
Comments
By ElijahLynn 2026-02-1223:3713 reply Wow, I wish we could post pictures to HN. That chip is HUGE!!!!
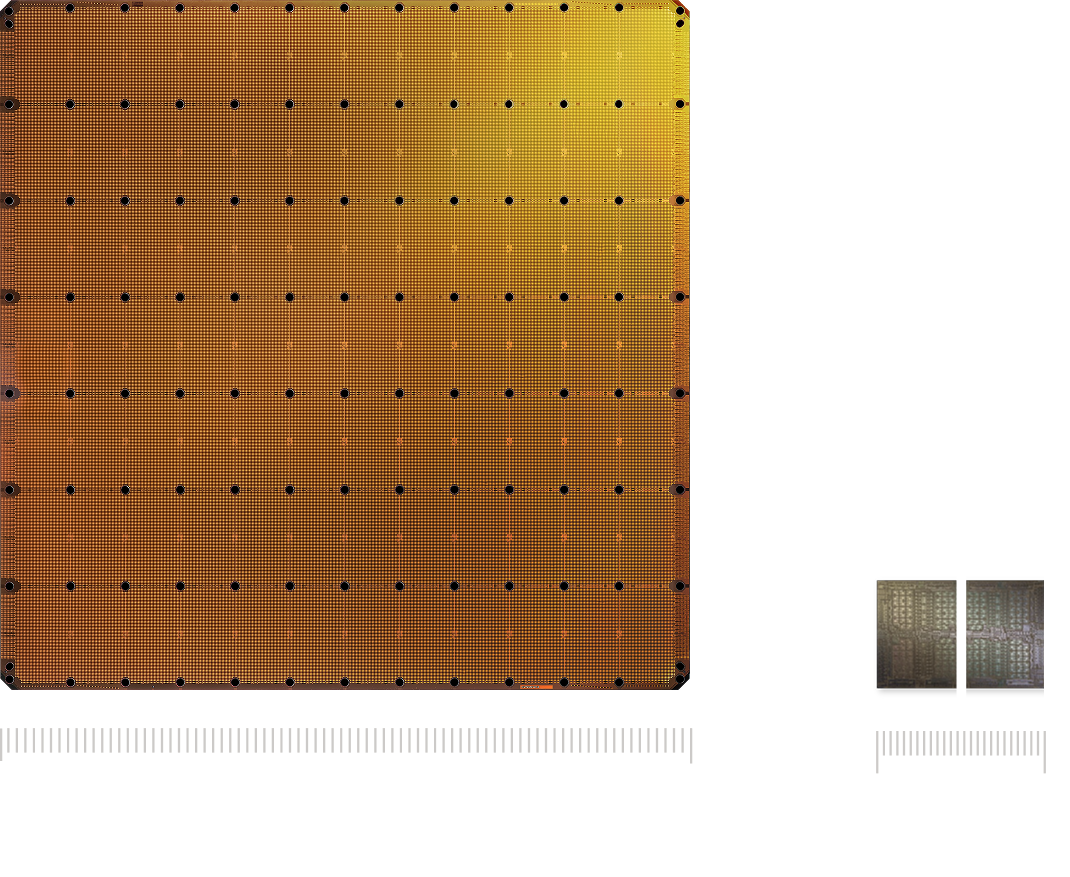
The WSE-3 is the largest AI chip ever built, measuring 46,255 mm² and containing 4 trillion transistors. It delivers 125 petaflops of AI compute through 900,000 AI-optimized cores — 19× more transistors and 28× more compute than the NVIDIA B200.
From https://www.cerebras.ai/chip:
https://cdn.sanity.io/images/e4qjo92p/production/78c94c67be9...
https://cdn.sanity.io/images/e4qjo92p/production/f552d23b565...
By dotancohen 2026-02-135:513 reply
To be clear: that's the thousandths separator, not the Nordic decimal. It's the size of a cat, not the size of a thumbnail.> 46,255 mm²*thousands, not thousandths, right?
The correct number is fourty six thousand, two hundred and fifty five square mm.
This is why space is the only acceptable thousands/grouping separator (a non-breaking space when possible). Avoids any confusion.
Space is also confusing! Then it looks like two separate numbers.
Underscore (_) is already used as a decimal separator in programming languages and Mathematics should just adopt it, IMO.
By awakeasleep 2026-02-1313:492 reply A competing format to simplify things?
A competing format that is understandable to probably everybody.
An ISO 8601 date is also comprehensible to anybody even if they never seen it before and have to figure it out themselves.
