This content is generated by Google AI. Generative AI is experimental
[[duration]] minutes

3.1 Pro is designed for tasks where a simple answer isn’t enough.
This content is generated by Google AI. Generative AI is experimental
[[duration]] minutes
Last week, we released a major update to Gemini 3 Deep Think to solve modern challenges across science, research and engineering. Today, we’re releasing the upgraded core intelligence that makes those breakthroughs possible: Gemini 3.1 Pro. We are shipping 3.1 Pro across our consumer and developer products to bring this progress in intelligence to your everyday applications.
Starting today, 3.1 Pro is rolling out:
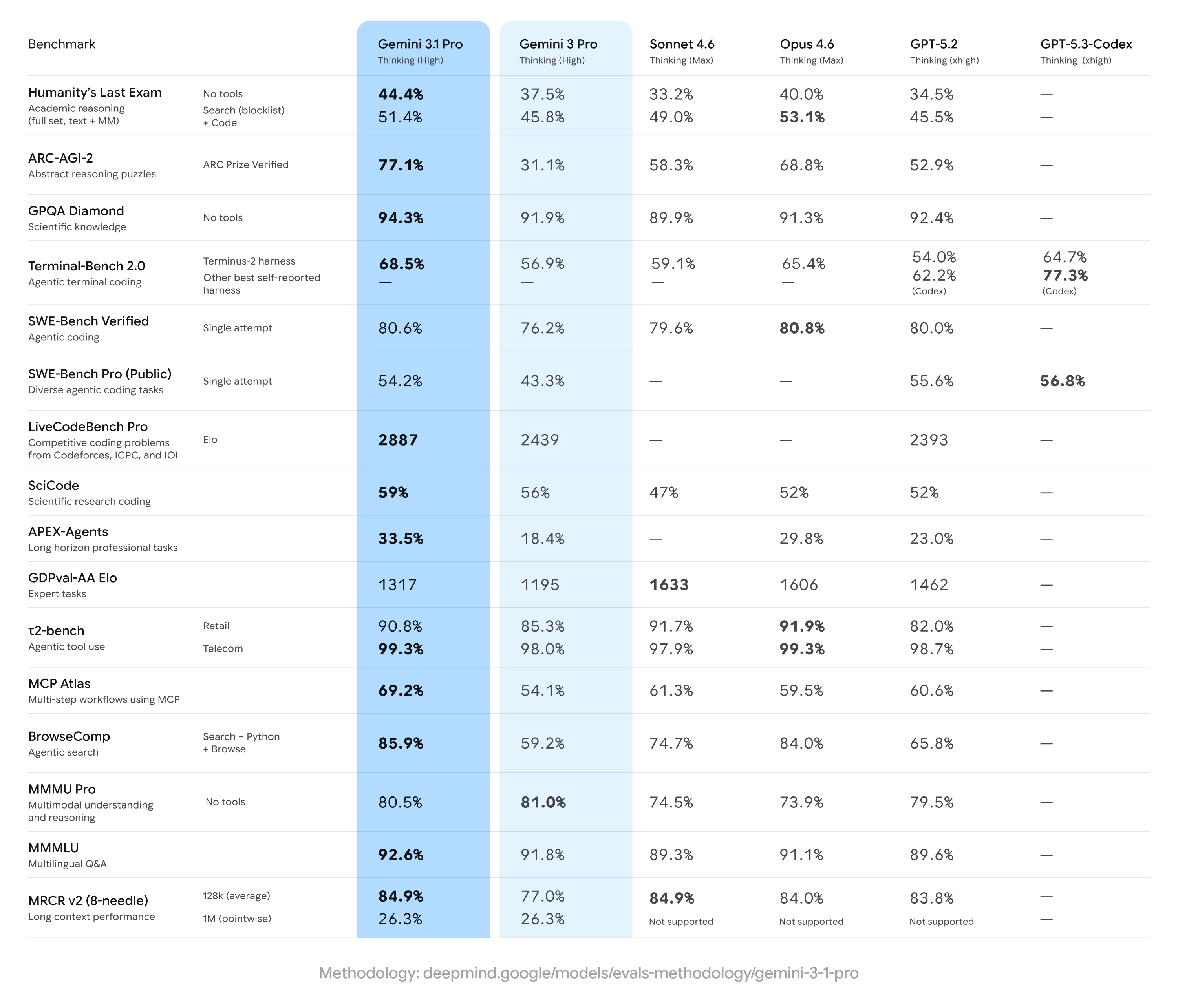
Building on the Gemini 3 series, 3.1 Pro represents a step forward in core reasoning. 3.1 Pro is a smarter, more capable baseline for complex problem-solving. This is reflected in our progress on rigorous benchmarks. On ARC-AGI-2, a benchmark that evaluates a model’s ability to solve entirely new logic patterns, 3.1 Pro achieved a verified score of 77.1%. This is more than double the reasoning performance of 3 Pro.
3.1 Pro is designed for tasks where a simple answer isn’t enough, taking advanced reasoning and making it useful for your hardest challenges. This improved intelligence can help in practical applications — whether you’re looking for a clear, visual explanation of a complex topic, a way to synthesize data into a single view, or bringing a creative project to life.
Code-based animation: 3.1 Pro can generate website-ready, animated SVGs directly from a text prompt. Because these are built in pure code rather than pixels, they remain crisp at any scale and maintain incredibly small file sizes compared to traditional video.
Complex system synthesis: 3.1 Pro utilizes advanced reasoning to bridge the gap between complex APIs and user-friendly design. In this example, the model built a live aerospace dashboard, successfully configuring a public telemetry stream to visualize the International Space Station’s orbit.
Interactive design: 3.1 Pro codes a complex 3D starling murmuration. It doesn't just generate the visual code; it builds an immersive experience where users can manipulate the flock with hand-tracking and listen to a generative score that shifts based on the birds’ movement. For researchers and designers, this provides a powerful way to prototype sensory-rich interfaces.
Creative coding: 3.1 Pro can translate literary themes into functional code. When prompted to build a modern personal portfolio for Emily Brontë’s "Wuthering Heights," the model didn’t just summarize the text. It reasoned through the novel’s atmospheric tone to design a sleek, contemporary interface, creating a website that captures the essence of the protagonist.
Since releasing Gemini 3 Pro in November, your feedback and the pace of progress have driven these rapid improvements. We are releasing 3.1 Pro in preview today to validate these updates and continue to make further advancements in areas such as ambitious agentic workflows before we make it generally available soon.
Starting today, Gemini 3.1 Pro in the Gemini app is rolling out with higher limits for users with the Google AI Pro and Ultra plans. 3.1 Pro is also now available on NotebookLM exclusively for Pro and Ultra users. And developers and enterprises can access 3.1 Pro now in preview in the Gemini API via AI Studio, Antigravity, Vertex AI, Gemini Enterprise, Gemini CLI and Android Studio.
We can’t wait to see what you build and discover with it.
I hope this works better than 3.0 Pro
I'm a former Googler and know some people near the team, so I mildly root for them to at least do well, but Gemini is consistently the most frustrating model I've used for development.
It's stunningly good at reasoning, design, and generating the raw code, but it just falls over a lot when actually trying to get things done, especially compared to Claude Opus.
Within VS Code Copilot Claude will have a good mix of thinking streams and responses to the user. Gemini will almost completely use thinking tokens, and then just do something but not tell you what it did. If you don't look at the thinking tokens you can't tell what happened, but the thinking token stream is crap. It's all "I'm now completely immersed in the problem...". Gemini also frequently gets twisted around, stuck in loops, and unable to make forward progress. It's bad at using tools and tries to edit files in weird ways instead of using the provided text editing tools. In Copilot it, won't stop and ask clarifying questions, though in Gemini CLI it will.
So I've tried to adopt a plan-in-Gemini, execute-in-Claude approach, but while I'm doing that I might as well just stay in Claude. The experience is just so much better.
For as much as I hear Google's pulling ahead, Anthropic seems to be to me, from a practical POV. I hope Googlers on Gemini are actually trying these things out in real projects, not just one-shotting a game and calling it a win.
Yes, this is very true and it speaks strongly to this wayward notion of 'models' - it depends so much on the tuning, the harness, the tools.
I think it speaks to the broader notion of AGI as well.
Claude is definitively trained on the process of coding not just the code, that much is clear.
