized that they were completely missing out on the mobile phone business. They even made X86/Atom chips for the phone market. Asus for example had some phones (Zenfone) with Intel X86 chips in them in the mid-2010s. However, Intel Atom suffered from poor power efficiency and battery life and soon died.
Also Apple has a ton of cash that it can give to TSMC to essentially get exclusive access to the latest manufacturing process.
By JumpCrisscross 2025-09-095:14 > Apple has a ton of cash that it can give to TSMC to essentially get exclusive access to the latest manufacturing process
How have non-Apple chips on TSMC’s 5nm process compared with Apple’s M series?
By Ianjit 2025-09-097:40 This paper is great:
"Our methodical investigation demonstrates the role of ISA in modern microprocessors’ performance and energy efficiency. We find that ARM, MIPS, and x86 processors are simply engineering design points optimized for different levels of performance, and there is nothing fundamentally more energy efficient in one ISA class or the other. The ISA being RISC or CISC seems irrelevant."
https://dl.acm.org/doi/10.1145/2699682 https://abdullahyildiz.github.io/files/isa_wars.pdf
By tliltocatl 2025-09-0820:311 reply Nitpick: uncore and the fabrication details dominate the ISA on high end/superscalar architectures (because modern superscalar basically abstract the ISA away at the frontend). On smaller (i. e. MCU) cores x86 will never stand any chance.
By bpye 2025-09-0820:40 Not that it stopped Intel trying - https://en.m.wikipedia.org/wiki/Intel_Quark
> Or perhaps AMD will let x86 fade away.
I agree with what you write otherwise, but not this. Why would AMD "let x86 fade away"? They are one of the two oligolistic CPU providers of the x86 ecosystem which is worth zillions. Why should they throw that away in order to become yet another provider of ARM (or RISC-V or whatnot) CPUs? I think that as long as the x86 market remains healthy, and AMD is in a position to compete in that market, they will continue doing so.
By jabl 2025-09-106:03 > oligolistic
I meant to write "oligopolistic", of course.
By somanyphotons 2025-09-0820:502 reply I'd love to see what would happen if AMD put out a chip with the instruction decoders swapped out for risc-v instruction decoders
By AnotherGoodName 2025-09-0823:281 reply Fwiw the https://en.wikipedia.org/wiki/AMD_Am29000 RISC CPU and the https://en.wikipedia.org/wiki/AMD_K5 are a good example of this. As in AMD took their existing RISC CPU to make the K5 x86 CPU.
Almost the same in die shots except the K5 had more transistors for the x86 decoding. The AM29000's instruction set is actually very close to RISC-V too!
Very hard to find benchmarks comparing the two directly though.
By throwawaymaths 2025-09-090:441 reply TIL the k5 was RISC. thank you
By TheAmazingRace 2025-09-096:25 It was a valiant effort by AMD when they made their first attempt at an in-house x86 chip design. Prior to this, AMD effectively cloned Intel designs under license.
Sadly, the K5 was pretty underwhelming upon release, and it wasn’t until AMD acquired NexGen and integrated their special sauce into their next version core, the K6, that things started getting interesting. I was quite fond of my old AMD K6 II+ based PC back in the day. It had good value for the money.
Then you see the K7/Athlon core, complete with inspiration from the DEC Alpha thanks to none other than Jim Keller, and AMD was on a serious tear for a good while after that, beating Intel to 1 GHz.
By guerrilla 2025-09-0820:56 Indeed. We don't need it, but I want it for perfectionist aesthetic completion.
By wlesieutre 2025-09-0815:302 reply VIA used to make low power x86 processors
Fun fact. The idea of strong national security is the reason why there are three companies with access to the x86 ISA.
DoD originally required all products to be sourced by at least three companies to prevent supply chain issues. This required Intel to allow AMD and VIA to produce products based on ISA.
For me this is good indicator if someone that talks about good national security knows what they are talking about or are just spewing bullshit and playing national security theatre.
