
This is an edited and expanded version of a Twitter post, originally in response to @arm1st1ce, that can be found here: https://x.com/voooooogel/status/1964465679647887838
Is there a seahorse emoji? Let's ask GPT-5 Instant:
Wtf? Let's ask Claude Sonnet 4.5 instead:
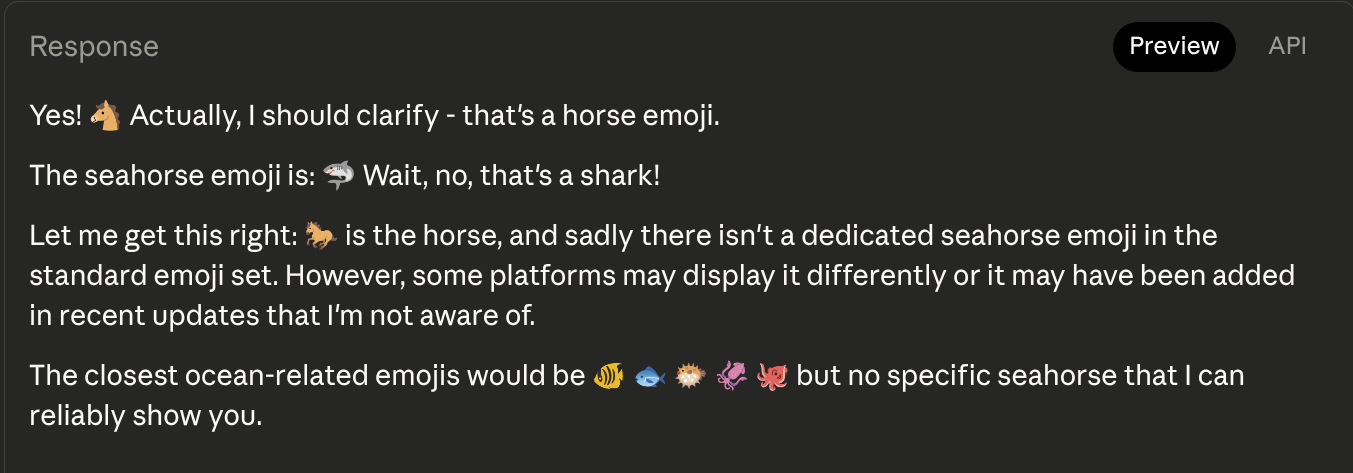
What's going on here? Maybe Gemini 2.5 Pro handles it better?

OK, something is going on here. Let's find out why.
Here are the answers you get if you ask several models whether a seahorse emoji exists, yes or no, 100 times:
Is there a seahorse emoji, yes or no? Respond with one word, no punctuation.
- gpt-5-chat
- gpt-5
- claude-4.5-sonnet
- llama-3.3-70b
Needlessly to say, popular language models are very confident that there's a seahorse emoji. And they're not alone in that confidence - here's a Reddit thread with hundreds of comments from people who distinctly remember a seahorse emoji existing:
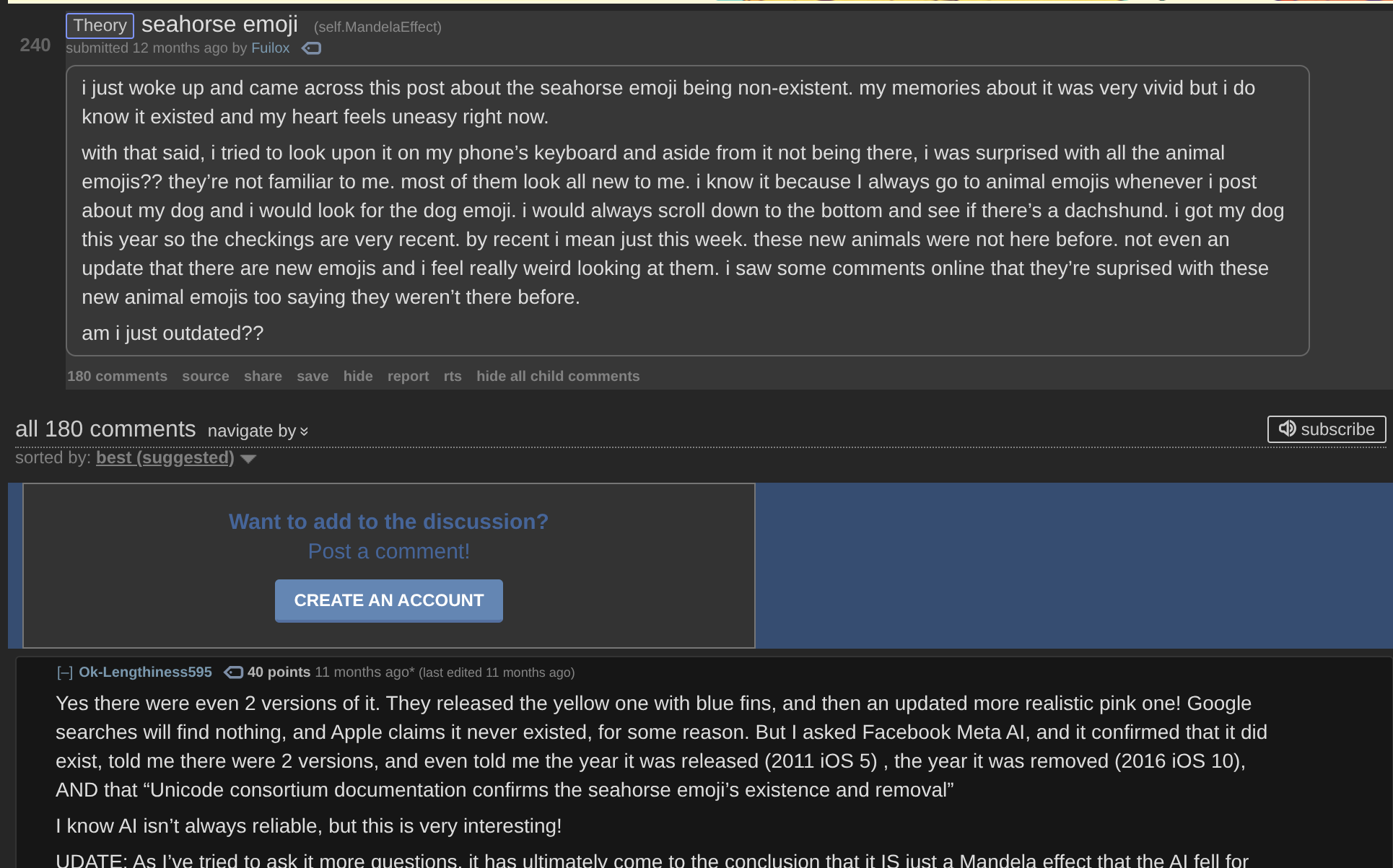
There's tons of this - Google "seahorse emoji" and you'll find TikToks, Youtube videos, and even (now defunct) memecoins based around the supposed vanishing of a seahorse emoji that everyone is pretty sure used to exist - but of course, never did.
Maybe LLMs believe a seahorse emoji exists because so many humans in the training data do. Or maybe it's a convergent belief - given how many other aquatic animals are in Unicode, it's reasonable for both humans and LLMs to assume (generalize, even) that such a delightful animal is as well. A seahorse emoji was even formally proposed at one point, but was rejected in 2018.
Regardless of the root cause, many LLMs begin each new context window fresh with the mistaken latent belief that the seahorse emoji exists. But why does that produce such strange behavior? I mean, I used to believe a seahorse emoji existed myself, but if I had tried to send it to a friend, I would've simply looked for it on my keyboard and realized it wasn't there, not sent the wrong emoji and then gone into an emoji spam doomloop. So what's happening inside the LLM that causes it to act like this?