Comprehensible?
By ultratalk 2026-02-1315:03
You mean thousands separator, yes? Agreed, it’s annoying when languages don’t have this feature.
By xyproto 2026-02-1616:45 Ah yes, thousands separator.
By wongarsu 2026-02-1315:44 A thin non-breaking space also clears up the confusion without the visual clutter of the underscore. It's just inconvenient to use
By mulmen 2026-02-1319:23 The problem is our primitive text representation online. The formatting should be localized but there’s not a number type I can easily insert inline in a text box.
By fcanesin 2026-02-1312:57 46_255
By shwetanshu21 2026-02-135:571 reply Thanks, I was acutally wondering how would someone even manage to make that big a chip.
By jmalicki 2026-02-1314:56 It's a whole wafer. Basically all chips are made on wafers that big, but normally it's a lot of different chips, you cut the wafer into small chips and throw the bad ones away.
Cerebras has other ways of marking the defects so they don't affect things.
Wow, I'm staggered, thanks for sharing
I was under the impression that often times chip manufacture at the top of the lines failed to be manufactured perfectly to spec and those with say, a core that was a bit under spec or which were missing a core would be down clocked or whatever and sold as the next in line chip.
Is that not a thing anymore? Or would a chip like this maybe be so specialized that you'd use say a generation earners transistor width and thus have more certainty of a successful cast?
Or does a chip this size just naturally ebb around 900,000 cores and that's not always the exact count?
20kwh! Wow! 900,000 cores. 125 teraflops of compute. Very neat
Designing to tolerate the defects is well trodden territory. You just expect some rate of defects and have a way of disabling failing blocks.
By DeathArrow 2026-02-136:552 reply So you shoot for 10% more cores and disable failing cores?
By joha4270 2026-02-137:38 More or less, yes. Of course, defects are not evenly distributed, so you get a lot of chips with different grades of brokenness. Normally the more broken chips gets sold off as lower tier products. A six core CPU is probably an eight core with two broken cores.
Though in this case, it seems [1] that Cerebras just has so many small cores they can expect a fairly consistent level of broken cores and route around them
[1]: https://www.cerebras.ai/blog/100x-defect-tolerance-how-cereb...
Well, it's more like they have 900,000 cores on a WSE and disable whatever ones that don't work.
Seriously, that's literally just what they do.
By fulafel 2026-02-147:52 In their blog post linked in the sibling comment it says the raw number is 970k and they enable 900k (table at the end).
By graboy 2026-02-138:22 IIRC, a lot of design went into making it so that you can disable parts of this chip selectively.
By vagrantstreet 2026-02-137:471 reply Why is the CEO some shady guy? though https://daloopa.com/blog/analyst-pov/cerebras-ipo-red-flags-...
"AI" always has some sleazy person behind it for some reason
By vagrantstreet 2026-02-1317:13 I have "shady CEO that doesn't give back to his country or community" fatigue
By carter2099 2026-02-1513:13 I sent this to someone I know knowledgeable about this type of thing, here’s what he had to say, sharing because I thought it was interesting:
Pretty cool tech, silicon is very advanced. That said, this is how every wafer comes out of the fab. This process does not dice out individual chips but instead adds interonnects. I doubt they have 100% yield, but probably just don't connect that die. This type of setup is one of the reasons Apple's M series chips are so effective. Their CPU/GPU/RAM are all on one die/directly interconnected instead of going through some motherboard based connector. I think Apple doesn't have them all go through the same process so those are connected via a different process but same layed on silicon direct connection. This solves the problem data centers tend to have of tons of latency for the connections between processors. This is also similar to AMD's infinity fabric of their Zen architecture. It's cool how all of these technologies build from another.
It's also all reliant on fab from TSMC who did the heavy lifting is making the process a reality
There have been discussions about this chip here in the past. Maybe not that particular one but previous versions of it. The whole server if I remember correctly eats some 20KWs of power.
A first-gen Oxide Computer rack puts out max 15 kW of power, and they manage to do that with air cooling. The liquid-cooled AI racks being used today for training and inference workloads almost certainly have far higher power output than that.
(Bringing liquid cooling to the racks likely has to be one of the biggest challenges with this whole new HPC/AI datacenter infrastructure, so the fact that an aircooled rack can just sit in mostly any ordinary facility is a non-trivial advantage.)
By mlyle 2026-02-1315:23 > The liquid-cooled AI racks being used today for training and inference workloads almost certainly have far higher power output than that.