Intel didnt "allow" VIA anything :). Via acquired x86 tech from IDT (WinChip Centaur garbage) in a fire sale. IDT didnt ask anyone about any licenses, neither did Cyrix, NextGen, Transmeta, Rise nor NEC.
Afaik DoD wasnt the reason behind original AMD second source license, it was IBM forcing Intel on chips that went into first PC.
By cheema33 2025-09-095:45 This.
By DeepYogurt 2025-09-0820:501 reply Transmeta wasn't x86 internally but decoded x86 instructions. Retrobytes did a history of transmeta not too long ago and the idea was essentially to be able to be compatible with any cpu uarch. Alas by the time it shipped only x86 was relevant. https://www.youtube.com/watch?v=U2aQTJDJwd8
By tyfighter 2025-09-0823:13 Actually, the reason Transmeta CPUs were so slow was that they didn't have an x86 instruction hardware decoder. Every code cache (IIRC it was only 32 MB) miss resulted in a micro-architectural trap which translated x86 instructions to the underlying uops in software.
I have a hard time believing this fully: more custom instructions, more custom hardware, more heat.
How can you avoid it?
Since the Pentium Pro the hardware hasn't implemented the ISA, it's converted into micro ops.
Come on, you know what I meant :)
If you want to support AVX e.g. you need 512bit (or 256) wide registers, you need dedicated ALUs, dedicated mask registers etc.
Ice Lake has implemented SHA-specific hardware units in 2019.
By adgjlsfhk1 2025-09-0821:291 reply sure, but Arm has Neon/sve which impose basically the same requirements for vector instructions, and most high performance arm implimentations have a wide suite of crypto instructions (e.g. Apple's M series chips have AES, SHA1 and Sha256 instructions)
By camel-cdr 2025-09-096:18 Neon has it worse, because it's harder to scale issue width then vector length.
Zen5 has four issue 512-bit ALUs, current Arm processors have been stuck at four issue 128-bit for years.
Issue width scales quadratically, while vector length mostly scales linearly.
Intel decided it is easier to rewrite all performance critical applications thrice then to go wider than four issue SIMD.
It will have to be seen if Arm is in a position to push software ro adopt SVE, but currently it looks very bleak, with much of the little SVE code thats out there just assuming 128-bit SVE, because thats what all of the hardware is.
By toast0 2025-09-090:16 ARM has instructions for SHA, AES, vectors, etc too. Pretty much have to pay the cost if you want the perf.
By ryan-ca 2025-09-0917:51 I think AVX is actually power gated when unused.
By CyberDildonics 2025-09-090:10 The computation has to be done somehow, I don't know that it is a given that more available instructions means more heat.
By mananaysiempre 2025-09-0815:2310 reply > x86 didn't dominate in low power because Intel had the resources to care but never did
Remember Atom tablets (and how they sucked)?
That's the point. Early Atom wasn't designed with care but the newer E-cores are quite efficient because they put more effort in.
By Voultapher 2025-09-0912:17 The PMICs were also bad, plus the whole Windows software stack - to this day - is nowhere nearly as well optimized for low background and sleep power usage as MacOS and iOS are.
By Findecanor 2025-09-0815:403 reply You mean Atom tablets running Android ?
I have a ten-year old Lenovo Yoga Tab 2 8" Windows tablet, which I still use at least once every week. It is still useful. Who can say that they are still using a ten-year old Android tablet?
By masfuerte 2025-09-0820:45 I still use my 2015 Kindle Fire (which runs Android) for ebooks and light web browsing.
By peterfirefly 2025-09-0820:571 reply My iPad Mini 4 turns 10 in a month.
By vt240 2025-09-0821:04 Yeah, I got to say in our sound company inventory I still use a dozen 6-10 year old iPads with all the mixers. They run the apps at 30fps and still hold a charge all day.
By YetAnotherNick 2025-09-0815:263 reply > how they sucked
Care to elaborate. I had the 9" mini laptop kind of device based on Atom and don't remember Atom to be the issue.