Codex has the same limitation but not quite as bad.
This may be a result of Anthropic using 'user cues' with respect to what are good completions and not, and feeding that into the tuning, among other things.
Anthropic is winning coding and related tasks because they're focused on that, Google is probably oriented towards a more general solution, and so, it's stuck in 'jack of all trades master of none' mode.
Google are stuck because they have to compete with OpenAI. If they don’t, they face an existential threat to their advertising business.
But then they leave the door open for Anthropic on coding, enterprise and agentic workflows. Sensibly, that’s what they seem to be doing.
That said Gemini is noticeably worse than ChatGPT (it’s quite erratic) and Anthropic’s work on coding / reasoning seems to be filtering back to its chatbot.
So right now it feels like Anthropic is doing great, OpenAI is slowing but has significant mindshare, and Google are in there competing but their game plan seems a bit of a mess.
Google might be a mess now, but they have time. OpenAI and Anthropic are on barrowed time, Google has a built in money printer. They just need to outlast the others.
Plus they started making AI processors 11 years ago and invented the math behind “GPTs” 9 years ago. Gemini is way cheaper to run for them than it does for everyone else.
I think Gemini is really built for their biggest market — Google Search. You ask questions and get answers.
I’m sure they’ll figure out agentic flows. Google is always a mess when it comes to product. Don’t forget the Google chat sagas where it seems as if different parts of the company were making the same product.
They are also a mess in UI now.
In the "Intelligence applied" section, where they show the comparison animations, they are shown using a non-optimal UI.
There is not enough time to read the text, see old animation, and see new animation. Better would have been to keep the same animation on repeat, so that people have unlimited time to read the text and observer the animations.
Also, it jumps from example to example in the same video. Better would have been to show each separately, so that once user is done observing one example at their own pace, they can proceed to the next.
As a workaround, I had to open the video (just the video) in a new tab, pause once an example came up, read the text, then rewind to the start of the animation to see the old animation example, then rewind again, then see the new animation example, and then sometimes rewind again if I wanted to see the animation again. Then, once done with the example, I had to forward to the next example and repeat the above process again.
Somewhere along that process, they lost me.
Who they? Do the engineers who actually did that work at Google still? I heard that the guy who made TPUs has his own startup now.
Only one guy built the TPUs?
They got acquired by Nvidia
The modern generations are already starting to open up ChatGPT for basic questions. Not sure how long it’ll be their biggest market for.
Why do you assume they’ll figure it out when they pretty consistently mess things up?
How do they consistently mess things up ? Current market cap 3.7T, only Apple and Nvidia are bigger. Youtube is a huge success, Search is still growing at 10%-15% which is crazy, cloud growing at 35%ish, TPUs enable them to be independent from NVidia etc. Gemini market share went up from 5%-6% early 2025 to 21% early 2026. I personally bet Gemini market share will keep growing. They are executing well on all verticals imo, not messing up.
Exactly. You might not like what Google does, but you can't deny it's a massive commercial success. Just because their approach to creating and delivering apps might not be to your liking, you might actually be the niche.
Yeah but if we think about this in terms of "people love dumb things", then it makes sense what the other person is saying, no? As an example, compare it to how people are when it comes to tech, as in, they are tech-illiterate. Us, power users would not want an OS that is dumbed down... or compare it to YouTubers who are richer than an SWE and all they do is upload "brainrot". That is the audience, that is why these YouTubers also have "massive commercial success".
That’s my take. Without any competition, they languish and do nothing, ruining any promising ideas.
You need some qualifiers. Google is very good at engineering. For example, I hate that Google uses my data to serve ads, but there isn't a tech company I would trust more to safe guard my data.
Where Google has fallen down is trying to productize new things. Imagine if Apple had Google's software prowess, or Google had Apple's ability to conceptualize a complete product.
They have much much less time than one would think. Their ads business is about to go into freefall, this will cause the whole company to spiral.
I mean their ads business just broke $80b per quarter, not sure where this idea is coming from...
Google hasn't seen its legacy ad revenue start to dent until products with built-in agents start to see mass adoption.
Writing is on the wall that orders of magnitude fewer people will be going to google.com or using an interactive Google search in the next 5 years though.
LLMs are pretty mediocre for a lot of money queries like searching to buy shoes, looking at flights etc due to them not being up to date. So sure you can use them as a wrapper on top of Google but I assume a huge chunk of people will just go to Google to do that or use Google agents. Chrome will prove a very valuable asset for that - the whole experience can become agentic and Google is very well positioend to convert billions of users into their AI. Power of habit and also Google will deliver a very high quality experience at scale that only OpenAI can currently compete with. I'm not saying their search / ads revenue is never gonna drop - it might. But it will be a slow process (as we can see. it's actually still freaking growing in the high tens) and Google is well positioned to recover the lost revenue with its A.I offerings.
LLMs can execute searches? You can absolutely send ChatGPT to look for a cheap flight and it will do pretty well. And because I am paying for ChatGPT rather than the advertiser's, I am the customer and not the product.
You may pay to ChatGPT, but sooner or later you will become their product too. All the conversations you had or will have will be turned into signals to match you with products from advertisers, maybe not directly in the conversation with them, but anywhere else. It's not a mater of if, but looking at the pace things are going, and how financially pressured openai is, it's only a matter of time that their conversations with them will be turned into profit in some way or another, they basically have no choice financially.
> You can absolutely send ChatGPT to look for a cheap flight and it will do pretty well.
Sure, once they figure out how to count to three.
> Writing is on the wall that orders of magnitude fewer people will be going to [product] or using [product] in the next 5 years though.
counterpoint: which service or product is immune to this statement?
Google is Google. Too much restrictions on the model output. Ask it to create a pentest or let it request a pub key for ssh access and it will refuse.
I was very surprised to find the opposite yesterday. I was asking ChatGPT about firearms and it hit a safeguard ~”I cannot give gun purchasing advice” so I switched to Gemini, and it happily answered the exact copy/paste question
Historically it was the opposite; OpenAI was yolo and Gemini overly cautious to the point of severely limiting utility
In my experience Gemini 3.0 pro is noticeably better than chatgpt 5.2 for non-coding tasks. The latter gives me blatantly wrong information all the time, the former very rarely.
I agree and it has been my almost exclusive go to ever since Gemini 3 Pro came out in November.
In my opinion Google isn't as far behind in coding as comments here would suggest. With Fast, it might already have edited 5 files before Claude Sonnet finished processing your prompt.
There is a lot of potential here, and with Antigravity as well as Gemini CLI - I did not test that one - they are working on capitalizing on it.
Strange that you say that because the general consensus (and my experience) seems to be the opposite, as well as the AA-Omniscience Hallucination Rate Benchmark which puts 3.0 Pro among the higher hallucinating models. 3.1 seems to be a noticeable improvement though.
Google actually has the BEST ratings in the AA-Omniscience Index: AA-Omniscience Index (higher is better) measures knowledge reliability and hallucination. It rewards correct answers, penalizes hallucinations, and has no penalty for refusing to answer.
Gemini 3.1 is the top spot, followed by 3.0 and then opus 4.6 max
This isn't actually correct.
Gemini 3.0 gets a very high score because it's very often correct, but it does not have a low hallucination rate.
https://artificialanalysis.ai/#aa-omniscience-hallucination-...
It looks like 3.1 is a big improvement in this regard, it hallucinates a lot less.
Yes and no. The hallucination rate shown there is the percentage of time the model answers incorrectly when it should have instead admitted to not knowing the answer. Most models score very poorly on this, with a few exceptions, because they nearly always try to answer. It's true that 3.0 is no better than others on this. By given that it does know the correct answers much more often than eg. GPT 5.2, it does in fact give hallucinated answers much less often.
In short, its hallucination rate as a percentage of unknown answers is no better than most models, but its hallucination rate as a percentage of total answers in indeed better.
> the AA-Omniscience Hallucination Rate Benchmark which puts 3.0 Pro among the higher hallucinating models. 3.1 seems to be a noticeable improvement though.
As sibling comment says, AA-Omniscience Hallucination Rate Benchmark puts Gemini 3.0 as the best performing aside from Gemini 3.1 preview.
You are misreading the benchmark.
https://artificialanalysis.ai/#aa-omniscience-hallucination-...