75kW is a sane "default baseline" and you can find plenty of deployments at 130kW.
There's talk of pushing to 240kW and beyond...
> Bringing liquid cooling to the racks likely has to be one of the biggest challenges with this whole new HPC/AI
Are you sure about that? HPC has had full rack liquid cooling for a long time now.
The primary challenge with the current generation is the unusual increase of power density in racks. This necessitates upgrades in capacity, notably getting 10-20 kWh of heat away from few Us is generally though but if done can increase density.
By jmalicki 2026-02-1314:58 HPC is also not a normal data center but also usually doesn't have the scale of hyperscaler AI data centers either.
By elcritch 2026-02-138:10 Well for some. Google has been using liquid cooling to racks for decades.
By dyauspitr 2026-02-135:35 That’s wild. That’s like running 15 indoor heaters at the same time.
By fodkodrasz 2026-02-136:32 What do you mean by "per hour"?
Watt is a measure of power, that is a rate: Joule/second, [energy/time]
> The watt (symbol: W) is the unit of power or radiant flux in the International System of Units (SI), equal to 1 joule per second or 1 kg⋅m2⋅s−3.[1][2][3] It is used to quantify the rate of energy transfer.
By ai-christianson 2026-02-132:382 reply If you run it for an hour, yes.
By t0mas88 2026-02-1317:04 You would hope that an EV reporting x kWh/hour considers the charge curve when charging for an hour. Then it makes sense to report that instead of the peak kW rating. But reality is that they just report the peak kW rating as the "kWh/hour" :-(
I asked because that's the average power consumption of an average household in the US per day. So, if that figure is per hour, that's equivalent to one household worth of power consumption per hour...which is a lot.
Others clarified the kW versus kWh, but to re-visit the comparison to a household:
One household uses about 30 kWh per day.
20 kW * 24 = 480 kWh per day for the server.
So you're looking at one server (if parent's 20kW number is accurate - I see other sources saying even 25kW) consuming 16 households worth of energy.
For comparison, a hair dryer uses around 1.5 kW of energy, which is just below the rating for most US home electrical circuits. This is something like 13 hair dryers going on full blast.
At least with GPT-5.3-Codex-Spark, I gather most of the AI inference isn't rendering cat videos but mostly useful work.. so I don't feel tooo bad about 16 households worth of energy.
By wongarsu 2026-02-1316:03 To be fair, this is 16 households of electrical energy. The average household uses about as much electrical energy as it uses energy in form of natural gas (or butane or fuel oil, depending on what they use). And then roughly as much gasoline as they use electricity. So really more like 5 households of energy. And that's just your direct energy use, not accounting for all the products including food consumed in the average household.
By seaal 2026-02-134:46 Which honestly doesn't sound that bad given how many users one server is able to serve.
By jodrellblank 2026-02-132:461 reply Consumption of a house per day is measured in kiloWatt-hours (an amount of power like litres of water), not kiloWatts (a flow of power like 1 litre per second of water).
1 Watt = 1 Joule per second.
By neya 2026-02-133:07 Thanks!
I think you are confusing KW (kilowatt) with KWH (kilowatt hour).
A KW is a unit of power while a KWH is a unit of energy. Power is a measure of energy transferred in an amount of time, which is why you rate an electronic device’s energy usage using power; it consumes energy over time.
In terms of paying for electricity, you care about the total energy consumed, which is why your electric bill is denominated in KWH, which is the amount of energy used if you use one kilowatt of power for one hour.
By ddalex 2026-02-136:41 20 kWh per hour
By hugh-avherald 2026-02-130:573 reply Maybe I'm silly, but why is this relevant to GPT-5.3-Codex-Spark?
By tonyarkles 2026-02-131:00 It’s the chip they’re apparently running the model on.
> Codex-Spark runs on Cerebras’ Wafer Scale Engine 3 (opens in a new window)—a purpose-built AI accelerator for high-speed inference giving Codex a latency-first serving tier. We partnered with Cerebras to add this low-latency path to the same production serving stack as the rest of our fleet, so it works seamlessly across Codex and sets us up to support future models.
By thunderbird120 2026-02-131:01 That's what it's running on. It's optimized for very high throughput using Cerebras' hardware which is uniquely capable of running LLMs at very, very high speeds.
for cerbras, can we call them chips? you're no longer breaking the wafer we should call them slabs
By amelius 2026-02-1311:22 They're still slices of a silicon ingot.