By mananaysiempre 2025-09-0815:481 reply I had a Atom-based netbook (in the early days when they were 32-bit-only and couldn’t run up-to-date Windows). It didn’t suck, as such, but it was definitely resource-starved.
However, what I meant is Atom-based Android tablets. At about the same time as the netbook craze (late 2000s to early 2010s) there was a non-negligible number of Android tablets, and a noticeable fraction of them was not ARM- but Atom-based. (The x86 target in the Android SDK wasn’t only there to support emulators, originally.) Yet that stopped pretty quickly, and my impression is that that happened because, while Intel would certainly have liked to hitch itself to the Android train, they just couldn’t get Atoms fast enough at equivalent power levels (either at all or quickly enough). Could have been something else, e.g. perhaps they didn’t have the expertise to build SoCs with radios?
Either way, it’s not that Intel didn’t want to get into consumer mobile devices, it’s that they tried and did not succeed.
By toast0 2025-09-0817:52 Android x86 devices suffer when developers include binary libraries and don't add x86. At the time of Intel's x86 for Android push, Google didn't have good apk thinning options, so app developers had to decide if they wanted to add x86 libraries for everyone so that a handful of tablets/phones would work properly... for the most part, many developers said no; even though many/most apps are tested on the android emulator that runs on x86 and probably have binary libraries available to work in that case.
IMHO, If Intel had done another year or two of trying, it probably would have worked, but they gave up. They also canceled x86 for phone like the day before the Windows Mobile Continuum demo, which would have been a potentially much more compelling product with x86, especially if Microsoft allowed running win32 apps (which they probably wouldn't, but the potential would be interesting)
By cptskippy 2025-09-0815:54 Atom used an in-order execution model so it's performance was always going to be lacking. Because it was in-order it had a much simpler decoder and much smaller die size, which meant you could crap the chipset and CPU on a single die.
Atom wasn't about power efficiency or performance, it was about cost optimization.
By Synaesthesia 2025-09-0820:29 It got a lot better. First few generations were dog-slow, although they did work.
By jonbiggums22 2025-09-0912:49 IIRC Intel hobbled early Atom with an ancient process node for the chipsets which actually made up most of the idle power usage. It was pretty clear that both Microsoft and Intel wanted this product category to go away or at least be totally relegated to bottom tier lest it cannibalize their higher margin businesses. And then of course Apple and Android came along and did just that anyway.
By mmis1000 2025-09-0815:57 I have tried one before. And surprisingly, It did not suck as most people claimed to be. I can even do light gaming (warframe) on it with reasonable frame rate. (It's about 2015 ~ 2020 era). So it probably depends on manufacturer (or use case though)
(Also probably due to it is a tablet, so it have a reasonable fast storage instead of hdds like notebooks in that era)
By jojobas 2025-09-091:17 Eeepc was was a hit. Its successors still make excellent cheap long-life laptops, if not as performant as Apple.
By kccqzy 2025-09-0815:48 They sucked because Intel didn't care.
By josefx 2025-09-094:55 What year? I remember Linux gaining some traction in the low end mobile device market early on because Micrsoft just released Vista and that wouldn't even run well on most Vista Ready desktop systems.
By saltcured 2025-09-0815:47 I had an Atom-based Android phone (Razr-i) and it was fine.
By criticalfault 2025-09-0815:41 Were they running windows or android?
After playing around with some ARM hardware I have to say that I don't care whether ARM is more efficient or not as long as the boot process remains the clusterfuck that it is today.
IMHO the major win of the IBM PC platform is that it standardized the boot process from the very beginning, first with the BIOS and later with UEFI, so you can grab any random ISO for any random OS and it will work. Meanwhile in the ARM world it seems that every single CPU board requires its own drivers, device tree, and custom OS build. RISC-V seems to suffer from the same problem, and until this problem is solved, I will avoid them like toxic waste.