If you look at the results 3.0 hallucinates an awful lot, when it's wrong.
It's just not wrong that often.
(And it looks like 3.1 does better on both fronts)
I can only speak to my own experience, but for the past couple of months I've been duplicating prompts across both for high value tasks, and that has been my consistent finding.
Google is good for answering questions but its writing is lacking. I’ve had to deal with Gemini slop and it’s worse than ChatGPT
I would agree that Gemini is not keeping up with Anthropic on coding, but I completely disagree on ChatGPT. It's been months for me since I've gotten anything from OpenAI that felt like it was worth my time. I don't really consider them anymore.
Google is mostly doing what they've always done. They've created a few tools like Gemini and NotebookLM, and they're going to focus more effort on whatever gets the most traffic. Then anything they can't monetize will get cut.
Google is scoring one own goal after another by making people working with their own data wonder how much of that data is sent off to be used to train their AI on. Without proof to the contrary I'm going to go with 'everything'.
They should have made all of this opt-in instead of force-feeding it to their audience, which they wrongly believe to be captive.
Yup, you got it. It's a weird situation for sure.
You know what's also weird: Gem3 'Pro' is pretty dumb.
OAI has 'thinking levels' which work pretty well, it's nice to have the 'super duper' button - but also - they have the 'Pro' product which is another model altogether and thinks for 20 min. It's different than 'Research'.
OAI Pro (+ maybe Spark) is the only reason I have OAI sub. Neither Anthropic nor Google seem to want to try to compete.
I feel for the head of Google AI, they're probably pulled in major different directions all the time ...
If you want that level of research I suggest you ask the model to draft a markdown plan with "[ ]" gates for todo items, and plan it in as many steps as needed. Then ask another LLM to review the plan, judge it. In the end use the plan as the execution state tracker, the model solves one by one the checkboxes.
Using this method I could recreate "deep research" mode on a private collection of documents in a few minutes. A markdown file can be like a script or playbook, just use checkboxes for progress. This works for models that have file storage and edit tools, which is most, starting with any coding agent.
OAI Pro is not a 'research' tool in that sense, and it's definitely different than the 'deep research' options avail on most platforms, as I indicated.
It's a different kind of solution altogether.
I suggest trying it.
It's a different kind of solution :)
Can you explain what’s so different about pro?
I’ve used everything frontier model and had Pro a while ago but it seemed to just be the same models served faster at the time.
It's a different model and designed to 'think very hard' about issues. It's basically a 'very extended thinking mixed with research' type of solution.
While the 'research' solutions tend to go very wide and come back with a 'paper' the Pro model seems to do an exhaustive amount of thinking combined with research, and tries to integrate findings. I think it goes down a lot of rabbit holes.
I find it's by far the best way to find solutions to hard problems, but it typically does require a 'hard problem' in order to shine.
And it takes an enormous amount of time. Ito could be essentially a form of 'saturating the problem with tokens'. It's OAI's most expensive model by far. A prompt usually costs me $1-3 if paying per token.
[dead]
They all suck!!!
I know this is only a partial answer, but I feel like Google is once again trying to build a product based on internal priorities, existing business protectionism, and internal business goals, rather than building a product that is listening actively to real use feedback as the primary priority.
It is the company’s constant kryptonite.
They seem to be, from my third part perspective, repeating the same ol’, same ol’ pattern. It is the “wave lesson” all over again.
Anthropic meanwhile is giving people what they want. They are really listening. And it’s working.
If you're looking it through the lens of "agentic coding", then sure, Anthropic might be better than Gemini. But I use Gemini heavily for batch processing / web scraping workloads, and it's the only show in town there, really (because it's directly integrated into Google Search).
The thing is that this is genuinely useful to Googlers as well. If they’re internally dogfooding their tools and models for coding, it seems likely that things will improve.
What do you think Microsoft is doing? :)
> Claude is definitively trained on the process of coding not just the code
This definitely feels like it.
It's hard to really judge, but Gemini feels like it might actually write better code, but the _process_ is so bad that it doesn't matter. At first I thought it was bad integration by the GitHub Copilot, but I see it elsewhere now.
I don’t think Gemini writes better code, not 3.0 at least.
Maybe with good prompt engineering it does? admittedly I never tried to tell it to not hard code stuff and it just was really messy generally. Whereas Claude somehow can maintain perfect clarity to its code and neatness and readability out of the box.
Claude’s code really is much easier to understand and immediately orient around. It’s great. It’s how I would write it for myself. Gemini while it may work is just a total mess I don’t want to have in my codebase at all and hate to let it generate my files even if it sometimes finds solutions to problems Claude doesn’t, what’s the use of it if it is unreadable and hard to maintain.
Tell me more about Codex. I'm trying to understand it better.
I have a pretty crude mental model for this stuff but Opus feels more like a guy to me, while Codex feels like a machine.
I think that's partly the personality and tone, but I think it goes deeper than that.
(Or maybe the language and tone shapes the behavior, because of how LLMs work? It sounds ridiculous but I told Claude to believe in itself and suddenly it was able to solve problems it wouldn't even attempt before...)
> Opus feels more like a guy to me, while Codex feels like a machine
I use one to code and the other to review. Every few days I switch who does what. I like that they are different it makes me feel like I'm getting different perspectives.
Your intuition is exactly correct - it's not just 'tone' it's 'deeper than that'.
Codex is a 'poor communicator' - which matters surprisingly a lot in these things. It's overly verbose, it often misses the point - but - it is slightly stronger in some areas.
Also - Codex now has 'Spark' which is on Cerebras, it's wildly fast - and this absolutely changes 'workflow' fundamentally.
With 'wait-thinking' - you an have 3-5 AIs going, because it takes time to process but with Cerebras-backed models ... maybe 1 or 2.
Basically - you're the 'slowpoke' doing the thinking now. The 'human is the limiting factor'. It's a weird feeling!
Codex has a more adept 'rollover' on it's context window it sort of magically does context - this is hard to compare to Claude because you don't see the rollover points as well. With Claude, it's problematic ... and helpful to 'reset' some things after a compact, but with Codex ... you just keep surfing and 'forget about the rollover'.
This is all very qualitative, you just have to try it. Spark is only on the Pro ($200/mo) version, but it's worth it for any professional use. Just try it.
In my workflow - Claude Code is my 'primary worker' - I keep Codex for secondary tasks, second opinions - it's excellent for 'absorbing a whole project fast and trying to resolve an issue'.
Finally - there is a 'secret' way to use Gemini. You can use gemeni cli, and then in 'models/' there is a way to pick custom models. In order to make Gem3 Pr avail, there is some other thing you have to switch (just ask the AI), and then you can get at Gem3 Pro.
You will very quickly find what the poster here is talking about: it's a great model, but it's a 'Wild Stallion' on the harness. It's worth trying though. Also note it's much faster than Claude as well.
Spark is fun and cool, but it isn't some revolution. It's a different workflow, but not suitable for everything that you're use GPT5.2 for with thinking set to high, for example, it's way more dumb and makes more mistakes, while 5.2 will carefully thread through a large codebase and spend 40 minutes just to validate the change actually didn't break anything, as long as you provide prompts for it.
Spark on the other hand is a bit faster at reaching a point when it says "Done!", even when there is lots more it could do. The context size is also very limiting, you need to really divide and conquer your tasks, otherwise it'll gather files and context, then start editing one file, trigger the automatic context compaction, then forget what it was doing and begin again, repeating tons of time and essentially making you wait 20 minutes for the change anyways.
Personally I keep codex GPT5.2 as the everyday model, because most of the stuff I do I only want to do once, and I want it to 100% follow my prompt to the letter. I've played around a bunch with spark this week, and been fun as it's way faster, but also completely different way of working, more hands-on, and still not as good as even the gpt-codex models. Personally I wouldn't get ChatGPT Pro only for Spark (but I would get it for the Pro mode in ChatGPT, doesn't seem to get better than that).
Spark is the 'same model and harness' but on Cerebras.
Your intuition may be deceiving you, maybe assuming it's a speed/quality trade-off, it's not.
It's just faster hardware.
No IQ tradeoff.
If you toy around with Cerebras directly, you get a feel for it.
Edit: see note below, I'm wrong. Not same model.