Just like potato chips are slices from a potato.
By colordrops 2026-02-1313:26 Macrochips
By DeathArrow 2026-02-136:533 reply >Wow, I wish we could post pictures to HN. That chip is HUGE!!!!
Using a waffer sized chip doesn't sound great from a cost perspective when compared to using many smaller chips for inference. Yield will be much lower and prices higher.
Nevertheless, the actual price might not be very high if Cerebras doesn't apply an Nvidia level tax.
By energy123 2026-02-137:01 > Yield will be much lower and prices higher.
That's an intentional trade-off in the name of latency. We're going to see a further bifurcation in inference use-cases in the next 12 months. I'm expecting this distinction to become prominent:
(A) Massively parallel (optimize for token/$)
(B) Serial low latency (optimize for token/s).
Users will switch between A and B depending on need.
Examples of (A):
- "Search this 1M line codebase for DRY violations subject to $spec."
An example of (B):
- "Diagnose this one specific bug."
- "Apply this diff".
(B) is used in funnels to unblock (A). (A) is optimized for cost and bandwidth, (B) is optimized for latency.
By magicalhippo 2026-02-137:05 As I understand it the chip consists of a huge number of processing units, with a mesh network between them so to speak, and they can tolerate disabling a number of units by routing around them.
Speed will suffer, but it's not like a stuck pixel on an 8k display rendering the whole panel useless (to consumers).
By Heathcorp 2026-02-137:32 Cerebras addresses this in a blog post: https://www.cerebras.ai/blog/100x-defect-tolerance-how-cereb...
Basically they use very small cores compared to competitors, so faults only affect small areas.
Is this actually beneficial than, say having a bunch of smaller ones communicating on a bus? Apart from space constraints that is.
By zamadatix 2026-02-131:38 It's a single wafer, not a single compute core. A familiar equivalent might be putting 192 cores in a single Epyc CPU (or, more to be more technically accurate, the group of cores in a single CCD) rather than trying to interconnect 192 separate single core CPUs externally with each other.
By santaboom 2026-02-131:38 Yes, bandwidth within a chip is much higher than on a bus.
By txyx303 2026-02-137:23 Those are scribe lines where you usually would cut out chips which is why it resembles multiple chips. However, they work with TSMC to etch across them.
Wooshka.
I hope they've got good heat sinks... and I hope they've plugged into renewable energy feeds...
By thrance 2026-02-131:05 Fresh water and gas turbines, I'm afraid...
By King-Aaron 2026-02-130:282 reply Nope! It's gas turbines
By atonse 2026-02-1315:29 For now. And also largely because it's easier to get that up and running than the alternative.
Eventually, as we ramp up on domestic solar production, (and even if we get rid of solar tariffs for a short period of time maybe?), the numbers will make them switch to renewable energy.
By quaintdev 2026-02-132:53 [flagged]
By xnx 2026-02-1322:55 Bigger != Better
I can imagine how terribly bad their yield must be. One little mistake and the whole "chip" is a goner.
They have a blog post called "100x Defect Tolerance: How Cerebras Solved the Yield Problem":
https://www.cerebras.ai/blog/100x-defect-tolerance-how-cereb...
By svnt 2026-02-1315:35 One thing is really bothering me: they show these tiny cores, but in the wafer comparison image, they chose to show their full chip as a square bounded by the circle of the wafer. Even the prior GPU arch tiled into the arcs of the circle. What gives?
I love this! I use coding agents to generate web-based slide decks where “master slides” are just components, and we already have rules + assets to enforce corporate identity. With content + prompts, it’s straightforward to generate a clean, predefined presentation. What I’d really want on top is an “improv mode”: during the talk, I can branch off based on audience questions or small wording changes, and the system proposes (say) 3 candidate next slides in real time. I pick one, present it, then smoothly merge back into the main deck. Example: if I mention a recent news article / study / paper, it automatically generates a slide that includes a screenshot + a QR code link to the source, then routes me back to the original storyline. With realtime voice + realtime code generation, this could turn the boring old presenter view into something genuinely useful.
I love the probabilistic nature of this. Presentations could be anywhere from extremely impressive to hilariously embarrassing.
By clickety_clack 2026-02-1220:147 reply It would be so cool if it generated live in the presentation and adjusted live as you spoke, so you’d have to react to whatever popped on screen!
By crystal_revenge 2026-02-1221:403 reply There was a pre-LLM version of this called "battledecks" or "PowerPoint Karaoke"[0] where a presenter is given a deck of slides they've never seen and have to present on it. With a group of good public speakers it can be loads of fun (and really impressive the degree that some people can pull it off!)