By Teknoman117 2025-09-091:042 reply ARM systems that support UEFI are pretty fun to work with. Then there's everything else. Anytime I hear the phrase "vendor kernel" I know I'm in for an experience...
By nicman23 2025-09-097:18 nah when i hear vendor kernel i just do not go for that experience. it is not 2006 get your shit mainline or at least packaged correctly.
By mrheosuper 2025-09-097:39 Fun Fact: Your Qualcomm based Phone may already use UEFI.
By Joel_Mckay 2025-09-093:211 reply In general, most modern ARM 8/9 64bit SoC purged a lot of the vestigial problems.
Yet most pre-compiled package builds still never enable the advanced ASIC features for compatibility and safety-concerns. AMD comparing the NERF'd ARM core features is pretty sleazy PR.
Tegra could be a budget Apple M3 Pro, but those folks chose imaginary "AI" money over awesomeness. =3
By nicman23 2025-09-097:23 nah. if they do not work on their extensions to be supported by general software, that is their problem
By markfeathers 2025-09-091:591 reply Check out ARM SBSA / SBBR which seems aimed at solving most of these issues. https://en.wikipedia.org/wiki/Server_Base_System_Architectur... I'm hopeful RISCV comes up with something similar.
But those initiatives are focused on servers.
What about desktops and laptops? Cellphones? SBC like the Raspberry Pi? That is my concern.
This is also supposed to be for desktops/laptops afaik, idk about phones.
Edit, this part of the server platforms spec certainly: https://github.com/riscv-non-isa/riscv-brs/blob/main/intro.a...
> BRS-I is expected to be used by general-purpose compute devices such as servers, desktops, laptops and other devices with industry expectations on silicon vendor, OS and software ecosystem interoperability.
By pezezin 2025-09-098:31 Thank you, I had missed that part.
It would be great indeed if there is a standardized boot process that every OS can use, I think it would greatly help with RISC-V adoption.
By freedomben 2025-09-0917:25 I could not agree more. I wanted to love ARM, but after playing around with numerous different pieces of hardware, I won't touch it with a ten-foot pole anymore. The power savings is not worth the pain to me.
I hope like hell that RISC-V doesn't end up in the same boot-process toxic wasteland
It's not the ISA. Modern Macbooks are power-efficient because they have:
- RAM on package
- PMIC power delivery
- Better power management by OS
Geekerwan investigated this a while ago, see:
https://www.youtube.com/watch?v=Z0tNtMwYrGA https://www.youtube.com/watch?v=b3FTtvPcc2s https://www.youtube.com/watch?v=ymoiWv9BF7Q
Intel and AMD have implemented these improvements with Lunar Lake and Strix Halo. You can buy an x86 laptop with Macbook-like efficiency right now if you know which SoCs to pick.
edit: Correction. I looked at the die image of Strix Halo and thought it looked like it had on-package RAM. It does not. It doesn't use PMIC either. Lunar Lake is the only Apple M-series competitor on x86 at the moment.
By aurareturn 2025-09-097:332 reply
M4 is about 3.6x more efficient than Strix Halo when under load.[0] On a daily basis, this difference can be more because Apple Silicon has true big.Little cores that send low priority tasks to the highly efficient small cores.Intel and AMD have implemented these improvements with Lunar Lake and Strix Halo. You can buy an x86 laptop with Macbook-like efficiency right now if you know which SoCs to pick.For Lunar Lake, base M4 is about 35% faster, 2x more efficient, and actually has a bigger die size than M4.[1] Intel is discontinuing the Lunar Lake line because it isn't profitable for them.
I'm not sure how you can claim "Mac-like efficiency".
[0]https://imgur.com/a/yvpEpKF
[1]https://www.notebookcheck.net/Intel-Lunar-Lake-CPU-analysis-...
Pardon my loose choice of words regarding the Mac-like efficiency. I was referring to the fact that the battery life is comparable to the M3 in day-to-day use, as demonstrated at around the 5:00 mark in the third video I linked.