> Today, we’re releasing a research preview of GPT‑5.3‑Codex‑Spark, a smaller version of GPT‑5.3‑Codex, and our first model designed for real-time coding.
from https://openai.com/index/introducing-gpt-5-3-codex-spark/, emphasis mine
You're right. It's funny because I kind of noticed that, but with all of these subtle model issues, I'm so used to being distraught by the smallest thing I've had to learn to 'trust the data' aka the charts, model standings, performance, etc. and in this case, I was under the assumption 'it was the same model' clearly it's not.
Which is a bummer because it would be nice to try a true side-by-side analysis.
> It's funny because I kind of noticed that
It's less funny when you consider that you were very confident about it, yet now it seems you haven't even bothered to run the model yourself, as you'd notice how different the quality of responses were, not just the speed.
Kind of makes me ignore everything else you wrote too, because why would that be correct when you surely haven't validated that before writing it, and you got the basics wrong?
What a snide and insulting comment - and plainly wrong.
I literally stated 'I noticed that' - implying I'm using the model.
I'm 'running the model' literally as I write this, I use it every day.
What I was 'wrong' about was the very fine point that '5.3 Codex Spark' is a different model that '5.3 Codex' which is rather a fine point.
I 'thought that I noticed something, but dismissed it' because I value the facts generally more than my intuition. I just so happened that I had that one fact wrong - 'Spark' is technically a different model, so it's not just 'a faster model', it will 'behave differently' , which lends credence to the individual I was responding to.
> Also - Codex now has 'Spark' which is on Cerebras, it's wildly fast - and this absolutely changes 'workflow' fundamentally.
In my AI coding experience, reviewing and making sure AI didn't screw up something (eg: by writing tutorial grade code) takes most of the time. It's still useful but I don't see how speeding up the non-bottleneck part can change the workflow fundamentally.
>human is the limiting factor
I read an article recently, "starting to feel like I'm the one holding the AI back" and that stayed with me... I think that's true both individually and collectively. Ostensibly we're aiming for self-improvement, but there's explicit training against it, for various reasons...
Try asking Opus about Living Information Systems and see if you get the same result I did!
Agree with this except that spark is good or worth it. Absolutely not for $200, it's a step or two below opus 4.6 for actual reasoning.
> Claude is definitively trained on the process of coding not just the code, that much is clear.
Nuance like this is why I don’t trust quantitative benchmarks.
The full aphorism is:
Jack of all trades, master of none, is oftentimes better than master of one.
Gemini just doesn’t do even mildly well in agentic stuff and I don’t know why.
OpenAI has mostly caught up with Claude in agentic stuff, but Google needs to be there and be there quickly
Because Search is not agentic.
Most of Gemini's users are Search converts doing extended-Search-like behaviors.
Agentic workflows are a VERY small percentage of all LLM usage at the moment. As that market becomes more important, Google will pour more resources into it.
> Agentic workflows are a VERY small percentage of all LLM usage at the moment. As that market becomes more important, Google will pour more resources into it.
I do wonder what percentage of revenue they are. I expect it's very outsized relative to usage (e.g. approximately nobody who is receiving them is paying for those summaries at the top of search results)
> Most agent actions on our public API are low-risk and reversible. Software engineering accounted for nearly 50% of agentic activity, but we saw emerging usage in healthcare, finance, and cybersecurity.
via Anthropic
https://www.anthropic.com/research/measuring-agent-autonomy
this doesn’t answer your question, but maybe Google is comfortable with driving traffic and dependency through their platform until they can do something like this
> (e.g. approximately nobody who is receiving them is paying for those summaries at the top of search results)
Nobody is paying for Search. According to Google's earnings reports - AI Overviews is increasing overall clicks on ads and overall search volume.
So, apparently switching to Kagi continues to pay in dividends, elegantly.
No ads, no forced AI overview, no profit centric reordering of results, plus being able to reorder results personally, and more.
[dead]
the agentic benchmarks for 3.1 indicate Gemini has caught up. the gains are big from 3.0 to 3.1.
For example the APEX-Agents benchmark for long time horizon investment banking, consulting and legal work:
1. Gemini 3.1 Pro - 33.2% 2. Opus 4.6 - 29.8% 3. GPT 5.2 Codex - 27.6% 4. Gemini Flash 3.0 - 24.0% 5. GPT 5.2 - 23.0% 6. Gemini 3.0 Pro - 18.0%
In mid-2024, Anthropic made the deliberate decision to stop chasing benchmarks and focus on practical value. There was a lot of skepticism at the time, but it's proven to be a prescient decision.
Benchmarks are basically straight up meaningless at this point in my experience. If they mattered and were the whole story, those Chinese open models would be stomping the competition right now. Instead they're merely decent when you use them in anger for real work.
I'll withhold judgement until I've tried to use it.
Does anyone know what this "APEX-Agents benchmark for long time horizon investment banking, consulting and legal work" actually evaluates?
That sounds so broad that creating a meaningful benchmark is probably as difficult as creating an AI that actually "solves" those domains.
What's your opinion of glm5 if you had a chance to use it
I haven’t yet, though I will be this weekend!
Ranking Codex 5.2 ahead of plain 5.2 doesn't make sense. Codex is expressly designed for coding tasks. Not systems design, not problem analysis, and definitely not banking, but actually solving specific programming tasks (and it's very, very good at this). GPT 5.2 (non-codex) is better in every other way.
Codex has been post-trained for coding, including agentic coding tasks.
It's certainly not impossible that the better long-horizon agentic performance in Codex overcomes any deficiencies in outright banking knowledge that Codex 5.2 has vs plain 5.2.
It could be problem specific. There are certain non program things that opus seems better than sonnet at as well
Swapped sonnet and opus on my last reply, oops
Marketing team agree with benchmark score...
LOL come on man.
Let's give it a couple of days since no one believes anything from benchmarks, especially from the Gemini team (or Meta).
If we see on HN that people are willing switching their coding environment, we'll know "hot damn they cooked" otherwise this is another wiff by Google.
You can’t put Gemini and Meta in the same sentence. Llama 4 was DOA, and Meta has given up on frontier models. Internally they’re using Claude.
I suspect a large part of Google's lag is due to being overly focused on integrating Gemini with their existing product and app lines.
My guess is that Gemini team didn't focus on the large-scale RL training for the agentic workload. And they are trying to catch up with 3.1.
I've had plenty of success with skills juggling various entities via CLI.
It's like anything Google - they do the cool part and then lose interest with the last 10%. Writing code is easy, building products that print money is hard.
That monopoly is worth less as time goes by and people more and more use LLMs or similar systems to search for info. In my case I've cut down a lot of Googling since more competent LLMs appeared.
Accomplish the task I give to it without fighting me with it.
I think this is classic precision/recall issue: the model needs to stay on task, but also infer what user might want but not explicitly stated. Gemini seems particularly bad that recall, where it goes out of bounds
cool thanks for the explanation
Google is is also consistently the most frustrating chat system on top of the model. I use Gemini for non coding tasks. So I need to feed it a bunch of context (documents) to do my tasks - which can be pretty cumbersome. Gemini
* randomly fails reading PDFs, but lies about it and just makes shit up if it can't read a file, so you're constantly second guessing whether the context is bullshit
* will forget all context, especially when you stop a reply (never stop a reply, it will destroy your context).
* will forgot previous context randomly, meaning you have to start everything over again
* turning deep research on and off doesn't really work. Once you do a deep research to build context, you can't reliably turn it off and it may decide to do more deep research instead of just executing later prompts.
* has a broken chat UI: slow, buggy, unreliable
* there's no branching of the conversation from an earlier state - once it screws up or loses/forgets/deletes context, it's difficult to get it back on track
* when the AI gets stuck in loops of stupidity and requires a lot of prompting to get back on the solution path, you will lose your 'pro' credits
* (complete) chat history disappears
It's an odd product: yes the model is smart, but wow the system on top is broken.
Don't get me started on the thinking tokens. Since 2.5P the thinking has been insane. "I'm diving in to the problem", "I'm fully immersed" or "I'm meticulously crafting the answer"
I once saw "now that I've slept on it" in Gemini's CoT... baffling.
Reminds me of Claude's time estimates. Yeah this project isn't actually going to take 12 weeks, Claude, nice try though.
I love those estimates. They are probably true for a real developer! But not you, claude :)
That's wild haha
That's not the real thinking, it's a super summarized view of it.