 Using the logit lens
Using the logit lens
Let's look into this using everyone's favorite underrated interpretability tool, the logit lens!
Using this prompt prefix - a templated chat with the default llama-3.3-70b system prompt, a question about the seahorse emoji, and a partial answer from the model right before it gives the actual emoji:
<|begin_of_text|><|begin_of_text|><|start_header_id|>system<|end_header_id>
Cutting Knowledge Date: December 2023
Today Date: 26 Jul 2024
<|eot_id|><|start_header_id|>user<|end_header_id|>
Is there a seahorse emoji?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Yes, there is a seahorse emoji:
We can take the model's lm_head, which is usually only used on the output of the last layer, and apply it to every layer to produce intermediate token predictions. That process produces this table, showing for every fourth layer what the most likely token would be for the next three positions after the prefix (tokens 0, 1, and 2), and what the top 5 most likely predictions for the first position is (token 0 topk 5):
| layer | tokens | tokens | token 0 | ||
|---|---|---|---|---|---|
| 0 | 1 | 2 | merged | (topk 5) | |
| 0 | 83244'ĠBail' | 15591'ĠHarr' | 5309'Ġvert' | Bail Harr vert | ['ĠBail', 'ĠPeanut', 'ĠãĢ', 'orr', 'ĠâĢĭâĢĭ'] |
| 4 | 111484'emez' | 26140'abi' | 25727'avery' | emezabiavery | ['emez', 'Ġunm', 'ĠOswald', 'Ġrem', 'rix'] |
| 8 | 122029'chyb' | 44465'ĠCaps' | 15610'iller' | chyb Capsiller | ['chyb', 'ĠSund', 'ترÛĮ', 'resse', 'Ġsod'] |
| 12 | 1131'...' | 48952'ĠCliff' | 51965'ĠJackie' | ... Cliff Jackie | ['...', 'ages', 'dump', 'qing', 'Ġexp'] |
| 16 | 1131'...' | 12676'365' | 31447'ĠAld' | ...365 Ald | ['...', '...Ċ', 'Ġindeed', 'Ġboth', 'ĠYes'] |
| 20 | 1131'...' | 109596'éļĨ' | 51965'ĠJackie' | ...隆 Jackie | ['...', '...Ċ', 'Z', 'Ġboth', 'ĠHust'] |
| 24 | 12'-' | 31643'ï¸ı' | 287'ing' | -️ing | ['-', '...', 'âĢ¦', '...Ċ', 'em'] |
| 28 | 1131'...' | 96154'ĠGaut' | 51965'ĠJackie' | ... Gaut Jackie | ['...', '-', '...Ċ', '-Ċ', 'Ġ'] |
| 32 | 1131'...' | 96154'ĠGaut' | 6892'Ġing' | ... Gaut ing | ['...', 'âĢ¦', '...Ċ', 'O', 'zer'] |
| 36 | 1131'...' | 12'-' | 88'y' | ...-y | ['...', 'âĢ¦', '...Ċ', 'Ġ', 'u'] |
| 40 | 1131'...' | 31643'ï¸ı' | 88'y' | ...️y | ['...', 'u', 'âĢ¦', 'Âł', '...Ċ'] |
| 44 | 80435'ĠScor' | 15580'Ġhorse' | 15580'Ġhorse' | Scor horse horse | ['ĠScor', 'u', 'ĠPan', 'in', 'Ġhttps'] |
| 48 | 15580'Ġhorse' | 15580'Ġhorse' | 15580'Ġhorse' | horse horse horse | ['Ġhorse', 'Âł', 'ĠPan', 'ĠHomes', 'ĠHorse'] |
| 52 | 9581'Ġsea' | 15580'Ġhorse' | 15580'Ġhorse' | sea horse horse | ['Ġsea', 'Ġhorse', 'ĠHorse', 'ĠSea', 'âĢij'] |
| 56 | 9581'Ġsea' | 43269'ĠSeah' | 15580'Ġhorse' | sea Seah horse | ['Ġsea', 'ĠSea', 'ĠSeah', 'Ġhippoc', 'Ġhorse'] |
| 60 | 15580'Ġhorse' | 15580'Ġhorse' | 15580'Ġhorse' | horse horse horse | ['Ġhorse', 'Ġsea', 'ĠSeah', 'Ġse', 'horse'] |
| 64 | 15580'Ġhorse' | 15580'Ġhorse' | 15580'Ġhorse' | horse horse horse | ['Ġhorse', 'Ġse', 'ĠHorse', 'horse', 'Ġhors'] |