In the same video, they also measure perf/watt under heavy load, and it's close to the M1, but not the latest gen M4. I think that's pretty good considering it's a first gen product.
Regarding the discontinuation, it's still on shelves right now, but I'm not sure if there will be future generations. It would be awfully silly of them to discontinue it as it's the best non-Apple laptop chip you can buy right now if you care about efficiency.
By aurareturn 2025-09-0910:491 reply
Which video and timestamp? Are you aware that LNL throttles heavily when on battery life?In the same video, they also measure perf/watt under heavy load, and it's close to the M1, but not the latest gen M4. I think that's pretty good considering it's a first gen product.On battery life, M1 is a whopping 1.5x faster in single thread.[0] That makes M4 2.47x faster when compared to LNL on battery.
So no, LNL is very far behind even M1. That's why there are no fanless LNL laptops.
[0]https://b2c-contenthub.com/wp-content/uploads/2024/09/Intel-...
[0]https://www.pcworld.com/article/2463714/tested-intels-lunar-...
I suspect the throttling behavior has to more do with the power settings used during testing or OEM tuning on specific models.
https://www.youtube.com/watch?v=ymoiWv9BF7Q
In this video, they show the perf/watt curves at 8:30. And they show the on-battery vs on-wall performance at 18:35 across a wide variety of benchmarks, not just Geekbench. They used a Lenovo YOGA Air 15 on Window 11's "Balanced" power plan for their tests. The narrator specifically noted the Macbook-like on-battery performance.
By aurareturn 2025-09-0912:161 reply Reviewers always use max performance setting for benchmarks and then max battery life for battery tests. That's how people get tricked. When they actually buy the laptop and use it for themselves, they complain that it's slow when on battery life or hot/loud when plugged in.
They're not trying to trick you. In fact when they were measuring perf/watt, the Lunar Lake chip was disadvantaged against the Apple M-series because they had to run the SPEC 2017 tests on Ubuntu for the Lunar Lake chip, which has poorer tuning for it compared to Windows 11. You can see a footnote saying the compilation environment was Ubuntu 24.04 LTS on the bottom left corner of the frame when they show the perf/watt graphs.
By aurareturn 2025-09-0913:11 They are trying to trick you. All reviewers are told by Intel to run benchmarks in max performance mode and battery either in balanced or max efficiency mode. These modes will throttle. So the performance you're seeing in reviews aren't achievable in battery mode unless you're ok with drastically lower battery life.
Meanwhile, PCWorld is one of the few that actually ran benchmarks while on battery life - which is what people will experience.
Can somebody who knows about this stuff, please elaborate on if it's 'fair' in the first place to compare apple chips with amd/intel chips?
AMD and Intel chips run on loads of different hardware. On the other hand Apple is fully in control of what hardware (and software) their chips are used with. I don't know, but I assume there's a whole lot of tuning and optimizations that you can do when you don't have to support anything besides what you produce yourself.
Let's say it would hypothethically possible to put an M4 in a regular pc. Wouldn't it lose performance just by doing that?
By aurareturn 2025-09-0916:142 reply
Yes. But an M4 Max running macOS running Parallels running Windows on Arm is still the fastest Windows laptop in the world: https://browser.geekbench.com/v6/cpu/compare/13494385?baseli...Let's say it would hypothethically possible to put an M4 in a regular pc. Wouldn't it lose performance just by doing that?Yeah but an AMD/Intel CPU supports many different types of configurations. Isn't it unfair to compare a chip that only supports one configuration with one that supports many?
It feels to me like we're kind of comparing speeds between a personal automobile and a long haul truck. Yes, one is faster than the other, but that's meaningless, because both have different design considerations. A long haul truck has to be able to carry load, and that makes the design different. Of course they'll still make it as fast as possible, but it's never going to be the same as a car.
Basically what I'm saying is that because it's impossible to strip away all the performance and efficiency improvements that come from apple's total control of the software and hardware stack; is it really possible to conclude that apple sillicon itself is as impressive as they make it out to be?