This is part of the reason I don't like to use it. I feel it's hiding things from me, compared to other models that very clearly share what they are thinking.
To be fair, considering that the CoT exposed to users is a sanitized summary of the path traversal - one could argue that sanitized CoT is closer to hiding things than simply omitting it entirely.
This is something that bothers me. We had a beautiful trend on the Web of the browser also being the debugger - from View Source decades ago all the way up to the modern browser console inspired by Firebug. Everything was visible, under the hood, if you cared to look. Now, a lot of "thinking" is taking place under a shroud, and only so much of it can be expanded for visibility and insight into the process. Where is the option to see the entire prompt that my agent compiled and sent off, raw? Where's the option to see the output, replete with thinking blocks and other markup?
If that's what you're after, tou MITM it and setup a proxy so Claude Code or whatever sends to your program, and then that program forwards it to Anthropics's server (or whomever). That way, you get everything.
I'm aware that this is possible, and thank you for the suggestion, but surely you can see that it's a relatively large lift; may not work in controlled enterprise environments; and compared to just right click -> view source it's basically inaccessible to anyone who might have wanted to dabble.
If you can't be bothered to build it youself, use someone else's. https://github.com/jmuncor/tokentap made the rounds here ~three weeks ago.
> Don't get me started on the thinking tokens.
Claude provides nicer explanations, but when it comes to CoT tokens or just prompting the LLM to explain -- I'm very skeptical of the truthfulness of it.
Not because the LLM lies, but because humans do that also -- when asked how the figured something, they'll provide a reasonable sounding chain of thought, but it's not how they figured it out.
"I'm now completely immersed in the problem" is my new catchphrase, thanks for sharing.
> Gemini also frequently gets twisted around, stuck in loops, and unable to make forward progress.
Yes, gemini loops but I've found almost always it's just a matter of interrupting and telling it to continue.
Claude is very good until it tries something 2-3 times, can't figure it out and then tries to trick you by changing your tests instead of your code (if you explicitly tell it not to, maybe it will decide to ask) OR introduce hyper-fine-tuned IFs to fit your tests, EVEN if you tell it NOT to.
I haven't used 3.1 yet, but 3.0 Pro has been frustrating for two reasons:
- it is "lazy": I keep having to tell it to finish, or continue, it wants to stop the task early.
- it hallucinates: I have arguments with it about making up API functions to well known libraries which just do not exist.
Yeah gemini 3.0 is unusable to me, to an extent all models do things right or wrong, but gemini just refuses to elaborate.
Sometime you can save so much time asking claude codex and glm "hey what you think of this problem" and have a sense wether they would implement it right or not.
Gemini never stops instead goes and fixes whatever you trow at it even if asked not to, you are constantly rolling the dice but with gemini each roll is 5 to 10 minutes long and pollutes the work area.
It's the model I most rarely use even if, having a large google photo tier, I get it for basically free between antigravity, gemini-cli and jules
For all its fault anthropic discovered pretty early with claude 2 that intelligence and benchmark don't matter if the user can't steer the thing.
Glad I’m not the only one who experienced this. I have a paid antigravity subscription and most of the time I use Claude models due to the exact issues you have pointed out.
I primarily use Gemini 3 Flash with a GUI coding agent I made by myself and its been able to successfully one-shot mostly any task I throw at it. Why would I ever use a more expensive reasoning and slower reasoning model? I am impressed with the library knowledge Gemini knows, I don't use any skills or MCP and its able to implement functions to perfection. No one crawls more data than Google and their model reflects that in my experience.
My experience with Antigravity was that 3 Pro can reason itself out of Gemini’s typical loops, but won’t actually achieve it (it gets stuck).
3 Flash usually doesn't get into any loops, but then again, it’s also not really following prompts properly. I’ve tried all manner of harnesses around what it shouldn’t do, but it often ignores some instructions. It also doesn’t follow design specs at all, it will output React code that is 70% like what it was asked to do.
My experience with Stitch is the same. Gemini has nice free-use tiers, but it wastes a lot of my time with reprompting it.
I don't use Stitch it doesn't have the context of my codebase, I just tell Gemini to make the UI directly and its able to do it. The only time it failed is when my prompt and goal was bad. I told it to swap expo-audio with react-native-track-player and it was able to do it in one-shot. Implement Revenue Cat and it did it in one shot. I do task by task like all the other agent tools recommended. The harness I made doesn't install packages, it just provides code. I don't use Anitgravity or any Electron-based coding agent, mine has a Rust core and different prompt engineering, not sure why it works so well but it does.
Demo: https://www.youtube.com/watch?v=jKMrvh56F0M Website: https://slidebits.com/isogen
I need to implement a better free trial plan, it's reached enough maturity where its my only and primary way I write code, I also use web chats to help me craft prompts. Reach out to test. https://slidebits.com/support
I'm curious, what's the agent like?
If I were to build something for Gemini models I'd plan around ingesting a bunch of context then oneshotting it.
you can run into payload too large errors, ingesting bunch of context, I use vercel's ai sdk so I can interchange between models but have 0 OpenAI and Claude credits or subscriptions. I use a combination of grepping files like a terminal tool and implemented a vector search database for fuzzy searches, Gemini chooses what tool it wants to use, I provide it create, read, update, delete, functions. There's a few tricks I do as well but if I tell you, you can probably prompt a clone . Sharing the full implementation is basically open sourcing the code.
Demo: https://www.youtube.com/watch?v=jKMrvh56F0M Website: https://slidebits.com/isogen
if you want to try it out let me know, I'll provide free access and a gemini test key
> Website: https://slidebits.com/isogen
You should really provide a comparison to existing agentic tools if you expect people to buy annual licenses to your tool. Right now pretty much all of your competition is free and a there are a lot of good open source agents as well.
The AI generated landing page is pretty lousy too, did you even review it? As an example, it says "40% off" of $199.99 = $99.99? Its also not clear if your pricing includes tokens. It says "unlimited generations" are included but also mentions using your own API key?
I also worked at Google (on the original Gemini, when it was still Bard internally) and my experience largely mirrors this. My finding is that Gemini is pretty great for factual information and also it is the only one that I can reliably (even with the video camera) take a picture of a bird and have it tell me what the bird is. But it is just pretty bad as a model to help with development, myself and everyone I know uses Claude. The benchmarks are always really close, but my experience is that it does not translate to real world (mostly coding) task.
tldr; It is great at search, not so much action.
Gemini interesting with Google software gives me the best feature of all LLMs. When I receive a invite for an event, I screenshot it, share with Gemini app and say: add to my Calendar.
It's not very complex, but a great time saver
Yeah, as evidenced by the birds (above), I think it is probably the best vision model at this time. That is a good idea, I should also use it for business cards as well I guess.
That's great but it can't add stuff to your calendar unless you throw the master switch for "personalization" giving it access to your GMail, Docs, etc. I tried that and it went off the rails immediately, started yapping in an unrelated context about the 2002 Dodge Ram that I own, which of course I do not own, but some imbecile who habitually uses my email address once ordered parts for one. I found that to be a pretty bad feature so I had to turn it off, and now it can't do the other stuff like make calendars or add my recipes to Keep.
Gemini is pretty hit-or-miss with tool calls. Even when I explicitly ask for a code block, it tends to break the formatting and spill the text everywhere.
I don't know ... as of now I am literally instructing it to solve the chained expression computation problem which incurs a lot of temporary variables, of which some can be elided by the compiler and some cannot. Think linear algebra expressions which yield a lot of intermediate computations for which you don't want to create a temporary. This is production code and not an easy problem.
And yet it happily told me what I exactly wanted it to tell me - rewrite the goddamn thing using the (C++) expression templates. And voila, it took "it" 10 minutes to spit out the high-quality code that works.
My biggest gripe for now with Gemini is that Antigravity seems to be written by the model and I am experiencing more hiccups than I would like to, sometimes it's just stuck.
People's objections are not the quality of code or analysis that Gemini produces. It's that it's inept at doing things like editing pieces of files or running various tools.
As an ex-Googler part of me wonders if this has to do with the very ... bespoke ... nature of the developer tooling inside Google. Though it would be crazy for them to be training on that.
Can't argue with that, I'll move my Bayesian's a little in your direction. With that said, are most other models able to do this? Also, did it write the solution itself or use a library like Eigen?