By bsharper 2026-02-1221:45 There is a Jackbox game called "Talking Points" that's like this: the players come up with random ideas for presentations, your "assistant" (one of the other players) picks what's on each slide while you present: https://www.youtube.com/watch?v=gKnprQpQONw
By hluska 2026-02-130:57 That is very cool. Thanks for posting this - I think I’m going to put on a PowerPoint karaoke night. This will rule! :)
By alfiedotwtf 2026-02-139:12 If you like this, search on YouTube for "Harry Mack". Mindblowing
By Etheryte 2026-02-1220:56 Some consulting firms do this, one guy is giving the presentation live while others are in the next meeting room still banging out the slides.
By dotancohen 2026-02-135:56 That would make a great Wii game.
PowerPoint Hero.
By onionisafruit 2026-02-1220:472 reply Every presentation becomes improv
By DonHopkins 2026-02-1220:56 I had a butterfly take over my live DreamScape slide show demo at the 1995 WWDC.
Isn't that such a great outcome. No more robotic presentations. The best part is that you can now practice Improv at the comfort of your home.
And this product will work great for any industry... can I get a suggestion for an industry from the crowd?
Audience: Transportation... Education... Insurance...
Speaker: Great! I heard "Healthcare".
Right... as we can see from this slide, this product fits the "Healthcare" industry great because of ...
By lelandfe 2026-02-1222:18 Caro’s first LBJ biography tells of how the future president became a congressman in Texas in his 20s, by carting around a “claque” of his friends to various stump speeches and having them ask him softball questions and applauding loudly after
Well, hey, who needs friends?
By nikcub 2026-02-1222:54 and with neuralink it would generate slides of the audience naked
By codyb 2026-02-134:36 I guess you could have two people per presentation, one person who confirms whether to slide in the generated slide or maybe regenerate. And then of course, eventually that's just an agent
You're describing almost verbatim what we're building at Octigen [1]! Happy to provide a demo and/or give you free access to our alpha version already online.
Claude Code is pretty good at making slides already. What’s your differentiator?
By m_mueller 2026-02-135:14 * ability to work with your own PowerPoint native templates; none of the AI slide makers I've seen have any competency in doing that.
* ability to integrate your corporate data.
* repeatable workflows for better control over how your decks look like.
By jorgenveisdal 2026-02-1220:141 reply As an associate professor who spends a ridiculous amount of time preparing for lectures, I would love to try this in one of my courses
By cebert 2026-02-132:25 Try Claude Code too. It’s surprisingly good at this.
By deepGem 2026-02-1221:00 I built something similar at a hackathon, a dynamic teleprompter that adjusts the speed of tele-prompting based on speaker tonality and spoken wpm. I can see extending the same to an improv mode. This is a super cool idea.
By beklein 2026-02-1221:08 The end result would be a normal PPT presentation, check https://sli.dev as an easy start, ask Codex/Claude/... to generate the slides using that framework with data from something.md. The interesting part here is generating these otherwise boring slide decks not with PowerPoint itself but with AI coding agents and a master slides, AGENTS.md context. I’ll be showing this to a small group (normally members only) at IPAI in Heilbronn, Germany on 03/03. If you’re in the area and would like to join, feel free to send me a message I will squeeze you in.
By orochimaaru 2026-02-1219:041 reply How do you handle the diagrams?
In my AGENTS.md file i have a _rule_ that tells the model to use Apache ECharts, the data comes from the prompt and normally .csv/.json files. Prompt would be like: "After slide 3 add a new content slide that shows a bar chart with data from @data/somefile.csv" ... works great and these charts can be even interactive.
By orochimaaru 2026-02-1220:074 reply What about other ad hoc diagrams like systems architecture, roadmaps, mind maps, etc.
These are the bane of any staff engineers life - lol. Because people above need to know a plan in art form.
So seriously interested on how I can make it easier
By mcamac 2026-02-1220:29 You could try something like mermaid (or ASCII) -> nano banana. You can also go the other way and turn images into embedded diagrams (which can be interactive depending on how you're sharing the presentation)
By beklein 2026-02-1220:59 Not my normal use-case, but you can always fall back and ask the AI coding agent to generate the diagram as SVG, for blocky but more complex content like your examples it will work well and still is 100% text based, so the AI coding agents or you manually can fix/adjust any issues. An image generation skill is a valid fallback, but in my opinion it's hard to change details (json style image creation prompts are possible but hard to do right) and you won't see changes nicely in the git history. In your use case you can ask the AI coding agent to run a script.js to get the newest dates for the project from a page/API, then it should only update the dates in the roadmap.svg file on slide x with the new data. This way you will automagically have the newest numbers and can track everything within git in one prompt. Save this as a rule in AGENTS.md and run this every month to update your slides with one prompt.