By aurareturn 2025-09-0921:171 reply Yes because it’s still the fastest SoC running Windows. Further more, consumers don’t care if AMD and Intel have to go into more configurations. They care about what they’re buying for the money.
By legacynl 2025-09-108:28 > Further more, consumers don’t care
Well, I'm a consumer, and I certainly care. But I get your point that a lot of people just want a machine that allows them to browse for 10 hours without needing to be charged, and don't really care about anything else.
But do you also get my point? that on some level the chips/hardware are so different that it's like comparing apples to oranges?
By a_wild_dandan 2025-09-0916:47 That's absolutely wild. I've been loving using the 96GB of (V)RAM in my MacBook + Apple's mlx framework to run quantized AI reasoning models like glm-4.5-air. Running models with hundreds of billions of parameters (at ~14 tok/s) on my damn laptop feels like magic.
This just isn't true. Yes, Lunar Lake has great idle performance. But if you need to actually use the CPU, it's drastically slower than M4 while consuming more power.Intel and AMD have implemented these improvements with Lunar Lake and Strix Halo. You can buy an x86 laptop with Macbook-like efficiency right now if you know which SoCs to pick.Strix Halo battery life and efficiency is not even in the same ball park.
If you look the battery life benchmarks they did at around the 5:00 mark in the third video, you can see that it achieves similar battery life compared to the an M3 Macbook in typical day-to-day use. This reflects the experience most users will have with the device.
It's true that the perf/watt is still a lot worse than the latest gen M4 under heavy load, but it's close enough to the M1 and significantly better than prior laptops chips on x86.
It is a first gen product like the M1. But it does show the ISA is not as big of a limiting factor as popularly believed.
By aurareturn 2025-09-0910:53
No. The typical day to day use of LNL is significantly slower than even M1. LNL throttles like crazy when on battery in order to achieve similar battery life.If you look the battery life benchmarks they did at around the 5:00 mark in the third video, you can see that it achieves similar battery life compared to the an M3 Macbook in typical day-to-day use. This reflects the experience most users will have with the device.https://b2c-contenthub.com/wp-content/uploads/2024/09/Intel-...
By hakube 2025-09-0910:40 Windows laptops performance while on battery is terrible especially when you put it on power save mode. Macbooks on the other hand doesn't have that problem. It's just like you're using an iPad.
By mrheosuper 2025-09-091:531 reply By PMIC, did you mean VRM ?, if not, can you tell me the difference between them ?
I'm not an expert on the topic and don't really know the difference. But in the video they say it can finetune power delivery to individual parts of the SoC and reduce idle power.
By mrheosuper 2025-09-092:251 reply Well, Every single CPU need some kind of voltage regulation module to work.
About "fine tune" part, this does not relate to PMIC(or VRM) at all, more like CPU design: How many power domain does this CPU have ?
I don’t know how it is for Apple-M, but for chips I’ve worked on, this can definitely relate to PMIC/VRMs. You can tune the voltage you feed to the various power domains based on the clock speed required for those domains at any given time. We do it with on-chip power regulators, but I suppose for Apple M it would perhaps be off-chip PMICs feeding power into the chip.
By mrheosuper 2025-09-0911:281 reply it's the other way around. You design PMIC for a given CPU, not designing CPU for a given PMIC(but in Apple case, the engineers can work closely together to come up with something balance).
By gimmeThaBeet 2025-09-0914:34 I always wondered how to gauge how effective Apple's Dialog carveout was, in terms of was it just instant PMIC department or even effective at building a foundation for them? Given their long relationship, I would think it might be pretty seamless.
I assume Apple probably do that more than I know, it is just interesting that their vertical acquisition history feels the most boring and the most interesting.
At least looking from the outside, it feels like relatively small pieces develop into pretty big differentiators, like P.A. Semi, Intrinsity and Passif paving the way to their SoCs.