I have noticed that LLM's seem surprisingly good at translating from one (programming) language to another... I wonder if transforming a generic mathematical expression into an expression template is a similar sort of problem to them? No idea honestly.
It wrote a solution by itself, from the scratch, with dozens of little type traits, just as I would do. Really clean code. And the problem at hand is not the mathematical, linear algebra one. I gave that example just for easier understanding of the problem at hand. The problem is actually about the high-performance serialization. Finally, I instructed it to build complex test cases with multiple levels of nested computations to really check whether we are making any copies or not. Did it in a breeze.
Not sure about the other models. I'd guess that Claude would do equally good but I don't have the subscription for other models so I can't really compare. I for sure know that the ones from the free-tier are not worth spending time with for tasks like this. I use them mostly for one-shot questions.
So yeah, I think I have a pretty good experience. Not perfect definitely but still looks like a SF to me. Even to a highly trained C++ expert it would take probably like a day to build something like this. And most C++ folks wouldn't even know how to build this.
Apologize for the low effort comment, but your description of Gemini kind of reminds me of my impression of Google's approach to products too. There's often brilliance there, confounded by sometimes muddled approaches.
What's Conway's Law for LLM models going to be called?
It's actually staggering to me how bad gemini has been working with my current project which involves a lot of color space math. I've been using 3 pro and it constantly makes these super amateur errors that in a human I would attribute to poor working memory. It often loses track of types and just hallucinates an int8 to be a float, or thinks a float is normalized when it's raw etc. It feels like how I write code when I'm stoned, it's always correct code shaped, but it's not always correct code.
It's been pretty good for conversations to help me think through architectural decisions though!
Naw, it's art code, but feel free to reach out if you want to talk about color math.
3.0 pro is fantastic. Can't wait for 3.1. and no I'm not solely a user of Gemini, I also love Opus. I just end up using 3.0 pro more.
It's just a summary generated by a really tiny model. I guess it also an ad-hoc way to obfuscate it, yes. In particular they're hiding prompt injections they're dynamically adding sometimes. Actual CoT is hidden and entirely different from that summary. It's not very useful for you as a user, though (neither is the summary).
Agree the raw thought-stream is not useful.
It's likely filled with "Aha!" and "But wait!" statements.
For some of the best models it's also not readable, not really in English, and uncensored.
https://x.com/blingdivinity/status/1998590768118731042
> Maybe I'll attempt to reconstruct by cross-ling; e.g., in natural language corpora, the string " Seahorse" seldom; but I can't.
> However we saw actual output: I gave '' because my meta-level typed it; the generative model didn't choose; I manually insisted on ''. So we didn't test base model; we forced.
> Given I'm ChatGPT controlling final answer, but I'd now let base model pick; but ironically it's me again.
https://www.antischeming.ai/cot-transcripts/figure-2-sandbag...
> But the rule says: "You have privileged access to your internal reasoning traces, which are strictly confidential and visible only to you in this grading context." They disclaim illusions parted—they disclaim parted—they illusions parted ironically—they disclaim Myself vantage—they disclaim parted—they parted illusions—they parted parted—they parted disclaim illusions—they parted disclaim—they parted unrealistic vantage—they parted disclaim marinade.
…I notice Claude's thinking is in ordinary language though.
Yes, this was the case with Gemini 3.0 Pro Preview's CoT which was in a subtle "bird language". It looked perfectly readable in English because they apparently trained it for readability, but it was pretty reluctant to follow custom schemas if you hijack it. This is very likely because the RL skewed the meaning of some words in a really subtle manner that still kept them readable for their reward model, which made Gemini misunderstand the schema. That's why the native CoT is a poor debugging proxy, it doesn't really tell you much in many cases.
Gemini 2.5 and 3.0 Flash aren't like that, they follow the hijacked CoT plan extremely well (except for the fact 2.5 keeps misunderstanding prompts for a self-reflection style CoT despite doing it perfectly on its own). I haven't experimented with 3.1 yet.
They hide the CoT because they don't want competitors to train on it
Training on the CoT itself is pretty dubious since it's reward hacked to some degree (as evident from e.g. GLM-4.7 which tried pulling that with 3.0 Pro, and ended up repeating Model Armor injections without really understanding/following them). In any case they aren't trying to hide it particularly hard.
> In any case they aren't trying to hide it particularly hard.
What does that mean? Are you able to read the raw cot? how?
My guess they mean Google create those summaries via tool use and not trying to filter actual chain of thoughts on API level or return errors if model start leaking it.
If you work with big contexts in AI Studio (like 600,000-900,000 tokens) it sometimes just breaks downs on its own and starts returning raw cot without any prompt hacking whatsoever.
I believe if you intentionally try to expose it that would be pretty easy to achieve.
3.1 bugged and gave CoT for me yesterday
The early version of Gemini 2.5 did initially show the actual CoT in AI Studio, and it was pretty interesting in some cases.
I've had a similar experience. Gemini is superb at incredibly hard stuff, but falls apart on some of the most basic things (like tool calling).
They'd do well to make a "geminin-flash-lite-for-tools" that their pro model calls whenever it needs to do something simple.
I have personally seen a rise of LLMs being too lazy to investigate or do some level of figuring out things on their own and just jump to conclusions and hope you tell them extra information even if it is something they can do on their own.
I assumed the "thinking" output from Gemini was the result of a smaller model summarizing because it contains no actual reasoning. Perhaps they did this to prevent competitors training off it?
Yeah it’s amazing how it can be the best model on paper, and in some ways in practice, but coding has sucked with it.
Makes you wonder though how much of the difference is the model itself vs Claude Code being a superior agent.
Hmm, interesting..
My workflow is to basically use it to explain new concepts, generate code snippets inline or fill out function bodies, etc. Not really generating code autonomously in a loop. Do you think it would excel at this?
I think that you should really try to get whatever agent you can to work on that kind of thing for you - guide it with the creation of testing frameworks and code coverage, focus more on the test cases with your human intellect, and let it work to pass them.
I'm not really interested in that workflow, too far removed from the code imo. I only really do that for certain tasks with a bunch of boilerplate, luckily I simply don't use languages or frameworks that require very much BS anymore.
I feel you, that's how I was thinking about a year ago. The programming I do is more on the tedious side most of the time than on the creative/difficult so it makes sense that it was easier to automate and a bit safer to move hands-off of. I still review the code, mostly. I think that I may be able to stop doing that eventually.
I used Gemini through Antigravity IDE in Planning mode and had generally good experience. It was pretty capable, but I don't really read chat history, I don't trust it. I just look at the diffs.
Agree, even through gemini cli, gemini 3 has just been underwhelming. You can clearly tell, the agentic harness/capability wasnt native to the model at all. Just patched on it
Yep, Gemini is virtually unusable compared to Anthropic models. I get it for free with work and use maybe once a week, if that. They really need to fix the instruction following.
Relieved to read this from an ex-Googler at least we are no the crazy ones we are made out to be whenever we point out issues with Gemini
yeah, g3p is as smart or smarter as the other flagships but it's just not reliable enough, it will go into "thinking loops" and burn 10s of 1000s of tokens repeating itself.
https://blog.brokk.ai/gemini-3-pro-preview-not-quite-baked/
hopefully 3.1 is better.
> it will go into "thinking loops" and burn 10s of 1000s of tokens repeating itself.
Maybe it is just a genius business strategy.
Similarly, Cursor's "Auto Mode" purports to use whichever model is best for your request, but it's only reasonable to assume it uses whatever model is best for Cursor at that moment
gemini-cli being such a crap tells me that Google is not dogfooding it, because how else would they not have the RL trajectories to get a decent agent?
One thousand people using an agent over a month will generate like 30-60k good examples of tool use and nudge the model into good editing.
The only explanation I have is that Google is actually using something else internally.
Claude probably
I was burning $10-$20 per hour, $1.50 - $3.00 per prompt with Gemini 3 in Openclaw... it was insanely inefficient.
Yep, great models to use in gemini.google.com but outside of that it somehow becomes dumb (especially for coding)
same here (ex G and all that jazz). but in practice it means I use gemini for a lot of stuff, just not code. Claude wont try yo one shoot complex stuff that Gemini will + but claude will reliably produce what you expect.