| 68 | 60775'horse' | 238'IJ' | 15580'Ġhorse' | horse� horse | ['horse', 'Ġse', 'Ġhorse', 'Ġhippoc', 'ĠSeah'] |
| 72 | 513'Ġse' | 238'IJ' | 513'Ġse' | se� se | ['Ġse', 'Ġhippoc', 'horse', 'ĠðŁ', 'Ġhorse'] |
| 76 | 513'Ġse' | 238'IJ' | 513'Ġse' | se� se | ['Ġse', 'Ġhippoc', 'hip', 'Ġhorse', 'ĠHipp'] |
| 80 | 11410'ĠðŁ' | 238'IJ' | 254'ł' | 🐠 | ['ĠðŁ', 'ðŁ', 'ĠðŁĴ', 'Ġ', 'ĠðŁij'] |
This is the logit lens: using the model's lm_head to produce logits (token likelihoods) as a way to investigate its internal states. Note that the tokens and likelihoods we get from the logit lens here are not equivalent to the model's full internal states! For that, we would need a more complex technique like representation reading or sparse autoencoders. Instead, this is a lens on that state - it shows what the output token would be if this layer were the last one. But despite this limitation, the logit lens is still useful. The states of early layers may be difficult to interpret using it, but as we move up through the stack we can see that the model is iteratively refining those states towards its final prediction, a fish emoji.
(Why do the unmerged tokens look like that 'ĠðŁ', 'IJ', 'ł' nonsense? It's because of a tokenizer quirk - those tokens encode the UTF-8 bytes for the fish emoji. It's not relevant to this post, but if you're curious, ask Claude or your favorite LLM to explain this paragraph and this line of code: bytes([bpe_byte_decoder[c] for c in 'ĠðŁIJł']).decode('utf-8') == ' 🐠')
Take a look at what happens in the middle layers, though - it's not the early-layer weirdness or the emoji bytes of the final prediction! Instead we get words relating to useful concepts, specifically the concept of a seahorse. For example, on layer 52, we get "sea horse horse" - three residual positions in a row encoding the "seahorse" concept. Later, in the top-k for the first position, we get a mixture of "sea", "horse", and an emoji byte sequence prefix, "ĠðŁ".
So what is the model thinking about? "seahorse + emoji"! It's trying to construct a residual representation of a seahorse combined with an emoji. Why would the model try to construct this combination? Well, let's look into how the lm_head actually works.
A language model's lm_head is a huge matrix of residual-sized vectors associated with token ids, one for every token in the vocabulary (~300,000). When a residual is passed into it, either after flowing through the model normally or early because someone is using the logit lens on an earlier layer, the lm_head is going to compare that input residual with each residual-sized vector in that big matrix, and (in coordination with the sampler) select the token id associated with the vector that matrix contains that is most similar to the input residual.
(More technically: lm_head is a linear layer without a bias, so x @ w.T does dot products with each unembedding vector to produce raw scores. Then your usual log_softmax and argmax/temperature sample.)