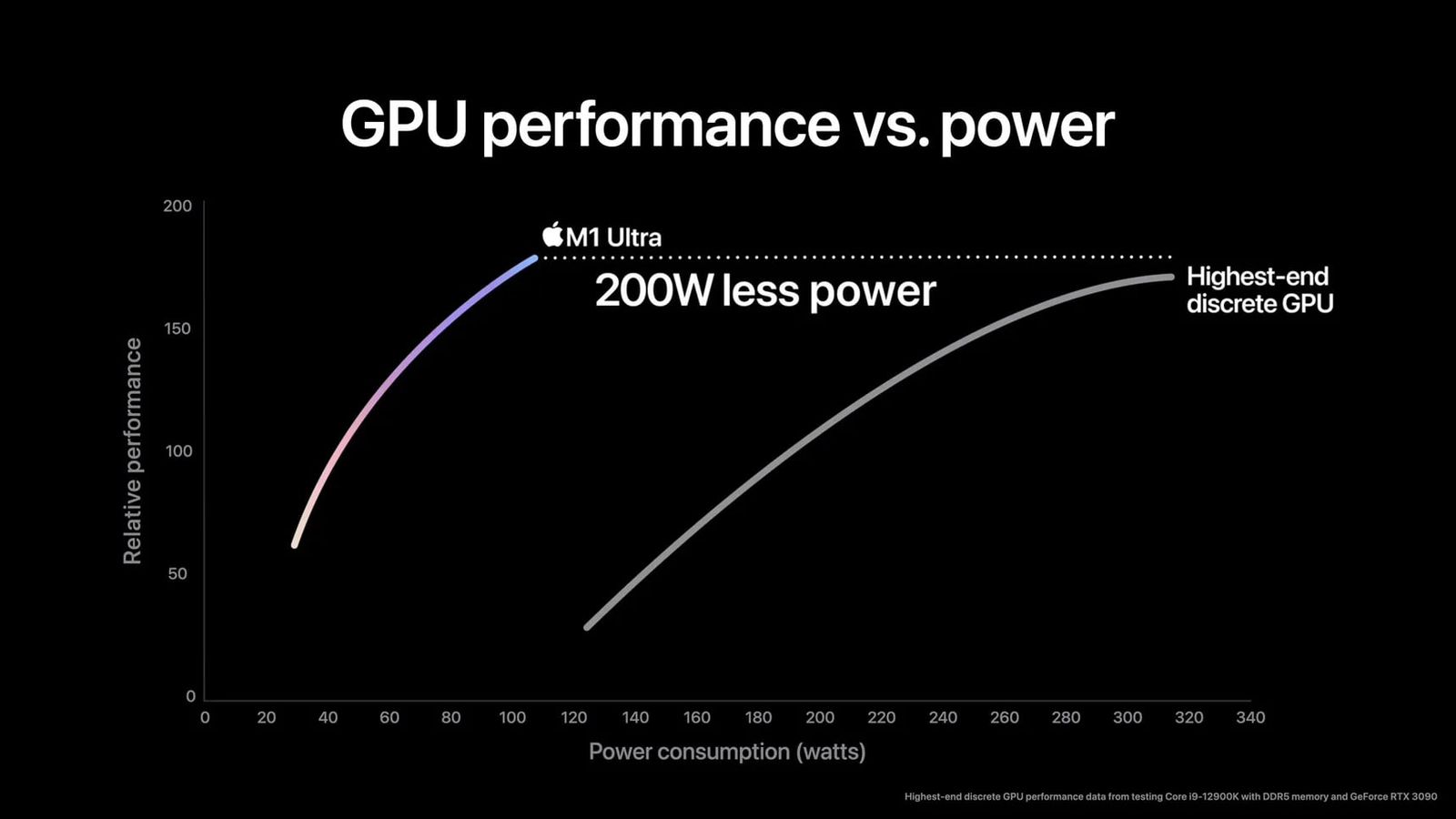{kind=link}
{kind=link}
{kind=link}