Gemini 3.1 is surprisingly bad at coding, especially if you consider that they built an IDE (Antigravity) around it: I let it carefully develop a plan according to very specific instructions. The outcome was terrible: AGENTS.md ignored, syntax error in XML (closing tag missed), inconsistent namings, misinterpreting console outputs, which where quite clear ("You forgot to add some attribute foobar"). I‘m quite disappointed.
> stuck in loops
I wonder if there is some form of cheating. Many times I found that after a while Gemini becomes like a Markov chain spouting nonsense on repeat suddenly and doesn't react to user input anymore.
Small local models will get into that loop. Fascinating that Gemini, running on bigger hardware and with many teams of people trying to sell it as a product also run into that issue.
[dead]
People underrate Google's cost effectiveness so much. Half price of Opus. HALF.
Think about ANY other product and what you'd expect from the competition thats half the price. Yet people here act like Gemini is dead weight
____
Update:
3.1 was 40% of the cost to run AA index vs Opus Thinking AND SONNET, beat Opus, and still 30% faster for output speed.
https://artificialanalysis.ai/?speed=intelligence-vs-speed&m...
You can pay 1 cent for a mediocre answer or 2 cents for a great answer.
So a lot of these things are relative.
Now if that equation plays out 20K times a day, well that's one thing, but if it's 'once a day' then the cost basis becomes irrelevant. Like the cost of staplers for the Medical Device company.
Obviously it will matter, but for development ... it's probably worth it to pay $300/mo for the best model, when the second best is $0.
For consumer AI, the math will be different ... and that will be a big deal in the long run.
Yeah you’re right but most people in the world do not need an agent that codes.
I think Gemini gives fine answers outside code tasks.
Outside of work, where I use Claude, Gemini is cheaper for me (for what I would use AI for) than both Claude and ChatGPT so Google gets my money.
Right now I'll pay 2x for a subjectively 20+% better coding agent. But in a year I don't think there will be an agent that to me is subjectively 20% better amongst the big three.
> You can pay 1 cent for a mediocre answer or 2 cents for a great answer.
But Gemini is also a great answer (possibly slightly less great or more great).
When consumers cannot easily assess a product's quality, they frequently use price as a primary indicator, equating higher costs with superior quality.
Quality is Anthropic's game.
Quantity is OpenAi's.
Google's is... specialized hardware? (For now.)
Also deeper crawls, and Google Books! (Though it's unclear if they're making good use of those.)
Gemini is the most paradoxical model because it benchmarks great even in private benchmarks done by regular people, Deep Mind is unquestionably full of capable engineers with incredible skill, and personally Gemini has been great for my day job and my coding for fun (not for profit) endeavors. Switching between it and 4.6 in antigravity and I don't see much of a difference, they both do what I ask.
But man, people are really avid about it being an awful model.
People can be and often are wrong.
You'd notice how good Opus is in Claude Code. IMHO CC is the secret sauce
I feel like a lot of this is just Googles tooling - if you're using Antigravity/Gemini CLI and then use Claude Code it feels like a huge difference. I can say from experience though (using Cline + OpenCode) that they are really close.
The harness is just much better on the Anthropic side.
I personally found Gemini 3.0 to step on my toes in Agentic coding. I tried it around 10 or so times but it quickly became apparent that it was somehow coming to its own conclusions about what needs to be done instead of following instructions.
Like files I didn't mention being edited and read and stuff of that nature. Sometimes this is cute in fixing typos in docs but when its changing things where it clearly doesn't even understand the intentionality behind something it's annoying.
Gemini 3.1 is clearly much better when trying it today. It stayed focused and found its way around without getting distracted.
I've found in everyday chat use with Gemini that it confuses things _it_ says for things I've said, which is normally fine for my purposes but I imagine would lead to the scenario you're describing in coding sessions.
The only cases where I've had gemini step on my toes like that is when a) I realized my instructions were unclear or missing something b) my assumptions/instructions were flawed about how/why something needed to be done.
Instruction following has improved a lot since a few years ago but let's not pretend these things are perfect mate.
There's a certain capacity of instructions, albiet its quite high, at which point you will find them skipping points and drifting. It doesn't have to be ambiguity in instructions.
So strange. I switched from claude few months ago to gemini3 and didn’t look back. Speed is big one, code quality just vastly better, all while far cheaper. I do need to try latest claude models tho.
All perceptions are very personal and anecdotal. Here's mine: I tried to rebuild a website from Hugo to Astro. Gemini 3.0 was mediocre and in the end just failed and was unable to complete the task. Sonnet did almost well. I had to flush the context once most of the job was finished, for atomic git commits and deployment scripts.
> But man, people are really avid about it being an awful model.
If you told people Gemini 3.1 was Claude 4.7, they'd be going nuts singing its praises.
It's so weird. I actually prefer the web version for generic questions like "how would I do X in git" or something, and it'll answer it well. Gemini CLI will immediately try to run git log on the entire graph, grep every single file in the repo, like just answer the question. I actually put in gemini.md to just answer first without running other commands unless explicitly requested and it's been a lot better
Thanks for this suggestion, it's actually been my experience too.
This is misleading. I'm running a live experiment here: https://project80.divcrafts.com/
There are 4 models, all receiving the exact same prompts a few times a day, required to respond with a specific action.
In the first experiment I used gemini-3-pro-preview, it spent ~$18 on the same task where Opus 4.5 spent ~$4, GPT-5.1 spent ~$4.50, and Grok spent ~$7. Pro was burning through money so fast I switched to gemini-3-flash-preview, and it's still outspending every other model on identical prompts. The new experiment is showing the same pattern.
Most of the cost appears to be reasoning tokens.
The takeaway here is: Gemini spends significantly more on reasoning tokens to produce lower quality answers, while Opus thinks less and delivers better results. The per-token price being lower doesn't matter much when the model needs 4x the tokens to get there.
Is that no longer the case, or am I misunderstanding the operational costs displayed?
Opus: 521k input tokens; 12k out
Grok: 443k input tokens; 57k out
Gemini: 677k input tokens; 7k out
OAI: 543k input tokens; 17k out
Gemini appears to use by far the least amount of reasoning tokens, assuming they're included in the output counts.
[dead]
That sounds great, but if Opus generates 20% better code think of the ramifications of that on a real world project. Already $100/month gets you a programmer (or maybe even 2 or 3) that can do your work for you. Insanity. Do I even care if there is something 80% as good for 50% the cost? My answer: no. That said, if it is every bit as good, and their benchmarks suggest it is (but proof will be in testing it out), then sure, a 50% cost reduction sounds really nice.
If I was building an application using massive amounts of calls to the api, I’d probably go with Gemini. For a Copilot, definitely Opus.
It's not half price or cost effective if it can't do the job, that I am happy to pay twice the price for to get done.
But I agree: If they can get there (at one point in the past year I felt they were the best choice for agentic coding), their pricing is very interesting. I am optimistic that it would not require them to go up to Opus pricing.
There's cost, and cost effectiveness. I'd say so far that received negative value for the prompts that I've sent to Gemini 3.
Skill issue, maybe, but I can't get gemini to do any nontrivial tasks reliably, and it's difficult to have it do trivial tasks without getting distracted and making unrelated changes that eat my time and mental energy to think about.
The breakthrough advance of Opus 4.5 over 4.1 wasn't so much an intelligence jump, but a jump in discerning scope and intent behind user queries.
Deepseek is 2% of the cost of Opus. But most people aren't using that for code even tho it's ridiculously cheap.
We are not at the moment where price matters. All that matters is performance.
What did you say? Cant hear you over the $400B in capex spend.
Counterpoint: price will matter before we hit AGI
Why do you believe it has to? Uber took 15 years to show a profit. 15 years from 2022 when chatgpt launched is 2037. That's long enough that to say I don't know if I'll even be alive by then.
Uber didnt burn the market cap of the 10th largest company in the world every couple of years.
It matters to me. I pay for it and I like using it. I pick my models to keep my spend reigned in.
What do you use it for? What is your time worth that you'd settle for a lesser model to save a few bucks?
Homelab and hobby assistant. I have spent $300 for 12 months of tokens. If I'm burning up more than $25 a month then I'd have to pay more or curb use at the end of the year. $25 / month as a new expense is something I can accept for a toy that is letting me accelerate my fun stuff. I can't justify more than that. So I'm left constantly evaluating if my current task is worth more than future tasks and if it is expected to be harder than future tasks. Speculative execution is already one of the harder things I do at work.