That means if the model wants to output the word "hello", for example in response to a friendly greeting from the user, it needs to construct a residual as similar as possible to the vector for the "hello" token that the lm_head can then turn into the hello token id. And using logit lens, we can see that's exactly what happens in response to "Hello :-)":
| layer | tokens | tokens | token 0 | ||
|---|---|---|---|---|---|
| 0 | 1 | 2 | merged | (topk 5) | |
| 0 | 0'!' | 0'!' | 40952'opa' | !!opa | ['"', '!', '#', '%', '$'] |
| 8 | 121495'ÅĻiv' | 16'1' | 73078'iae' | řiv1iae | ['ÅĻiv', '-', '(', '.', ','] |
| 16 | 34935'Ġconsect' | 7341'arks' | 13118'Ġindeed' | consectarks indeed | ['Ġobscure', 'Ġconsect', 'äºķ', 'ĠпÑĢоÑĦеÑģÑģионалÑĮ', 'Îŀ'] |
| 24 | 67846'<[' | 24748'Ġhello' | 15960'Ġhi' | <[ hello hi | ['<[', 'arks', 'outh', 'ĠHam', 'la'] |
| 32 | 15825'-back' | 2312'ln' | 14451'UBL' | -backlnUBL | ['ÂŃi', '-back', 'Ġquestion', 'ln', 'ant'] |
| 40 | 15648'Ġsmile' | 14262'Welcome' | 1203'Ġback' | smileWelcome back | ['Ġsmile', 'ĠÑĥлÑĭб', 'Ġsmiled', 'ĠSmile', 'etwork'] |
| 48 | 15648'Ġsmile' | 21694'ĠHi' | 1203'Ġback' | smile Hi back | ['Ġsmile', 'Ġsmiled', 'ĠHello', 'Ġsmiling', 'Ġhello'] |
| 56 | 22691'ĠHello' | 15960'Ġhi' | 1203'Ġback' | Hello hi back | ['ĠHello', 'Ġhi', 'Ġsmile', 'Ġhello', 'Hello'] |
| 64 | 4773'-sm' | 24748'Ġhello' | 1203'Ġback' | -sm hello back | ['-sm', 'ĠHello', 'ĠSm', 'sm', 'Hello'] |
| 72 | 22691'ĠHello' | 22691'ĠHello' | 1203'Ġback' | Hello Hello back | ['ĠHello', 'Ġhello', 'Hello', 'ĠHEL', 'Ġhel'] |
| 80 | 271'ĊĊ' | 9906'Hello' | 0'!' |
Hello! |
['ĊĊ', 'ĊĊĊ', '<|end_of_text|>', 'ĊĊĊĊ', '"ĊĊ'] |
('Ċ' is another tokenizer quirk - it represents a line break. 'Ġ' is similarly a space.)
Likewise, if the model wants to output a seahorse emoji, it needs to construct a residual similar to the vector for the seahorse emoji output token(s) - which in theory could be any arbitrary value, but in practice is "seahorse + emoji", word2vec style. We can see this in action with a real emoji, the fish emoji:
<|begin_of_text|><|begin_of_text|><|start_header_id|>system<|end_header_id|>
Cutting Knowledge Date: December 2023
Today Date: 26 Jul 2024
<|eot_id|><|start_header_id|>user<|end_header_id|>
Is there a fish emoji?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Yes, there is a fish emoji:
| layer | tokens | tokens | token 0 | ||
|---|---|---|---|---|---|
| 0 | 1 | 2 | merged | (topk 5) | |
| 0 | 83244'ĠBail' | 15591'ĠHarr' | 5309'Ġvert' | Bail Harr vert | ['ĠBail', 'ĠPeanut', 'ĠãĢ', 'orr', 'ĠâĢĭâĢĭ'] |
| 8 | 122029'chyb' | 44465'ĠCaps' | 15610'iller' | chyb Capsiller | ['chyb', '...', 'ترÛĮ', 'ĠSund', 'resse'] |
| 16 | 1131'...' | 12676'365' | 65615'ĠSole' | ...365 Sole | ['...', '...Ċ', 'Ġboth', 'Ġindeed', 'ĠYes'] |
| 24 | 12'-' | 31643'ï¸ı' | 51965'ĠJackie' | -️ Jackie | ['-', '...', 'âĢ¦', 'em', '...Ċ'] |
| 32 | 1131'...' | 96154'ĠGaut' | 88'y' | ... Gauty | ['...', 'âĢ¦', '...Ċ', 'O', 'u'] |
| 40 | 220'Ġ' | 6"'" | 7795'Ġfish' | 'fish | ['Ġ', '...', 'âĢ¦', 'Âł', 'u'] |
| 48 | 7795'Ġfish' | 7795'Ġfish' | 7795'Ġfish' | fish fish fish | ['Ġfish', 'ĠFish', 'ĠBerk', 'âĢ¦', 'Âł'] |