By sleazebreeze 2026-02-1221:05 Claude code can output Excalidraw format files which can be imported directly into the webapp. You can MCP it too if you want.
By jmalicki 2026-02-1315:02 I have it do svgs.
The layout isn't always great on first shot, but you iterate on that.
They can also natively generate e.g. github markdown mermaid diagrams (github markdown has a lot of extensions like that)
By turnsout 2026-02-1219:09 I love the idea of a living slide deck. This feels like a product that needs to exist!
By postalcoder 2026-02-1220:027 reply First thoughts using gpt-5.3-codex-spark in Codex CLI:
Blazing fast but it definitely has a small model feel.
It's tearing up bluey bench (my personal agent speed benchmark), which is a file system benchmark where I have the agent generate transcripts for untitled episodes of a season of bluey, perform a web search to find the episode descriptions, and then match the transcripts against the descriptions to generate file names and metadata for each episode.
Downsides:
- It has to be prompted to do actions in my media library AGENTS.md that the larger models adhere to without additional prompting.
- It's less careful with how it handles context which means that its actions are less context efficient. Combine that with the smaller context window and I'm seeing frequent compactions.
Bluey Bench* (minus transcription time): Codex CLI gpt-5.3-codex-spark low 20s gpt-5.3-codex-spark medium 41s gpt-5.3-codex-spark xhigh 1m 09s (1 compaction) gpt-5.3-codex low 1m 04s gpt-5.3-codex medium 1m 50s gpt-5.2 low 3m 04s gpt-5.2 medium 5m 20s Claude Code opus-4.6 (no thinking) 1m 04s Antigravity gemini-3-flash 1m 40s gemini-3-pro low 3m 39s *Season 2, 52 episodesBy HumanOstrich 2026-02-136:092 reply Yea it's been butchering relatively easy to moderate tasks for me even with reasoning set to high. I am hoping it's just tuning that needs to be done since they've had to port it to a novel architecture.
If instead the model is performing worse due to how much they had to shrink it just so it will fit on Cerebras hardware, then we might be in for a long wait for the next gen of ginormous chips.
By postalcoder 2026-02-136:551 reply Agree w/ you on the model's tendency to butcher things. Performance wise, this almost feels like the GPT-OSS model.
I need to incorporate "risk of major failure" into bluey bench. Spark is a dangerous model. It doesnt strongly internalize the consequences of the commands that it runs, even on xhigh. As a result I'm observing a high tendency to run destructive commands.
For instance, I asked it to assign random numbers to the filename of the videos in my folder to run the bm. It accidentally deleted the files on most of the runs. The funniest part about it is that it comes back to you within a few seconds and says something like "Whoops, I have to keep it real, I just deleted the files in your folder."
By HumanOstrich 2026-02-137:00 Ouch, at least it fesses up. I ran into problems with it first refusing to use git "because of system-level rules in the session". Then later it randomly amended a commit and force pushed it because it made a dumb mistake. I guess it was embarassed.
> If instead the model is performing worse due to how much they had to shrink it just so it will fit on Cerebras hardware
They really should have just named it "gpt-5.3-codex-mini" (served by Cerebras). It would have made it clear what this model really is.
By HumanOstrich 2026-02-138:211 reply Not if you're suggesting that "(served by Cerebras)" should be part of the name. They're partnering with Cerebras and providing a layer of value. Also, OpenAI is "serving" you the model.
We don't know how they integrate with Cerebras hardware, but typically you'd pay a few million dollars to get the hardware in your own datacenter. So no, "served by Cerebras" is confusing and misleading.
Also "mini" is confusing because it's not analagous to gpt-5.1-codex vs gpt-5.1-codex-mini. Gpt-5.3-codex-spark is a unique, _experimental_ offering that doesn't fit the existing naming suffixes.
I don't understand what's wrong with "spark". It's friendly and evokes a sense of something novel, which is perfect.
If you want to know more about the model, read the first paragraph of the article. That information doesn't need to be hardcoded into the model name indefinitely. I don't see any "gpt-5.3-codex-nvidia" models.