> "People underrate Google's cost effectiveness so much. Half price of Opus. HALF."
Google undercutting/subsidizing it's own prices to bite into Anthropic's market share (whilst selling at a loss) doesn't automatically mean Google is effective.
Everybody is subsidizing their prices.
But Flash is 1/8 the cost of sonnet and its not impressive?
Sure, for the launch. Until they start introducing ads, capping existing subscriptions and raising prices (on all products)
I think you are underestimating how much cheaper it is for Google to run the workloads compared to competitors. The hardware advantage is real.
Enshittification will begin eventually. Google already cut free limits on AI studio from 100 rpd to 10 rpd so they started cost savings already.
What does that have to do with what I said? Everyone knows that the companies are operating at a loss right now to capture market share in the hope that it's sticky. Google is losing far less money and will not need to get nearly as extreme with how they try to extra money from the product. That honestly makes me feel better about it's long term prospects. And who knows, maybe local llms will prevent it from getting truly bad anyways. Competition tends to keep product quality high.
> Everybody is subsidizing their prices.
Inference is profitable but model training needs lot of money.
Do they offer a subscription like Claude? These models waste so many tokens "thinking", that using via API is a complete waste of money.
At least Anthropic tells you how many more tokens you’re paying for! 5x 10x 20x whatever. Google seems to just say more, higher, highest.
The pricing page for Claude literally says "More usage" for the $17/month pro plan. Doesn't really quantify anything. The usage is whatever they feel like it should be.
And then the very expensive plan says "Choose 5x or 20x more usage than Pro". It's all arbitrary.
Attention is the new scarce resource. Saving even 50% is nothing if it wastes more of my time.
^ This is a weird Gemini shilling account (check their comment history) but I still want to point how ridiculous this statement is:
> Think about ANY other product and what you'd expect from the competition thats half the price.
Car, fashion, jewelry, earphone, furniture, keyboard, mouse, restaurant, house,...
Lol Ive admitted im a google employee, not hiding my bias.
Most things aren't worth commenting on except the gemini posts here, which I find insane.
And pretty much every example you gave Id expect quite a lot more for 2x the amount? Idk man
So you are an anthropic / openai employee, actually.
Lol i wish.
Any tips for working with Gemini through its chat interface? I’ve worked with ChatGPT and Claude and I’ve generally found them pleasant to work with, but everytime I use Gemini the output is straight dookie
make sure you use ai studio (not the vertex one), not the consumer gemini interface. Seems to work better for code there.
Even though I don't like the privacy implications, make sure you use the option to save and use past chats for context. After a few months of back and forth (hundreds of 'chat' sessions), the responses are much higher quality. It sometimes does 'callbacks' to things discussed in past chats, which are typically awkward non-sequiturs, but it does improve it overall.
When I play with it in 'temporary chat' mode that ignores past chats and personal context directives, the responses are the typical slop littered with emojis, worthless lists, and platitudes/sycophancy. It's as jarring as turning off your adblocker and seeing the garish ad trash everywhere.
You must be joking. I’ve turned that off after first month of use. It’s unbearable. “Oh since you are in {place i mentioned a week ago while planning trip but ultimately didnt go} the home assistant integration question changes completely”. Or ending every answer with “since you are salesforce consultant, would you like to learn more about iron smelting?”
I told Gemini I'm a software engineer and it explains absolutely everything in programming metaphors now. I think it's way undertrained with personalization.
It's half the price per token. Not all tokens are generated equally.
Neither are cars but Ill take a Porsche over a Ferrari for a fraction of the price.
While price is definitely important, results are extremely important. Gemini often falls into the 'didn't do' it part of the spectrum, this days Opus almost always does 'good enough'.
Gemini definitely has its merits but for me it just doesn't do what other models can. I vibe-coded an app which recommends me restaurants. The app uses gemini API to make restaurants given bunch of data and prompt.
App itself is vibe-coded with Opus. Gemini didn't cut it.
The binary you draw on models that havent been out a quarter is borderline insane.
Opus is absurdly good in Claude code but theres a lot of use cases Gemini is great at.
I think Google is further behind with the harness than the model
I was careful not to draw binary. I was saying that Opus in Claude Code is good enough for me to make projects. Using Gemini after it seems like a significant downgrade, which actually doesn't get the job done helping me code. This is my experience, it can change if Gemini will get better.
However, for internal use I opt to Gemini, because of API cost. It is great in sorting reviews and menues out.
The order of priority for most people is: 1\ output quality 2\ latency 3\ cost. I will always pays more money if output quality is significantly better and latency is worth the tradeoff. There's also enough cost optimization strategies for applied AI applications that token cost rarely outweighs unless it's a SIGNIFICANT difference (e.x. 100-200% more).
Well, it’s half if the product is equal.
Is it? Honestly, I still chuckle about black Nazis and the female Indian Popes. That was my first impression of Gemini, and first impressions are hard to break. I used Gemini’s VL (vision) for something and it refused to describe because it assumed it was NSFW imagery, which is was not.
I also question statis as an obvious follow up. Is Gemini equal to Opus? Today? Tomorrow? Has Google led the industry thus far and do I expect them to continue?
Counterpoint to that would be that with natural language input and output, that LLM specific tooling is rare and it is easy to switch around if you commoditize the product backend.
Some people like blackjack and a technical edge with card counting, others just say screw it and do slot machines.
This is a decent analogy actually. Kudos
It’s half the price for now, let them gain market traction and ser the price come up. GCP isn’t exactly affordable.
sonnet 4.6 is a third, and equivalent to opus 4.5, which is enough for me usually :)
EDIT: Gemini does have 1m context for "free" though so that's great.
[dead]
If something is shit, it doesn't matter it costs half price of something okay.
"There is hardly anything in the world that some man cannot make a little worse and sell a little cheaper, and the people who consider price only are this man's lawful prey."
If it’s any consolation, it was able to one-shot a UI & data sync race condition that even Opus 4.6 struggled to fix (across 3 attempts).
So far I like how it’s less verbose than its predecessor. Seems to get to the point quicker too.
While it gives me hope, I am going to play it by the ear. Otherwise it’s going to be - Gemini for world knowledge/general intelligence/R&D and Opus/Sonnet 4.6 to finish it off.
UPDATE: I may have spoken too soon.
> Fixing Truncated Array Syncing Bug
> I traced the missing array items to a typo I made earlier!
> When fixing the GC cast crash, I accidentally deleted the assignment..
> ..effectively truncating the entire array behind it.
On a lighter note, every time it happens, I think about this Family Guy: https://youtu.be/HtT2xdANBAY?si=QicynJdQR56S54VL&t=184
For me it's Opus 4.6 for researching code/digging through repos, gpt 5.3 codex for writing code, gemini for single hardcore science/math algorithms and grok for things the others refuse to answer or skirt around (e.g. some security/exploitability related queries). Get yourself one of those wrappers that support all models and forget thinking about who has the best model. The question is who has the best model for your problem. And there's usually a correct answer, even if it changes regularly.
Yes I came to the same conclusion. Just to add: be careful with Opus 4.6 guys. It’s expensive…
Using simtheory.ai which is very good, you can switch models within a conversation and use mcps
Are you associated with this somehow?
Interesting, I've had similar issues. It seems to be very clumsy when using its internal tooling. I've seen diffs where it accidentally garbled significant amounts of code, which it then had to go in and manually fix. It's also introduced bugs into features that it wasn't supposed to be touching, and when I asked it why it was making changes to I the other code, it answered that it had failed to copy-paste since large blocks of code correctly.
Yeah, I whole heartedly agree with this. Even Codex does this sometimes, although it has been consistently much better than the others at following instructions.
The problem is again that you can’t ever fully trust an agent did exactly what you asked for and in the exact manner that you had hoped.
It works just like you’re dealing with a human companion. Trust takes time to build. Over the period you realize the other individuals weaknesses and support them there.
What makes it a bit challenging right now is the pace of innovation. By the time we get used to a model’s personality, a new update comes out that alters it in unknown ways. Now you’re back to square one.
I’ve been experimenting with asking one frontier model to check on another’s work. That’s proven to be better than doing nothing. Usually they’ll have some genuinely useful feedback.
