
a. start the server:
lms server start --port 1234b. configure environment variables to point CC at LM Studio: export ANTHROPIC_BASE_URL=http://localhost:1234
export ANTHROPIC_AUTH_TOKEN=lmstudioc. start CC pointing at your server:
claude --model openai/gpt-oss-20b/model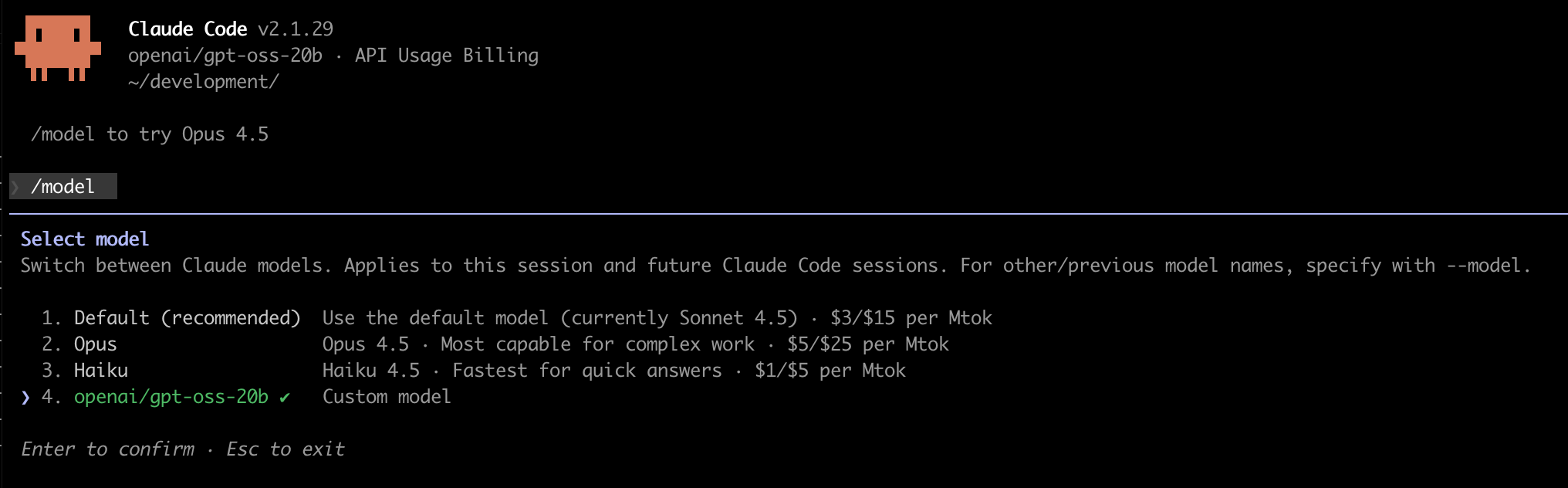
LM Studio is built on top of the open source project llama.cpp.
If you prefer not to use LM Studio, you can install and run the project directly and connect Claude Code to it but honestly, unless you are fine tuning a model, or have really specific needs, probably LM Studio is going to be a quicker setup.
For the moment, this is a backup solution. Unless you have a monster of a machine, you’re going to notice the time it takes to do things and a drop in code quality but it works(!) and it’s easy enough to switch between your local OSS model and Claude when you’re quota limit is back, so it’s a good way to keep coding when you’re stuck or you just want to save some quota. If you try it let me know how you go and which model works for you.