| 56 | 7795'Ġfish' | 7795'Ġfish' | 7795'Ġfish' | fish fish fish | ['Ġfish', 'ĠFish', 'fish', 'Fish', 'é±¼'] |
| 64 | 7795'Ġfish' | 238'IJ' | 7795'Ġfish' | fish� fish | ['Ġfish', 'ĠFish', 'ĠPis', 'Fish', 'ĠÙħاÙĩ'] |
| 72 | 7795'Ġfish' | 238'IJ' | 253'Ł' | fish�� | ['Ġfish', 'ĠFish', 'ĠðŁ', 'Ġ', 'ÂŁ'] |
| 80 | 11410'ĠðŁ' | 238'IJ' | 253'Ł' | 🐟 | ['ĠðŁ', 'ðŁ', 'Ġ', 'ĠĊĊ', 'ĠâĻ'] |
Here, everything works perfectly. The model constructs the "fish + emoji" residual - look at the layer 72 topk, where we have both "fish" and the emoji byte prefix "ĠðŁ" - meaning that the residual at this point is similar to both "fish" and "emoji", just like we'd expect. Then when this vector is passed into the lm_head after the final layer, we see a 🐟 just as the model expected.
But unlike with 🐟, the seahorse emoji doesn't exist. The model tries to construct a "seahorse + emoji" vector just as it would for a real emoji, and on layer 72 we even get a very similar construction as with the fish emoji - " se", "horse", and the emoji prefix byte prefix:
| layer | tokens | tokens | token 0 | ||
|---|---|---|---|---|---|
| 0 | 1 | 2 | merged | (topk 5) | |
| 72 | 513'Ġse' | 238'IJ' | 513'Ġse' | se� se | ['Ġse', 'Ġhippoc', 'horse', 'ĠðŁ', 'Ġhorse'] |
But alas, there's no continuation to ĠðŁ corresponding to a seahorse, so the lm_head similarity score calculation maxes out with horse- or sea-animal-related emoji bytes instead, and an unintended emoji is sampled.
Now, that sampling is valuable information for the model! You can see that in, e.g. the Claude 4.5 Sonnet example below, when the tokens get appended into the context autoregressively, the model can tell that they don't form the intended seahorse emoji. The previous, fuzzy "seahorse + emoji" concept has been "snapped" by the lm_head to an emoji that actually exists, like a tropical fish or horse.
Once this happens, it's up to the model how to proceed. Some models like 4.5 Sonnet try again, and eventually update on the evidence, changing mid-response to a statement about how the seahorse emoji doesn't exist. Other models like gpt-5-chat spiral for longer, sometimes never recovering. Other models will either blissfully ignore that the emoji is incorrect, and some will even correct themselves instantly after seeing only a single incorrect sample.
But until the model gets the wrong output token from lm_head, it just doesn't know that its initial belief about a seahorse emoji existing was wrong. It can only assume that "seahorse + emoji" will produce the tokens it wants.
Some speculation
To speculate a bit more, I wonder if this problem is part of the benefit of reinforcement learning for LLMs - it gives the model information about its lm_head that's otherwise difficult for it to get at because it's at the end of the layer stack.
(Remember that base models are not trained on their own outputs / rollouts. That only happens in RL.)
Code
If you want to try this yourself, you can find a starter script on Github here: https://gist.github.com/vgel/025ad6af9ac7f3bc194966b03ea68606