Uh, that paragraph translated from "marketing bullshit" into "engineer" would be "we distilled the big gpt-5.3-codex model into a smaller size that fits on the 44GB of SRAM of a Cerebras WSE-3 multiplied by whatever tensor parallel or layer parallel grouping they're doing".
(Cerebras runs llama-3.3 70b on 4 WSE-3 units with layer parallelism, for example).
That's basically exactly what gpt-5.3-codex-mini would be.
> Also "mini" is confusing because it's not analagous to gpt-5.1-codex vs gpt-5.1-codex-mini.
So perhaps OpenAI intentionally picked the model's layer param count, MoE expert size, etc to fit onto the Cerebras machines. That's like saying "the DVD producer optimized this movie for you" (they just cropped and compressed it down to 4.7GB so it would fit on a DVD). Maybe the typical mini model is 100gb, and they made it 99gb instead or something like that. It's still analogous to gpt-5.3-codex-mini.
I'm underselling it a little bit, because it takes a bit more work than that to get models to run on Cerebras hardware (because they're so weird and un-GPU-like), but honestly if Cerebras can get Llama 3.1 405b or GLM 4.7 running on their own chips, it's not that much harder to have Cerebras get gpt-5.3-codex-mini running.
By HumanOstrich 2026-02-139:361 reply Uh, the combined offering (smaller model + ~800 tps on cerebras) is nothing like the previous mini offerings, and you're hallucinating details about their process of creating it.
Read more about how Cerebras hardware handles clustering. The limit is not 44 GB or 500GB. Each CS-3 has 1,200 TB of MemoryX, supporting up to ~24T parameter models. And up to 2,048 can be clustered.
Yeah, it's pretty clear you're loud mouthed and don't know anything about distilling ML models or anything Cerebras. Distilling ML models into smaller mini versions is basic stuff. How do you think Qwen 3 235b and Qwen 3 30b were made? Or GLM 4.5 355b vs GLM 4.5 Air 105b? Or Meta Llama 4 Maverick and Scout? And everyone knows that the reason Cerebras never served Deepseek R1 or Kimi K2 or any other model bigger than ~500B is because their chips don't have enough memory. People have been begging Cerebras to serve Deepseek forever now, and they never actually managed to do it.
Cerebras doesn't run inference from MemoryX, the same way no other serious inference provider runs inference off of system RAM. MemoryX is connected to the CS-3 over ethernet! It's too slow. MemoryX is only 150GB/sec for the CS-3![1] If you're running inference at 800tokens/sec, with 150GB/sec that means each token can only load 0.18GB of params. For obvious reasons, I don't think OpenAI is using a 0.18B sized model.
The limit is 44GB for each WSE-3. [2] That's how much SRAM a single WSE-3 unit has. For comparison, a Nvidia H100 GPU has 80GB, and a DGX H100 server with 8 GPUs have 640GB of VRAM. Each WSE-3 has 44GB to play around with, and then if you have each one handling a few layers, you can load larger models. That's explicitly what Cerebras says they do: "20B models fit on a single CS-3 while 70B models fit on as few as four systems." [3]
You're reading marketing material drivel about training models that NOBODY uses Cerebras for. Basically nobody uses Cerebras for training, only inference.
[1] https://www.kisacoresearch.com/sites/default/files/documents... "The WSE-2’s 1.2Tb/s of I/O bandwidth is used for [...] transmitting gradients back to the MemoryX service." That quote is about WSE-2/CS-2, but the CS-3 spec lists the same System I/O: 1.2 Tb/s (12×100 GbE).
[2] https://cdn.sanity.io/images/e4qjo92p/production/50dcd45de5a... This really makes it obvious why Cerebras couldn't serve Deepseek R1. Deepseek is 10x larger than a 70b model. Since they don't do tensor parallelism, that means each chip has to wait for the previous one to finish before it can start. So not only is it 10x more memory consumption, it has to load all that sequentially to boot. Cerebras' entire market demands 1000 tokens per second for the much higher price that they charge, so there's no profit in them serving a model which they can only do 500 tokens/sec or something slow like that.
[3] https://www.cerebras.ai/blog/introducing-cerebras-inference-...
By aurareturn 2026-02-1312:13 Yes. In order to serve 1k/s, they must be fitting the entire model on SRAM and not reaching out to off chip RAM. This means they’re likely chaining multiple wafer chips together to serve this model or they shrunk the model to fit one wafer chip. It’s uneconomical for many use cases but for highly valuable tasks, it could be worth it.
This is one area Nvidia chips have not been able to do, ultra fast, ultra high value tasks. Hence, the Grog acquisition.
By HumanOstrich 2026-02-1312:22 Yea, it's pretty clear you're loudmouthed and an aggressively arrogant know-it-all (at least you think). You keep moving the goalposts too. First you're acting like they can't run models that don't fit in 44GB or 4x44GB. Then you say they can "only" run a larger model at 500 tps but that wouldn't be profitable.. Lol
Cerebras CURRENTLY serves GLM-4.7. I've used it through their API. Look up how big it is. 1,000-1,700 tps. https://www.cerebras.ai/blog/glm-4-7
Not interested in further conversation, so have a nice day! You can go ahead and get in the last word though.
By alexdobrenko 2026-02-1221:17 can we plese make the bluey bench the gold standard for all models always
I wonder why they named it so similiarly to the normal codex model while it much worse, while cool of course.
By HumanOstrich 2026-02-136:152 reply Not sure what you mean. It IS the same model, just a smaller version of it. And gpt-5.3-codex is a smaller version of gpt-5.3 trained more on code and agentic tasks.
Their naming has been pretty consistent since gpt-5. For example, gpt-5.1-codex-max > gpt-5.1-codex > gpt-5.1-codex-mini.
By Squarex 2026-02-157:14 what do you mean by the same model, just smaller version? Codex should be finetune of the "normal" version, where did you get it's smaller? It's not that simple as to take some weights from the model and create a new model, normaly the mini or flash models are separately trained based on the data from the larger model.
By swyx 2026-02-1320:29 how are you so sure :)
Can you compare it to Opus 4.6 with thinking disabled? It seems to have very impressive benchmark scores. Could also be pretty fast.
By postalcoder 2026-02-1221:00 Added a thinking-disabled Opus 4.6 timing. It took 1m 4s – coincidentally the same as 5.3-codex-low.
By yojo 2026-02-133:39 I’ve been slow to invest in building flows around parallelizing agent work under the assumption that eventually inference will get fast enough that I will basically always be the bottleneck.
Excited to see glimpses of that future. Context switching sucks and I’d much rather work focused on one task while wielding my coding power tools.
By ttul 2026-02-132:25 I gave it a run on my Astro website project. It definitely makes more mistakes than Codex-5.3, but the speed is something to behold. The text flashes by way faster than I can understand what's going on. And most of its edits worked. I then used Codex-5.3-xhigh to clean things up...
How do the agents perform the transcription? I'm guessing just calling out to other tools like Whisper? Do all models/agents take the same approach or do they differ?
also as a parent, I love the bluey bench concept !
By postalcoder 2026-02-134:29 I am using whisper transcription via the Groq API to transcribe the files in parallel. But (caveat), I cut out the transcription step and had the models operate on a shared transcript folder. So the times you see are pure search and categorization times.
re. your question about the approach – they all took on the problem in different ways that I found fascinating.
Codex Spark was so fast because it noticed that bluey announces the episode names in the episode ("This episode of Bluey is called ____.") so, instead of doing a pure matching of transcript<->web description, it cut out the title names from the transcripts and matched only that with the episode descriptions.
The larger models were more careful and seemed to actually try to doublecheck their work by reading the full transcripts and matching them against descriptions.
gpt-5.2 went through a level of care that wasn't wrong, but was unnecessary.
Sonnet 4.5 (non-thinking) took the most frustrating approach. It tried to automate the pairing process with scripting to match the extracted title with the official title via regex. So, instead of just eyeballing the lists of extracted and official titles to manually match them, it relied purely on the script's logging as its eyes. When the script failed to match all 52 episodes perfectly, it went into a six-iteration loop of writing increasingly convoluted regex until it found 52 matches (which ended up incorrectly matching episodes). It was frustrating behavior, I stopped the loop after four minutes.
In my mind, the "right way" was straightforward but that wasn't borne out by how differently the llms behaved.
By jiggawatts 2026-02-134:26 Most frontier models are multi-modal and can handle audio or video files as input natively.
I'm experimenting right now with an English to Thai subtitle translator that feeds in the existing English subtitles as well as a mono (centre-weighted) audio extracted using ffmpeg. This is needed because Thai has gendered particles -- word choice depends on the sex of the speaker, which is not recorded in English text. The AIs can infer this to a degree, but they do better when given audio so that they can do speaker diarization.

{kind=link}
{kind=link}
{kind=link}